R語(yǔ)言與非參數(shù)統(tǒng)計(jì)(核密度估計(jì))
核密度估計(jì)是在概率論中用來(lái)估計(jì)未知的密度函數(shù),屬于非參數(shù)檢驗(yàn)方法之一,由Rosenblatt (1955)和Emanuel Parzen(1962)提出����,又名Parzen窗(Parzen window)��。
假設(shè)我們有n個(gè)數(shù)X1-Xn,我們要計(jì)算某一個(gè)數(shù)X的概率密度有多大���。核密度估計(jì)的方法是這樣的:
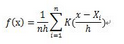
其中K為核密度函數(shù),h為設(shè)定的窗寬。
核密度估計(jì)的原理其實(shí)是很簡(jiǎn)單的�。在我們對(duì)某一事物的概率分布的情況下。如果某一個(gè)數(shù)在觀察中出現(xiàn)了����,我們可以認(rèn)為這個(gè)數(shù)的概率密度很大,和這個(gè)數(shù)比較近的數(shù)的概率密度也會(huì)比較大��,而那些離這個(gè)數(shù)遠(yuǎn)的數(shù)的概率密度會(huì)比較小���?�;谶@種想法�,針對(duì)觀察中的第一個(gè)數(shù),我們都可以f(x-xi)去擬合我們想象中的那個(gè)遠(yuǎn)小近大概率密度����。當(dāng)然其實(shí)也可以用其他對(duì)稱(chēng)的函數(shù)��。針對(duì)每一個(gè)觀察中出現(xiàn)的數(shù)擬合出多個(gè)概率密度分布函數(shù)之后�,取平均。如果某些數(shù)是比較重要�����,某些數(shù)反之����,則可以取加權(quán)平均。
但是核密度的估計(jì)并不是��,也不能夠找到真正的分布函數(shù)�����。我們可以舉一個(gè)極端的例子:在R中輸入:
plot(density(rep(0, 1000)))
可以看到它得到了正態(tài)分布的曲線��,但實(shí)際上呢?從數(shù)據(jù)上判斷�,它更有可能是一個(gè)退化的單點(diǎn)分布。
但是這并不意味著核密度估計(jì)是不可取的�����,至少他可以解決許多模擬中存在的異方差問(wèn)題�。比如說(shuō)我們要估計(jì)一下下面的一組數(shù)據(jù):
set.seed(10)
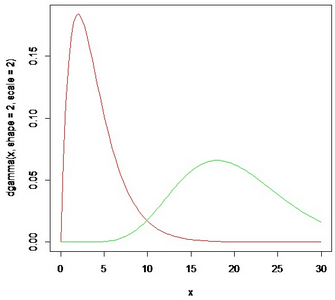
dat<-c(rgamma(300,shape=2,scale=2),rgamma(100,shape=10,scale=2))
可以看出它是由300個(gè)服從gamma(2,2)與100個(gè)gamma(10,2)的隨機(jī)數(shù)構(gòu)成的,他用參數(shù)統(tǒng)計(jì)的辦法是沒(méi)有辦法得到一個(gè)好的估計(jì)的���。那么我們嘗試使用核密度估計(jì):
plot(density(dat),ylim=c(0,0.2))
將利用正態(tài)核密度與標(biāo)準(zhǔn)密度函數(shù)作對(duì)比
dfn<-function(x,a,alpha1,alpha2,theta){
