機(jī)器學(xué)習(xí)模型評(píng)價(jià)(Evaluating Machine Learning Models)-主要概念與陷阱
本文主要解釋一些關(guān)于機(jī)器學(xué)習(xí)模型評(píng)價(jià)的主要概念,與評(píng)價(jià)中可能會(huì)遇到的一些陷阱�����。如訓(xùn)練集-驗(yàn)證集二劃分校驗(yàn)(Hold-out
validation)����、交叉校驗(yàn)(Cross-validation)、超參數(shù)調(diào)優(yōu)(hyperparameter
tuning)等����。這三個(gè)術(shù)語都是從不同的層次對(duì)機(jī)器學(xué)習(xí)模型進(jìn)行校驗(yàn)。Hold-out
validation與Cross-validation是將模型能夠更好得對(duì)將來的數(shù)據(jù)(unseen
data)進(jìn)行擬合而采用的方法��。Hyperparameter tuning是一種模型選擇方法�。
??機(jī)器學(xué)習(xí)是一門跨學(xué)科領(lǐng)域,涉及到統(tǒng)計(jì)學(xué)�����、計(jì)算機(jī)科學(xué)、最優(yōu)化理論���、信息理論、神經(jīng)科學(xué)�����、理論物理以及其他領(lǐng)域�。同時(shí),機(jī)器學(xué)習(xí)也是一門非常年輕的學(xué)科����。機(jī)器學(xué)習(xí)的大規(guī)模應(yīng)用僅僅開始于過去二十年。當(dāng)今��,數(shù)據(jù)科學(xué)應(yīng)用已成為一種職業(yè)����。就像西部開發(fā)一樣,擁有則無盡的機(jī)會(huì)�����,同時(shí)也有伴隨著很多迷惑與問題���。
??本文將從以下部分對(duì)機(jī)器學(xué)習(xí)模型的評(píng)價(jià)進(jìn)行介紹:
* 介紹模型離線與在線評(píng)價(jià)體系與知識(shí)��;
* 介紹一些不同類別下得機(jī)器學(xué)習(xí)模型評(píng)價(jià)指標(biāo)��,如分類回歸���、排序等�。
* 介紹訓(xùn)練目標(biāo)�����、模型驗(yàn)證指標(biāo)的區(qū)別
* 介紹解決數(shù)據(jù)傾斜的一些方法以及模型參數(shù)調(diào)優(yōu)的方法
* 最后介紹一些工具����,如GraphLab與Dato等。
機(jī)器學(xué)習(xí)Workflow
一般的���,機(jī)器學(xué)習(xí)過程包括兩個(gè)階段���,分別為:原型設(shè)計(jì)階段(Prototyping)與應(yīng)用階段(Deployed),與軟件開發(fā)類似的Debug與Release階段����。如下圖所示:

Prototyping階段是使用歷史數(shù)據(jù)訓(xùn)練一個(gè)適合解決目標(biāo)任務(wù)的一個(gè)或多個(gè)機(jī)器學(xué)習(xí)模型�,并對(duì)模型進(jìn)行驗(yàn)證(Validation)與離線評(píng)估(Offline
evalutation)�����,然后通過評(píng)估指標(biāo)選擇一個(gè)較好的模型�。如在分類任務(wù)中,選擇一個(gè)適合自己問題的最好的分類算法���。Deployed階段是當(dāng)模型達(dá)到設(shè)定的指標(biāo)值時(shí)便將模型上線,投入生產(chǎn)���,使用新生成的數(shù)據(jù)來對(duì)該模型進(jìn)行在線評(píng)估(Online
evalution)�����,以及使用新數(shù)據(jù)更新模型��。在對(duì)模型進(jìn)行離線評(píng)估或者在線評(píng)估時(shí)����,它們所用的評(píng)價(jià)指標(biāo)往往不同���。如在離線評(píng)估中�����,我們精彩使用的有準(zhǔn)確率(accuracy)�����、精確率-召回率(precision-recall)�,而在在線評(píng)估中,一般使用一些商業(yè)評(píng)價(jià)指標(biāo)���,如用戶生命周期值(customer
lifetime value)���、廣告點(diǎn)擊率(click through rate)、用戶流失率(customer churn
rate)等��,這些指標(biāo)才是模型使用者最終關(guān)心的一些指標(biāo)��。甚至在對(duì)模型進(jìn)行訓(xùn)練和驗(yàn)證過程中使用的評(píng)價(jià)指標(biāo)都不一樣��。
??同時(shí)我們注意到����,在這兩個(gè)階段使用的數(shù)據(jù)集也不一樣,分別是歷史數(shù)據(jù)(historical data)與新數(shù)據(jù)(live
data)����。在機(jī)器學(xué)習(xí)中����,很多模型都是假設(shè)數(shù)據(jù)的分布是一定的���,不變的�����,即歷史數(shù)據(jù)與將來的數(shù)據(jù)都服從相同的分布。但是�,在現(xiàn)實(shí)生活中,這種假設(shè)往往是不成立的���,即數(shù)據(jù)的分布會(huì)隨著時(shí)間的移動(dòng)而改變�����,有時(shí)甚至變化得很急劇����,這種現(xiàn)象稱為分布漂移(Distribution
Drift)��。例如����,在文章推薦系統(tǒng)中,文章的主題集數(shù)目和主題的發(fā)生頻率可能是每天改變的,甚至每個(gè)小時(shí)都在改變,昨天流行的主題在今天可能就不再流行了���。如在新聞推薦中,新聞主題就變更得非?��?臁R虼嗽谶M(jìn)行模型構(gòu)建之時(shí),我們需要去撲捉分布漂移信息并使自己的模型能夠應(yīng)對(duì)這種情況�����。一個(gè)常用的方法便是使用一些驗(yàn)證指標(biāo)對(duì)模型在不斷新生的數(shù)據(jù)集上進(jìn)行性能跟蹤。如果指標(biāo)值能夠達(dá)到模型構(gòu)建時(shí)的指標(biāo)值�,那么表示模型能夠繼續(xù)對(duì)當(dāng)前數(shù)據(jù)進(jìn)行擬合�。當(dāng)性能開始下降時(shí)���,說明該模型已經(jīng)無法擬合當(dāng)前的數(shù)據(jù)了,因此需要對(duì)模型進(jìn)行重新訓(xùn)練了�。
??不同的機(jī)器學(xué)習(xí)任務(wù)有著不同的性能評(píng)價(jià)指標(biāo)����。例如���,在垃圾郵件檢測系統(tǒng)中�,它本身是一個(gè)二分類問題(垃圾郵件vs正常郵件)���,可以使用準(zhǔn)確率(Accuracy)��、對(duì)數(shù)損失函數(shù)(log-loss)�����、AUC等評(píng)價(jià)方法����。又如在股票預(yù)測中,它本身是一個(gè)實(shí)數(shù)序列數(shù)據(jù)預(yù)測問題�,可以使用平方根誤差(root
mean square error, RMSE)等指標(biāo)�;又如在搜索引擎中進(jìn)行與查詢相關(guān)的項(xiàng)目排序中,可以使用精確率-召回率(precision-recall)����、NDCG(normalized discounted cumulative gain)。
??正如前面所提到的那樣�����,在原型階段中最重要的任務(wù)便是選擇一個(gè)正確的適合的模型對(duì)數(shù)據(jù)進(jìn)行擬合���。而當(dāng)模型訓(xùn)練完畢后���,我們需要使用一個(gè)與訓(xùn)練數(shù)據(jù)集獨(dú)立的新的數(shù)據(jù)集去對(duì)模型進(jìn)行驗(yàn)證。因?yàn)槟P捅旧砭褪鞘褂糜?xùn)練數(shù)據(jù)集訓(xùn)練出來的��,因此它已經(jīng)對(duì)訓(xùn)練集進(jìn)行了很好的擬合�,但是它在新的數(shù)據(jù)集上的效果則有待驗(yàn)證,因此需要使用新的與訓(xùn)練集獨(dú)立的數(shù)據(jù)集對(duì)模型進(jìn)行訓(xùn)練�,確保該模型在新的數(shù)據(jù)集上也能夠滿足要求。模型能夠?qū)π碌臄?shù)據(jù)也能work稱為模型的泛化能力���。
??那么新的數(shù)據(jù)集如何得來呢���?一般的解決方法是將已有的數(shù)據(jù)集隨機(jī)劃分成兩個(gè)個(gè)部分,一個(gè)用來訓(xùn)練模型�����,另一個(gè)用來驗(yàn)證與評(píng)估模型�����。另一種方法是重采樣,即對(duì)已有的數(shù)據(jù)集進(jìn)行有放回的采樣�,然后將數(shù)據(jù)集隨機(jī)劃分成兩個(gè)部分,一個(gè)用來訓(xùn)練�,一個(gè)用來驗(yàn)證。至于具體的做法有hold-out
validation���、k-fold cross-validation�����、bootstrapping與jackknife
resampling����,后面會(huì)進(jìn)行詳細(xì)介紹����。
??機(jī)器學(xué)習(xí)模型建立過程其實(shí)是一個(gè)參數(shù)學(xué)習(xí)與調(diào)優(yōu)的過程。對(duì)模型進(jìn)行訓(xùn)練�����,便是模型參數(shù)的學(xué)習(xí)更新過程��。模型出了這些常規(guī)參數(shù)之外����,還存在超參數(shù)(hyperparameters)�����。它們之間有何區(qū)別呢?簡而言之����,模型參數(shù)使指通過模型訓(xùn)練中的學(xué)習(xí)算法而進(jìn)行調(diào)整的,而模型超參數(shù)不是通過學(xué)習(xí)算法而來的����,但是同樣也需要進(jìn)行調(diào)優(yōu)。舉例�,我們?cè)趯?duì)垃圾郵件檢測進(jìn)行建模時(shí),假設(shè)使用logistic回歸��。那么該任務(wù)就是在特征空間中尋找能夠?qū)⒗]件與正常郵件分開的logistic函數(shù)位置�,于是模型訓(xùn)練的學(xué)習(xí)算法便是得到各個(gè)特征的權(quán)值,從而決定函數(shù)的位置�。但是該學(xué)習(xí)算法不會(huì)告訴我們對(duì)于該任務(wù)需要使用多少個(gè)特征來對(duì)一封郵件進(jìn)行表征,特征的數(shù)目這個(gè)參數(shù)便是該模型的超參數(shù)����。
