當(dāng)下,在線行為分析已并不罕見,但對整個音樂產(chǎn)業(yè)進行分析仍然不是一件容易的事情——你需要橫跨Spotify�、iTunes�、YouTube�����、
Facebook等眾多流行平臺進行相關(guān)跟蹤,其中包括近5億的音樂視頻流�、下載、藝術(shù)家頁面上產(chǎn)生的大量likes(每日)等���,這將給分析系統(tǒng)擴展性帶
來巨大的挑戰(zhàn)��。Next Big
Sound每天從100多個源中收集這些數(shù)據(jù)�,進行分析�,并通過基于網(wǎng)絡(luò)的分析平臺將這些信息提供給唱片公司、樂隊經(jīng)理及藝術(shù)家���。
時至今日,類似Hadoop���、
HBase��、Cassandra����、MongoDB���、RabbitMQ及MySQL這樣的開源系統(tǒng)已在生產(chǎn)環(huán)境中得到了廣泛應(yīng)用��,Next Big
Sound正是基于開源構(gòu)建���,然而Next Big
Sound的規(guī)模顯然更大了一些——從超過100個源接收或收集數(shù)據(jù)�。Eric團隊首先面臨的問題就是如何處理這些不停變化的數(shù)據(jù)源����,最終他們不得不自主
研發(fā)了一個存儲系統(tǒng),從根本上說是個可以“version”或者“branch”化從這些數(shù)據(jù)源上收集的數(shù)據(jù)�,類似GitHub上的代碼版本控制。
Next Big Sound通過給Cloudera發(fā)布版增加邏輯層來實現(xiàn)這個需求����,隨后將這個層與Apache Pig、
HBase�、Hive、HDFS等組件整合�,形成一個在Hadoop集群上海量數(shù)據(jù)的版本控制框架。
作為 “Moneyball for Music”一
員����,Next Big
Sound開始只是個運行在單服務(wù)器上的LAMP網(wǎng)站,為少量藝術(shù)家追蹤MySpace上的播放記錄����,用以建立Billboard人氣排行榜���,以及收集
Spotify上每首歌曲上產(chǎn)生的數(shù)據(jù)。隨著數(shù)據(jù)以近指數(shù)級速度的增長��,他們不得不選用了分布式系統(tǒng)���。同時��,為了跟蹤來自公共及私有提供者的100多個數(shù)
據(jù)源和不同性質(zhì)音樂的分析處理�����,Next Big Sound需要比當(dāng)下開源數(shù)據(jù)庫更優(yōu)秀的解決方案����。
Next Big Sound一直保持著非常小的工程團隊���,使用開源技術(shù)搭建整個系統(tǒng),采用過完全云架構(gòu)(Slicehost)���、混合云架構(gòu)(Rackspace)����、主機托管(Zcolo)等不同架構(gòu)形式。
統(tǒng)計
-
40個節(jié)點的Hadoop集群(150TB容量)�,約60個OpenStack虛擬機
-
10TB的非重復(fù)、已壓縮的數(shù)值型數(shù)據(jù)(6TB原始���、4TB索引)
-
10個工程師����,總計22人
-
5年的開發(fā)
-
每天30萬時間序列查詢
-
峰值期間每天400GB新數(shù)據(jù)
