一句python�,一句R︱列表、元組���、字典�、數(shù)據(jù)類型����、自定義模塊導(dǎo)入(格式、去重)
先學(xué)了R語言�,最近剛剛上手Python,所以想著將python和R結(jié)合起來互相對(duì)比來更好理解python。最好就是一句python�����,對(duì)應(yīng)寫一句R�。
pandas中有類似R中的read.table的功能,而且很像��。
————————————————————————————————————————————————————
一、數(shù)據(jù)類型
Python有五個(gè)標(biāo)準(zhǔn)的數(shù)據(jù)類型:
Numbers(數(shù)字)
String(字符串)
List(列表) 使用:[] list()
Tuple(元組) 使用:() tuple()
Dictionary(字典) 使用:{ } dict()
其中pandas和numpy中的數(shù)組格式 以及Series DataFrame都是基于此之上而得到的�����。其中比R要多:Tuple�����、Dictionary兩種類型�����。
1�����、數(shù)字格式 int() float() long() complex()
Python支持四種不同的數(shù)字類型:
int(有符號(hào)整型)
long(長(zhǎng)整型[也可以代表八進(jìn)制和十六進(jìn)制])
float(浮點(diǎn)型)
complex(復(fù)數(shù))
一些數(shù)值類型的實(shí)例:
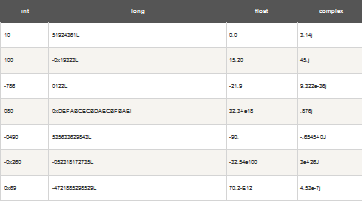
長(zhǎng)整型也可以使用小寫"L"����,但是還是建議您使用大寫"L"�����,避免與數(shù)字"1"混淆��。Python使用"L"來顯示長(zhǎng)整型。
Python還支持復(fù)數(shù)�����,復(fù)數(shù)由實(shí)數(shù)部分和虛數(shù)部分構(gòu)成�,可以用a + bj,或者complex(a,b)表示, 復(fù)數(shù)的實(shí)部a和虛部b都是浮點(diǎn)型
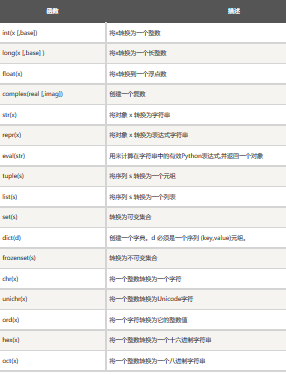
格式轉(zhuǎn)換
以下幾個(gè)內(nèi)置的函數(shù)可以執(zhí)行數(shù)據(jù)類型之間的轉(zhuǎn)換����。這些函數(shù)返回一個(gè)新的對(duì)象,表示轉(zhuǎn)換的值����。
2、字符串 str()
字符串或串(String)是由數(shù)字�����、字母�、下劃線組成的一串字符。
可參考:
一句python���,一句R︱python中的字符串操作���、中文亂碼
————————————————————————————————————————————————————
二����、列表型/list/ [] =R=c()向量
速查手冊(cè):
[html] view plain copy
print?
L.append(var) #追加元素
L.insert(index,var)
L.pop(var) #返回最后一個(gè)元素�,并從list中刪除之
L.remove(var) #刪除第一次出現(xiàn)的該元素
L.count(var) #該元素在列表中出現(xiàn)的個(gè)數(shù)
L.index(var) #該元素的位置,無則拋異常
L.extend(list) #追加list,即合并list到L上
L.sort() #排序
L.reverse() #倒序
list 操作符:,+,*����,關(guān)鍵字del
a[1:] #片段操作符,用于子list的提取
[1,2]+[3,4] #為[1,2,3,4]���。同extend()
[2]*4 #為[2,2,2,2]
del L[1] #刪除指定下標(biāo)的元素
del L[1:3] #刪除指定下標(biāo)范圍的元素
list的復(fù)制
L1 = L #L1為L(zhǎng)的別名����,用C來說就是指針地址相同�����,對(duì)L1操作即對(duì)L操作����。函數(shù)參數(shù)就是這樣傳遞的
L1 = L[:] #L1為L(zhǎng)的克隆����,即另一個(gè)拷貝�。
List(列表) 是 Python 中使用最頻繁的數(shù)據(jù)類型���。
列表可以完成大多數(shù)集合類的數(shù)據(jù)結(jié)構(gòu)實(shí)現(xiàn)���。它支持字符,數(shù)字�����,字符串甚至可以包含列表(所謂嵌套)�。
[html] view plain copy
print?
