R語言與抽樣技術(shù)學(xué)習(xí)筆記(bootstrap)
Bootstrap方法
Bootstrap一詞來源于西方神話故事“The adventures of Baron Munchausen”歸結(jié)出的短語“to pull oneself up by one's bootstrap",意味著不靠外界力量�,依靠自身提升性能。
Bootstrap的基本思想是:因?yàn)橛^測樣本包含了潛在樣本的全部的信息��,那么我們不妨就把這個樣本看做“總體”��。那么相關(guān)的統(tǒng)計(jì)工作(估計(jì)或者檢驗(yàn))的統(tǒng)計(jì)量的分布可以從“總體”中利用Monte
Carlo模擬得到。其做法可以簡單地概括為:既然樣本是抽出來的�,那我何不從樣本中再抽樣。
bootstrap基本方法
1����、采用重抽樣技術(shù)從原始樣本中抽取一定數(shù)量(自己給定)的樣本,此過程允許重復(fù)抽樣�����。
2����、根據(jù)抽出的樣本計(jì)算給定的統(tǒng)計(jì)量T。
3����、重復(fù)上述N次(一般大于1000),得到N個統(tǒng)計(jì)量T��。其均值可以視作統(tǒng)計(jì)量T的估計(jì)��。
4����、計(jì)算上述N個統(tǒng)計(jì)量T的樣本方差,得到統(tǒng)計(jì)量的方差�。
上述的估計(jì)我們可以看成是Bootstrap的非參數(shù)估計(jì)形式,它基本的思想是用頻率分布直方圖來估計(jì)概率分布���。當(dāng)然Bootstrap也有參數(shù)形式�,在已知分布下��,我們可以先利用總體樣本估計(jì)出對應(yīng)參數(shù)�,再利用估計(jì)出的分布做Monte
Carlo模擬,得到統(tǒng)計(jì)量分布的推斷���。
值得一提的是�,參數(shù)化的Bootstrap方法雖然不夠穩(wěn)健�����,但是對于不平滑的函數(shù)��,參數(shù)方法往往要比非參數(shù)辦法好��,當(dāng)然這是基于你對樣本的分布有一個初步了解的基礎(chǔ)上的���。
例如:我們要考慮均勻分布U(θ)的參數(shù)θ的估計(jì)����。我們采用似然估計(jì)。
data.sim <- runif(10)
theta.hat <- max(data.sim)
theta.boot1 <- replicate(1000, expr = {
y <- sample(data.sim, size = 10, replace = TRUE)
max(y)
})
theta.boot1.estimate <- mean(theta.boot1)
cat("the original estimate is ", theta.hat, "after bootstrap is ", theta.boot1.estimate)
## the original estimate is 0.7398 after bootstrap is 0.7138
[plain] view plain copy
print?
hist(theta.boot1)
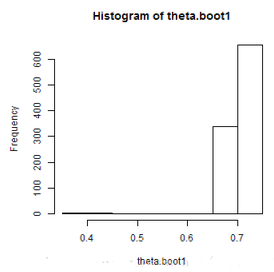
從結(jié)果來看�����,倒不是說估計(jì)有多不好�,只是說方差比較大,而且它的經(jīng)驗(yàn)分布真的不太像真正的分布��,這個近似很糟糕�,導(dǎo)致的直接結(jié)果是方差也很大。
如果采用參數(shù)方法���,我們再來看看:
theta.boot2 <- replicate(1000, expr = {
y <- runif(1000, 0, theta.hat)
max(y)
})
theta.boot2.estimate <- mean(theta.boot2)
cat("the original estimate is ", theta.hat, "after bootstrap is ", theta.boot2.estimate)
## the original estimate is 0.7398 after bootstrap is 0.7391
[plain] view plain copy
print?