-
記錄百萬藝術(shù)家超過萬億的事件����,包括了YouTube音樂視頻訪問數(shù)、Twitter上轉(zhuǎn)發(fā)和@藝術(shù)家的數(shù)量��、iTunes購買數(shù)以及在線廣播流���。
平臺
-
托管:使用ZColo進行托管
-
操作系統(tǒng):虛擬和實體服務(wù)器都使用 Ubuntu 12.04 LTS
-
虛擬化:OpenStack(2x Dell R720計算節(jié)點���、96GB RAM、2x Intel 8-core CPU�����、5K SAS磁盤驅(qū)動器)
-
服務(wù)器:Dell R420、 32GB RAM����、4x 1TB 7.2K SATA數(shù)據(jù)磁盤, 2x Intel 4-core CPU
-
部署:Jenkins
-
Hadoop: Cloudera (CDH 4.3.0)
-
配置:Chef
-
監(jiān)視:Nagios、Ganglia���、Statsd + Graphite��、 Zenoss�、 Cube��、 Lipstick
-
數(shù)據(jù)庫:HBase���、MySQL�、MongoDB��、Cassandra(正在逐步使用HBase替代)
-
語言:數(shù)據(jù)收集和集成用PigLatin + Java����、數(shù)據(jù)分析使用Python + R + SQL��、PHP ( Codeigniter + Slim)��、JavaScript ( AngularJS + Backbone.js + D3)
-
處理:Impala、Pig����、Hive、 Oozie��、 RStudio
-
網(wǎng)絡(luò):Juniper(10Gig���、冗余核心層W/自動故障轉(zhuǎn)移���、機架上配備1 Gig接入交換機)
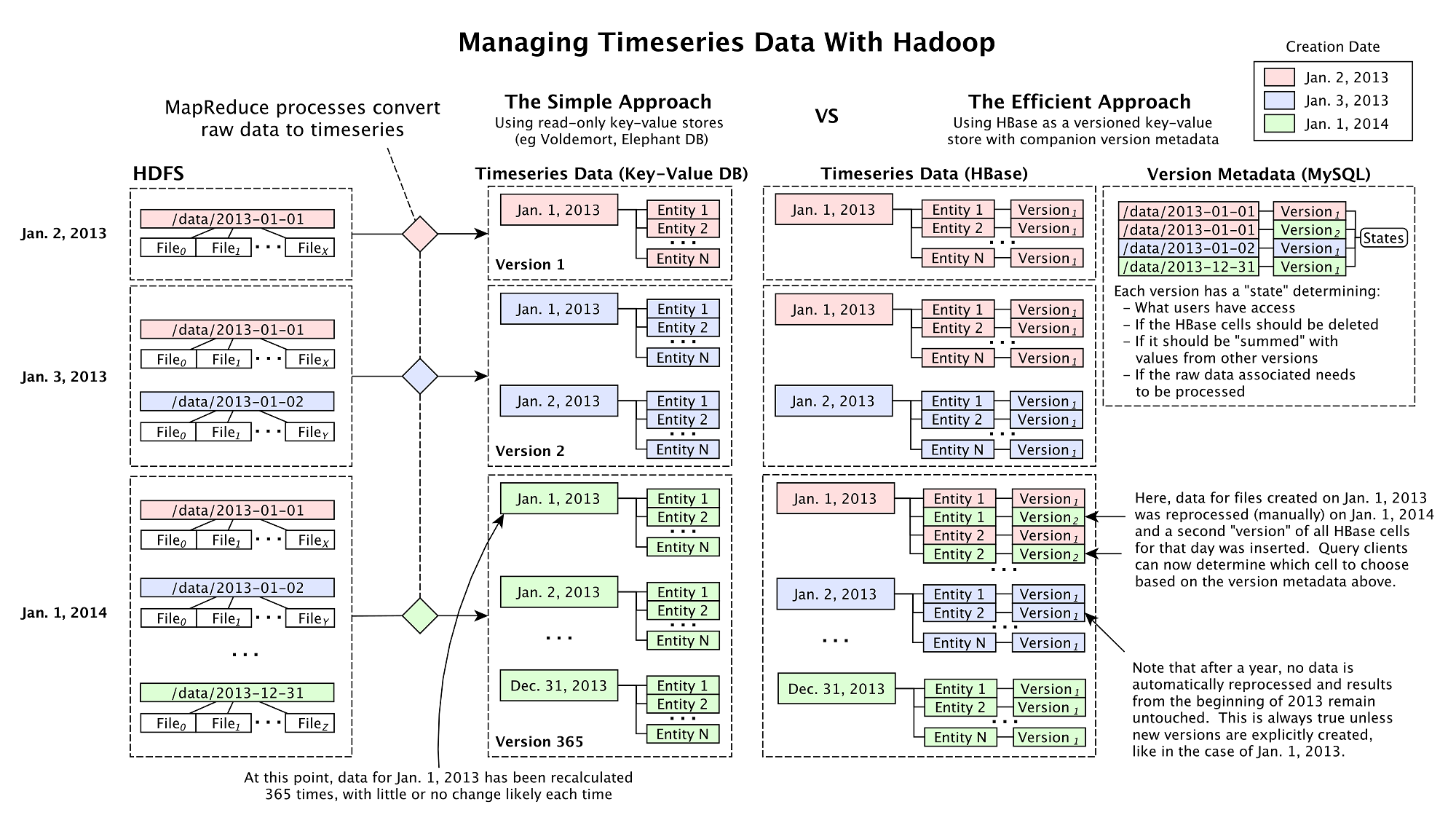
存儲架構(gòu)
使用類似Cassandra
及HBase這類分布式系統(tǒng)存儲時間序列是很容易的,然而�,隨著數(shù)據(jù)和數(shù)據(jù)源的暴增,數(shù)據(jù)管理變得不再容易�。傳統(tǒng)情況下,整合從100+數(shù)據(jù)源中搜集數(shù)據(jù)
的工作包含以下兩個步驟:首先�,在Hadoop
ETL管道對原始數(shù)據(jù)進行處理(使用MapReduce應(yīng)用、Pig或者Hive)��;其次����,將結(jié)果存儲到HBase以便后續(xù)Finagle/Thrift
服務(wù)的檢索。但是在Next Big
Sound,情況有了些不同���,所有存儲在Hadoop/HBase中的數(shù)據(jù)通過一個特殊的版本控制系統(tǒng)維護�,它支持ETL結(jié)果上的改動�,允許根據(jù)需求來修
改定義處理管道的代碼。
在對Hadoop數(shù)據(jù)進行再計算時����,使用“版本化”管理Hadoop數(shù)據(jù)提供了一個可恢
復(fù)及版本化途徑,擴展了許多數(shù)據(jù)處理周期技術(shù)(比如LinkedIn)����。而Next Big