??超參數(shù)的調(diào)優(yōu)是一個(gè)相當(dāng)復(fù)雜與繁瑣的任務(wù)��。在模型原型設(shè)計(jì)階段����,需要嘗試不同的模型���、不同的超參數(shù)意見不同的特征集����,我們需要尋找一個(gè)最優(yōu)的超參數(shù)�����,因此需要使用相關(guān)的搜索算法去尋找�����,如格搜索(grid
search)��、隨機(jī)搜索(random search)以及啟發(fā)式搜索(smart
search)等����。這些搜索算法是從超參數(shù)空間中尋找一個(gè)最優(yōu)的值。本文后面會(huì)進(jìn)行詳細(xì)介紹����。
??當(dāng)模型使用離線數(shù)據(jù)訓(xùn)練好并滿足要求后�,就需要將模型使用新的在線數(shù)據(jù)進(jìn)行上線測試��,這就是所謂的在線測試�。在線測試不同于離線測試,有著不同的測試方法以及評(píng)價(jià)指標(biāo)���。最常見的便是A/B
testing,它是一種統(tǒng)計(jì)假設(shè)檢驗(yàn)方法����。不過,在進(jìn)行A/B
testing的時(shí)候���,會(huì)遇到很多陷阱與挑戰(zhàn)���,具體會(huì)在本文后面進(jìn)行詳細(xì)介紹。另一個(gè)相對(duì)使用較小的在線測試方法是multiarmed
bandits�。在某些情況下,它比A/B testing的效果要好���。后面會(huì)進(jìn)行具體講解���。
評(píng)價(jià)指標(biāo)(Evaluation metrics)
評(píng)價(jià)指標(biāo)是機(jī)器學(xué)習(xí)任務(wù)中非常重要的一環(huán)���。不同的機(jī)器學(xué)習(xí)任務(wù)有著不同的評(píng)價(jià)指標(biāo),同時(shí)同一種機(jī)器學(xué)習(xí)任務(wù)也有著不同的評(píng)價(jià)指標(biāo)�,每個(gè)指標(biāo)的著重點(diǎn)不一樣。如分類(classification)�����、回歸(regression)��、排序(ranking)��、聚類(clustering)��、熱門主題模型(topic
modeling)�����、推薦(recommendation)等�����。并且很多指標(biāo)可以對(duì)多種不同的機(jī)器學(xué)習(xí)模型進(jìn)行評(píng)價(jià),如精確率-召回率(precision-recall)���,可以用在分類����、推薦����、排序等中。像分類��、回歸�、排序都是監(jiān)督式機(jī)器學(xué)習(xí)��,本文的重點(diǎn)便是監(jiān)督式機(jī)器學(xué)習(xí)的一些評(píng)價(jià)指標(biāo)���。
分類評(píng)價(jià)指標(biāo)
分類是指對(duì)給定的數(shù)據(jù)記錄預(yù)測該記錄所屬的類別���。并且類別空間已知。它包括二分類與多分類�,二分類便是指只有兩種類別,如垃圾郵件分類中便是二分類問題����,因?yàn)轭悇e空間只有垃圾郵件和非垃圾郵件這兩種���,可以稱為“負(fù)”(negative)與正(positive)兩種類別,一般在實(shí)際計(jì)算中���,將其映射到“0”-“1”
class中�����;而多分類則指類別數(shù)超過兩種��。下面主要根據(jù)二分類的評(píng)價(jià)指標(biāo)進(jìn)行講解��,不過同時(shí)它們也可擴(kuò)展到多分類任務(wù)中�。下面對(duì)分類中一些常用的評(píng)價(jià)指標(biāo)進(jìn)行介紹�����。
準(zhǔn)確率(Accuracy)
準(zhǔn)確率是指在分類中��,使用測試集對(duì)模型進(jìn)行分類����,分類正確的記錄個(gè)數(shù)占總記錄個(gè)數(shù)的比例:
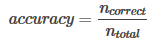
??準(zhǔn)確率看起來非常簡單。然而,準(zhǔn)確率評(píng)價(jià)指標(biāo)沒有對(duì)不同類別進(jìn)行區(qū)分�����,即其平等對(duì)待每個(gè)類別�。但是這種評(píng)價(jià)有時(shí)是不夠的,比如有時(shí)要看類別0與類別1下分類錯(cuò)誤的各自個(gè)數(shù)�����,因?yàn)椴煌悇e下分類錯(cuò)誤的代價(jià)不同��,即對(duì)不同類別的偏向不同�����,比如有句話為“寧可錯(cuò)殺一萬�����,不可放過一千“就是這個(gè)道理�,例如在病患診斷中���,診斷患有癌癥實(shí)際上卻未患癌癥(False
Positive)與診斷未患有癌癥的實(shí)際上卻患有癌癥(False
Negative)的這兩種情況的重要性不一樣��。���。另一個(gè)原因是�����,可能數(shù)據(jù)分布不平衡�,即有的類別下的樣本過多��,有的類別下的樣本個(gè)數(shù)過少���,兩類個(gè)數(shù)相差較大���。這樣,樣本占大部分的類別主導(dǎo)了準(zhǔn)確率的計(jì)算��,為了解決這個(gè)問題�,對(duì)準(zhǔn)確率進(jìn)行改進(jìn),得到平均準(zhǔn)確率��。
平均準(zhǔn)確率(Average Per-class Accuracy)
為了應(yīng)對(duì)每個(gè)類別下樣本的個(gè)數(shù)不一樣的情況��,對(duì)準(zhǔn)確率進(jìn)行變種�,計(jì)算每個(gè)類別下的準(zhǔn)確率���,然后再計(jì)算它們的平均值。舉例��,類別0的準(zhǔn)確率為80%�����,類別1下的準(zhǔn)確率為97.5%����,那么平均準(zhǔn)確率為(80%+97.5%)/2=88.75%。因?yàn)槊總€(gè)類別下類別的樣本個(gè)數(shù)不一樣�,即計(jì)算每個(gè)類別的準(zhǔn)確率時(shí),分母不一樣��,則平均準(zhǔn)確率不等于準(zhǔn)確率�,如果每個(gè)類別下的樣本個(gè)數(shù)一樣,則平均準(zhǔn)確率與準(zhǔn)確率相等��。
??平均準(zhǔn)確率也有自己的缺點(diǎn)�,比如����,如果存在某個(gè)類別���,類別的樣本個(gè)數(shù)很少,那么使用測試集進(jìn)行測試時(shí)(如k-fold cross validation)��,可能造成該類別準(zhǔn)確率的方差過大���,意味著該類別的準(zhǔn)確率可靠性不強(qiáng)���。
對(duì)數(shù)損失函數(shù)(Log-loss)
在分類輸出中,若輸出不再是0-1���,而是實(shí)數(shù)值�����,即屬于每個(gè)類別的概率��,那么可以使用Log-loss對(duì)分類結(jié)果進(jìn)行評(píng)價(jià)�。這個(gè)輸出概率表示該記錄所屬的其對(duì)應(yīng)的類別的置信度�����。比如如果樣本本屬于類別0�,但是分類器則輸出其屬于類別1的概率為0.51����,那么這種情況認(rèn)為分類器出錯(cuò)了�。該概率接近了分類器的分類的邊界概率0.5。Log-loss是一個(gè)軟的分類準(zhǔn)確率度量方法��,使用概率來表示其所屬的類別的置信度����。Log-loss具體的數(shù)學(xué)表達(dá)式為:
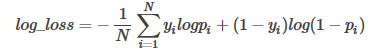
其中,yi是指第i個(gè)樣本所屬的真實(shí)類別0或者1���,pi表示第i個(gè)樣本屬于類別1的概率����,這樣上式中的兩個(gè)部分對(duì)于每個(gè)樣本只會(huì)選擇其一���,因?yàn)橛幸粋€(gè)一定為0����,當(dāng)預(yù)測與實(shí)際類別完全匹配時(shí)�����,則兩個(gè)部分都是0��,其中假定0log0=0����。
??其實(shí),從數(shù)學(xué)上來看���,Log-loss的表達(dá)式是非常漂亮的����。我們仔細(xì)觀察可以發(fā)現(xiàn)���,其信息論中的交叉熵(Cross
Entropy�����,即真實(shí)值與預(yù)測值的交叉熵)���,它與相對(duì)熵(Relative Entropy,也稱為KL距離或KL散度�,
Kullback–Leibler
divergence.)也非常像。信息熵是對(duì)事情的不確定性進(jìn)行度量��,不確定越大,熵越大��。交叉熵包含了真實(shí)分布的熵加上假設(shè)與真實(shí)分布不同的分布的不確定性�。因此,log-loss是對(duì)額外噪聲(extra
noise)的度量����,這個(gè)噪聲是由于預(yù)測值域?qū)嶋H值不同而產(chǎn)生的。因此最小化交叉熵�,便是最大化分類器的準(zhǔn)確率。
精確率-召回率(Precision-Recall)
精確率-召回率其實(shí)是兩個(gè)評(píng)價(jià)指標(biāo)�。但是它們一般都是同時(shí)使用。精確率是指分類器分類正確的正樣本的個(gè)數(shù)占該分類器所有分類為正樣本個(gè)數(shù)的比例����。召回率是指分類器分類正確的正樣本個(gè)數(shù)占所有的正樣本個(gè)數(shù)的比例。
F1-score:
F1-score為精確率與召回率的調(diào)和平均值�,它的值更接近于Precision與Recall中較小的值。即:
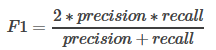
AUC(Area under the Curve(Receiver Operating Characteristic, ROC))
AUC的全稱是Area under the Curve���,即曲線下的面積�����,這條曲線便是ROC曲線��,全稱為the Receiver
Operating Characteristic曲線����,它最開始使用是上世紀(jì)50年代的電信號(hào)分析中�����,在1978年的“Basic
Principles of ROC Analysis ”開始流行起來�。ROC曲線描述分類器的True Positive