hist(theta.boot2)
結(jié)果從直方圖來看是更優(yōu)秀了���,估計(jì)也更好一些,關(guān)鍵是方差變小了�����,從非參數(shù)的0.0402減少到了7.3944 × 10-4�����。
bootstrap推斷與bootstrap置信區(qū)間
既然我們已經(jīng)得到了Bootstrap估計(jì)量的經(jīng)驗(yàn)分布函數(shù),那么一個自然的結(jié)果就是我們可以利用這個分布對統(tǒng)計(jì)量做出一些統(tǒng)計(jì)推斷�����。例如可以推測估計(jì)量的方差����,估計(jì)量的偏差�,估計(jì)量的置信區(qū)間等。
現(xiàn)在�����,我們就來考慮如何做Bootstrap的統(tǒng)計(jì)推斷�����。
利用Bootstrap估計(jì)偏差
既然Bootstrap將獲得的樣本樣本看成了”總體“�����,那么估計(jì)量T自然是一個無偏的估計(jì)��,Bootstrap數(shù)據(jù)集構(gòu)造的”樣本“的統(tǒng)計(jì)量T與原始估計(jì)量T的偏差自然就是估計(jì)量偏差的一個很好的估計(jì)。
具體做法是:
1. 從原始樣本x1,?,xn中有放回的抽取n個樣本構(gòu)成一個Bootstrap數(shù)據(jù)集�����,重復(fù)這個過程m次�����,得到m個數(shù)據(jù)集�。
2. 對于每個Bootstrap數(shù)據(jù)集,計(jì)算估計(jì)量T的值�����,記為T?j�。
3.T?j的均值是T的無偏估計(jì),而其與T的差是偏差的估計(jì)���。
利用Bootstrap估計(jì)方差
估計(jì)量T的方差的估計(jì)可以看做每個Bootstrap數(shù)據(jù)集的統(tǒng)計(jì)量T的值的方差��。
以我們遺留的問題�,求1到100中隨機(jī)抽取10個數(shù)的中位數(shù)的方差為例來說明��。
n <- 10
x <- sample(1:100, size = n)
Mboot <- replicate(1000, expr = {
y <- sample(x, size = n, replace = TRUE)
median(y)
})
print(var(Mboot))
## [1] 334.2
這個應(yīng)該是一個正確的估計(jì)了�。Efron指出要得到標(biāo)準(zhǔn)差的估計(jì)并不需要非常多的Bootstrap數(shù)據(jù)集(m不需要過分的大)�,通常50已經(jīng)不錯了�,m>200是比較少見的(區(qū)間估計(jì)可能需要多一些)
在R中,bootstrap包的函數(shù)bootstrap可以幫助你完成這一過程�。bootstrap函數(shù)的調(diào)用格式如下:
bootstrap(x,nboot,theta,…, func=NULL)
參數(shù)說明:
x:原始抽樣數(shù)據(jù)
theta:統(tǒng)計(jì)量T
nboot:構(gòu)造Bootstrap數(shù)據(jù)集個數(shù)
library(bootstrap)
theta <- function(x) {
median(x)
}
results <- bootstrap(x, 100, theta)
print(var(results$thetastar))
## [1] 393.2
可以看到兩個的結(jié)果是相近的,所以�����,利用這個函數(shù)還是不錯的選擇��。類似的還有boot包的boot函數(shù)����。我們在相關(guān)數(shù)據(jù)的Bootstrap推斷中會用到���。
相關(guān)數(shù)據(jù)的Bootstrap推斷
回歸數(shù)據(jù)的Bootstrap推斷
我們之所以可以采用Bootstrap去做這些估計(jì)���,蘊(yùn)含了一個很重要的假設(shè),這些樣本是近似iid的����,然而我們不能保證需要推斷的數(shù)據(jù)都是近似獨(dú)立同分布的,對于相關(guān)數(shù)據(jù)的Bootstrap推斷�����,我們常用的方法有配對的Bootstrap(paired
Bootstrap)與殘差法。
先說paired Bootstrap����,它的基本想法是,對于觀測構(gòu)成的數(shù)據(jù)框�,雖然觀測的每一行數(shù)據(jù)是相關(guān)的,但是每行是獨(dú)立的���,我們Bootstrap抽樣��,每次抽取一行�,而不是單獨(dú)的抽一個數(shù)即可���。
例如�����,數(shù)據(jù)集women列出了美國女性的平均身高與體重�,我們以體重為響應(yīng)變量���,身高為協(xié)變量進(jìn)行回歸�����,得到回歸系數(shù)的估計(jì)��。
使用paired Bootstrap:
m <- 200
n <- nrow(women)
beta <- numeric(m)
for (b in 1:m) {
i <- sample(1:n, size = n, replace = TRUE)
weight <- women$weight[i]
height <- women$height[i]
beta[b] <- lm(weight ~ height)$coef[2]
}
cat("the estimate of beta is", lm(weight ~ height, data = women)$coef[2], "paired bootstrap estimate is",
mean(beta))
## the estimate of beta is 3.45 paired bootstrap estimate is 3.452
cat("the bias is", lm(weight ~ height, data = women)$coef[2] - mean(beta), "the stand error is",
sd(beta))
## the bias is -0.002468 the stand error is 0.126
我們可以看到���,估計(jì)量是無偏的����,但是這個辦法估計(jì)的方差變化較小���,可能導(dǎo)致區(qū)間估計(jì)是不夠穩(wěn)健。我們可以利用boot包的boot函數(shù)來解決�����。
beta <- function(x, i) {
xi <- x[i, ]
coef(lm(xi[, 2] ~ xi[, 1]))[2]
}
library(boot)
obj <- boot(data = women, statistic = beta, R = 2000)
obj
##
## ORDINARY NONPARAMETRIC BOOTSTRAP
##
##
## Call:
## boot(data = women, statistic = beta, R = 2000)
##
##
## Bootstrap Statistics :
## original bias std. error
## t1* 3.45 -0.002534 0.1208
接下來我們說說殘差法:
1. 由觀測數(shù)據(jù)擬合模型.