Sound系統(tǒng)的區(qū)別在于可以配置版本化的等級,而不是必須在全局運行�,舉個例子:在記錄一個藝術(shù)家某個地理區(qū)域上tweet轉(zhuǎn)發(fā)次數(shù)的用例中,忽然發(fā)現(xiàn)
在某個時間段內(nèi)基于地理位置編碼的邏輯是錯誤的�,只需建立這個時間段的新數(shù)據(jù)集就可以了,從而避免了對整個數(shù)據(jù)集進行重建���。不同的數(shù)據(jù)通過版本進行關(guān)聯(lián)�,
也可以為某些用戶指定所訪問數(shù)據(jù)的版本�����,從而實現(xiàn)只有在數(shù)據(jù)精確時才對用戶釋放新的版本。類似這樣的“Branching”數(shù)據(jù)可以應(yīng)對數(shù)據(jù)源和客戶需求
的變化��,同時也可以讓數(shù)據(jù)管道更高效����。更多詳情查看下圖(點擊查看大圖):
在Hadoop
基礎(chǔ)設(shè)施方面���,同樣面臨了很多難題:1��,跨整個音樂產(chǎn)業(yè)的社交網(wǎng)絡(luò)和內(nèi)容發(fā)布網(wǎng)站的實體關(guān)系映射���;2,貫穿上千萬數(shù)據(jù)集建立用于排序和搜索的Web應(yīng)
用�����;3�����,管理數(shù)百萬API調(diào)用的信息以及網(wǎng)絡(luò)爬蟲����。這些操作都產(chǎn)生了特定的需求,而在Next Big
Sound,系統(tǒng)完全建立在開源技術(shù)之上����,下面是一個概況圖(點擊查看大圖):

數(shù)據(jù)顯示
測量儀表盤一直都是個進行中的項目,這個工作大部分由用戶需求主導(dǎo)�。由于數(shù)據(jù)源太多,這里的長期目標(biāo)是做靈活性和學(xué)習(xí)曲線之間的平衡�����;同時��,由于新客戶和特性的增加�����,維持一個連續(xù)的JavaScript/PHP代碼庫進行管理也變得愈加困難�����。Next Big Sound操作如下:
-
開始使用簡單的Codeigniter應(yīng)用��,盡可能的嘗試添加Backbone���,當(dāng)下已戰(zhàn)略性的轉(zhuǎn)向Angular�����。
-
使用Memcache緩存大型靜態(tài)對象�����。
-
度量數(shù)據(jù)的緩存和歷史記錄使用本地存儲�。
-
使用D3做圖��,之前使用的是Rickshaw��。
沒有做功能標(biāo)志�,但是使用了自己的方法。如果某個代碼庫經(jīng)常被重寫����,這點將非常重要,沒有它��,很多事情我們都完成不了��。
FIND
投
入大量精力做用戶基于給定條件的數(shù)據(jù)集搜索�����,這個功能被定義為“FIND”項目的預(yù)覽版本。類似股票篩選器�����,用戶可以做類似的查詢�。比如:Rap藝術(shù)家,
占YouTube視頻播放數(shù)的30-40百分位��,同時之前從未出現(xiàn)在任何流行排行榜上���。這個功能主要依賴于MongoDB�,在MapReduce作業(yè)提供
了大量索引集的情況下���,系統(tǒng)完全有能力以近實時速度完成數(shù)百萬實體上的查詢�。
MongoDB在這個用例上表現(xiàn)的非常好�����,然而其中一直存在索引限制問題�。Next Big Sound一直在挑戰(zhàn)這個瓶頸,ElasticSearch得到了重點關(guān)注����。