Rate(TPR,分類器分類正確的正樣本個(gè)數(shù)占總正樣本個(gè)數(shù)的比例)與False Positive
Rate(FPR�,分類器分類錯(cuò)誤的負(fù)樣本個(gè)數(shù)占總負(fù)樣本個(gè)數(shù)的比例)之間的變化關(guān)系。如下圖所示:

如上圖�,ROC曲線描述FPR不斷變化時(shí),TPR的值�����,即FPR與TPR之間的關(guān)系曲線�。顯而易見,最好的分類器便是FPR=0%�,TPR=100%,但是一般在實(shí)踐中一個(gè)分類器很難會(huì)有這么好的效果���,即一般TPR不等于1����,F(xiàn)PR不等于0的。當(dāng)使用ROC曲線對(duì)分類器進(jìn)行評(píng)價(jià)時(shí)�,如果對(duì)多個(gè)分類器進(jìn)行比較時(shí),如果直接使用ROC曲線很難去比較���,只能通過將ROC分別畫出來����,然后進(jìn)行肉眼比較�����,那么這種方法是非常不便的�,因此我們需要一種定量的指標(biāo)去比較,這個(gè)指標(biāo)便是AUC了���,即ROC曲線下的面積��,面積越大�����,分類器的效果越好����,AUC的值介于0.5到1.0之間。
??具體如何描繪ROC曲線����,如在二分類中����,我們需要設(shè)定一個(gè)閾值,大于閾值分類正類����,否則分為負(fù)類。因此����,我們可以變化閾值,根據(jù)不同的閾值進(jìn)行分類�����,根據(jù)分類結(jié)果計(jì)算得到ROC空間中的一些點(diǎn)����,連接這些點(diǎn)就形成ROC曲線��。ROC曲線會(huì)經(jīng)過(0,0)與(1,1)這兩點(diǎn)�,實(shí)際上這兩點(diǎn)的連線形成的ROC代表一個(gè)隨機(jī)分類器����,一般情況下分類器的ROC曲線會(huì)在這條對(duì)角連線上方。
??在ROC曲線中��,點(diǎn)(0,0)表示TPR=0���,F(xiàn)PR=0���,即分類器將每個(gè)實(shí)例都預(yù)測為負(fù)類;點(diǎn)(1,1)表示TPR=1��,F(xiàn)PR=1���,即分類器將每個(gè)實(shí)例都預(yù)測為正類�;點(diǎn)(0,0)表示TPR=1�����,F(xiàn)PR=0,即分類器將每個(gè)正類實(shí)例都預(yù)測為正類�����,將每個(gè)負(fù)類實(shí)例都預(yù)測為負(fù)類����,這是一個(gè)理想模型。
??ROC曲線有個(gè)很好的特性:當(dāng)測試集中的正負(fù)樣本的分布變化的時(shí)候�,ROC曲線能夠保持不變。在實(shí)際的數(shù)據(jù)集中��,經(jīng)常會(huì)出現(xiàn)類別不平衡(class
imbalance)現(xiàn)象�,即負(fù)樣本比正樣本少很多(或者相反),而且測試數(shù)據(jù)集中的正負(fù)樣本的分布也可能隨時(shí)間發(fā)生變化��。
混淆矩陣(Confusion Matrix)
混淆矩陣是對(duì)分類的結(jié)果進(jìn)行詳細(xì)描述的一個(gè)表����,無論是分類正確還是錯(cuò)誤���,并且對(duì)不同的類別進(jìn)行了區(qū)分�����,對(duì)于二分類則是一個(gè)2*2的矩陣�����,對(duì)于n分類則是n*n的矩陣���。對(duì)于二分類�����,第一行是真實(shí)類別為“Positive”的記錄個(gè)數(shù)(樣本個(gè)數(shù))�,第二行則是真實(shí)類別為“Negative”的記錄個(gè)數(shù)�����,第一列是預(yù)測值為“Positive”的記錄個(gè)數(shù)����,第二列則是預(yù)測值為“Negative”的記錄個(gè)數(shù)。如下表所示:

如上表�����,可以將結(jié)果分為四類:
* 真正(True Positive, TP):被模型分類正確的正樣本�����;
* 假負(fù)(False Negative, FN):被模型分類錯(cuò)誤的正樣本;
* 假正(False Positive, FP):被模型分類的負(fù)樣本�;
* 真負(fù)(True Negative, TN):被模型分類正確的負(fù)樣本;
進(jìn)一步可以推出這些指標(biāo):

進(jìn)一步�����,由混淆矩陣可以計(jì)算以下評(píng)價(jià)指標(biāo):
* 準(zhǔn)確率(Accuracy):分類正確的樣本個(gè)數(shù)占所有樣本個(gè)數(shù)的比例����,即:
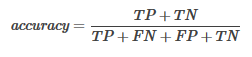
* 平均準(zhǔn)確率(Average per-class accuracy):每個(gè)類別下的準(zhǔn)確率的算術(shù)平均,即:
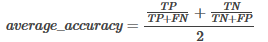
* 精確率(Precision):分類正確的正樣本個(gè)數(shù)占分類器所有的正樣本個(gè)數(shù)的比例����,即:
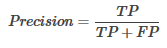
* 召回率(Recall):分類正確的正樣本個(gè)數(shù)占正樣本個(gè)數(shù)的比例,即:
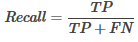
* F1-Score:精確率與召回率的調(diào)和平均值�,它的值更接近于Precision與Recall中較小的值,即:
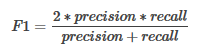
* ROC曲線
ROC曲線的x軸便是FPR�����,y軸便是TPR��。
回歸評(píng)價(jià)指標(biāo)
與分類不同的是�����,回歸是對(duì)連續(xù)的實(shí)數(shù)值進(jìn)行預(yù)測����,即輸出值是連續(xù)的實(shí)數(shù)值,而分類中是離散值���。例如����,給你歷史股票價(jià)格���,公司與市場的一些信息�����,需要你去預(yù)測將來一段時(shí)間內(nèi)股票的價(jià)格走勢(shì)��。那么這個(gè)任務(wù)便是回歸任務(wù)����。對(duì)于回歸模型的評(píng)價(jià)指標(biāo)主要有以下幾種:
* RMSE
??回歸模型中最常用的評(píng)價(jià)模型便是RMSE(root mean square error��,平方根誤差),其又被稱為RMSD(root mean square deviation)��,其定義如下:
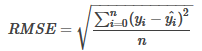
其中�,yi是第i個(gè)樣本的真實(shí)值,yi^是第i個(gè)樣本的預(yù)測值��,n是樣本的個(gè)數(shù)�����。該評(píng)價(jià)指標(biāo)使用的便是歐式距離�����。
??RMSE雖然廣為使用���,但是其存在一些缺點(diǎn)��,因?yàn)樗鞘褂闷骄`差�,而平均值對(duì)異常點(diǎn)(outliers)較敏感�,如果回歸器對(duì)某個(gè)點(diǎn)的回歸值很不理性,那么它的誤差則較大����,從而會(huì)對(duì)RMSE的值有較大影響,即平均值是非魯棒的���。
* Quantiles of Errors
??為了改進(jìn)RMSE的缺點(diǎn)��,提高評(píng)價(jià)指標(biāo)的魯棒性�����,使用誤差的分位數(shù)來代替�,如中位數(shù)來代替平均數(shù)�。假設(shè)100個(gè)數(shù),最大的數(shù)再怎么改變��,中位數(shù)也不會(huì)變���,因此其對(duì)異常點(diǎn)具有魯棒性�����。
??在現(xiàn)實(shí)數(shù)據(jù)中���,往往會(huì)存在異常點(diǎn),并且模型可能對(duì)異常點(diǎn)擬合得并不好,因此提高評(píng)價(jià)指標(biāo)的魯棒性至關(guān)重要���,于是可以使用中位數(shù)來替代平均數(shù)�����,如MAPE:

MAPE是一個(gè)相對(duì)誤差的中位數(shù)����,當(dāng)然也可以使用別的分位數(shù)�����。
* “Almost Crrect” Predictions
??有時(shí)我們可以使用相對(duì)誤差不超過設(shè)定的值來計(jì)算平均誤差�,如當(dāng)|yi?yi^|/yi超過100%(具體的值要根據(jù)問題的實(shí)際情況)則認(rèn)為其是一個(gè)異常點(diǎn),�,從而剔除這個(gè)異常點(diǎn),將異常點(diǎn)剔除之后���,再計(jì)算平均誤差或者中位數(shù)誤差來對(duì)模型進(jìn)行評(píng)價(jià)����。
排序評(píng)價(jià)指標(biāo)
排序任務(wù)指對(duì)對(duì)象集按照與輸入的相關(guān)性進(jìn)行排序并返回排序結(jié)果的過程����。舉例�����,我們?cè)谑褂盟阉饕妫ㄈ鏶oogle,baidu)的時(shí)候����,我們輸入一個(gè)關(guān)鍵詞或多個(gè)關(guān)鍵詞,那么系統(tǒng)將按照相關(guān)性得分返回檢索結(jié)果的頁面�。此時(shí)搜索引擎便是一個(gè)排序器。其實(shí)���,排序也可以說是一個(gè)二分類問題�。即將對(duì)象池中的對(duì)象分為與查詢?cè)~相關(guān)的正類與不相關(guān)的負(fù)類����。并且每一個(gè)對(duì)象都有一個(gè)得分,即其屬于正類的置信度����,然后按照這個(gè)置信度將正類進(jìn)行排序并返回。
??另一個(gè)與排序相關(guān)的例子便是個(gè)性化推薦引擎�����。個(gè)性化推薦引擎便是根據(jù)用戶的歷史行為信息或者元信息計(jì)算出每個(gè)用戶當(dāng)前有興趣的項(xiàng)目,并為每個(gè)項(xiàng)目賦一個(gè)興趣值���,最好按照這個(gè)興趣值進(jìn)行排序�����,返回top n興趣項(xiàng)目�����。
??對(duì)排序器進(jìn)行評(píng)價(jià)的一下指標(biāo)如下:
* Precision-Recall精確率-召回率
??精確率-召回率已經(jīng)在分類器的評(píng)價(jià)指標(biāo)中介紹過��。它們同樣也可以用于對(duì)排序器進(jìn)行評(píng)價(jià)����。如下圖所示:

