機(jī)器學(xué)習(xí)之深度學(xué)習(xí)
本文基于臺(tái)大機(jī)器學(xué)習(xí)技法系列課程進(jìn)行的筆記總結(jié)���。
一��、主要內(nèi)容

topic 1 深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)
從類神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)中我們已經(jīng)發(fā)現(xiàn)了神經(jīng)網(wǎng)絡(luò)中的每一層實(shí)際上都是對(duì)前一層進(jìn)行的特征轉(zhuǎn)換����,也就是特征抽取�。一般的隱藏層(hidden layer)較少的類神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)我們稱之為shallow,而當(dāng)隱藏層數(shù)比較多的類神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)我們稱之為deep�。如下圖所示:
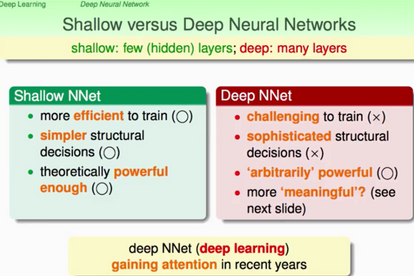
從兩者的對(duì)比中可以明顯發(fā)現(xiàn),隨著類神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的層數(shù)逐漸變多�����,由shallow轉(zhuǎn)向deep����,訓(xùn)練的效率會(huì)下降,結(jié)構(gòu)變得復(fù)雜����,那么對(duì)應(yīng)的能力(powerful)呢?實(shí)際上shallow的類神經(jīng)網(wǎng)絡(luò)已經(jīng)很強(qiáng)的powerful了���,那么多增加layer的目的到底是什么呢�����?是如何的更加富有意義(meaningful)呢���?且往下看:
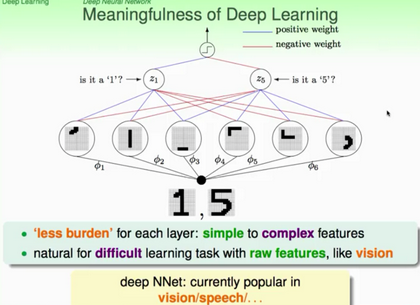
圖中所示的一個(gè)非常常見(jiàn)的問(wèn)題:識(shí)別手寫(xiě)體數(shù)字的模式識(shí)別問(wèn)題�。最原始的特征就是我們的原始數(shù)字化的圖像(raw
features:pixels)�����,從pixels出發(fā)�����,通過(guò)第一層的轉(zhuǎn)換我們可以得到一些稍微復(fù)雜一點(diǎn)點(diǎn)的features:筆畫(huà)特征��,然后我們?cè)儆蛇@些筆畫(huà)特征開(kāi)始輸入到下一層中�,就可以得到更加抽象的認(rèn)識(shí)特征(將像素組合成筆畫(huà),然后再由筆畫(huà)的組成去構(gòu)成對(duì)數(shù)字的認(rèn)識(shí)����,進(jìn)而識(shí)別數(shù)字)。上圖中可以看出�,數(shù)字1可以由第一層的左邊三個(gè)筆畫(huà)構(gòu)成,而數(shù)字5可以由第一層右邊四個(gè)筆畫(huà)構(gòu)成�,從第一層到第二層,鏈接權(quán)重紅色表示抑制�,藍(lán)色表示激勵(lì)����,其實(shí)就是模仿人類神經(jīng)元的工作機(jī)制(最簡(jiǎn)單的模仿:激勵(lì)和抑制)�����。那么這個(gè)手寫(xiě)體數(shù)字的模式識(shí)別問(wèn)題就可以通過(guò)這一層一層的類神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)得到解決����。但是問(wèn)題是��,類神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)如何確定�,模型復(fù)雜度如何評(píng)估(會(huì)不會(huì)overfitting呢),以及優(yōu)化的方式和計(jì)算復(fù)雜度的評(píng)估呢��?且看下圖總結(jié):

