大型互聯(lián)網(wǎng)站解決海量數(shù)據(jù)的常見策略
大型互聯(lián)網(wǎng)站的數(shù)據(jù)存儲(chǔ)與傳統(tǒng)存儲(chǔ)環(huán)境相比不僅是一個(gè)服務(wù)器、一個(gè)數(shù)據(jù)庫那么簡單�����,而是由網(wǎng)絡(luò)設(shè)備���、存儲(chǔ)設(shè)備�����、應(yīng)用服務(wù)器�、公用訪問接口��、應(yīng)用程序
等多個(gè)部分組成的復(fù)雜系統(tǒng)�。分為 業(yè)務(wù)數(shù)據(jù)層、計(jì)算層���、數(shù)據(jù)倉儲(chǔ)����、數(shù)據(jù)備份,通過應(yīng)用服務(wù)器軟件提供數(shù)據(jù)存儲(chǔ)服務(wù)����,并且通過監(jiān)控工具對(duì)存儲(chǔ)單元監(jiān)控。
隨著系統(tǒng)中用戶數(shù)據(jù)量的線性增長����,數(shù)據(jù)量將會(huì)越來越多。在這樣一個(gè)數(shù)據(jù)不斷膨脹的環(huán)境中��,數(shù)據(jù)已經(jīng)如洪水般洶涌泛濫���。數(shù)據(jù)查找和調(diào)用困難�,在海量數(shù)據(jù)中一些用戶提交的請(qǐng)求往往要等到第二天才能得知結(jié)果����,直接影響到了用戶滿意度的提升和新業(yè)務(wù)的布局。在技術(shù)上而言����,這一特點(diǎn)使得RDBMS在大型應(yīng)用場景被大幅限制,唯一的可選方案是Scale
Out,通過增加多個(gè)邏輯單元的資源,并使它們?nèi)缤粋€(gè)集中的資源那樣提供服務(wù)來實(shí)現(xiàn)系統(tǒng)的擴(kuò)展性�����。
系統(tǒng)中的數(shù)據(jù)就好比我們家里的物品,衣服放在衣柜里����,碟子放在碗櫥里��,數(shù)據(jù)庫����、存儲(chǔ)系統(tǒng)就好比你的衣柜和碗櫥是一個(gè)存放的容器,衣服和碟子就好比不同的數(shù)據(jù)���,將不同類型的東西放入合適的存儲(chǔ)空間里面���,這樣系統(tǒng)的效率和利用率將會(huì)更高,所以我們將會(huì)做出如下設(shè)計(jì)����,如圖所示:
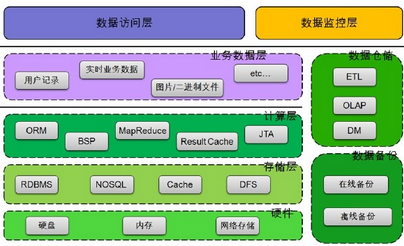
對(duì)于大型系統(tǒng)存儲(chǔ)單元的結(jié)構(gòu)模型我們分為6個(gè)部分組成,清單如下:
1. 業(yè)務(wù)數(shù)據(jù)層
各類業(yè)務(wù)所產(chǎn)生的各種文件類型的數(shù)據(jù)��,其中包含 用戶信息���、用戶操作記錄���、實(shí)時(shí)業(yè)務(wù)數(shù)據(jù)�、手機(jī)客戶端升級(jí)應(yīng)用程序��、圖片�����,等���。
2. 計(jì)算層
針對(duì)不同的數(shù)據(jù)格式���、不同類型的數(shù)據(jù)文件,通過不同的工具���、計(jì)算方法進(jìn)行操作�,針對(duì)大量的數(shù)據(jù)計(jì)算采用一些分布式�、并行計(jì)算的算法,例如:MapReduce�����,BSP。并且對(duì)一部分的數(shù)據(jù)進(jìn)行緩存����,緩解對(duì)存儲(chǔ)應(yīng)用服務(wù)器的壓力。
3. 數(shù)據(jù)存儲(chǔ)層
對(duì)于海量數(shù)據(jù)的查詢與存儲(chǔ)����,特別是針對(duì)用戶行為日志操作��,需要使用到一些列式數(shù)據(jù)庫服務(wù)器����,對(duì)于處理業(yè)務(wù)和一些業(yè)務(wù)規(guī)則的數(shù)據(jù)依然存放在關(guān)系型數(shù)據(jù)庫中,將采用MySQL來存儲(chǔ)��。
4. 數(shù)據(jù)倉儲(chǔ)
數(shù)據(jù)存儲(chǔ)主要是針對(duì)于用戶行為日志和用戶行為分析�,也是系統(tǒng)中數(shù)據(jù)量產(chǎn)生較大的一個(gè)環(huán)節(jié),將會(huì)采用Apache Hive���、Pig����、Mathout 對(duì)數(shù)據(jù)倉儲(chǔ)進(jìn)行構(gòu)建���。