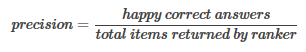

??一般的���,排序器返回top k的items�,如k=5, 10, 20, 100等��。那么該評(píng)價(jià)指標(biāo)改為“precision@k”和“recall@k”���。
??在推薦系統(tǒng)中�,它相當(dāng)于一個(gè)多興趣查詢,即每個(gè)用戶是一個(gè)查詢?cè)~�����,然后返回每個(gè)查詢?cè)~相關(guān)的top k項(xiàng)目��,即返回每個(gè)用戶感興趣的top
k項(xiàng)目��,那么在計(jì)算評(píng)價(jià)指標(biāo)值時(shí)�,則需要對(duì)每個(gè)用戶的精確率與召回率進(jìn)行平均(average precision@k” and “average
recall@k”)���,將平均值作為模型的精確率與召回率���。
* Precision-Recall Curve和F1 Score
??當(dāng)我們改變top
k中的k值時(shí),便可以得到不同的精確率與召回率�����,那么我們可以通過改變k值而得到精確率曲線和召回率曲線�����。與ROC曲線一樣,我們也需要一個(gè)定量的指標(biāo)對(duì)其ROC曲線進(jìn)行描述而來評(píng)價(jià)其對(duì)應(yīng)的模型進(jìn)行評(píng)價(jià)�。可取多個(gè)k值����,然后計(jì)算其評(píng)價(jià)的精確率與召回率。
??除了Precision-Recall曲線外��,另一個(gè)便是F1 Score���,在分類器評(píng)價(jià)指標(biāo)中也有提及到����,它將精確度與召回率兩個(gè)指標(biāo)結(jié)合起來�,如下:
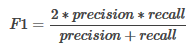
F1-score是精確率與召回率的調(diào)和平均值,它的值更接近于Precision與Recall中較小的值��。
* NDCG
??在精確率與召回率中��,返回集中每個(gè)項(xiàng)目的地位(權(quán)值)是一樣����,即位置k處的項(xiàng)目與位置1處的項(xiàng)目地位一樣,但是實(shí)際情況應(yīng)該是越排在前面的項(xiàng)目越相關(guān)�����,得分越高。NDCG(normalized
discounted cumulative gain)指標(biāo)便考慮了這種情況��,在介紹NDCG之前�����,首先介紹一下CG(cumulative
gain與DCG(discounted cumulative gain)��。CG是對(duì)排序返回的top
k個(gè)項(xiàng)目的相關(guān)性(即得分)求和���,而DCG在每個(gè)項(xiàng)目的得分乘上一個(gè)權(quán)值,該權(quán)值與位置成反方向(如成反比)�����,即位置越近�,權(quán)值越大。而NDCG則對(duì)每項(xiàng)的帶權(quán)值得分先進(jìn)行歸一化�,然后再求和。
??在信息檢索中或者那些對(duì)項(xiàng)目的返回位置關(guān)心的模型中經(jīng)常使用DCG或NDCG��。
注意事項(xiàng)
數(shù)據(jù)傾斜
在對(duì)模型進(jìn)行評(píng)價(jià)的時(shí)候�����,數(shù)據(jù)的好壞往往對(duì)評(píng)價(jià)指標(biāo)有著很大的影響。其中數(shù)據(jù)傾斜便是一個(gè)常見的數(shù)據(jù)特征����,具體指分類中每個(gè)類別的數(shù)據(jù)量不均衡,相差較大�����,存在一些異常點(diǎn)��,這些異常點(diǎn)會(huì)對(duì)評(píng)價(jià)指標(biāo)的計(jì)算產(chǎn)生較大的影響等��。
類別不均衡(Imbalanced Classes)
在前面我們提到使用average per-class
accuracy(平均類別準(zhǔn)確率)來解決類別不均衡所帶來的評(píng)價(jià)指標(biāo)問題����。舉例:假設(shè)數(shù)據(jù)集中正類的數(shù)據(jù)記錄數(shù)占總記錄數(shù)的1%(現(xiàn)實(shí)世界中如廣告系統(tǒng)中的點(diǎn)擊率CTR、推薦系統(tǒng)中的發(fā)生行為的用戶-項(xiàng)目對(duì)�、惡意軟件檢測中的惡意軟件),那么這種情況下��,如果將所有對(duì)象都預(yù)測為負(fù)類���,那么準(zhǔn)確率則為99%�,然而一個(gè)好的分類器準(zhǔn)確率應(yīng)該超過99%。在ROC曲線中��,只有左上角的那個(gè)部分菜重要��,如下圖所示:

??如果評(píng)價(jià)指標(biāo)對(duì)待每一個(gè)類別下的每一個(gè)實(shí)例都采用相等的權(quán)值��,那么就很難處理類別不平衡問題�����。因?yàn)榇藭r(shí)評(píng)價(jià)指標(biāo)會(huì)被數(shù)據(jù)量大的類別占主導(dǎo)��,起決定性作用����。并且不止是影響模型評(píng)價(jià)階段���,而且會(huì)影響模型的訓(xùn)練階段���。如果數(shù)據(jù)的類別不平衡不做處理,那么就會(huì)影響到對(duì)小類別的數(shù)據(jù)記錄的分類���。
??例如在推薦系統(tǒng)中�����,真實(shí)的數(shù)據(jù)中���,有行為的用戶-項(xiàng)目對(duì)很少���,即大部分用戶有發(fā)生行為的項(xiàng)目量很少,以及大部分項(xiàng)目只有少量的用戶在上面有行為����。這兩個(gè)問題會(huì)對(duì)推薦系統(tǒng)模型的訓(xùn)練與評(píng)價(jià)都會(huì)產(chǎn)生影響,但訓(xùn)練數(shù)據(jù)很少時(shí)��,模型很難學(xué)習(xí)都用戶的偏好�,或者項(xiàng)目的興趣相似項(xiàng)目量很少,導(dǎo)致在對(duì)模型進(jìn)行評(píng)價(jià)時(shí)會(huì)得到一個(gè)很低的評(píng)價(jià)指標(biāo)值��,即會(huì)得到一個(gè)性能較差的推薦模型�。
異常點(diǎn)(Outliers)
異常點(diǎn)是另一種數(shù)據(jù)傾斜問題。值大的異常點(diǎn)會(huì)對(duì)回歸造成很大的影響與問題��。例如�����,Million Song Dataset中,一個(gè)用戶對(duì)一首歌曲的評(píng)分為該用戶聽這首歌曲的次數(shù)��,回歸模型的預(yù)測得分中最高得分竟然超過了16000分��,這說明回歸模型出現(xiàn)了一些問題���,并且導(dǎo)致其它的誤差相對(duì)于該誤差都是極小的���。我們可以使用誤差的中位數(shù)來減少這個(gè)異常點(diǎn)所所帶來的影響。從而增加魯棒性�。但是該方法不能解決在模型訓(xùn)練階段的該問題。有效的解決方法是在數(shù)據(jù)預(yù)處理階段對(duì)數(shù)據(jù)進(jìn)行數(shù)據(jù)清洗從而剔除異常點(diǎn)���,以及對(duì)人物進(jìn)行重新定義與建模�����,使得其對(duì)異常低能不敏感。
離線評(píng)價(jià)機(jī)制
在模型的原型設(shè)計(jì)階段包:特征選擇�、模型類型的選擇、模型訓(xùn)練等���。該部分內(nèi)容仍然放在模型的原型設(shè)計(jì)階段�。
模型訓(xùn)練(Training)、驗(yàn)證(Validation)與模型選擇(Model Selection)
我們?cè)诮鉀Q機(jī)器學(xué)習(xí)任務(wù)之時(shí)�,需要選擇一個(gè)合適正確的模型去擬合數(shù)據(jù),模型的選擇發(fā)生在模型的驗(yàn)證階段而不是模型的訓(xùn)練階段���。即當(dāng)我們訓(xùn)練出多個(gè)模型之時(shí)�,需要選擇一個(gè)較好的模型���,具體而言�����,便是使用一個(gè)新的數(shù)據(jù)集(稱為驗(yàn)證數(shù)據(jù)集)去對(duì)每個(gè)模型進(jìn)行評(píng)價(jià)�����,選擇一個(gè)最優(yōu)的模型��,最優(yōu)不止是指效果�,還有模型復(fù)雜度����,模型可實(shí)踐性等方面����。如下圖所示:

在上圖中��,超參數(shù)調(diào)優(yōu)(hyperparameter tuning )作為控制模型訓(xùn)練的一個(gè)元過程(“meta”
process)�,即前奏過程,將會(huì)在后面詳細(xì)介紹��。圖中將歷史數(shù)據(jù)集劃分成兩個(gè)部分(一般是隨機(jī)劃分)�����,一個(gè)作為模型的訓(xùn)練集�����,一個(gè)作為模型的驗(yàn)證數(shù)據(jù)集��。模型訓(xùn)練階段使用訓(xùn)練集來訓(xùn)練模型并輸出之����,然后使用驗(yàn)證集對(duì)該模型進(jìn)行評(píng)價(jià)。并將驗(yàn)證結(jié)果反饋到超參數(shù)調(diào)優(yōu)器中�,對(duì)超參數(shù)進(jìn)行調(diào)優(yōu)后繼續(xù)訓(xùn)練模型。
為何要將歷史數(shù)據(jù)劃分為兩個(gè)數(shù)據(jù)集呢����?在統(tǒng)計(jì)模型世界中,任何事物的發(fā)生都假設(shè)是隨機(jī)的�,它們服從一個(gè)隨機(jī)分布。模型便是從隨機(jī)數(shù)據(jù)中學(xué)習(xí)而來的����,因此模型也是隨機(jī)的。并且這個(gè)學(xué)習(xí)的模型需要被一個(gè)隨機(jī)的已觀察到的數(shù)據(jù)集進(jìn)行測試評(píng)估�����,因此測試結(jié)果也是隨機(jī)的���。為了確保準(zhǔn)確性與公平性�,需要使用一個(gè)與訓(xùn)練集獨(dú)立的數(shù)據(jù)集對(duì)模型進(jìn)行驗(yàn)證�。必須使用與訓(xùn)練樣本集不同的數(shù)據(jù)樣本集進(jìn)行測試,從而可以得到模型的泛化誤差����。那么如何產(chǎn)生一個(gè)新的數(shù)據(jù)集呢?