對(duì)于第一個(gè)問(wèn)題�,如何確定類神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu),可以通過(guò)domain knowledge來(lái)解決����,比如在圖像處理中應(yīng)用的卷積神經(jīng)網(wǎng)絡(luò),就是利用了像素在空間上的關(guān)系�。
對(duì)于第二個(gè)問(wèn)題,我們知道一個(gè)非常經(jīng)典的關(guān)系�,overfitting與模型復(fù)雜度��、數(shù)據(jù)量��、噪聲的關(guān)系:模型復(fù)雜度越大�����,數(shù)據(jù)量越小�,噪聲越大����,就越容易發(fā)生overfitting,反之亦然���。所以��,如果我們訓(xùn)練時(shí)候的數(shù)據(jù)量足夠大�����,就完全可以消弭由于模型復(fù)雜度帶來(lái)的overfitting的風(fēng)險(xiǎn)�。所以����,對(duì)于模型復(fù)雜度�,要保證足夠大的數(shù)據(jù)量���。當(dāng)然�,另外一種我們最熟悉的用來(lái)抑制模型復(fù)雜度的工具就是regularization��,通過(guò)對(duì)噪聲的容忍(noise-tolerant)對(duì)象不同可以有兩種regularization的方式:對(duì)網(wǎng)絡(luò)節(jié)點(diǎn)退化可以容忍的dropout以及對(duì)輸入數(shù)據(jù)退化可以容忍的denoising��,都表現(xiàn)在對(duì)噪聲的抑制��。所以���,第二個(gè)問(wèn)題可以通過(guò)在數(shù)據(jù)量上的保證和對(duì)噪聲的抑制來(lái)解決。
對(duì)于第三個(gè)問(wèn)題��,deep
learning的layer越多���,權(quán)重也就越多���,在進(jìn)行優(yōu)化的時(shí)候就更加容易出現(xiàn)局部最優(yōu),因?yàn)樽兞慷嗔?��,想象一下���,似乎連綿起伏的山一樣����,局部最優(yōu)的情況也就更加容易發(fā)生����。那么如果克服發(fā)生局部最優(yōu)的優(yōu)化問(wèn)題呢?可以通過(guò)一個(gè)叫做pre-training的方法,慎重的對(duì)權(quán)重進(jìn)行初始化����,使得權(quán)重一開(kāi)始就出現(xiàn)在全局最優(yōu)的那個(gè)“山峰”上,然后通過(guò)梯度下降或者隨機(jī)梯度的方式往下滾����,直到全局最優(yōu)。所以�����,這個(gè)pre-training就可以克服局部最優(yōu)的問(wèn)題���,后面也將是我們講解的一個(gè)重點(diǎn)�����。
對(duì)于第四個(gè)問(wèn)題��,計(jì)算的復(fù)雜度是與deep learning的結(jié)構(gòu)復(fù)雜度正相關(guān)的�,但是不用擔(dān)心,一個(gè)強(qiáng)有力的硬件支持或者架構(gòu)支持已經(jīng)被用來(lái)進(jìn)行深度神經(jīng)網(wǎng)絡(luò)的訓(xùn)練和計(jì)算���,那就是GPU或FPGA這種可以進(jìn)行大量的硬件上的并行計(jì)算的處理器���。所以第四個(gè)問(wèn)題只要通過(guò)選擇專用的硬件平臺(tái)就可以解決。