list = [ 'abcd', 786 , 2.23, 'john', 70.2 ]
tinylist = [123, 'john']
list中的元素追加,那可以直接:
list = []
list = list + list
或者list.append
append是添加單個(gè)元素�����,如果要追加同樣元組���,可以用list.extend
[]或者() 追加用 加號(hào) + 或者 list.append
兩個(gè)列表同時(shí)迭代:
[html] view plain copy
print?
nfc = ["Packers", "49ers"]
afc = ["Ravens", "Patriots"]
for teama, teamb in zip(nfc, afc):
print teama + " vs. " + teamb
>>> Packers vs. Ravens
>>> 49ers vs. Patriots
格式轉(zhuǎn)化:
(1)列表轉(zhuǎn)為字符串
''.join(a)
(2)列表轉(zhuǎn)換為元組
l = ['a','b','c']
tuple(l)
(3)列表轉(zhuǎn)換為字典
list1 = dic.items()
dict(list1)
———————————————————————————————————————————————————
三���、元組——()/ tuple() =R= 固定的c()
元組是另一個(gè)數(shù)據(jù)類型,類似于List(列表)����。
元組用"()"標(biāo)識(shí)�。內(nèi)部元素用逗號(hào)隔開��。但是元組不能二次賦值��,相當(dāng)于只讀列表����。不能用append來新賦值
[html] view plain copy
print?
以下是元組無效的,因?yàn)樵M是不允許更新的����。而列表是允許更新的:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
tuple = ( 'abcd', 786 , 2.23, 'john', 70.2 )
list = [ 'abcd', 786 , 2.23, 'john', 70.2 ]
tuple[2] = 1000 # 元組中是非法應(yīng)用
list[2] = 1000 # 列表中是合法應(yīng)用
相當(dāng)于固定的c()
元組中元素的追加,就可以直接用:
用 '+' 號(hào)
a+a
元組不可以用append添加元素
格式轉(zhuǎn)化:
元組轉(zhuǎn)換為字符串
''.join(t)
元組轉(zhuǎn)換為列表
t = ('a','b','c')
list(t)
['a','b','c']
————————————————————————————————————————————————————
四�����、Python元字典 { } =R= list()
字典(dictionary)是除列表以外python之中最靈活的內(nèi)置數(shù)據(jù)結(jié)構(gòu)類型�。列表是有序的對(duì)象結(jié)合,字典是無序的對(duì)象集合��。
兩者之間的區(qū)別在于:字典當(dāng)中的元素是通過鍵來存取的���,而不是通過偏移存取。
字典用"{ }"標(biāo)識(shí)。字典由索引(key)和它對(duì)應(yīng)的值value組成�。
速查手冊(cè):
[html] view plain copy
print?
dictionary的方法
D.get(key, 0) #同dict[key],多了個(gè)沒有則返回缺省值�,0。[]沒有則拋異常
D.has_key(key) #有該鍵返回TRUE����,否則FALSE
D.keys() #返回字典鍵的列表
D.values() #以列表的形式返回字典中的值,返回值的列表中可包含重復(fù)元素
D.items() #將所有的字典項(xiàng)以列表方式返回��,這些列表中的每一項(xiàng)都來自于(鍵,值),但是項(xiàng)在返回時(shí)并沒有特殊的順序
D.update(dict2) #增加合并字典
D.popitem() #得到一個(gè)pair����,并從字典中刪除它。已空則拋異常
D.clear() #清空字典����,同del dict
D.copy() #拷貝字典
D.cmp(dict1,dict2) #比較字典,(優(yōu)先級(jí)為元素個(gè)數(shù)����、鍵大小、鍵值大小)
#第一個(gè)大返回1��,小返回-1����,一樣返回0
dictionary的復(fù)制
dict1 = dict #別名
dict2=dict.copy() #克隆�,即另一個(gè)拷貝�。
生成方式一:用在函數(shù)、for循環(huán)中
dict = {}
dict['one'] = "This is one"
dict[2] = "This is two"
但是dict有一個(gè)好處����,就是不僅可以list[1] 還可以list[strings],其中可以裝下字符�。
生成方式二:{}
tinydict = {'name': 'john','code':6734, 'dept': 'sales'}
輸出方式:
print dict[2] # 輸出鍵為 2 的值
print tinydict # 輸出完整的字典
print tinydict.keys() # 輸出所有鍵
print tinydict.values() # 輸出所有值
延伸
一種特殊的,字典的生成方式:
[html] view plain copy
print?