內(nèi)部服務(wù)
產(chǎn)品使用了所有度量數(shù)據(jù)��,API
由1個內(nèi)部Finagle服務(wù)支撐�����,從HBase和MySQL中讀取數(shù)據(jù)��。這個服務(wù)被分為多個層(同一個代碼運行)��,關(guān)鍵、低延時層通常直接被產(chǎn)品使用��,
一個具備更高吞吐量���、高延時的二級層則被用作編程客戶端��。后兩個方向一般具有更多的突發(fā)性和不可知性��,因此使用這樣的分離層可以給客戶交付更低的延時���。這
樣的分層同樣有利于為核心層建立更小的虛擬機,將Finagle剩余的服務(wù)器共至于Hadoop/HBase機器上����。
Next Big Sound API
支撐Next Big Sound內(nèi)外共同使用的主API已經(jīng)過多次迭代���,下面是一些重點建議:
-
不要建立一個只體現(xiàn)方法的API,建立一個模型化系統(tǒng)實體的API�,使用HTTP(GET、PUT��、POST����、HEAD、PATCH����、DELETE)處理這些實體行為,這樣會讓API更容易預(yù)測和實驗��。
-
對
于依賴實體關(guān)系的方法���,為主實體使用類似“字段”里的參數(shù)�,讓它提供重點關(guān)注的實體關(guān)系��。在Next Big
Sound�,這就意味著API將提供一個帶有“字段”參數(shù)的“藝術(shù)家”方法,如果這個字段被設(shè)置成“id�、name”��,那么將允許返回這個藝術(shù)家的姓名�����;
如果將這個字段設(shè)置成“id��、name�、profiles��、videos”�,那么將允許返回藝術(shù)家在YouTube頻道上的信息以及所有視頻。讀取實體之
間的關(guān)系可能有很大的開銷���,這種方法可以適當(dāng)?shù)谋苊鈹?shù)據(jù)庫查詢,并拋棄一些丑陋的組合方法�,比如“getArtistProfiles”或者
“getArtistVideos”。
-
使用外部API來建立應(yīng)用程序的好處已眾所周知���,但是在實踐的過程中還發(fā)現(xiàn)一些比較隱晦的益處�����,
比如給項目添加新Web工程師����。Next Big
Sound之前在API調(diào)用和JS代碼之間添加了一些PHP代碼,而現(xiàn)在則嚴(yán)格限制JavaScript和API之間的交互�。這就意味著Web開發(fā)者可以
專注于瀏覽器代碼,而在使用Backbone及Angular框架后更是如虎添翼�����。
提醒和基準(zhǔn)
在音樂的世界里隨時都有事情發(fā)生���,為了獲得“有意義”的事情����,Next Big Sound必須在所有平臺建立基準(zhǔn)數(shù)據(jù)(比如Facebook
每天產(chǎn)生like的數(shù)量)��,并提醒客戶�����。開始時也遇到過許多擴展性問題�����,但是在使用Pig/Hadoop做處理并將結(jié)果儲存在MongoDB或MySQL
后,事情簡單了起來����。Next Big
