業(yè)界共同開掘大數(shù)據(jù)文化價值
使用深度學習方法按照本文所介紹的步驟處理結構化數(shù)據(jù)有這樣的好處:
快
無需領域知識
表現(xiàn)優(yōu)良
在機器學習/深度學習或任何類型的預測建模任務中,都是先有數(shù)據(jù)然后再做算法/方法��。這也是某些機器學習方法在解決某些特定任務之前需要做大量特征工程的主要原因�,這些特定任務包括圖像分類、NLP
和許多其它「非常規(guī)的」數(shù)據(jù)的處理——這些數(shù)據(jù)不能直接送入 logistic
回歸模型或隨機森林模型進行處理。相反���,深度學習無需任何繁雜和耗時的特征工程也能在這些類型的任務取得良好的表現(xiàn)。大多數(shù)時候��,這些特征需要領域知識�、創(chuàng)造力和大量的試錯。

圖 1:一只萌狗和一只怒貓
由于特征生成(比如
CNN
的卷積層)的本質和能力很復雜�,所以深度學習在各種各樣的圖像��、文本和音頻數(shù)據(jù)問題上得到了廣泛的應用����。這些問題無疑對人工智能的發(fā)展非常重要,而且這一領域的頂級研究者每年都在分類貓��、狗和船等任務上你追我趕����,每年的成績也都優(yōu)于前一年。但在實際行業(yè)應用方面我們卻很少看到這種情況�。這是為什么呢?公司企業(yè)的數(shù)據(jù)庫涉及到結構化數(shù)據(jù),這些才是塑造了我們的日常生活的領域�。
首先,讓我們先定義一下結構化數(shù)據(jù)。在結構化數(shù)據(jù)中����,你可以將行看作是收集到的數(shù)據(jù)點或觀察,將列看作是表示每個觀察的單個屬性的字段�����。比如說��,來自在線零售商店的數(shù)據(jù)有表示客戶交易事件的列和包含所買商品����、數(shù)量、價格�、時間戳等信息的列。
下面我們給出了一些賣家數(shù)據(jù)�����,行表示每個獨立的銷售事件�����,列中給出了這些銷售事件的信息��。
據(jù)�?")
圖 2:結構化數(shù)據(jù)的 pandas dataframe 示例
接下來我們談談如何將神經網(wǎng)絡用于結構化數(shù)據(jù)任務。實際上�,在理論層面上,創(chuàng)建帶有任何所需架構的全連接網(wǎng)絡都很簡單�����,然后使用「列」作為輸入即可���。在損失函數(shù)經歷過一些點積和反向傳播之后�,我們將得到一個訓練好的網(wǎng)絡����,然后就可以進行預測了����。
盡管看起來非常簡單直接,但在處理結構化數(shù)據(jù)時����,人們往往更偏愛基于樹的方法,而不是神經網(wǎng)絡���。原因為何?這可以從算法的角度理解——算法究竟是如何對待和處理我們的數(shù)據(jù)的�。
人們對結構化數(shù)據(jù)和非結構化數(shù)據(jù)的處理方式是不同的。非結構化數(shù)據(jù)雖然是「非常規(guī)的」�,但我們通常處理的是單位量的單個實體,比如像素�����、體素����、音頻頻率、雷達反向散射�、傳感器測量結果等等。而對于結構化數(shù)據(jù)����,我們往往需要處理多種不同的數(shù)據(jù)類型;這些數(shù)據(jù)類型分為兩大類:數(shù)值數(shù)據(jù)和類別數(shù)據(jù)。類別數(shù)據(jù)需要在訓練之前進行預處理���,因為包含神經網(wǎng)絡在內的大多數(shù)算法都還不能直接處理它們���。
編碼變量有很多可選的方法,比如標簽/數(shù)值編碼和 one-hot 編碼���。但在內存方面和類別層次的真實表示方面�����,這些技術還存在問題���。內存方面的問題可能更為顯著���,我們通過一個例子來說明一下。
假設我們列中的信息是一個星期中的某一天����。如果我們使用 one-hot 或任意標簽編碼這個變量,那么我們就要假設各個層次之間都分別有相等和任意的距離/差別����。
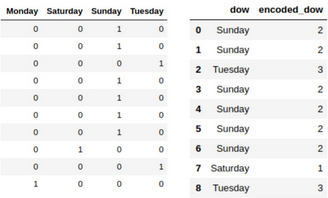
圖 3:one-hot 編碼和標簽編碼
但這兩種方法都假設每兩天之間的差別是相等的,但我們很明顯知道實際上并不是這樣��,我們的算法也應該知道這一點!