5. 數(shù)據(jù)備份
分為在線數(shù)據(jù)備份和離線數(shù)據(jù)備份��,數(shù)據(jù)備份環(huán)節(jié)需要經(jīng)過運(yùn)維經(jīng)驗(yàn)的積累�����,根據(jù)業(yè)務(wù)和用戶訪問量進(jìn)行定制合理的備份規(guī)律���。
6. 硬件
硬件環(huán)境是存儲(chǔ)單元最基礎(chǔ)的部分��,分為磁盤��、內(nèi)存���、網(wǎng)絡(luò)設(shè)備存儲(chǔ),將不同的業(yè)務(wù)數(shù)據(jù)���、文件存儲(chǔ)在不同的硬件設(shè)備上��。
技術(shù)實(shí)現(xiàn)
對(duì)于系統(tǒng)不同的業(yè)務(wù)數(shù)據(jù)和應(yīng)用服務(wù)器的架構(gòu)需要采用不同的讀寫方式���,以及數(shù)據(jù)存儲(chǔ)類型存放,數(shù)據(jù)倉儲(chǔ)構(gòu)建,數(shù)據(jù)冷熱分離����、數(shù)據(jù)索引多個(gè)部分組成。例如:業(yè)務(wù)應(yīng)用程序�����、日志采集代理����、用戶空間文件系統(tǒng)(Filesystem
in Userspace)。Data Access Proxy Layer(DDAL/Cache
Handler)���、OLAP、日志服務(wù)器����、Oracle(暫定)、MySQL���、Redis�����、Hive����、HDFS、Moosefs��。
如圖所示:
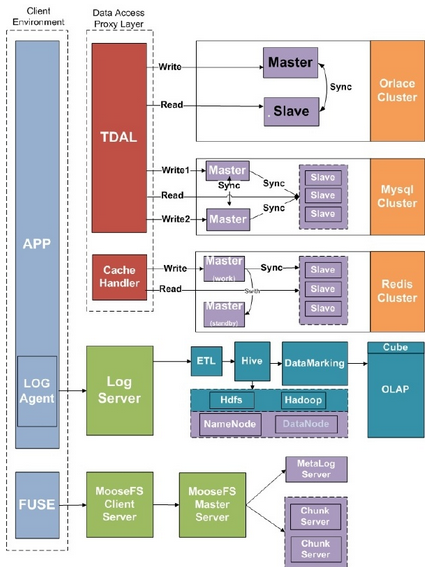
針對(duì)以上設(shè)計(jì)架構(gòu)��,描述清單如下:
1. Data Access Proxy Layer
統(tǒng)稱數(shù)據(jù)訪問代理層(簡稱 DAPL)��,封裝了DDAL和Cache
Handler層�����,抽象的對(duì)編寫的應(yīng)用程序進(jìn)行了劃分�����,便于擴(kuò)展和維護(hù)�����,例如:需要對(duì)HDFS或者圖形數(shù)據(jù)庫操作���,上層不需要知道HDFS具體操作�,只需要關(guān)注提供的接口。DAPL封裝了很多訪問各種數(shù)據(jù)源的讀寫策略�����。因此����,可以保證對(duì)不同數(shù)據(jù)庫、數(shù)據(jù)源操作的事務(wù)完整性�����。
2. DDAL
統(tǒng)稱分布式數(shù)據(jù)訪問層(簡稱
DDAL)主要針對(duì)關(guān)系數(shù)據(jù)庫的讀寫分離操作���,需要做到讀寫分離�,首先需要對(duì)傳入的SQL語句進(jìn)行解析���,并且采用Round-Robin算法負(fù)載分載對(duì)數(shù)據(jù)大量讀取的操作,在代碼實(shí)現(xiàn)中將使用MySQL-JDBC中的參數(shù)配置實(shí)現(xiàn)對(duì)MySQL-Slave的讀取壓力分載��。
3. Cache Handler
與DDAL的相似�,具體區(qū)別在于自己實(shí)現(xiàn)了Round-Robin算法負(fù)載分載對(duì)數(shù)據(jù)大量讀取的操作,并且能在Redis Master當(dāng)機(jī)的狀態(tài)下重新指派新的Master進(jìn)行寫的操作�����。
4. Redis一主多從
對(duì)緩存數(shù)據(jù)進(jìn)行讀寫分離,減少單臺(tái)機(jī)器的I/O瓶頸����,值得一提的是Cache不是可靠的存儲(chǔ),所以在設(shè)計(jì)時(shí)����,需要容許Cache的數(shù)據(jù)丟失,因此����,Cache的數(shù)據(jù)全部失效時(shí),會(huì)從數(shù)據(jù)庫里重新裝載����。
5. MySQL雙主多從
