一句python,一句R︱python中的字符串操作����、中文亂碼、NaN情況
先學(xué)了R,最近剛剛上手Python,所以想著將python和R結(jié)合起來互相對(duì)比來更好理解python����。最好就是一句python,對(duì)應(yīng)寫一句R�。
pandas可謂如雷貫耳,數(shù)據(jù)處理神器���。
以下符號(hào):
=R=
代表著在R中代碼是怎么樣的。
————————————————————————————————————————————
字符編碼
encode 和 decode
Python2 默認(rèn)的編碼是 ascii�����,通過 encode 可以將對(duì)象的編碼轉(zhuǎn)換為指定編碼格式(稱作“編碼”)���,而 decode 是這個(gè)過程的逆過程(稱作“解碼”)����。
decode�����,將字節(jié)串轉(zhuǎn)變?yōu)樽址?,并且這個(gè)字符串是按照 unicode 編碼的。在 unicode 編碼中,一個(gè)漢字對(duì)應(yīng)一個(gè)字符�����,這時(shí)候度量它的長度就是 1.
encode��,一個(gè) unicode 編碼的字符串�,也可以轉(zhuǎn)換為字節(jié)串。
[html] view plain copy
print?
>>> a = "中"
>>> a
'\xe4\xb8\xad'
>>> b = a.decode()
>>> b
u'\u4e2d'
其中�����,a就是ASCII格式的編碼�,字節(jié)串;b就是unicode編碼的字符串�����。當(dāng)然有一個(gè)問題就是最后出來的還不是漢字�。。���。(醉?。?br />
————————————————————————————————————————————
一�、字符形成����、展示���、拼接����、切片
1����、字符形成=R=paste
雙引號(hào)包裹單引號(hào)
[html] view plain copy
print?
>>> "What's your name?"
"What's your name?"
單引號(hào)使用轉(zhuǎn)義符
[html] view plain copy
print?
>>> 'What\'s your name?'
"What's your name?"
2、字符串展示print /raw_input
[html] view plain copy
print?
>>> name = raw_input("input your name:")
input your name:python
>>> name
'python'
其中raw_input有點(diǎn)交互關(guān)系�,具體看案例��,直接鍵入name就可以獲得你輸入的內(nèi)容�����。
[html] view plain copy
print?
>>> print("hello, world")
hello, world
3��、字符切片�����、選擇、截取 =R=無
字符可以像一般的數(shù)據(jù)格式一樣進(jìn)行切片選擇���,有點(diǎn)像series:
[html] view plain copy
print?
>>> lang = "study Python"
>>> lang[0]
's'
>>> lang[2:9]
'udy pyt'
當(dāng)然也包括lang[:]可以選中所有的�����。
其中index代表著某個(gè)字符的索引值�����。
[html] view plain copy
print?
lang.index("p")
4���、內(nèi)存編號(hào) =R= 無
這個(gè)與R中不一樣,當(dāng)數(shù)據(jù)存入python之后�,機(jī)器會(huì)自動(dòng)給存入內(nèi)存的數(shù)據(jù)編號(hào),這個(gè)編號(hào)可以用id來查看�����。
[html] view plain copy
print?
>>> id(c)
3071934536L
>>> id(lang)
3071934536L
5���、ASCII 值(是十進(jìn)制的)
ord("a") 代表輸入字符返回ASCII值
cha(97) 代表輸入ASCII值返回字符
[html] view plain copy
print?
>>> cmp("a","b") #a-->97, b-->98, 97 小于 98�,所以 a 小于 b
-1
其中cmp()代表比較 a b 兩個(gè)字符的ASCII值的大小��,返回值為1,0��,-1
[html] view plain copy
print?
>>> max(str1)
'd'
>>> max(str2)
'e'
>>> min(str1)
'a'
返回字符的ASCII值的最大值���。
————————————————————————————————————————————
二����、字符串基本操作
1����、字符串重復(fù) =R=rep
[html] view plain copy
print?
>>> str1*3
'abcdabcdabcd'
其中變成字符串有兩種方式:一種是str()或者是用單引號(hào)來表示。
2��、字符串拼接
(1)+ 號(hào) =R= paste
[html] view plain copy
print?
>>> "Py" + "thon"
'Python'
>>> a = 1989
>>> b = "free"
>>> print b+“a”
>>> print b+str(a)
其中變成字符串有兩種方式:一種是str()或者是用單引號(hào)來表示�。
乘法,就是重復(fù)那個(gè)字符串的含義�。
(2)join =R= paste
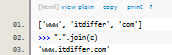
用 . 來填補(bǔ)間隔中的內(nèi)容���。
3�����、語句分割split =R= split
這個(gè)函數(shù)的作用是將字符串根據(jù)某個(gè)分割符進(jìn)行分割����。
[html] view plain copy
print?