2. 獲得響應(yīng)y^i與殘差?i
3. 從殘差數(shù)據(jù)集中有放回的抽取殘差��,構(gòu)成Bootstrap殘差數(shù)據(jù)集?^i(這是近似獨(dú)立的)
4. 構(gòu)造偽響應(yīng)Y?i=yi+?^i
5. 對x回歸偽響應(yīng)Y����,得到希望得到的統(tǒng)計(jì)量,重復(fù)多次���,得到希望的統(tǒng)計(jì)量的經(jīng)驗(yàn)分布�����,利用它做統(tǒng)計(jì)推斷
我們將women數(shù)據(jù)集的例子利用殘差法在做一次����,R代碼如下:
lm.reg <- lm(weight ~ height, data = women)
y.fit <- predict(lm.reg)
y.res <- residuals(lm.reg)
y.bootstrap <- rep(1, 15)
beta <- NULL
for (p in 1:100) {
for (i in 1:15) {
res <- sample(y.res, 1, replace = TRUE)
y.bootstrap[i] <- y.fit[i] + res
}
beta[p] <- lm(y.bootstrap ~ women$height)$coef[2]
}
cat("the estimate of beta is", lm(weight ~ height, data = women)$coef[2], "paired bootstrap estimate is",
mean(beta))
## the estimate of beta is 3.45 paired bootstrap estimate is 3.436
cat("the bias is", lm(weight ~ height, data = women)$coef[2] - mean(beta), "the stand error is",
sd(beta))
## the bias is 0.01436 the stand error is 0.08561
可以看到,利用殘差法得到的方差更為穩(wěn)健�����,做出的估計(jì)也更為的合理�。
這里需要指出一點(diǎn),Bootstrap雖然可以處理相關(guān)數(shù)據(jù)�����,但是在變量篩選方面����,其效果遠(yuǎn)不如Cross Validation準(zhǔn)則好。
時(shí)間序列數(shù)據(jù)中的Bootstrap方法
還有一類數(shù)據(jù)的相關(guān)性是上述假定也不滿足的����,那就是時(shí)間序列數(shù)列����。那么如何利用Bootstrap來推斷時(shí)間序列呢����?我們以1947年–1991年美國GNP季度增長率數(shù)據(jù)為例進(jìn)行說明。這個數(shù)據(jù)來自《金融時(shí)間序列分析》一書��,數(shù)據(jù)可以在這里下載���。
我們先來了解一下這個數(shù)據(jù):
data <- read.table("D:/R/data/dgnp82.txt")
gnp <- data * 100
gnp1 <- ts(gnp, fre = 4, start = c(1947, 2))
par(mfrow = c(3, 1))
plot(gnp1, type = "l")
acf(gnp1, lag = 24)
pacf(gnp1, lag = 24)
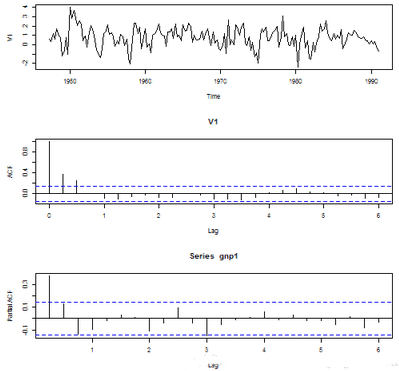
對于這個數(shù)據(jù)集����,假設(shè)我想利用這些增長率估計(jì)平均增長率����,顯然直接從這些數(shù)據(jù)中有放回抽樣是不合理的����,因?yàn)樗鼈兪窍嘁赖模凑战鹑诘恼f法����,它們還存在波動性聚集�����。但是我們?nèi)匀徊环料冗@么計(jì)算��,可以與之后的“正確”結(jié)果對比一下�����。
<pre code_snippet_id="302224" snippet_file_name="blog_20140419_13_5757445" name="code" class="plain">mean.boot <- replicate(1000, expr = {
y <- sample(gnp1, size = 0.5 * length(gnp1), replace = TRUE)
mean(y)
})
cat("mean estimate is:", (mean.boot.estimate <- mean(mean.boot)), "variance is:",
var(mean.boot))</pre>
## mean estimate is: 0.7691 variance is: 0.01215
對于這類問題����,一個利用我們前面描述的辦法可以解決的方案就是利用參數(shù)的Bootstrap方法�。我們可以先考慮對時(shí)間序列建模:
library(tseries)
adf.test(gnp1)
##
## Augmented Dickey-Fuller Test
##
## data: gnp1
## Dickey-Fuller = -5.153, Lag order = 5, p-value = 0.01
## alternative hypothesis: stationary
我們從上面的圖片以及平穩(wěn)性檢驗(yàn)很快就可以發(fā)現(xiàn),AR(3)是對這個時(shí)間序列的不錯的描述��,那么我們先求取這個模型的參數(shù)估計(jì):
model <- arima(gnp1, order = c(3, 0, 0))
tsdiag(model)
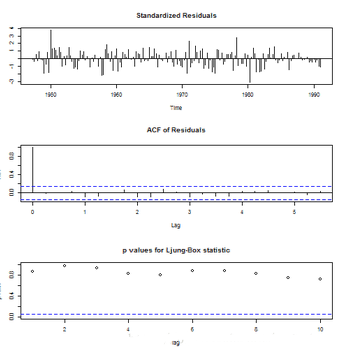
那么我們的參數(shù)Bootstrap可以這么做:
simu <- function(model) {
n <- 1000 # Generate AR(3) process
a <- as.numeric(coef(model))
e <- rnorm(n + 200, 0, sqrt(9.48e-05))
x <- double(n + 200)
x[1:3] <- rnorm(3)
for (i in 4:(n + 100)) {
x[i] <- a[1] * x[i - 1] + a[2] * x[i - 2] + a[3] * x[i - 3] + a[4] +
e[i]
}
x <- ts(x[-(1:200)])
mean(x)
}
mean.boot1 <- replicate(1000, expr = simu(model))
cat("mean estimate is:", (mean.boot.estimate <- mean(mean.boot)), "variance is:",
var(mean.boot))
## mean estimate is: 0.7691 variance is: 0.01215
可以看到兩者的結(jié)果是差不多的��,究其原因是因?yàn)檫@是一個平穩(wěn)過程��,所以相差不大�,我們來看一個非平穩(wěn)的例子,很快就能發(fā)現(xiàn)不同:
data.sim <- arima.sim(list(order = c(2, 2, 0), ar = c(0.7, 0.2)), n = 500)
cat("mean is:", mean(data.sim))
## mean is: -5574## [1] "In the iid case:"
mean.boot <- replicate(1000, expr = {
y <- sample(data.sim, size = 2 * length(data.sim), replace = TRUE)
mean(y)
})
cat("mean estimate is:", (mean.boot.estimate <- mean(mean.boot)), "variance is:",
var(mean.boot))
## mean estimate is: -5560 variance is: 86089## [1] "In the dependence case:"
model <- arima(data.sim, order = c(2, 2, 0))
simu <- function(model) {
x <- arima.sim(list(order = c(2, 2, 0), ar = as.numeric(coef(model))), n = 500)
mean(x)
}
mean.boot1 <- replicate(1000, expr = simu(model))
cat("mean estimate is:", (mean.boot.estimate <- mean(mean.boot)), "variance is:",
var(mean.boot))
## mean estimate is: -5560 variance is: 86089
但是這種明顯需要知道模型����,或者正確模型設(shè)定才能得到比較好的結(jié)果的Bootstrap是不穩(wěn)健的�����,如果上面我們采用了一個非真實(shí)的模型�����,結(jié)果會變?yōu)椋?
(model <- arima(data.sim, order = c(5, 3, 1)))
##
## Call:
## arima(x = data.sim, order = c(5, 3, 1))
##
## Coefficients:
## ar1 ar2 ar3 ar4 ar5 ma1
## -1.149 -0.260 -0.137 -0.142 -0.024 0.897
## s.e. 0.121 0.074 0.069 0.070 0.048 0.112
##
## sigma^2 estimated as 1.02: log likelihood = -713.5, aic = 1441
從建模的角度來說�,這個也是不錯的一個模型���,那么它的估計(jì)可以由下面代碼給出:
simu <- function(model) {
x <- arima.sim(list(order = c(5, 3, 1), ar = as.numeric(coef(model))[1:5],
ma = as.numeric(coef(model))[6]), n = 500, sd = sqrt(1.067))
mean(x)
}
mean.boot1 <- replicate(1000, expr = simu(model))
cat("mean estimate is:", (mean.boot.estimate <- mean(mean.boot)), "variance is:",
var(mean.boot))
## mean estimate is: -5560 variance is: 86089
我們可以想見����,在置信區(qū)間上這會給出一個比較寬的置信區(qū)間�,這很有可能是我們不想見到的。那么�����,我們有沒有穩(wěn)健些的非參數(shù)方法呢�����?這是有的����,這個方法通常被稱為“Block Bootstrap”方法。
Block Bootstrap的思想很簡單�,雖然時(shí)間序列存在相關(guān),但是自相關(guān)系數(shù)可能在若干延遲后就可以忽略不計(jì)了���。那么我們?nèi)∫粋€區(qū)間長度�,將整個樣本分為若干個區(qū)間����,序列的順序不改變,而區(qū)間之間看做近似獨(dú)立的�,我們對這些區(qū)間(block)做Bootstrap。如果區(qū)間間不存在重疊��,我們稱之為"Nonmoving block bootstrap";如果區(qū)間存在重疊(如樣本為1, 2, 3, 4, 5, 6, 7, 8, 9, 10����,我們將區(qū)間分為就可以稱作"Moving block bootstrap"。