a*dgamma(x,shape=alpha1,scale=theta)+(1-a)*dgamma(x,shape=alpha2,scale=theta)}
pfn<-function(x,a,alpha1,alpha2,theta){
a*pgamma(x,shape=alpha1,scale=theta)+(1-a)*pgamma(x,shape=alpha2,scale=theta)}
curve(dfn(x,0.75,2,10,2),add=T,col="red")
得到下圖:
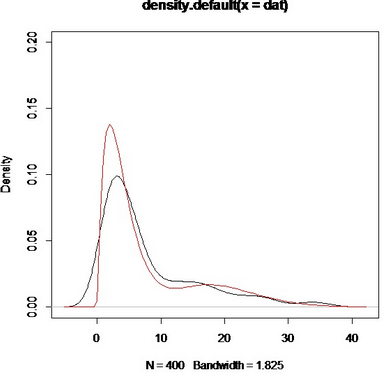
(紅色的曲線為真實(shí)密度曲線)
可以看出核密度與真實(shí)密度相比�����,得到大致的估計(jì)是不成問(wèn)題的��。至少趨勢(shì)是得到了的����。如果換用gamma分布的核效果無(wú)疑會(huì)更好�����,但是遺憾的是r中并沒(méi)有提供那么多的核供我們挑選(其實(shí)我們知道核的選擇遠(yuǎn)沒(méi)有窗寬的選擇來(lái)得重要)�,所以也無(wú)需介懷�����。
R中提供的核:kernel = c("gaussian", "epanechnikov", "rectangular", "triangular", "biweight","cosine", "optcosine")���。
我們先來(lái)看看窗寬的選擇對(duì)核密度估計(jì)的影響:
dfn1<-function(x){
0.5*dnorm(x,3,1)+0.5*dnorm(x,-3,1)}
par(mfrow=c(2,2))
curve(dfn1(x),from=-6,to=6)
data<-c(rnorm(200,3,1),rnorm(200,-3,1))
plot(density(data,bw=8))
plot(density(data,bw=0.8))
plot(density(data,bw=0.08))
得到下圖,我們可以清楚的看到帶寬為0.8恰好合適����,其余的不是擬合不足便是過(guò)擬合��。
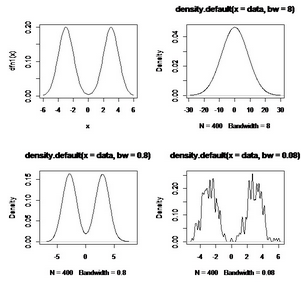
窗寬究竟該如何選擇呢���?
我們這里不加證明的給出最佳窗寬選擇公式:
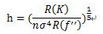
(這個(gè)基于積分均方誤差最小的角度得到的)
這里介紹兩個(gè)可操作的窗寬估計(jì)辦法:(這兩種方法都比較容易導(dǎo)致過(guò)分光滑)
1��、 Silverman大拇指法則
這里使用R(phi’’)/sigma^5估計(jì)R(f’’)��,phi代表標(biāo)準(zhǔn)正態(tài)密度函數(shù)�����,得到h的表達(dá)式:
h=(4/(3n))^(*1/5)*sigma
2�����、 極大光滑原則
h=3*(R(K)/(35n))^(1/5)*sigma
當(dāng)然也有比較麻煩的窗寬估計(jì)辦法��,比如缺一交叉驗(yàn)證�,插入法等,可以參閱《computational statistics》一書(shū)
我們用上面的兩種辦法得到的窗寬是多少��,他的核密度估計(jì)效果好嗎���?