Sound所做的工作就是發(fā)現(xiàn)趨勢,那么給“有意義”設(shè)立臨界值就變得至關(guān)重要���,因此在做基準(zhǔn)時必須使用盡可能多的數(shù)據(jù)�����,而不是只從某個數(shù)據(jù)上入手����,與基
準(zhǔn)線的偏離量將代表了一切�����。
Billboard Charts
Next Big Sound被授權(quán)做兩個Billboard
雜志排行榜��,一個是藝術(shù)家在線流行指數(shù)總排行���,另一個是哪個藝術(shù)家可能會在未來排行榜上占據(jù)一席之地。這個功能并未造成任何擴展性問題�,因為只是做所有藝
術(shù)家得分的一個反向排行,但是制造一個無重復(fù)、有價值的列表顯然需要考慮更多因素����。非實名給系統(tǒng)帶來了大量麻煩(比如Justin
Bieber的Twitter用戶名到底是"justinbieber"、"bieber"及"bieberofficial"中的哪一個)����,通常情況
下,會采用機器和人工組合來解決這個問題��?�;?個人名的選錯會產(chǎn)生重大影響����,手動完成則必不可少。隨后發(fā)現(xiàn)�����,為在系統(tǒng)上增加這個“功能”��,即讓它記住類
似的處理方法并有能力重現(xiàn)將變得非常有效���,幸運的是���,這個系統(tǒng)實現(xiàn)難度并不大�。
預(yù)測Billboard得分
在
哪個藝術(shù)家將會在下一個年度爆發(fā)的預(yù)測上曾開發(fā)了一個專利算法��,這個過程應(yīng)用了Stochastic Gradient
Boosting技術(shù)�����,分析基于不同社交媒體成員的傳播能力�。在數(shù)學(xué)方面,實現(xiàn)難度比較大����,因為許多使用的工具都非Hadoop友好實現(xiàn),同時也發(fā)現(xiàn)
Mahout表現(xiàn)非常一般��。這里的處理過程包括輸入數(shù)據(jù)集��、通過MapReduce作業(yè)寫入MongoDB或者是Impala���,通過R-MongoDB或
者R-Impala來兼容R����,然后使用R的并行處理庫在大型機上處理�����,比如multicore���。讓Hadoop承擔(dān)大部分負(fù)載和大型機承擔(dān)剩余負(fù)載帶來了
很多局限性��,不幸的是�,暫時未發(fā)現(xiàn)更好的解決辦法�,或許RHadoop是最好的期望。
托管
1. 必須擁有自己的網(wǎng)絡(luò)解決方案�。如果你想從小的團隊開始,確保你團隊中有人精通這個���,如果沒有的話必須立刻雇傭��。這曾是Next Big Sound最大的痛點���,也是導(dǎo)致一些重大宕機的原因。
2. 在
不同的主機托管提供商之間轉(zhuǎn)移總是很棘手�,但是如果你有充足的額外預(yù)算去支付兩個環(huán)境運行主機的開銷,那么風(fēng)險將不會存在����。拋開一些不可避免的異常�����,在關(guān)
閉舊供應(yīng)商的服務(wù)之前��,將架構(gòu)完全復(fù)制到新服務(wù)供應(yīng)商�����,并做一些改進��。使用提供商服務(wù)往往伴隨著各種各樣的問題�����,對比因此耗費的工作及宕機時間來說��,資金