??在離線階段��,我們只有一個(gè)歷史數(shù)據(jù)集合��。那么如何去獲得另一個(gè)獨(dú)立的數(shù)據(jù)集呢?因此我們需要一種機(jī)制去產(chǎn)生另一個(gè)數(shù)據(jù)集�����。一種方式是留下一部分?jǐn)?shù)據(jù)來作為驗(yàn)證集�,如hold-out
validation與cross-validation,
另一種方式是重采樣技術(shù)�����,如bootstrapping與Jackknife�����。如下圖所示:

??從上圖可以看出��,cross-validation與bootstrapping都是將數(shù)據(jù)集劃分為多個(gè)較小的數(shù)據(jù)集�,而hold-out validation只是將數(shù)據(jù)集劃分為一大一小的兩個(gè)部分,大的部分作為訓(xùn)練集��,較小的部分作為驗(yàn)證集��。
Hold-out Validation
Hold-out Validation較簡單�,它假設(shè)數(shù)據(jù)集中的每個(gè)數(shù)據(jù)點(diǎn)都是獨(dú)立同分布的(i.i.d,independently
and identically
distributed)。因此我們只需要簡單得將原數(shù)據(jù)集隨機(jī)劃分成兩個(gè)部分���,較大的部分作為訓(xùn)練集���,用來訓(xùn)練數(shù)據(jù),較小的部分作為驗(yàn)證集���,用來對(duì)模型進(jìn)行驗(yàn)證����。
??從計(jì)算的角度來說�����,Hold-out
Validation是簡單的并運(yùn)行時(shí)間快的����。缺點(diǎn)便是它是強(qiáng)假設(shè)的,缺乏有效的統(tǒng)計(jì)特征����,并且驗(yàn)證數(shù)據(jù)集較小,那么其驗(yàn)證的結(jié)果則可靠性較低�,同時(shí)也很難在單個(gè)數(shù)據(jù)集上計(jì)算方差信息與置信區(qū)間。因此如果需要使用
hold-out validation方法��,則需要足夠的數(shù)據(jù)以確保驗(yàn)證集數(shù)據(jù)足夠而確保可靠的統(tǒng)計(jì)估計(jì)���。
Cross-Validation
Cross-Validation是另一種模型訓(xùn)練集與驗(yàn)證集的產(chǎn)生方法���,即將數(shù)據(jù)集劃分成多個(gè)小部分集合,如劃分成k個(gè)部分����,那么就變?yōu)榱薻-fold
cross
validation。依次使用其中的k-1個(gè)數(shù)據(jù)集對(duì)模型進(jìn)行訓(xùn)練(每次使用k-1個(gè)不同的數(shù)據(jù)集)����,然后使用剩下的一個(gè)數(shù)據(jù)集對(duì)模型進(jìn)行評(píng)價(jià),計(jì)算評(píng)價(jià)指標(biāo)值���。接著重復(fù)前面的步驟��,重復(fù)k次�����,得到k個(gè)評(píng)價(jià)指標(biāo)值�����。最后計(jì)算這k個(gè)評(píng)價(jià)指標(biāo)的平均值�。其中k是一個(gè)超參數(shù),我們可以嘗試多個(gè)k�����,選擇最好的平均評(píng)價(jià)指標(biāo)值所對(duì)應(yīng)的k為最終的k值���。
??另一個(gè)Cross-Validation的變種便是leave-one-out。該方法與k-fold cross
validation方法類似��,只是k等于數(shù)據(jù)集中樣本的總數(shù)目���,即每次使用n-1個(gè)數(shù)據(jù)點(diǎn)對(duì)模型進(jìn)行訓(xùn)練�����,使用最好一個(gè)數(shù)據(jù)點(diǎn)對(duì)模型進(jìn)行訓(xùn)練�。重復(fù)n次�,計(jì)算每次的評(píng)價(jià)指標(biāo)值,最后得到平均評(píng)價(jià)指標(biāo)值��。該方法又稱為n-fold
cross validation。
??當(dāng)數(shù)據(jù)集較小時(shí)以致hold-out validation效果較差的時(shí)候���,cross validation是一種非常有效的訓(xùn)練集-驗(yàn)證集產(chǎn)生方法�。
Bootstrapping和Jackknife
Bootstrapping是一種重采樣技術(shù)�����,翻譯成自助法���。它通過采樣技術(shù)從原始的單個(gè)數(shù)據(jù)集上產(chǎn)生多個(gè)新的數(shù)據(jù)集�����,每個(gè)新的數(shù)據(jù)集稱為一個(gè)bootstrapped
dataset���,并且每個(gè)新的數(shù)據(jù)集大小與原始數(shù)據(jù)集大小相等。這樣�����,每個(gè)新的數(shù)據(jù)集都可以用來對(duì)模型進(jìn)行評(píng)價(jià)�����,從而可以得到多個(gè)評(píng)價(jià)值,進(jìn)一步可以得到評(píng)價(jià)方差與置信區(qū)間�。
??Bootstrapping與Cross Validation交叉校驗(yàn)相關(guān)。Bootstrapping對(duì)原數(shù)據(jù)集進(jìn)行采樣生成一個(gè)新的數(shù)據(jù)集(
bootstrapped
dataset)��。不同的是��,Bootstrapping假設(shè)每個(gè)數(shù)據(jù)點(diǎn)都服從均勻分布����。它采用的是一種有放回的采樣,即將原始數(shù)據(jù)集通過采樣生成一個(gè)新的數(shù)據(jù)集時(shí)��,每次采樣都是有放回得采樣���,那么這樣在新生成的數(shù)據(jù)集中,可能存在重復(fù)的數(shù)據(jù)點(diǎn)��,并且可能會(huì)重復(fù)多次��。
??為什么使用有放回的采樣�?每一個(gè)樣本都可以用一個(gè)真實(shí)的分布進(jìn)行描述,但是該分布我們并不知道���,我們只有一個(gè)數(shù)據(jù)集去推導(dǎo)該分布���,因此我們只能用該數(shù)據(jù)集去估計(jì)得到一個(gè)經(jīng)驗(yàn)分布���。Bootstrap假設(shè)新的樣本都是從該經(jīng)驗(yàn)分布中得到的,即新的數(shù)據(jù)集服從該經(jīng)驗(yàn)分布�����,并且分布一直不變��。如果每次采樣后不進(jìn)行放回��,那么這個(gè)經(jīng)驗(yàn)分布會(huì)一直改變�。因此需要進(jìn)行有放回的采樣。
??顯然采樣后得到的新數(shù)據(jù)集中會(huì)包含同樣的樣本多次�����。如果重復(fù)采樣n次����,那么原數(shù)據(jù)集中的樣本出現(xiàn)在新的數(shù)據(jù)集中的概率為1?1/e≈63.2%,用另外一種講法���,原數(shù)據(jù)集中有約2/3的數(shù)據(jù)會(huì)在新數(shù)據(jù)集中出現(xiàn)��,并且有的會(huì)重復(fù)多次�����。
??在對(duì)模型進(jìn)行校驗(yàn)時(shí)�����,可以使用新生成的數(shù)據(jù)集( bootstrapped dataset)對(duì)模型進(jìn)行訓(xùn)練��,使用未被采樣的樣本集來對(duì)模型進(jìn)行驗(yàn)證����。這種方式類似交叉校驗(yàn)。
??Jackknife翻譯成刀切法�����。Jackknife即從原始進(jìn)行不放回采樣m(m
注意:模型驗(yàn)證與測試不同
在前面一直都是使用“驗(yàn)證”這個(gè)詞作為模型訓(xùn)練后需要進(jìn)行的過程�。而沒有使用“測試”這個(gè)詞����。因?yàn)槟P万?yàn)證與模型測試不同。
??在原型設(shè)計(jì)階段中�,需要進(jìn)行模型選擇���,即需要對(duì)多個(gè)候選模型在一個(gè)或多個(gè)驗(yàn)證集上進(jìn)行性能評(píng)價(jià)。當(dāng)在模型訓(xùn)練與驗(yàn)證確定了合適的模型類型(如分類中是采用決策樹還是svm等)以及最優(yōu)的超參數(shù)(如特征的個(gè)數(shù))后�����,需要使用全部可利用的數(shù)據(jù)(包括前面對(duì)模型進(jìn)行驗(yàn)證的驗(yàn)證集)對(duì)模型進(jìn)行訓(xùn)練�����,訓(xùn)練出的模型便是最終的模型�,即上線生產(chǎn)的模型。
??模型測試則發(fā)生在模型的原型設(shè)計(jì)之后���,即包含在上線階段又包含在離線監(jiān)視(監(jiān)測分布漂移 distribution drift)階段���。
??不要將訓(xùn)練數(shù)據(jù)、驗(yàn)證數(shù)據(jù)與測試數(shù)據(jù)相混淆�����。模型的訓(xùn)練�、驗(yàn)證與測試應(yīng)該使用不同的數(shù)據(jù)集,如果驗(yàn)證數(shù)據(jù)集��、測試數(shù)據(jù)集與訓(xùn)練數(shù)據(jù)集有重疊部分,那么會(huì)導(dǎo)致模型的泛化能力差�。