我們還是以上面的混合正態(tài)數(shù)據(jù)為例來(lái)看看效果���。
使用大拇指法則,將數(shù)據(jù)n=400,sigma=3.030658,帶入公式�����,h=0.9685291
使用極大光滑原則�����,假設(shè)K為正態(tài)核��,R(K)=1/(sqrt(2*pi))�,h=1.121023
可以看出他們都比我們認(rèn)為的h=0.8要大一些,作圖如下:
plot(density(data,bw=0.9685))
plot(density(data,bw=1.1210))
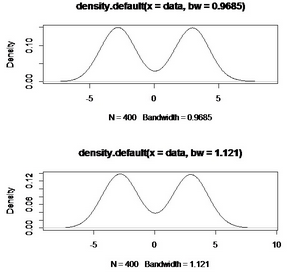
由我們給出的
以Gauss核為例做核密度估計(jì)

用Gauss核做核密度估計(jì)的R程序如下(還是使用我們的混合正態(tài)密度的例子):
ker.density=function(x,h){
x=sort(x)
n=length(x);s=0;t=0;y=0
for(i in 2:n)
s[i]=0
for(i in 1:n){
for(j in 1:n)
s[i]=s[i]+exp(-((x[i]-x[j])^2)/(2*h*h))
t[i]=s[i]
}
for(i in 1:n)
y[i]=t[i]/(n*h*sqrt(2*pi))
z=complex(re=x,im=y)
hist(x,freq=FALSE)
lines(z)
}
ker.density(data,0.8)
作圖如下:
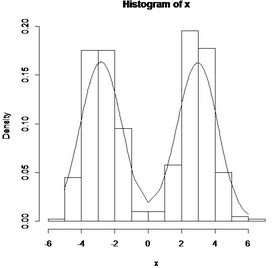
最后說(shuō)一個(gè)R的內(nèi)置函數(shù)density()。其實(shí)我覺(jué)得如果不是為了簡(jiǎn)要介紹核密度估計(jì)的一些常識(shí)我們完全可以只學(xué)會(huì)這個(gè)函數(shù)
先看看函數(shù)的基本用法:
density(x, ...)
## Default S3 method:
density(x, bw = "nrd0", adjust = 1,
kernel = c("gaussian", "epanechnikov", "rectangular",
"triangular", "biweight",
"cosine", "optcosine"),
weights = NULL, window = kernel, width,
give.Rkern = FALSE,
n = 512, from, to, cut = 3, na.rm = FALSE, ...)
對(duì)重要參數(shù)做出較為詳細(xì)的說(shuō)明:
X:我們要進(jìn)行核密度估計(jì)的數(shù)據(jù)
Bw:窗寬���,這里可以由我們自己制定�����,也可以使用默認(rèn)的辦法nrd0: Bandwidth selectors for Gaussian
kernels����。我們還可以使用bw.SJ(x,nb = 1000, lower = 0.1 * hmax, upper = hmax,
method = c("ste","dpi"), tol = 0.1 * lower)��,這里的method
=”dpi”就是前面提到過(guò)的插入法���,”ste”代表solve-the-equationplug-in����,也是插入法的改進(jìn)
Kernel:核的選擇
Weights:對(duì)比較重要的數(shù)據(jù)采取加權(quán)處理
對(duì)于上述混合正態(tài)數(shù)據(jù)data�����,有
> density(data)
Call:
density.default(x = data)
Data: data (400 obs.); Bandwidth 'bw' = 0.8229
x y
Min. :-7.5040 Min. :0.0000191
1stQu.:-3.5076 1st Qu.:0.0064919
Median : 0.4889 Median :0.0438924
Mean :0.4889 Mean :0.0624940
3rdQu.: 4.4853 3rd Qu.:0.1172919
Max. :8.4817 Max. :0.1615015
知道帶寬:h=0.8229(采取正態(tài)密度核)那么帶入密度估計(jì)式就可以寫(xiě)出密度估計(jì)函數(shù)����。
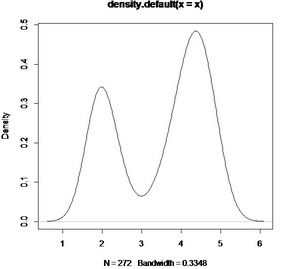
最后以faithful數(shù)據(jù)集為例說(shuō)明density的用法:
R數(shù)據(jù)集faithful是old faithful火山爆發(fā)的數(shù)據(jù)����,其中“eruption”是火山爆發(fā)的持續(xù)時(shí)間��,waiting是時(shí)間間隔
對(duì)數(shù)據(jù)“eruption”做核密度估計(jì)
R程序:
data(faithful)
A<-faithful
x<-A[,"eruptions"]
density(x)
plot(density(x))
知道h= 0.3348
作圖:
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)�����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330