「神經網(wǎng)絡的連續(xù)性本質限制了它們在類別變量上的應用����。因此�����,用整型數(shù)表示類別變量然后就直接應用神經網(wǎng)絡,不能得到好的結果�。」[1]
基于樹的算法不需要假設類別變量是連續(xù)的�,因為它們可以按需要進行分支來找到各個狀態(tài),但神經網(wǎng)絡不是這樣的����。實體嵌入(entity
embedding)可以幫助解決這個問題。實體嵌入可用于將離散值映射到多維空間中��,其中具有相似函數(shù)輸出的值彼此靠得更近�。比如說,如果你要為一個銷售問題將各個省份嵌入到國家這個空間中�,那么相似省份的銷售就會在這個投射的空間相距更近。
因為我們不想在我們的類別變量的層次上做任何假設��,所以我們將在歐幾里得空間中學習到每個類別的更好表示���。這個表示很簡單�����,就等于 one-hot 編碼與可學習的權重的點積����。
嵌入在 NLP 領域有非常廣泛的應用,其中每個詞都可表示為一個向量���。Glove 和 word2vec
是其中兩種著名的嵌入方法���。我們可以從圖 4 看到嵌入的強大之處
[2]。只要這些向量符合你的目標���,你隨時可以下載和使用它們;這實際上是一種表示它們所包含的信息的好方法����。
據(jù)�?")
圖 4:來自 TensorFlow 教程的 word2vec
盡管嵌入可以在不同的語境中使用(不管是監(jiān)督式方法還是無監(jiān)督式方法),但我們的主要目標是了解如何為類別變量執(zhí)行這種映射���。
實體嵌入
盡管人們對「實體嵌入」有不同的說法�,但它們與我們在詞嵌入上看到的用例并沒有太大的差異�����。畢竟���,我們只關心我們的分組數(shù)據(jù)有更高維度的向量表示;這些數(shù)據(jù)可能是詞�、每星期的天數(shù)����、國家等等。這種從詞嵌入到元數(shù)據(jù)嵌入(在我們情況中是類別)的轉換使用讓
Yoshua Bengio 等人使用一種簡單的自動方法就贏得了 2015 年的一場 Kaggle
競賽——通常這樣做是無法贏得比賽的�。參閱:https://www.kaggle.com/c/pkdd-15-predict-taxi-service-trajectory-i
「為了處理由客戶 ID、出租車 ID���、日期和時間信息組成的離散的元數(shù)據(jù)�,我們使用該模型為這些信息中的每種信息聯(lián)合學習了嵌入���。這種方法的靈感來自于自然語言建模方法 [2]����,其中每個詞都映射到了一個固定大小的向量空間(這種向量被稱為詞嵌入)�����。[3]
據(jù)���?")
圖 5:使用 t-SNE 2D 投影得到的出租車元數(shù)據(jù)嵌入可視化
我們將一步步探索如何在神經網(wǎng)絡中學習這些特征�。定義一個全連接的神經網(wǎng)絡���,然后將數(shù)值變量和類別變量分開處理��。
對于每個類別變量:
1. 初始化一個隨機的嵌入矩陣 mxD:
-
m:類別變量的不同層次(星期一�、星期二……)的數(shù)量
-
D:用于表示的所需的維度�����,這是一個可以取值 1 到 m-1 的超參數(shù)(取 1 就是標簽編碼�����,取 m 就是 one-hot 編碼)

圖 6:嵌入矩陣
2. 然后�����,對于神經網(wǎng)絡中的每一次前向通過�,我們都在該嵌入矩陣中查詢一次給定的標簽(比如為「dow」查詢星期一),這會得到一個 1xD 的向量����。
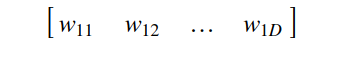
圖 7:查找后的嵌入向量
3. 將這個 1×D 的向量附加到我們的輸入向量(數(shù)值向量)上�����。你可以把這個過程看作是矩陣增強,其中我們?yōu)槊恳粋€類別都增加一個嵌入向量��,這是通過為每一特定行執(zhí)行查找而得到的���。
據(jù)?")