我們還是來考慮GNP數(shù)據(jù)�����,我們假設(shè)block長度為6,去掉前2個數(shù)據(jù)����。利用"Nonmoving block bootstrap"我們有:
data <- read.table("D:/R/data/dgnp82.txt")
gnp <- data * 100
blocks <- gnp[1:6, 1]
for (i in 2:(length(gnp[, 1]) - 5)) {
blocks <- rbind(blocks, gnp[i:(i + 5), 1])
}
# MOVING BLOCK BOOTSTRAP
xbar <- NULL
for (i in 1:10000) {
take.blocks <- sample(1:(length(gnp[, 1]) - 5), 29, replace = TRUE)
newdat = c(t(blocks[take.blocks, ]))
xbar[i] = mean(newdat)
}
hist(xbar)
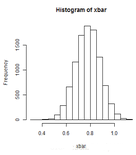
## the mean estimate is 0.7781 the sample standard deviation is 0.1016
對于Moving block bootstrap,我們有:
data <- read.table("D:/R/data/dgnp82.txt")
gnp <- data * 100
blocks <- gnp[1:6, 1]
for (i in 2:(length(gnp[, 1]) - 5)) {
blocks <- rbind(blocks, gnp[i:(i + 5), 1])
}
# MOVING BLOCK BOOTSTRAP
xbar <- NULL
for (i in 1:10000) {
take.blocks <- sample(1:(length(gnp[, 1]) - 5), 29, replace = TRUE)
newdat = c(t(blocks[take.blocks, ]))
xbar[i] = mean(newdat)
}
hist(xbar)
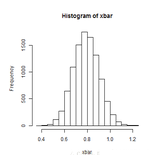
## the mean estimate is 0.7896 the sample standard deviation is 0.1114
在tseries包中提供了tsbootstrap函數(shù)�����,來完成block Bootstrap過程�。函數(shù)調(diào)用格式如下:
tsbootstrap(x, nb = 1, statistic = NULL, m = 1, b = NULL, type = c(“stationary”,“block”), …)
參數(shù)說明:
x:原始數(shù)據(jù),必須是數(shù)值向量或時(shí)序列
nb:Bootstrap數(shù)據(jù)集個數(shù)
statistic:Bootstrap統(tǒng)計(jì)量
我們可以將上面的例子利用tsbootstrap函數(shù)再算一次:
data <- read.table("D:/R/data/dgnp82.txt")
gnp <- data * 100
gnp1 <- ts(gnp, fre = 4, start = c(1947, 2))
tsbootstrap(gnp1, nb = 500, mean, type = "block")
##
## Call:
## tsbootstrap(x = gnp1, nb = 500, statistic = mean, type = "block")
##
## Resampled Statistic(s):
## original bias std. error
## 0.7741 0.0316 0.1056
這與我們算的也差不多�。
最后,我們提一下自相關(guān)系數(shù)的Bootstrap估計(jì)��,這個有些類似多元統(tǒng)計(jì)中用到的拉直變換的逆變換�,我們僅通過tsbootstrap提供的example來看看,具體內(nèi)容可以參閱Paolo Giudici et al.的*Computational Statistic*一書����。
n <- 500 # Generate AR(1) process
a <- 0.6
e <- rnorm(n + 100)
x <- double(n + 100)
x[1] <- rnorm(1)
for (i in 2:(n + 100)) {
x[i] <- a * x[i - 1] + e[i]
}
x <- ts(x[-(1:100)])
acflag1 <- function(x) {
xo <- c(x[, 1], x[1, 2])
xm <- mean(xo)
return(mean((x[, 1] - xm) * (x[, 2] - xm))/mean((xo - xm)^2))
}
tsbootstrap(x, nb = 500, statistic = acflag1, m = 2)
##
## Call:
## tsbootstrap(x = x, nb = 500, statistic = acflag1, m = 2)
##
## Resampled Statistic(s):
## original bias std. error
## 0.61538 -0.00549 0.02701
Bootstrap置信區(qū)間
說到Bootstrap推斷總會說到假設(shè)檢驗(yàn)與置信區(qū)間。那么Bootstrap的置信區(qū)間如何求解呢���?