那么四個(gè)問(wèn)題都加以了分析和解決�����,我們下面的重點(diǎn)在于pre-training的機(jī)制�����,如何獲得較好的網(wǎng)絡(luò)初始值呢���?
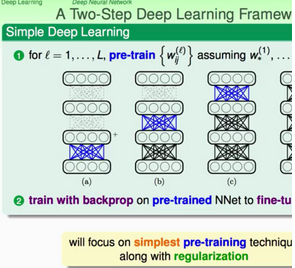
上圖就是典型的深度神經(jīng)網(wǎng)絡(luò)的訓(xùn)練過(guò)程,先通過(guò)pre-training進(jìn)行網(wǎng)絡(luò)參數(shù)的初始設(shè)置�����,然后再通過(guò)第二步利用誤差回傳機(jī)制對(duì)網(wǎng)絡(luò)參數(shù)進(jìn)行調(diào)優(yōu)(fine-tune)。
那么這個(gè)pre-training的具體是如何進(jìn)行的呢���?實(shí)際上就是如上圖所示���,每次只進(jìn)行兩層之間的參數(shù)訓(xùn)練,確定之后再往其緊接著的上面兩層參數(shù)進(jìn)行訓(xùn)練�����,就這樣逐層的訓(xùn)練�。那么訓(xùn)練的機(jī)制呢?就是今天的第二個(gè)topic���,autoencoder��,自動(dòng)編碼器����。
topic 2 自動(dòng)編碼器
那么我們看���,自動(dòng)編碼器是如何實(shí)現(xiàn)的�。在這之前,先說(shuō)明一個(gè)概念:information
preserving�,就是信息保持,我們?cè)趯优c層之間的進(jìn)行的特征轉(zhuǎn)換實(shí)際上就是一個(gè)編碼的過(guò)程�,那么一個(gè)好的編碼就是能夠做到information
preserving。所以一個(gè)好的特征轉(zhuǎn)換就是轉(zhuǎn)換后的特征能夠最大限度地保留原始信息�,而不至于使得信息變得面目全非。轉(zhuǎn)換后的特征是raw
features的一個(gè)好的representation�。且看下圖:
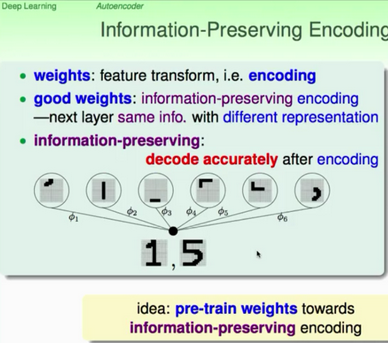
我們還以原來(lái)的手寫(xiě)體數(shù)字的識(shí)別為例,將原始特征(raw
features����,pixels)轉(zhuǎn)換為筆畫(huà)特征是一個(gè)好的特征轉(zhuǎn)換嗎?能夠保持原始信息嗎��?那么如何衡量這個(gè)信息是不是丟失了呢����?自然而然就想到了,我把數(shù)字1的轉(zhuǎn)化成了筆畫(huà)�����,那么這些筆畫(huà)能不能重新組合表示為數(shù)字1呢���?根據(jù)上面的介紹,我們可以做到從1到筆畫(huà),然后還可以從筆畫(huà)再到1的過(guò)程�����。這就是很好的信息保持(information
preserving)�����。那么根據(jù)這種由輸入通過(guò)一層hidden
layer����,然后再轉(zhuǎn)變?yōu)檩斎氲臋C(jī)制去評(píng)估信息保持的效果,去衡量特征轉(zhuǎn)化的品質(zhì)����。那么就得到以下的一個(gè)訓(xùn)練機(jī)制,且看下圖:
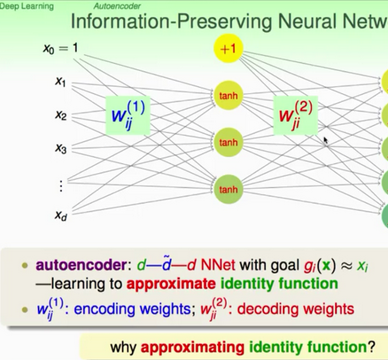
這就是我們要將的pre-training的機(jī)制�����。由輸入經(jīng)編碼權(quán)重得到原始數(shù)據(jù)的特征轉(zhuǎn)換��,然后再由特征轉(zhuǎn)換經(jīng)解碼權(quán)重得到原始數(shù)據(jù)的機(jī)制����。整個(gè)映射實(shí)際上就是一個(gè)identity function�,因?yàn)檩敵?輸入嘛�����!