圖 8:添加了嵌入向量后
4. 在執(zhí)行反向傳播的同時��,我們也以梯度的方式來更新這些嵌入向量��,以最小化我們的損失函數(shù)��。
輸入一般不會更新�����,但對嵌入矩陣而言有一種特殊情況����,其中我們允許我們的梯度反向流回這些映射的特征�����,從而優(yōu)化它們��。
我們可以將其看作是一個讓類別嵌入在每次迭代后都能進行更好的表示的過程���。
注意:根據(jù)經驗,應該保留沒有非常高的基數(shù)的類別���。因為如果一個變量的某個特定層次占到了 90% 的觀察��,那么它就是一個沒有很好的預測價值的變量���,我們可能最好還是避開它。
好消息
通過在我們的嵌入向量中執(zhí)行查找并允許 requires_grad=True
并且學習它們����,我們可以很好地在我們最喜歡的框架(最好是動態(tài)框架)中實現(xiàn)上面提到的架構。但 Fast.ai
已經實現(xiàn)了所有這些步驟并且還做了更多�����。除了使結構化的深度學習更簡單,這個庫還提供了很多當前最先進的功能��,比如差異學習率�����、SGDR�、周期性學習率�、學習率查找等等。這些都是我們可以利用的功能�。
使用 Fast.ai 實現(xiàn)
在這一部分,我們將介紹如何實現(xiàn)上述步驟并構建一個能更有效處理結構化數(shù)據(jù)的神經網(wǎng)絡���。
為此我們要看看一個熱門的
Kaggle
競賽:https://www.kaggle.com/c/mercari-price-suggestion-challenge/��。對于實體嵌入來說�����,這是一個非常合適的例子����,因為其數(shù)據(jù)基本上都是類別數(shù)據(jù)�����,而且有相當高的基數(shù)(也不是過高),另外也沒有太多其它東西�����。
數(shù)據(jù):
約 140 萬行
item_condition_id:商品的情況(基數(shù):5)
category_name:類別名稱(基數(shù):1287)
brand_name:品牌名稱(基數(shù):4809)
shipping:價格中是否包含運費(基數(shù):2)
重要說明:因為我已經找到了最好的模型參數(shù)����,所以我不會在這個例子包含驗證集,但是你應該使用驗證集來調整超參數(shù)�����。
第 1 步:
將缺失值作為一個層次加上去����,因為缺失本身也是一個重要信息。
-
train.category_name = train.category_name.fillna('missing').astype('category')
-
train.brand_name = train.brand_name.fillna('missing').astype('category')
-
train.item_condition_id = train.item_condition_id.astype('category')
-
test.category_name = test.category_name.fillna('missing').astype('category')
-
test.brand_name = test.brand_name.fillna('missing').astype('category')
-
test.item_condition_id = test.item_condition_id.astype('category')
第 2 步:
預處理數(shù)據(jù)��,對數(shù)值列進行等比例的縮放調整����,因為神經網(wǎng)絡喜歡歸一化的數(shù)據(jù)。如果你不縮放你的數(shù)據(jù)�,網(wǎng)絡就可能格外重點關注一個特征����,因為這不過都是點積和梯度�����。如果我們根據(jù)訓練統(tǒng)計對訓練數(shù)據(jù)和測試數(shù)據(jù)都進行縮放����,效果會更好,但這應該影響不大��。這就像是把每個像素的值都除以
255�,一樣的道理���。
因為我們希望相同的層次有相同的編碼���,所以我將訓練數(shù)據(jù)和測試數(shù)據(jù)結合了起來。
-
combined_x, combined_y, nas, _ = proc_df(combined, 'price', do_scale=True)
第 3 步:
創(chuàng)建模型數(shù)據(jù)對象����。路徑是 Fast.ai 存儲模型和激活的地方。
-
path = '../data/'
-
md = ColumnarModelData.from_data_frame(path, test_idx, combined_x, combined_y, cat_flds=cats, bs= 128
第 4 步:
確定 D(嵌入的維度)����,cat_sz 是每個類別列的元組 (col_name, cardinality+1) 的列表�����。
-
# We said that D (dimension of embedding) is an hyperparameter
-
# But here is Jeremy Howard's rule of thumb
-
emb_szs = [(c, min(50, (c+1)//2)) for _,c in cat_sz]
-
# [(6, 3), (1312, 50), (5291, 50), (3, 2)]
第 5 步:
創(chuàng)建一個 learner���,這是 Fast.ai 庫的核心對象。
-
params: embedding sizes, number of numerical cols, embedding dropout, output, layer sizes, layer dropouts
-
m = md.get_learner(emb_szs, len(combined_x.columns)-len(cats),
第 6 步:
這部分在我前面提及的其它文章中有更加詳細的解釋��。
要充分利用 Fast.ai 的優(yōu)勢�����。
在損失開始增大之前的某個時候�,我們要選擇我們的學習率……
-
# find best lrm.lr_find()# find best lrm.sched.plot()
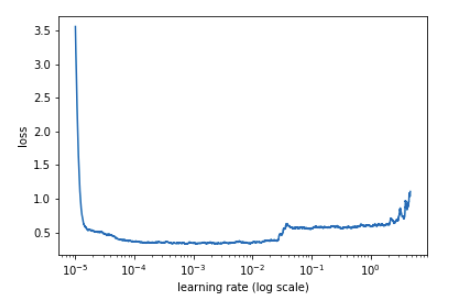
圖 9:學習率與損失圖
擬合
我們可以看到,僅僅過了 3 epoch��,就得到:
-
lr = 0.0001m.fit(lr, 3, metrics=[lrmse])
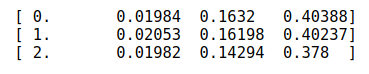
更多擬合
-
m.fit(lr, 3, metrics=[lrmse], cycle_len=1)

還有更多……
-
m.fit(lr, 2, metrics=[lrmse], cycle_len=1)

所以�,在短短幾分鐘之內,無需進一步的其它操作��,這些簡單卻有效的步驟就能讓你進入大約前 10% 的位置�����。如果你真的有更高的目標,我建議你使用
item_description 列并將其作為多個類別變量使用�。然后把工作交給實體嵌入完成,當然不要忘記堆疊和組合����。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經營許可證編號:京B2-20210330