一般來說有以下幾種方法:
標(biāo)準(zhǔn)正態(tài)Bootstrap置信區(qū)間
基本Bootstrap置信區(qū)間
分位數(shù)Bootstrap置信區(qū)間
Bootstrap t置信區(qū)間
BCa 置信區(qū)間
先說說標(biāo)準(zhǔn)正態(tài)Bootstrap置信區(qū)間��,這是通過構(gòu)造偽Z統(tǒng)計(jì)量(\( z=\frac{\hat{\theta}-E(\hat{\theta})}{se(\hat{\theta})} \)),假設(shè)Z服從正態(tài)分布,根據(jù)Z的分位數(shù)來構(gòu)造置信區(qū)間��,當(dāng)然假設(shè)Z服從t分布也是可以的�����。
基本的Bootstrap置信區(qū)間是由置信區(qū)間的定義\[ P ( L < \hat{\theta}-\theta < U )=1- \alpha \]得到的啟發(fā),利用Bootstrap分位數(shù)\( \hat{\theta}_{U}^{*} \)和\( \hat{\theta}_{L}^{*} \)來估計(jì)統(tǒng)計(jì)量的置信區(qū)間���,即通過\[ P(\hat{\theta}_{L}^{*}-\hat{\theta}<\theta^{*}-\hat{\theta}<\hat{\theta}_{U}^{*}-\hat{\theta})\approx1-\alpha
\]可以將區(qū)間估計(jì)為:\[ (2\hat{\theta} - \hat{\theta}_{U}^{*}\hspace{1em} ,\hspace{1em} 2\hat{\theta}-\hat{\theta}_{L}^{*}) \]
分位數(shù)Bootstrap的想法比較簡單:既然我們將Bootstrap數(shù)據(jù)集求出的統(tǒng)計(jì)量的經(jīng)驗(yàn)分布視為統(tǒng)計(jì)量的分布��,那么它的置信區(qū)間自然就應(yīng)該是這個統(tǒng)計(jì)量的上下兩側(cè)的分位數(shù)����。
Bootstrap t置信區(qū)間又稱為學(xué)生Bootstrap置信區(qū)間��,它是通過Bootstrap構(gòu)造偽t統(tǒng)計(jì)量(\( t=\frac{\hat{\theta}-E(\hat{\theta})}{se(\hat{\theta})} \))���,這與正態(tài)Bootstrap置信區(qū)間類似����,但是這與正態(tài)Bootstrap不同的是�����,統(tǒng)計(jì)量t并不是簡單的服從student-t分布,而是構(gòu)造Bootstrap數(shù)據(jù)集時(shí)���,利用這個Bootstrap數(shù)據(jù)集再次進(jìn)行Bootstrap�����,得到一個t統(tǒng)計(jì)量���,由于我們有m個Bootstrap數(shù)據(jù)集,那么我們就有m個t統(tǒng)計(jì)量�����,利用這些t統(tǒng)計(jì)量的分位數(shù)作為t分布的分位數(shù)����,求取置信區(qū)間。這里我們嵌套了一個Bootstrap是為了求出偽t統(tǒng)計(jì)量的方差�,這在一些文獻(xiàn)中又被稱為經(jīng)驗(yàn)Bootstrap
t置信區(qū)間。我們有時(shí)也會利用delta method 求解t統(tǒng)計(jì)量的方差���,它的好處就在于不需要通過額外的Bootstrap求解方差了�����,時(shí)間上有優(yōu)化����,但是精度方面���,究竟誰最優(yōu)�����,還是有待商榷的��。
BCa區(qū)間的想法是:分位數(shù)Bootstrap置信區(qū)間可能由于偏差或者偏度使得估計(jì)量沒有那么好的覆蓋率�,我們聲稱的置信水平\( \alpha \)可能并不對應(yīng)\( \alpha \)分位數(shù)����,那么我就對估計(jì)量施加一個變換,使得它的偏差與偏度得到修正��,那么就找到\( \alpha \)實(shí)際對應(yīng)的分位數(shù)����,利用實(shí)際的分位數(shù)給出估計(jì)。這是由Efron于1987年提出的����,如果偏差與偏度都是0的話�,它就是分位數(shù)法求出的置信區(qū)間了����。偏差的修正是利用中位數(shù)的偏差來進(jìn)行修正,偏度的修正是利用Jackknife估計(jì)得到的�。
boot包里的boot.ci函數(shù)可以輕松地計(jì)算這5種置信區(qū)間,其調(diào)用格式為:
boot.ci(boot.out, conf = 0.95, type = “all”, index = 1:min(2,length(boot.out$t0)), var.t0 = NULL, var.t = NULL, t0 = NULL, t = NULL, L = NULL, h = function(t) t, hdot = function(t) rep(1,length(t)), hinv = function(t) t, …)
我們以computational statistics一書的Copper-Nickel Alloy數(shù)據(jù)為例說明這個函數(shù)的使用:
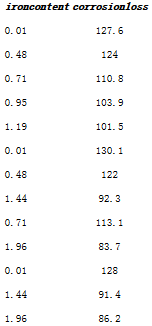
這個數(shù)據(jù)是關(guān)于金屬腐蝕與金屬體積的數(shù)據(jù)�����,我們要估計(jì)的估計(jì)量為以腐蝕損失為響應(yīng)變量的回歸的自變量回歸系數(shù)與截距項(xiàng)之比�,(這里我們不考慮估計(jì)量的意義),這里我們可以利用delta方法��,認(rèn)為估計(jì)量就是兩個回歸系數(shù)的估計(jì)量之比��。