那么實(shí)際上我們?cè)O(shè)計(jì)的這個(gè)訓(xùn)練過(guò)程能夠應(yīng)用到監(jiān)督學(xué)習(xí)和非監(jiān)督學(xué)習(xí)��。對(duì)于監(jiān)督學(xué)習(xí)��,我們可以用來(lái)學(xué)習(xí)數(shù)據(jù)的informative
representation����,hidden layer的輸出就是。對(duì)于非監(jiān)督學(xué)習(xí)�����,我們可以用來(lái)進(jìn)行密度估計(jì)(density
estimation):當(dāng)g(x)≈x時(shí)的x處的密度更大�����;還可以用來(lái)進(jìn)行outlier檢測(cè):那些g(x)與x相差遠(yuǎn)的x就可以作為outlier�����。那些g(x)≈x的隱藏層輸出��,能夠作為x的典型表示(typical
representation)。
因此�����,一個(gè)基本的autoencoder的完整流程就有了�,且看下圖:

因?yàn)樯厦娼忉尩木捅容^多了����,下面就不再對(duì)這個(gè)流程進(jìn)行詳細(xì)說(shuō)明。一個(gè)需要點(diǎn)出的就是使得編碼權(quán)重Wij與解碼權(quán)重Wji相等可以用來(lái)作為一種形式的regularization�����。而整個(gè)訓(xùn)練一層一層的進(jìn)行實(shí)際上就是一個(gè)只有兩層的類神經(jīng)網(wǎng)絡(luò)�����,進(jìn)行誤差回傳和梯度下降計(jì)算的復(fù)雜度都不會(huì)很大����。
有了pre-training,于是乎我們的deep learning的過(guò)程就變成了下圖:
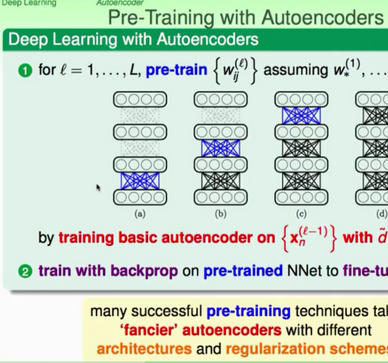
上面講完了通過(guò)pre-training得到較好的初始權(quán)重��,以便于整個(gè)deep learning能夠在開(kāi)始訓(xùn)練的時(shí)候就站在一個(gè)非常好的位置�����,即在一定程度上避免由于模型結(jié)構(gòu)復(fù)雜度導(dǎo)致的overfitting發(fā)生的風(fēng)險(xiǎn)。由此引出的autoencoder��。
那么前面講為了克服overfitting的風(fēng)險(xiǎn)���,還可以從另一個(gè)角度:noise的角度出發(fā)���。下面我們就進(jìn)行denoising autoencoder的相關(guān)內(nèi)容。
topic 3 去噪自動(dòng)編碼器
在類神經(jīng)網(wǎng)絡(luò)中其實(shí)已經(jīng)介紹過(guò)一些用于regularization的方法�,比如通過(guò)限制模型輸出的精度、權(quán)重的消減或者提前終止訓(xùn)練等���,那么下面介紹的是一種比較另類的regularization的方法�����。
上面說(shuō)了���,基于消除噪聲的方式,一般直接的想法或者常用的是data
cleaning/pruning���,那么我們這里介紹的也不是這種常規(guī)的方法����,而是一種反向思維的方式:如果我直接往輸入數(shù)據(jù)中加入人工的噪聲呢?會(huì)發(fā)生什么樣的情況��。這就是我們下面要探討的去噪自動(dòng)編碼器�����。
這種往input中添加噪聲的思維是以robustness健壯性出發(fā)的���,試想如果我加完噪聲后的數(shù)據(jù)作為輸入,經(jīng)過(guò)編碼和解碼后���,如果輸出依然等于加入噪聲前的數(shù)據(jù)����,這樣的類神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)是不是非常的穩(wěn)健���,也就說(shuō)抗干擾能力很強(qiáng)���。基于此想法�����,我們就得到denoising
autoencoder的方法,且看下圖

所以輸入時(shí)x+人工噪聲���,標(biāo)簽是x���,這樣來(lái)對(duì)網(wǎng)絡(luò)進(jìn)行訓(xùn)練,這樣的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)自然就具備了denosing的效果���。
topic 4 線性自動(dòng)編碼器與主成分分析
所以前面講的都是直接基于非線性映射的結(jié)構(gòu)�����,而一般上我們常常是先通過(guò)線性的解釋��,然后再拓展至非線性��。那么我們看看線性自動(dòng)編碼器是怎樣的���,看下圖:
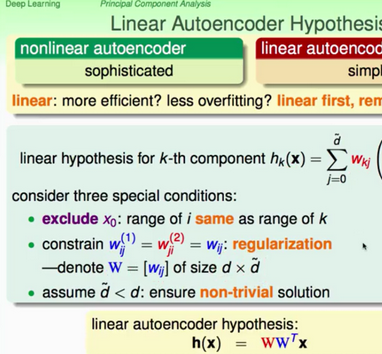
我們依然通過(guò)平方誤差進(jìn)行推導(dǎo),推導(dǎo)過(guò)程見(jiàn)下圖�,總之就是一堆矩陣的運(yùn)算,如果學(xué)過(guò)矩陣分析課程看起來(lái)并不復(fù)雜,實(shí)際上就是進(jìn)行譜分解���,看不懂也沒(méi)關(guān)系����,只要知道處理過(guò)程就好��,求輸入矩陣的最大特征值和其對(duì)應(yīng)的特征向量���,實(shí)際上這也是PCA處理的過(guò)程(PCA基于matlab的代碼鏈接,小弟資源分不夠���,求個(gè)資源分勿怪)���。

那么實(shí)際上,linear 的autoencoder實(shí)際上與主成分分析是非常相近的���,只不過(guò)主成分分析具有統(tǒng)計(jì)學(xué)的說(shuō)明�。進(jìn)行特征轉(zhuǎn)換后的方差要大��。我們把數(shù)據(jù)進(jìn)行零均值化作為autoencoder的輸入�,結(jié)果就跟PCA一樣了。具體的關(guān)系可以看下圖說(shuō)明:

*************************************************************************************************************************************
通過(guò)以上的介紹,相信對(duì)整個(gè)deep learning的架構(gòu)有了一定認(rèn)識(shí)�����,當(dāng)然這里面介紹的大部分都是入門(mén)級(jí)的知識(shí)����,不過(guò)有了一個(gè)guideline之后,再去對(duì)更加細(xì)節(jié)的設(shè)計(jì)方法進(jìn)行學(xué)習(xí)時(shí)就能有更加宏觀方向的把握���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情��;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330