>>> a = "I LOVE PYTHON"
>>> a.split(" ")
['I', 'LOVE', 'PYTHON']
其中split(“ ”)括號(hào)中,代表著依據(jù)什么樣式來進(jìn)行分割���。
4��、字符串去掉空格 = R=grep
方法是:
S.strip() 去掉字符串的左右空格
S.lstrip() 去掉字符串的左邊空格
S.rstrip() 去掉字符串的右邊空格
[html] view plain copy
print?
>>> b=" hello " # 兩邊有空格
>>> b.strip()
'hello'
5����、字符串大小寫
在 Python 中有下面一堆內(nèi)建函數(shù)�,用來實(shí)現(xiàn)各種類型的大小寫轉(zhuǎn)化
S.upper() #S 中的字母大寫
S.lower() #S 中的字母小寫
S.capitalize() # 首字母大寫
S.isupper() #S 中的字母是否全是大寫
S.islower() #S 中的字母是否全是小寫
S.istitle()
S.title() #把所有的單詞的第一個(gè)字母轉(zhuǎn)化為大寫
S.istitle() #判斷每個(gè)單詞的第一個(gè)字母是否為大寫
6、in 包含關(guān)系 =R=%in%
類似集合計(jì)算���,a in b代表a是否包含在b中���,返回的是布爾值。
[html] view plain copy
print?
>>> "a" in str1
True
>>> "de" in str1
False
>>> "de" in str2
True
7��、字符長度len =R= length
[html] view plain copy
print?
>>> a="hello"
>>> len(a)
5
————————————————————————————————————————————
三�����、轉(zhuǎn)義符��、占用符列表
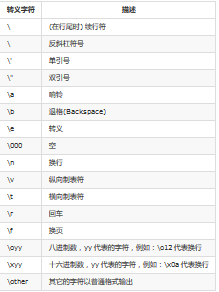
1、轉(zhuǎn)義符列表
在字符串中����,有時(shí)需要輸入一些特殊的符號(hào),但是�,某些符號(hào)不能直接輸出,就需要用轉(zhuǎn)義符���。所謂轉(zhuǎn)義���,就是不采用符號(hào)本來的含義,而采用另外一含義了��。下面表格中列出常用的轉(zhuǎn)義符:
轉(zhuǎn)義字符 描述
\ (在行尾時(shí)) 續(xù)行符
\ 反斜杠符號(hào)
\' 單引號(hào)
\" 雙引號(hào)
\a 響鈴
\b 退格(Backspace)
\e 轉(zhuǎn)義
\000 空
\n 換行
\v 縱向制表符
\t 橫向制表符
\r 回車
\f 換頁
\oyy 八進(jìn)制數(shù)�����,yy 代表的字符���,例如:\o12 代表換行
\xyy 十六進(jìn)制數(shù),yy 代表的字符��,例如:\x0a 代表換行
\other 其它的字符以普通格式輸出
以上所有轉(zhuǎn)義符�����,都可以通過交互模式下 print 來測(cè)試一下,感受實(shí)際上是什么樣子的�。
2、占位符
占位符在自動(dòng)生成字符內(nèi)容方面有很好的應(yīng)用:
[html] view plain copy
print?
>>> print "我%s喜歡NLP" % "非常"
我非常喜歡NLP
(1)老式占位符%s
另外�����,不同的占位符�,會(huì)表示那個(gè)位置應(yīng)該被不同類型的對(duì)象填充。下面列出許多���,供參考�。不過��,不用記憶����,常用的只有 %s 和 %d,或者再加上 %f�,其它的如果需要了,到這里來查即可�����。
(2)新式{}
[html] view plain copy
print?
