奇異值分解SVD應(yīng)用——LSI
在自然語言處理中��,最常見的兩類的分類問題分別是��,將文本按主題歸類(比如將所有介紹亞運會的新聞歸到體育類)和將詞匯表中的字詞按意思歸類(比如將各種體育運動的名稱個歸成一類)��。這兩種分類問題都可用通過矩陣運算來圓滿地����、同時解決�����。為了說明如何用矩陣這個工具類解決這兩個問題的���,讓我們先來來回顧一下我們在余弦定理和新聞分類中介紹的方法。
分類的關(guān)鍵是計算相關(guān)性�。我們首先對兩個文本計算出它們的內(nèi)容詞����,或者說實詞的向量��,然后求這兩個向量的夾角�。當(dāng)這兩個向量夾角為零時,新聞就相關(guān)�;當(dāng)它們垂直或者說正交時,新聞則無關(guān)���。當(dāng)然����,夾角的余弦等同于向量的內(nèi)積���。從理論上講���,這種算法非常好。但是計算時間特別長����。通常,我們要處理的文章的數(shù)量都很大����,至少在百萬篇以上���,二次回標(biāo)有非常長,比如說有五十萬個詞(包括人名地名產(chǎn)品名稱等等)�����。如果想通過對一百萬篇文章兩篇兩篇地成對比較��,來找出所有共同主題的文章���,就要比較五千億對文章?����,F(xiàn)在的計算機一秒鐘最多可以比較一千對文章��,完成這一百萬篇文章相關(guān)性比較就需要十五年時間。注意����,要真正完成文章的分類還要反復(fù)重復(fù)上述計算。
在文本分類中���,另一種辦法是利用矩陣運算中的奇異值分解(Singular Value Decomposition���,簡稱 SVD)?����,F(xiàn)在讓我們來看看奇異值分解是怎么回事�����。首先�����,我們可以用一個大矩陣A來描述這一百萬篇文章和五十萬詞的關(guān)聯(lián)性�。這個矩陣中����,每一行對應(yīng)一篇文章,每一列對應(yīng)一個詞�����。
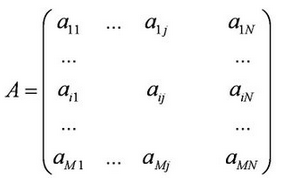
在上面的圖中����,M=1,000,000���,N=500,000。第 i 行�,第 j 列的元素,是字典中第 j 個詞在第 i 篇文章中出現(xiàn)的加權(quán)詞頻(比如����,TF/IDF)。讀者可能已經(jīng)注意到了���,這個矩陣非常大�,有一百萬乘以五十萬��,即五千億個元素����。
奇異值分解就是把上面這樣一個大矩陣,分解成三個小矩陣相乘�,如下圖所示。比如把上面的例子中的矩陣分解成一個一百萬乘以一百的矩陣X�,一個一百乘以一百的矩陣B���,和一個一百乘以五十萬的矩陣Y��。這三個矩陣的元素總數(shù)加起來也不過1.5億����,僅僅是原來的三千分之一。相應(yīng)的存儲量和計算量都會小三個數(shù)量級以上�。
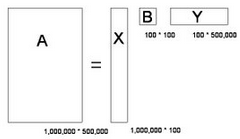
三個矩陣有非常清楚的物理含義。第一個矩陣X中的每一列表示一類主題��,其中的每個非零元素表示一個主題與一篇文章的相關(guān)性�����,數(shù)值越大越相關(guān)�。最后一個矩陣Y中的每一列表示100個關(guān)鍵詞,每個key word與500���,000個詞的相關(guān)性���。中間的矩陣則表示文章主題和keyword之間的相關(guān)性。因此�,我們只要對關(guān)聯(lián)矩陣A進行一次奇異值分解,w 我們就可以同時完成了近義詞分類和文章的分類。(同時得到每類文章和每類詞的相關(guān)性)�����。
比如降至2維(rank=2)�����,則document-term的關(guān)系可以在下面二維圖中展現(xiàn):
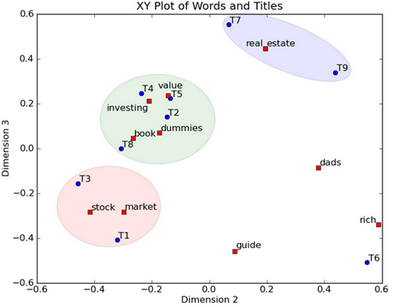
在圖上��,每一個紅色的點�,都表示一個詞,每一個藍色的點��,都表示一篇文檔��,這樣我們可以對這些詞和文檔進行聚類�,比如說stock
和
market可以放在一類,因為他們老是出現(xiàn)在一起��,real和estate可以放在一類���,dads�����,guide這種詞就看起來有點孤立了���,我們就不對他們進行合并了。按這樣聚類出現(xiàn)的效果����,可以提取文檔集合中的近義詞,這樣當(dāng)用戶檢索文檔的時候�����,是用語義級別(近義詞集合)去檢索了��,而不是之前的詞的級別�。這樣一減少我們的檢索、存儲量���,因為這樣壓縮的文檔集合和PCA是異曲同工的�����,二可以提高我們的用戶體驗�����,用戶輸入一個詞����,我們可以在這個詞的近義詞的集合中去找,這是傳統(tǒng)的索引無法做到的�。
現(xiàn)在剩下的唯一問題,就是如何用計算機進行奇異值分解�。這時,線性代數(shù)中的許多概念���,比如矩陣的特征值等等��,以及數(shù)值分析的各種算法就統(tǒng)統(tǒng)用上了�����。在很長時間內(nèi),奇異值分解都無法并行處理�。(雖然
Google 早就有了MapReduce 等并行計算的工具,但是由于奇異值分解很難拆成不相關(guān)子運算���,即使在 Google
內(nèi)部以前也無法利用并行計算的優(yōu)勢來分解矩陣�����。)最近��,Google
中國的張智威博士和幾個中國的工程師及實習(xí)生已經(jīng)實現(xiàn)了奇異值分解的并行算法�,我認為這是 Google 中國對世界的一個貢獻。
最后說說個人拙見�,這里我們可以把document和term(word)中間加上一層latent
semantics項,那么上圖中的X和Y矩陣就可以分別表示同一個latent
semantics對不同document之間的相關(guān)性和同一latent
semantics在不同terms之間的相關(guān)性聯(lián)系�����。X和Y的大小分別是m*r與r*n��,r為A矩陣的rank(秩)����,最后��,B是A的r個奇異值組成的對角方陣(r*r)����,在譜分解中也就是A的r個特征值��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330