theta.boot <- function(dat, ind) {
y <- dat[ind, 1]
z <- dat[ind, 2]
theta <- as.numeric(coef(lm(z ~ y))[2]/coef(lm(z ~ y))[1])
model <- lm(z ~ y)
cov.m <- summary(lm(z ~ y))$cov
theta.var <- (theta^2) * (cov.m[2, 2]/(model$coef[2]^2) + cov.m[1, 1]/(model$coef[1]^2) -
2 * cov.m[1, 2]/(prod(model$coef)))
theta.var <- as.numeric((theta.var))
c(theta, theta.var)
}
dat <- read.table("D:/R/data/alloy.txt", head = TRUE)
boot.obj <- boot(dat, statistic = theta.boot, R = 2000)
print(boot.obj)
##
## ORDINARY NONPARAMETRIC BOOTSTRAP
##
##
## Call:
## boot(data = dat, statistic = theta.boot, R = 2000)
##
##
## Bootstrap Statistics :
## original bias std. error
## t1* -1.851e-01 -1.270e-03 8.342e-03
## t2* 7.466e-06 1.373e-06 3.244e-06
print(boot.ci(boot.obj))
## BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
## Based on 2000 bootstrap replicates
##
## CALL :
## boot.ci(boot.out = boot.obj)
##
## Intervals :
## Level Normal Basic Studentized
## 95% (-0.2002, -0.1675 ) (-0.1971, -0.1649 ) (-0.1978, -0.1690 )
##
## Level Percentile BCa
## 95% (-0.2053, -0.1730 ) (-0.2030, -0.1722 )
## Calculations and Intervals on Original Scale
這里的Bootstrap t利用的就是delta方法求解估計(jì)量\( \theta \)的方差的����,與經(jīng)驗(yàn)Bootstrap t有那么一點(diǎn)點(diǎn)的區(qū)別,我們這里也報(bào)告一個經(jīng)驗(yàn)Bootstrap t的置信區(qū)間好了:
boot.t.ci <- function(x, B = 500, R = 100, level = 0.95, statistic) {
# compute the bootstrap t CI
x <- as.matrix(x)
n <- nrow(x)
stat <- numeric(B)
se <- numeric(B)
boot.se <- function(x, R, f) {
# local function to compute the bootstrap estimate of standard error for
# statistic f(x)
x <- as.matrix(x)
m <- nrow(x)
th <- replicate(R, expr = {
i <- sample(1:m, size = m, replace = TRUE)
f(x[i, ])
})
return(sd(th))
}
for (b in 1:B) {
j <- sample(1:n, size = n, replace = TRUE)
y <- x[j, ]
stat[b] <- statistic(y)
se[b] <- boot.se(y, R = R, f = statistic)
}
stat0 <- statistic(x)
t.stats <- (stat - stat0)/se
se0 <- sd(stat)
alpha <- 1 - level
Qt <- quantile(t.stats, c(alpha/2, 1 - alpha/2), type = 1)
names(Qt) <- rev(names(Qt))
CI <- rev(stat0 - Qt * se0)
}
stat <- function(dat) {
z <- dat[, 2]
y <- dat[, 1]
theta <- as.numeric(coef(lm(z ~ y))[2]/coef(lm(z ~ y))[1])
}
ci <- boot.t.ci(dat, statistic = stat, B = 200, R = 50)
print(ci)
## 2.5% 97.5%
## -0.2030 -0.1688
這個程序運(yùn)行十分緩慢����,我們看看他的運(yùn)行時(shí)間:
system.time(boot.t.ci(dat, statistic = stat, B = 200, R = 50))
## user system elapsed## 34.46 0.04 35.32
這對于我的落后的電腦來說是個很大的打擊���,估計(jì)要是不是R而是C++,matlab的話�����,可能會死掉吧����。所以可以用delta method求解近似的估計(jì)問題���,還是謹(jǐn)慎的使用經(jīng)驗(yàn)Bootstrap t吧�����。還有這里都是使用paired Bootstrap給出的估計(jì)�,你可以用殘差法試試�����,看看估計(jì)區(qū)間會不會更大些�����。