>>> print "我{}喜歡NLP" .format("非常")
我非常喜歡NLP
Python 非常提倡的 string.format()的格式化方法,其中 {} 作為占位符�。
這種方法真的是非常好,而且非常簡單�,只需要將對(duì)應(yīng)的東西,按照順序在 format 后面的括號(hào)中排列好���,分別對(duì)應(yīng)占位符 {} 即可��。我喜歡的方法�。
四�����、Python 中如何避免中文是亂碼
這個(gè)問題是一個(gè)具有很強(qiáng)操作性的問題��。我這里有一個(gè)經(jīng)驗(yàn)總結(jié)��,分享一下�,供參考:
首先,提倡使用 utf-8 編碼方案�����,因?yàn)樗缙脚_(tái)不錯(cuò)。
經(jīng)驗(yàn)一:在開頭聲明:
# -*- coding: utf-8 -*-
有朋友問我-*-有什么作用�����,那個(gè)就是為了好看���,愛美之心人皆有,更何況程序員����?當(dāng)然,也可以寫成:
# coding:utf-8
經(jīng)驗(yàn)二:遇到字符(節(jié))串����,立刻轉(zhuǎn)化為 unicode,不要用 str()�����,直接使用 unicode()
unicode_str = unicode('中文', encoding='utf-8')
print unicode_str.encode('utf-8')
經(jīng)驗(yàn)三:如果對(duì)文件操作��,打開文件的時(shí)候��,最好用 codecs.open�,替代 open(這個(gè)后面會(huì)講到,先放在這里)
import codecs
codecs.open('filename', encoding='utf8')
五、Python正則表達(dá)式:re的match方法(來源公眾號(hào)人人可以學(xué)python)
Python 從1.5版本起添加了模塊re ���,提供 Perl 風(fēng)格的正則表達(dá)式模式
我們經(jīng)常用的有re.match( ), re.search( )���,re.sub( ), 下面我們一個(gè)一個(gè)來講一下��。
其中注意它們各自的區(qū)別
re.match( )
match( )從要匹配的字符串的起始位置開始匹配一個(gè)正則表達(dá)式�����。如果起始位置匹配失敗�,則返回None
re.match(pattern, string, flags=0)
參數(shù):
pattern: 正則表達(dá)式
string:要匹配的字符串
flags:標(biāo)志位,用來控制匹配模式
[html] view plain copy
print?
舉例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
str1 = "Allen is renren python"
print re.match('Bllen', str1)
print re.match('Allen', str1)
print re.match('.*renren.*', str1)
allenwoo@~/renren$ python test.py
第一個(gè)由于一開始匹配不成功����,所以結(jié)果是None
第二個(gè)在字符串開始就找到了“Allen”所以匹配成功,返回結(jié)果
第三個(gè)�����," . "表示任何字符���,“ * ”表示前面一個(gè)修飾符有任何個(gè)(包括0個(gè))
所以" .* "就是匹配任何個(gè)數(shù)的任何字符的意思�����。
[html] view plain copy
print?
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
str1 = "Allen is renren python"
r = re.match('Allen', str1)
# span是返回我們匹配到的字符串的開始和結(jié)束的下標(biāo)
print r.span()
# group返回我們匹配到的字符串
print r.group()
print "\n"
r = re.match('.*renren.*', str1)
print r.span()
print r.group()
數(shù)字匹配可以使用\w或者[0-9]
比如要匹配字符串"Jack age:18��,sex:m"中的數(shù)字
[html] view plain copy
print?
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
str1 = "Jack age:18����,sex:m"
r = re.match('.*\w+.*', str1)
if r:
print r.group()
print "\n"
r = re.match('.*[0-9]+.*', str1)
if r:
print r.group()
print("分組匹配輸出")
r = re.match(r'(.*):([0-9]+).*', str1)
if r:
print r.group()
print r.group(1)
print r.group(2)
你會(huì)發(fā)現(xiàn)我們?cè)?a href='/map/zhengzebiaodashi/' style='color:#000;font-size:inherit;'>正則表達(dá)式中使用()就能分組匹配��,然后可以使用group返回每個(gè)括號(hào)中匹配的字符串���。
注意: 在re.match(r'(.*):([0-9]+).*', str1)的表達(dá)式前面我們使用了一個(gè) r����, r是防止字符串轉(zhuǎn)意����,因?yàn)槲覀兪褂昧耍ǎ?我們不希望它被當(dāng)作要匹配的字符。
附:那這就先講一下轉(zhuǎn)意:
[html] view plain copy
print?
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 大家都知道\n是換行符�,
# 而\t 是tab空格,相當(dāng)于我們鍵盤的tab鍵
print("We\tare\trenrenpython")
# 加上r防止轉(zhuǎn)意后
print(r"We\tare\trenrenpython")
\是一個(gè)特殊符符號(hào)�,用來轉(zhuǎn)意一些字符,如\n換行符
使用了 r 后"\t"就是字符串"\t", 而不是tab
然后又有新的問題來了����,想"\w"," . ", " * "都被用作了正則表達(dá)式的修飾符�����,如果我們需要把它們當(dāng)原本的字符匹配怎么辦呢�����?使用" \"
[html] view plain copy
print?
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
str1 = "python . renren"
str2 = "python : renren"
# 由于"." 是代表任何字符��,所以下面表達(dá)式str1,str2都能匹配到
r = re.match('.* . .*', str1)
if r:
print r.group()
else:
print "未匹配"
r = re.match('.* . .*', str2)
if r:
print r.group()
else:
print "未匹配"
print "\n"
# 如果我們要匹配的是"."這個(gè)字符呢?
r = re.match('.* \. .*', str1)
if r:
print r.group()
else:
print "未匹配"
r = re.match('.* \. .*', str2)
if r:
print r.group()
else:
print "未匹配"
延伸一:Nan
[python] view plain copy
print?
def isnotNaN(num):
return num == num
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330