節(jié)省根本不值一提�����。
3. Next Big Sound有90%的工作負(fù)載都運行在
Hadoop/HBase上�,鑒于大部分的工作都是數(shù)據(jù)分析而非用戶帶訪問網(wǎng)站產(chǎn)生��,因此峰值出現(xiàn)的很少���,也就造成了使用提供商服務(wù)開銷很難比自己托管服
務(wù)器低的局面��。Next Big
Sound周期性的購買容量���,但是容量增加更意味著獲得了更大的客戶或者是數(shù)據(jù)合作伙伴,這也是為什么使用自己硬件可以每個月節(jié)省2萬美元的原因�。
經(jīng)驗
1. 如果你從很多的數(shù)據(jù)源中收集數(shù)據(jù),同時還需要做適度的轉(zhuǎn)換����,錯誤不可避免會發(fā)生。大多數(shù)情況下�����,這些錯誤都非常明顯��,在投入生產(chǎn)之前給予解決���;但是也有一些時候���,你需要做充足的準(zhǔn)備以應(yīng)對生產(chǎn)過程中發(fā)生的錯誤。下面是一些生產(chǎn)過程中發(fā)現(xiàn)的錯誤:
-
Twitter上藝術(shù)家TB級數(shù)據(jù)集的收集��,并在1到2天內(nèi)加載到數(shù)據(jù)庫。
-
為了證明自己應(yīng)對交期�,告訴客戶數(shù)據(jù)已經(jīng)可用。
-
(1個月的)等待��,為什么有20%的追隨者都在Kansas�,Bumblefuck?
-
地理名稱轉(zhuǎn)換代碼將“US”譯為國家的中部�。
-
因為客戶仍然在使用數(shù)據(jù)集正確的部分導(dǎo)致無法刪除,只能對之再加工��,并重新寫入數(shù)據(jù)庫�����,修改所有代碼讓之讀取兩個表格�����,只在新表格中沒有這條記錄時才讀取舊表格��,只在所有再處理結(jié)束后才可以刪除舊表格���。
-
近百行的套管程序�,直至幾天后�����,作業(yè)完成。
在這些情景下可能存在更明智的做法����,直到出現(xiàn)的次數(shù)足夠多����,你才會明確需要修改這些不能被完全刪除的生產(chǎn)數(shù)據(jù)并重建,這也是為什么Next Big Sound為之專門建立系統(tǒng)的原因�。
2. 多數(shù)的數(shù)據(jù)都使用Pig
建立并處理,幾乎所有的工程師都會使用它��。因此����,工程師們一直在致力研究Pig,這里不得不提到Netflix的Lipstick��,非常有效�����。這個過程中
還發(fā)現(xiàn)�����,取代可見性,降低Pig上開發(fā)迭代的時間也非常重要��。同時����,在測試之前,花時間為產(chǎn)生20+
Hadoop作業(yè)的長期運行腳本建立樣本輸入數(shù)據(jù)集也非常重要��。
3. 關(guān)于HBase和Cassandra����,在使用之前討論這兩個技術(shù)的優(yōu)劣純粹是浪費時間,只要弄懂這兩個技術(shù)��,它們都會提供一個穩(wěn)健且高效的平臺��。當(dāng)然�����,你必須基于自己的數(shù)據(jù)模型和使用場景在這兩個技術(shù)之間做選擇��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330