??就在前一段時(shí)間,某隊(duì)在ImageNet(圖像識(shí)別最大數(shù)據(jù)庫)圖像識(shí)別測試挑戰(zhàn)賽競賽宣稱自己的效果擊敗了google和microsoft����,圖像識(shí)別錯(cuò)誤率低至4.58%,而microsoft為4.94%����,谷歌為4.8%。但是最后查出他們違規(guī)了���,按照測試的官方規(guī)定����,參與者每周只能向服務(wù)器提交2次測試結(jié)果���,而他們卻在5天內(nèi)提交了40次結(jié)果�����。此外,ImageNet表示���,他們還使用了30個(gè)不同的賬號(hào)�����,在過去6個(gè)月中提交了約200次測試結(jié)果����。從本質(zhì)上講,他們多次測試調(diào)優(yōu)而得到了對(duì)測試數(shù)據(jù)集更好的擬合超參數(shù)和模型參數(shù)����,因此模型的效果可能更好,但是可能會(huì)導(dǎo)致過擬合而使得模型的泛化能力差���。
總結(jié)
本節(jié)主要對(duì)模型離線評(píng)估與模型離線驗(yàn)證進(jìn)行講解����。
* 在模型原型設(shè)計(jì)階段���,需要進(jìn)行模型選擇���,包括超參數(shù)調(diào)優(yōu)、模型訓(xùn)練�、模型驗(yàn)證��。
* Cross validation是一種生成訓(xùn)練數(shù)據(jù)集與驗(yàn)證數(shù)據(jù)集的機(jī)制���;該方式在數(shù)據(jù)集較小時(shí)特別有用。
* Hyperparameter tuning是一種為模型選擇最優(yōu)的超參數(shù)機(jī)制��,需要使用交叉校驗(yàn)來對(duì)超參數(shù)進(jìn)行評(píng)估��。
* Hold-out validation是另一種訓(xùn)練數(shù)據(jù)集與驗(yàn)證集的產(chǎn)生方式�,它較簡單。當(dāng)數(shù)據(jù)集較充分時(shí)使用����。
* Bootstrapping與Jackknife是兩種不同的采樣方式,用來產(chǎn)生訓(xùn)練集與驗(yàn)證集�����。該方法可以為模型提供評(píng)價(jià)指標(biāo)值方差與置信區(qū)間���。
超參數(shù)調(diào)優(yōu)(Hyperparameter Tuning)
在機(jī)器學(xué)習(xí)領(lǐng)域�����,超參數(shù)調(diào)優(yōu)是學(xué)習(xí)任務(wù)的先導(dǎo)步驟(meta)��,下面將對(duì)其進(jìn)行介紹����。
模型參數(shù)與超參數(shù)
什么是模型的超參數(shù)����,它與模型正常的參數(shù)有什么不同。機(jī)器學(xué)習(xí)從本質(zhì)上來說是一個(gè)數(shù)學(xué)模型���,它代表著數(shù)據(jù)的各個(gè)方面的聯(lián)系���。
??例如:在線性回歸模型中,使用一條線表示特征與目標(biāo)之間的關(guān)系�����,用數(shù)學(xué)公式表示為 :
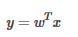
其中x是特征向量�����,每個(gè)樣本使用一個(gè)特征向量進(jìn)行表征�����,y是一個(gè)數(shù)值變量,代表目標(biāo)�,w則是每個(gè)特征的權(quán)值向量,代表著這條線的斜率����。這個(gè)模型假設(shè)特征與目標(biāo)之間是線性的。w表示模型的參數(shù)���,需要在模型的訓(xùn)練階段進(jìn)行學(xué)習(xí)更新����,也就是說���,模型訓(xùn)練其實(shí)就是使用一種優(yōu)化算法決定最優(yōu)的模型參數(shù)來對(duì)數(shù)據(jù)進(jìn)行擬合����。
??另外一種被稱為模型超參數(shù)����。超參數(shù)的確定不是在模型的訓(xùn)練階段。普通的線性回歸是沒有超參數(shù)的(除了特征的個(gè)數(shù))�����,而Ridge回歸與Lasso回歸都添加了正則項(xiàng)(Ridge嶺回歸加上L2正則項(xiàng),Lasso回歸加上L1正則項(xiàng))�,這些正則項(xiàng)都需要一個(gè)正則參數(shù)(regularization
parameter)。如決策樹需要設(shè)置樹的深度和葉子數(shù)�����、支持向量機(jī)(SVM)需要設(shè)置一個(gè)分類錯(cuò)誤的懲罰因子�、帶核的SVM還需要設(shè)置核的參數(shù)(如RBF徑向基函數(shù)的寬度)等���。
超參數(shù)的作用
模型的超參數(shù)是用來干什么的呢��?如正則化因子是來控制模型的能力����,模型擬合數(shù)據(jù)的自由度(degrees of
freedom)決定了模型的靈活度��。合理的控制模型的能力能夠有效得防止過擬合現(xiàn)象��。因此為了防止過擬合的發(fā)生���,需要犧牲一些精度��。因此合理的設(shè)置模型的超參數(shù)則非常重要��。
??另一種類型的模型超參數(shù)來自于模型的訓(xùn)練階段���。模型訓(xùn)練是一個(gè)使損失函數(shù)(或代價(jià)函數(shù)���,訓(xùn)練階段的評(píng)價(jià)指標(biāo))最小化的過程,這過程會(huì)用到很多最優(yōu)化技術(shù)與方法���,使用的最優(yōu)化方法中需要用到一些參數(shù)���。如SGD(
stochastic gradient descent)中,需要一個(gè)學(xué)習(xí)速率因子�����、初始點(diǎn)以及收斂閾值等��。又如���,隨機(jī)森林(Random
Forests)和自助提升決策樹(Boosted decision
trees)需要設(shè)置樹的個(gè)數(shù)的參數(shù)與正則化參數(shù)等等��。這些超參數(shù)需要被合理地設(shè)置以找到一個(gè)好的模型�����。
超參數(shù)調(diào)優(yōu)機(jī)制
超參數(shù)設(shè)置的好壞對(duì)模型的評(píng)價(jià)指標(biāo)值產(chǎn)生較大的影響����。不同的數(shù)據(jù)集上面創(chuàng)建模型會(huì)有不同的最優(yōu)超參數(shù),因此對(duì)于不同的數(shù)據(jù)集需要各自調(diào)優(yōu)��。
??如下圖���,超參數(shù)的設(shè)置過程為:首先設(shè)置一個(gè)初始的超參數(shù)值,然后進(jìn)行模型訓(xùn)練�,將模型的指標(biāo)反饋都超參數(shù)調(diào)優(yōu)機(jī)制中,調(diào)節(jié)超參數(shù)�,繼續(xù)訓(xùn)練模型,一直進(jìn)行下去����,若干次后得到一個(gè)目前最優(yōu)的超參數(shù)值。最后使用該最優(yōu)的超參數(shù)去訓(xùn)練模型����,并進(jìn)行模型驗(yàn)證。

超參數(shù)調(diào)優(yōu)算法
從概念上講�,超參數(shù)調(diào)優(yōu)是一個(gè)最優(yōu)化任務(wù)過程�,就像模型訓(xùn)練一樣�����。然而��,這兩者之間相當(dāng)?shù)牟煌?�。在模型?xùn)練中���,使用一個(gè)稱為代價(jià)函數(shù)的數(shù)據(jù)公式為目標(biāo)去進(jìn)行對(duì)模型參數(shù)進(jìn)行訓(xùn)練調(diào)優(yōu)���。而在超參數(shù)調(diào)優(yōu)中,無法使用一個(gè)形式化的公式為目標(biāo)去進(jìn)行調(diào)優(yōu)�����,它就像一個(gè)黑盒子����,需要使用模型訓(xùn)練結(jié)束后的模型評(píng)價(jià)結(jié)果為指導(dǎo)去進(jìn)行調(diào)優(yōu)。這就是為什么超參數(shù)調(diào)優(yōu)較為困難��。下面是一些具體的超參數(shù)調(diào)優(yōu)方法:
格搜索(Grid Search)
顧名思義����,格搜索便是將超參數(shù)的取值范圍劃分成一個(gè)個(gè)格子����,然后對(duì)每一個(gè)格子所對(duì)應(yīng)的值進(jìn)行評(píng)估����,選擇評(píng)估結(jié)果最好的格子所對(duì)應(yīng)的超參數(shù)值。例如��,對(duì)于決策樹葉子節(jié)點(diǎn)個(gè)數(shù)這一超參數(shù)�,可以將值劃分為這些格子:10,
20, 30, …, 100, …;又如正則化因子這一超參數(shù)�����,一般使用指數(shù)值���,那么可以劃分為:1e-5, 1e-4 1e-3, …,
1。有時(shí)可以進(jìn)行猜測對(duì)格子進(jìn)行搜索去獲得最優(yōu)的超參數(shù)���。如��,當(dāng)從第一個(gè)開始����,發(fā)現(xiàn)效果較差,第二個(gè)好了一點(diǎn)����,那么可以第三個(gè)可以取最后一個(gè)。格搜索較為簡單并且可以進(jìn)行并行化�����。
隨機(jī)搜索(Random Search)
在論文 “Random Search for Hyper Parameter Optimization” (Bergstra and
Bengio)中����,已經(jīng)驗(yàn)證了隨機(jī)搜索是一個(gè)簡單而有效的方法。它是格搜索的變種���。相比于搜索整個(gè)格空間�,隨機(jī)搜索只對(duì)隨機(jī)采樣的那些格進(jìn)行計(jì)算�����,然后在這中間選擇一個(gè)最好的�����。因此隨機(jī)搜索比格搜索的代價(jià)低。隨機(jī)搜索有個(gè)缺點(diǎn)���,即其可能找不到最優(yōu)的點(diǎn)���。但是前面的那篇論文已經(jīng)證明,隨機(jī)采樣60個(gè)點(diǎn)的性能已經(jīng)足夠好了����。從概率的角度來說,對(duì)于任何的分布的樣本空間若存在最大值����,那么隨機(jī)采樣60個(gè)點(diǎn)中的最大值位于整個(gè)樣本空間top5%的值的集合中的概率達(dá)到95%。證明如下:
??對(duì)于top%5的值����,我們每次隨機(jī)采樣,得到top5%的值的概率為5%�����,沒有得到top5%的值的概率為(1-0.05)��,重復(fù)有放回地采樣n次���,那么至少有一次得到top5的值這件事發(fā)生的概率若要超過95%���,則:
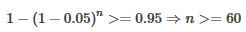
這表示我們只需要從所有候選格中隨機(jī)采樣60個(gè)格,便可以以95%的概率得到至少一個(gè)的top5%最優(yōu)的格�。因此隨機(jī)搜索60個(gè)格進(jìn)行計(jì)算便可以以很高的概率得到top%5最優(yōu)的格。當(dāng)最優(yōu)格以及近似最優(yōu)格的集合較大�����,加上機(jī)器學(xué)習(xí)模型對(duì)超參數(shù)一個(gè)近似最優(yōu)值與最優(yōu)值不會(huì)太敏感��,因此����,隨機(jī)搜索算法便是有效的。由于隨機(jī)搜索簡單并且有效���,一般是超參數(shù)調(diào)優(yōu)的首選搜索算法�����。并且其容易并行化��。
智能搜索(Smart Search)
除了前面的兩種搜索算法�����,還可以利用智能搜索算法����,但是相對(duì)于前面的兩種方法,智能搜索算法最大的缺點(diǎn)便是不能并行化���。它的處理過程是一個(gè)序列���,并只處理一部分候選點(diǎn),然后對(duì)當(dāng)前點(diǎn)進(jìn)行評(píng)估�,決定下一個(gè)點(diǎn)。智能搜索的目的是只對(duì)一部分點(diǎn)進(jìn)行評(píng)估從而節(jié)省調(diào)優(yōu)時(shí)間�����。
??可以看出����,智能搜索需要時(shí)間去計(jì)算下一個(gè)評(píng)估的點(diǎn),于是相對(duì)于前面的方法�����,可能需要更多的時(shí)間�����。因此只有在對(duì)點(diǎn)進(jìn)行評(píng)估所用的時(shí)間大于決定下一個(gè)需要評(píng)估的點(diǎn)的時(shí)間時(shí)才有意義���。當(dāng)然智能搜索算法也需要自己的超參數(shù)����,因此也需要調(diào)優(yōu)���。有時(shí)好的智能搜索算法超參數(shù)可以確保智能搜索快于隨機(jī)搜索����。
??文章前面提到����,超參數(shù)調(diào)優(yōu)是一個(gè)困難的過程,因?yàn)樗荒芟肽P蛥?shù)調(diào)優(yōu)那樣����,給出一個(gè)形式化的數(shù)學(xué)函數(shù)�,而對(duì)數(shù)學(xué)函數(shù)進(jìn)行調(diào)優(yōu)�。因此很多優(yōu)化算法,如牛頓優(yōu)化算法�、隨機(jī)梯度下降算法都不能使用。目前有超參數(shù)三個(gè)智能調(diào)優(yōu)算法:derivative-free
optimization, Bayesian optimization和random forest smart
tuning�����。derivative-free優(yōu)化算法采用啟發(fā)式來決定下一個(gè)計(jì)算的點(diǎn)�;Bayesian和random
forest優(yōu)化算法都是創(chuàng)建一個(gè)響應(yīng)函數(shù)曲面模型,由模型決定下一步需要計(jì)算的點(diǎn)����。
??Jasper Snoek等使用高斯過程對(duì)響應(yīng)函數(shù)進(jìn)行建模。Frank Hutter等使用回歸隨機(jī)森林來近似這個(gè)響應(yīng)曲面�。 Misha Bilenko等使用Nelder-Mead來進(jìn)行超參數(shù)調(diào)優(yōu)。
嵌套交叉校驗(yàn)(Nested Cross-Validation)
嵌套交叉校驗(yàn)又稱為嵌套超參數(shù)調(diào)優(yōu)����。模型選擇與超參數(shù)調(diào)優(yōu)的不同之處在于:模型選擇不僅包括對(duì)某個(gè)模型的參數(shù)進(jìn)行調(diào)優(yōu)(如決策樹的深度),并且包括對(duì)不同模型的選擇(如分類中�,選擇決策樹還是SVM)。嵌套交叉校驗(yàn)即在進(jìn)行某個(gè)模型訓(xùn)練后���,需要對(duì)該模型進(jìn)行交叉校驗(yàn)�����,然后將結(jié)果反饋到超參數(shù)調(diào)優(yōu)機(jī)制中����,對(duì)超參數(shù)調(diào)優(yōu)��,并使用更新后的超參數(shù)繼續(xù)訓(xùn)練模型��,一直迭代下去�,知道滿足一定的要求,同時(shí)對(duì)其它模型也需要如此進(jìn)行訓(xùn)練���,最后在所有訓(xùn)練好的模型選擇一個(gè)綜合各方面因素最優(yōu)的模型�。
A/B測試的陷阱
A/B測試(A/B Testing)是機(jī)器學(xué)習(xí)實(shí)踐中廣泛應(yīng)用的一種方法�����。但是在應(yīng)用該方法時(shí)�,會(huì)遇到一些陷阱。下面便對(duì)相關(guān)問題進(jìn)行討論�。
??在本文的前部分已經(jīng)講述到,機(jī)器學(xué)習(xí)模型的評(píng)價(jià)分為離線評(píng)價(jià)與在線評(píng)價(jià)兩個(gè)階段�����。離線評(píng)價(jià)階段發(fā)生在模型原型設(shè)計(jì)階段,對(duì)不同的超參數(shù)���、不同的特征集���、不同模型進(jìn)行評(píng)價(jià),它是一個(gè)迭代的過程�����,使用選定的評(píng)價(jià)指標(biāo)對(duì)每個(gè)迭代過程中生成的模型進(jìn)行評(píng)價(jià)�����。一旦達(dá)到指定的迭代次數(shù)��,則選擇所有迭代中最優(yōu)的模型���,作為最終模型并投入到生產(chǎn)環(huán)境中使用����。而在線評(píng)價(jià)則是使用一些商業(yè)評(píng)價(jià)指標(biāo)來對(duì)模型進(jìn)行評(píng)價(jià)以及更新��。而A/B測試則屬于在線測試。
什么是A/B測試
A/B測試是目前在線測試中最主要的方法�����。該方法可以用來回答“新的模型比舊的模型更好嗎(模型)��?”�����、“這個(gè)按鈕是使用黃色好一些還是藍(lán)色好(設(shè)計(jì))”等等問題����。在A/B測試中����,與兩個(gè)部分:A和B,或控制/實(shí)驗(yàn)(control
and
experiment)�����,A代表舊模型(設(shè)計(jì))的評(píng)價(jià)���,B代表新的模型(設(shè)計(jì))的評(píng)價(jià)�,然后將它們進(jìn)行對(duì)比,得到是否新的模型比舊模型更好�。當(dāng)然是由具體的機(jī)制來進(jìn)行衡量。
??該衡量方法便是統(tǒng)計(jì)假設(shè)檢驗(yàn)(statistical hypothesis
testing)��。其用來回答“新的模型或設(shè)計(jì)是否對(duì)一些關(guān)鍵的評(píng)價(jià)指標(biāo)有著大幅度的提升或者明顯的提升”�����。它包括兩個(gè)對(duì)立的假設(shè):空假設(shè)(null
hypothesis)與替代假設(shè)(alternate
hypothesis)��。前者表示“新的模型或設(shè)計(jì)沒有明顯的提升”��,后者則表示“新的模型或設(shè)計(jì)有了明顯的提升”��,“提升”具體反映在關(guān)鍵評(píng)價(jià)指標(biāo)的平均值(mean
value)等上面�。
??有很多書籍與網(wǎng)上資源對(duì)A/B測試有著詳細(xì)的描述,這里不再累贅�。如 www.evanmiller.org,它對(duì)A/B測試進(jìn)行了詳細(xì)的講解以及列舉了一些工具��。簡而言之���,A/B測試包括以下幾個(gè)步驟:
* 隨機(jī)劃分成兩組A與B
* 使用一些方法分別觀察兩組中的行為
* 計(jì)算一些統(tǒng)計(jì)指標(biāo)
* 計(jì)算p-value
* 最后輸出孰好孰壞
??舉個(gè)最簡單的例子�����,在網(wǎng)頁設(shè)計(jì)中使用A/B測試�����。首先需要建立一個(gè)測試頁面(experiment
page)�����,這個(gè)頁面可能在標(biāo)題字體�����,背景顏色��,措辭等方面與原有頁面(control
page)有所不同��,然后將這兩個(gè)頁面以隨機(jī)的方式同時(shí)推送給所有瀏覽用戶�。接下來分別統(tǒng)計(jì)兩個(gè)頁面的用戶轉(zhuǎn)化率���,即可清晰的了解到兩種設(shè)計(jì)的優(yōu)劣���。
??A/B測試雖然通俗易懂,但是要想正確的使用它則較為棘手����。下面將介紹一些在使用A/B測試時(shí)可能會(huì)遇到的一些陷阱與問題���,這些問題包括理論層面的和實(shí)踐層面的。
A/B測試的一些陷阱
實(shí)驗(yàn)完全分離
在A/B測試中����,需要將用戶隨機(jī)分為兩組。一部分用戶使用舊的模型或設(shè)計(jì)(如瀏覽原來的網(wǎng)頁)�����,另一部分用戶使用新的模型或設(shè)計(jì)(如瀏覽新設(shè)計(jì)的網(wǎng)頁)�����。那么需要保證experimentation組(使用新的模型或設(shè)計(jì)的組)的用戶的純凈度�,什么意思呢?