Jackknife after bootstrap
我們前面介紹了利用Bootstrap估計(jì)給出偏差與方差的估計(jì),而這些Bootstrap本身又是一個估計(jì)量�����,我們也想知道這個估計(jì)量的好壞�����,那么它們的偏差�,方差怎么估計(jì)呢?再用一次Bootstrap��,或者用一次Jackknife是一個不錯的選擇��,但是這個效率是十分低下的���,我們看經(jīng)驗(yàn)Bootstrap就知道了�,這是一個讓人很厭煩的過程����,在這里我們絕對不會再一次重復(fù)這個讓人火大的操作。萬幸的是����,我們有一個稍微好些的辦法來解決這個問題����,這就是著名的Jackknife after Bootstrap�����。
我們將算法描述如下:
記\( X_{i}^{*} \)為一次Bootstrap抽樣��,\( X_{1}^{*},\cdots,X_{B}^{*} \)是樣本大小為B的Bootstrap數(shù)據(jù)集���,令\( J(i) \)表示不含總體樣本的元素\( x_{i} \)的Bootstrap數(shù)據(jù)集,我們利用\( J(i) \)作為一次Jackknife重復(fù)���,這有點(diǎn)類似delete-K Jackknife�,標(biāo)準(zhǔn)差估計(jì)量的Jackknife估計(jì)為\[ \hat{se}_{jack}(\hat{se}_{Boot}(\hat{\theta}))=\sqrt{\frac{n-1}{n}\sum_{i=1}^{n}(\hat{se}_{Boot(i)}-\overline{\hat{se}_{Boot(\cdot)}})^2}\\\hat{se}_{Boot(i)}=\sqrt{\frac{1}{B(i)}\sum_{j\in
J(i)}(\hat{\theta}_{(j)}-\overline{\hat{\theta}_{(J(i))}})^2}\\\overline{\hat{\theta}_{(J(i))}}=\frac{1}{B(i)}\sum_{j\in J(i)}\hat{\theta}_{(j)} \]其中B(i)表示不含\( x_{i} \)的樣本個數(shù)����。
我們來看金屬腐蝕與金屬體積數(shù)據(jù)的估計(jì)量的方差的方差的估計(jì):
dat <- read.table("D:/R/data/alloy.txt", head = TRUE)
n <- nrow(dat)
y <- dat[, 2]
z <- dat[, 1]
B <- 2000
theta.b <- numeric(B)
# set up storage for the sampled indices
indices <- matrix(0, nrow = B, ncol = n)
# jackknife-after-bootstrap step 1: run the bootstrap
for (b in 1:B) {
i <- sample(1:n, size = n, replace = TRUE)
y <- dat[i, 2]
z <- dat[i, 1]
theta.b[b] <- as.numeric(coef(lm(z ~ y))[2]/coef(lm(z ~ y))[1])
# save the indices for the jackknife
indices[b, ] <- i
}
# jackknife-after-bootstrap to est. se(se)
se.jack <- numeric(n)
for (i in 1:n) {
# in i-th replicate omit all samples with x[i]
keep <- (1:B)[apply(indices, MARGIN = 1, FUN = function(k) {
!any(k == i)
})]
se.jack[i] <- sd(theta.b[keep])
}
print(sd(theta.b))
## [1] 8.838e-05
Bootstrap的方差縮減問題
要知道方差縮減,首先需要明白方差來源于何處��?對于Bootstrap而言����,方差的來源主要有兩個方面:一個是原始樣本抽樣的方差����,另一個是Bootstrap抽樣產(chǎn)生的方差��。
原始樣本抽樣的方差在這里我們假定是沒法改進(jìn)的���,那么Bootstrap抽樣的方差該如何減少呢���?這可以借鑒Monte Carlo中的方差縮減技術(shù),采用重要抽樣�����,關(guān)聯(lián)抽樣等辦法���,其中關(guān)聯(lián)抽樣的方法運(yùn)用于Bootstrap�����,就產(chǎn)生了平衡Bootstrap與方向Bootstrap兩種方法�����。
Further reading
看上去我們已經(jīng)較為完善的討論了隨機(jī)化檢驗(yàn)��、Jackknife�、Bootstrap的基本內(nèi)容,但是我們還是有很多沒涉及到的東西��,特別是在時(shí)間序列的Bootstrap里關(guān)于block長度的確定�,Bootstrap效率分析等。Shao和Tu(1995),Li和Maddala(1996)都較為詳盡的討論了Bootstrap在時(shí)間序列中的應(yīng)用����,后者還添加了不少Bootstrap在經(jīng)濟(jì)學(xué)中的應(yīng)用。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330