這種方式是MySQL架構(gòu)設(shè)計(jì)中最折中的方案,對(duì)數(shù)據(jù)的訪問壓力分載和數(shù)據(jù)的可靠性都有了相應(yīng)的保障���。前端2臺(tái)Master
MySQL相互進(jìn)行數(shù)據(jù)備份���,后端大量的Slave
MySQL對(duì)Master寫入的數(shù)據(jù)進(jìn)行同步,所以每臺(tái)機(jī)器節(jié)點(diǎn)上的MySQL數(shù)據(jù)庫中的數(shù)據(jù)都是一致的���,并且DDAL應(yīng)用程序?qū)?shù)據(jù)輪詢寫入Master
MySQL數(shù)據(jù)庫中����。
6. 數(shù)據(jù)庫讀寫分離
主要采用mysql的策略,學(xué)習(xí)MySQL-Prxoy的策略�����,自己開發(fā)對(duì)MySQL書籍節(jié)點(diǎn)進(jìn)行讀寫分離的方法�,MySQL驅(qū)動(dòng)支持讀寫分離的數(shù)據(jù)完整性,當(dāng)數(shù)據(jù)量超大規(guī)模的時(shí)候?qū)?huì)采用Sharding策略��。
7. 緩存讀寫分離
緩存Redis的策略��,采用自己開發(fā)的應(yīng)用程序需要實(shí)現(xiàn)Round Robin算法���,對(duì)Redis Master和Slave緩存集群進(jìn)行讀寫分離操作����。
8. ETL Tools
采用Apache Hadoop項(xiàng)目中的Pig對(duì)海量的行為數(shù)據(jù)進(jìn)行清洗�,Pig可以針對(duì)有規(guī)律的半結(jié)構(gòu)化數(shù)據(jù)執(zhí)行類似SQL的腳本����,并且可以將計(jì)算壓力分載到每臺(tái)服務(wù)器上進(jìn)行分布式�、并行處理����。
9. Hive集群
針對(duì)數(shù)據(jù)倉庫的建設(shè)由Apache Hive進(jìn)行構(gòu)建,是一個(gè)建立在Hadoop上的數(shù)據(jù)倉庫框架�,它提供了一個(gè)方便的數(shù)據(jù)集成方法和類似SQL的Hive QL查詢語言,實(shí)現(xiàn)了Map/Reduce算法支持在Hadoop框架上進(jìn)行大規(guī)模數(shù)據(jù)分析��。
10. HDFS分布式文件系統(tǒng)
Hive中的數(shù)據(jù)全部存儲(chǔ)在Hadoop分布式文件系統(tǒng)中����,所有被存儲(chǔ)的數(shù)據(jù)都會(huì)有數(shù)據(jù)的存儲(chǔ)副本,這樣對(duì)數(shù)據(jù)的可靠性有了保障����。
11. Moosefs分布式文件系統(tǒng)
與上面提到的HDFS一個(gè)文件系統(tǒng)是有區(qū)別的,Moosefs不需要任何客戶端程序?qū)Ψ植际轿募M(jìn)行操作的服務(wù)器����,可以直接與任何運(yùn)行環(huán)境進(jìn)行對(duì)接,而且服務(wù)端也有副本復(fù)制的功能�。
12. 冷熱數(shù)據(jù)分離
將系統(tǒng)中產(chǎn)生的進(jìn)行歸類存放,將用戶更多關(guān)心�����、熱門話題等內(nèi)容
抽象為“最近幾天”的“熱數(shù)據(jù)”,而越早的數(shù)據(jù)我們?cè)谠O(shè)計(jì)中抽象的分為“冷數(shù)據(jù)”�����。由此可見����,“熱節(jié)點(diǎn)”存放最新的、被訪問頻率較高的數(shù)據(jù)�����。對(duì)于這部分?jǐn)?shù)據(jù)�����,我們希望能給用戶提供盡可能快的查詢速度����,因此無論在硬件還是軟件的選擇上都會(huì)有了明顯的區(qū)分,例如:最近常訪問頻率高的數(shù)據(jù)將會(huì)存儲(chǔ)在系統(tǒng)緩存中�����,需要經(jīng)常性被的業(yè)務(wù)數(shù)據(jù)將會(huì)存儲(chǔ)在MySQL或者Oracle數(shù)據(jù)庫系統(tǒng)中��,
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330