??A/B測試中�����,劃分為完全獨(dú)立的��,干凈的兩組是非常重要的。設(shè)想一下����,在對(duì)網(wǎng)頁中的按鈕新樣式進(jìn)行測試時(shí),需要確保統(tǒng)一用戶自始自終是使用同一個(gè)按鈕設(shè)計(jì)���,那么我們?cè)趯?duì)用戶進(jìn)行隨機(jī)劃分時(shí)���,就需要使用能夠唯一代表用戶的來進(jìn)行劃分(即導(dǎo)流),如用戶ID�,用戶sessions等。Kohavi等的KDD 2012論文表明一些使用舊設(shè)計(jì)的用戶再使用新的設(shè)計(jì)時(shí)會(huì)帶著某著偏見�����。
使用什么評(píng)價(jià)指標(biāo)
另一個(gè)重要的問題便是�,在A/B測試中使用什么評(píng)價(jià)指標(biāo)�。因?yàn)锳/B測試是在在線評(píng)價(jià)階段,因此使用的評(píng)價(jià)指標(biāo)便是商業(yè)指標(biāo)�����。但是商業(yè)指標(biāo)有沒有離線階段那些評(píng)價(jià)指標(biāo)那么容易計(jì)算�����。舉個(gè)例子,在搜索引擎中���,一般對(duì)用戶的數(shù)目���、用戶在結(jié)果站點(diǎn)的逗留時(shí)間、以及市場份額�。在現(xiàn)實(shí)中,統(tǒng)計(jì)比較并不是那么容易���,因此我們需要對(duì)獨(dú)立用戶每天訪問數(shù)��、平均會(huì)話時(shí)間長度等這些能夠反映市場份額的指標(biāo)進(jìn)行計(jì)算�����,以便能夠?qū)κ袌龇蓊~進(jìn)行估計(jì)����。并且一般短期指標(biāo)并不與長期指標(biāo)保持一致�。
??在機(jī)器學(xué)習(xí)過程中,一般會(huì)用到四種類型的評(píng)價(jià)指標(biāo)��,分別是:訓(xùn)練評(píng)價(jià)指標(biāo)(training
metrics)、離線評(píng)價(jià)指標(biāo)(驗(yàn)證評(píng)價(jià)指標(biāo)���,offline evaluation metrics or validation
metrics)����、新生數(shù)據(jù)評(píng)價(jià)指標(biāo)(live metrics)���、商業(yè)指標(biāo)(business
metrics)�。訓(xùn)練評(píng)價(jià)指標(biāo)是指模型優(yōu)化的評(píng)價(jià)指標(biāo)���,即代價(jià)函數(shù)(目標(biāo)函數(shù)或損失函數(shù))���,如在線性回歸中使用平方誤差和、svm中分類平面幾何間隔最大化等��。離線評(píng)價(jià)指標(biāo)是指模型訓(xùn)練完畢需要使用驗(yàn)證數(shù)據(jù)集來對(duì)模型進(jìn)行評(píng)價(jià)���,即前面所提到的那些指標(biāo),如分類模型評(píng)價(jià)指標(biāo)���、回歸模型評(píng)價(jià)指標(biāo)以及排序模型評(píng)價(jià)指標(biāo)等��。新生數(shù)據(jù)評(píng)價(jià)指標(biāo)即使用模型上線后新生成的數(shù)據(jù)來評(píng)價(jià)模型�,評(píng)價(jià)指標(biāo)同離線評(píng)價(jià)指標(biāo),只是評(píng)價(jià)所用的數(shù)據(jù)不同���。而商業(yè)指標(biāo)即系統(tǒng)真正關(guān)心的最終指標(biāo)��,如轉(zhuǎn)化率�����、點(diǎn)擊率����、PV訪問量�、UV訪問量等。每個(gè)階段使用的評(píng)價(jià)指標(biāo)不一樣���,并且這些指標(biāo)可能并不呈現(xiàn)線性相關(guān)��,如在回歸模型中��,隨著RMSE的下降���,但是點(diǎn)擊率(click-through
rates.)并沒有提高��,詳細(xì)可以參見Kohavi‘s paper�����。
多少改變才算是真正的改變�����?
當(dāng)確定了使用什么商業(yè)指標(biāo)進(jìn)行評(píng)價(jià)以及如何去計(jì)算這些指標(biāo)時(shí)���,接下來需要明確指標(biāo)值提升了多少才算正在的提升,即多少的提升才可接受�。這在某種程度上取決于實(shí)驗(yàn)的觀察者數(shù)量。并且與問題2一樣�����,它并不是一個(gè)數(shù)據(jù)科學(xué)范疇的問題���,而是一個(gè)商業(yè)問題�����。因此需要根據(jù)經(jīng)驗(yàn)挑選一個(gè)合適的值��。
單面測試還是雙面測試(One-Sided or Two-Sided Test)��?
單面測試只能告訴你新的模型是否比基準(zhǔn)的是否更好���,而無法告訴你是否更糟。因此需要進(jìn)行雙面測試��,其不僅會(huì)告訴你新的模型是否會(huì)更好并且會(huì)告訴你是否更糟����。是否更好與是否更糟需要進(jìn)行分開對(duì)待。
多少的FP(False Positives)能夠忍受����?
比基準(zhǔn)模型更好,但是實(shí)際上確不是��。FP的代價(jià)取決于實(shí)際應(yīng)用���。如在醫(yī)藥中���,F(xiàn)P意味著病人使用無效藥,這樣便會(huì)對(duì)患者的健康造成很大的威脅����。又如在機(jī)器學(xué)習(xí)中���,F(xiàn)P意味著會(huì)使用一個(gè)認(rèn)為會(huì)更有效的但卻未更有效的模型來代替單前的模型。而FN意味著放棄了一個(gè)實(shí)際上會(huì)更有效的模型�����。
??統(tǒng)計(jì)假設(shè)檢驗(yàn)可以通過設(shè)定顯著性水平( the significance level)控制FP的概率����,并通過測試的力(the power of the test.)度來控制FN的概率。
需要多少觀察者�����?
觀察者的數(shù)量由期望的統(tǒng)計(jì)功效(statistical
power)部分決定�。而統(tǒng)計(jì)功效在測試進(jìn)行之前便需設(shè)定。一個(gè)常見的嘗試時(shí)運(yùn)行測試直到觀察到一個(gè)重要的結(jié)果���。這個(gè)方法是錯(cuò)誤的。測試的力度是能夠正確識(shí)別那些正樣本���。它能夠使用顯著性水平��、A組的評(píng)價(jià)指標(biāo)值與B組的評(píng)價(jià)指標(biāo)值之差、觀察者的個(gè)數(shù)這些去形式化地表示�。選擇合理的統(tǒng)計(jì)功效、顯著水平等����。然后選擇每組中觀察者的數(shù)量。StitchFix與Evan Miller’s website詳細(xì)地進(jìn)行了介紹��。
評(píng)價(jià)指標(biāo)是否滿足高斯分布
?A/B測試中絕大部分是使用T檢驗(yàn)����,但是T檢驗(yàn)的所做出的假設(shè)前提并不是所有的評(píng)價(jià)指標(biāo)都滿足的。一個(gè)好的方法便是去查看指標(biāo)的分布與檢查T檢驗(yàn)所做的假設(shè)是否有效����。T檢驗(yàn)假設(shè)是滿足高斯分布的,那么評(píng)價(jià)指標(biāo)釋放滿足高斯分布呢�?通常,使用中心極限定理可以得到任何獨(dú)立同分布并且具有期望與方差的隨機(jī)變量都收斂于高斯分布�����。不難得出,評(píng)價(jià)指標(biāo)假設(shè)以下條件成立:
* 指標(biāo)值是采用平均值
* 指標(biāo)值的分布是同一分布
* 指標(biāo)值分布是對(duì)稱的
但是還是會(huì)有一些指標(biāo)不滿足的�,如點(diǎn)擊率是一個(gè)平均值,但是AUC卻是一個(gè)積分值��。并且可能不服從同一分布���,如在A/B組中的用戶種群不一樣�����。同時(shí)�,也有可能不是對(duì)稱的��。Kohavi等例舉了一些例子說明評(píng)價(jià)指標(biāo)不服從高斯分布�,在這些例子中,標(biāo)準(zhǔn)誤差不會(huì)隨著測試的進(jìn)行而降低�����。比如那些計(jì)數(shù)評(píng)價(jià)指標(biāo)服從負(fù)二項(xiàng)式分布�����。當(dāng)這些假設(shè)不成立時(shí)�,分布遍不再收斂于高斯分布�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330