dict(dim=[1, 3, 227, 227])
格式轉(zhuǎn)化�����,由list->數(shù)組:
[html] view plain copy
print?
np.array('d',[1,2,3])
轉(zhuǎn)回來的話調(diào)用tolist函數(shù)
_.tolist()
還有一種方式是:.toarray()變?yōu)閍rray
延伸二:dict格式轉(zhuǎn)化
[html] view plain copy
print?
字典轉(zhuǎn)換為列表
dic={'a':1,'b':2}
dic.items()
[('a',1),('b',2)]
或者:
[html] view plain copy
print?
D.get(key, 0) #同dict[key]�����,多了個(gè)沒有則返回缺省值��,0����。[]沒有則拋異常
D.has_key(key) #有該鍵返回TRUE,否則FALSE
D.keys() #返回字典鍵的列表
D.values() #以列表的形式返回字典中的值�,返回值的列表中可包含重復(fù)元素
D.items() #將所有的字典項(xiàng)以列表方式返回,這些列表中的每一項(xiàng)都來自于(鍵,值),但是項(xiàng)在返回時(shí)并沒有特殊的順序
其中的.values()就可以實(shí)現(xiàn)dict轉(zhuǎn)化為list
延伸三:去掉List中的空格
[python] view plain copy
print?
filter(None,[None,1,2,3,None])
即可
————————————————————————————————————————————————————
五���、模組���、模塊導(dǎo)入與復(fù)查、自定義模塊
1����、一般傳統(tǒng)模塊
下載模塊是一個(gè)麻煩的事情,一般用pip來執(zhí)行�����,但是貌似每次下載都是一堆麻煩提示�����,于是轉(zhuǎn)而用pycharm�,很方面,傻瓜版.
一般模塊就像R中的函數(shù)包�����,需要先調(diào)用
[html] view plain copy
print?
library(packages)=import pandas as pd
查看模塊是否載入����,一般import pandas����,如果該包下載就不會(huì)用任何提示�,如果沒有加載成功,就會(huì)報(bào)錯(cuò):
[html] view plain copy
print?
ImportError: No module named da
查看已有的加載包
[html] view plain copy
print?
help("modules") #查看安裝包
按照R語言中曾經(jīng)存在的問題:
1���、如何取消模塊的加載?
2���、模塊的位置是在哪?
3、模塊的信息如何調(diào)用出來��?就像R中的介紹一樣����,有沒有比較詳細(xì)的說明?
2��、自定義模塊導(dǎo)入
上網(wǎng)查了下資料和自己實(shí)驗(yàn)了下����,有幾個(gè)方法:
1.如果導(dǎo)入的模塊和主程序在同個(gè)目錄下,直接import就行了
2.如果導(dǎo)入的模塊是在主程序所在目錄的子目錄下�,可以在子目錄中增加一個(gè)空白的__init__.py文件�����,該文件使得python解釋器將子目錄整個(gè)也當(dāng)成一個(gè)模塊,然后直接通過“import 子目錄.模塊”導(dǎo)入即可�。
3.如果導(dǎo)入的模塊是在主程序所在目錄的父目錄下,則要通過修改path來解決����,有兩種方法:
(1)通過”import sys,sys.path.append('父目錄的路徑')“來改變���,這種方法屬于一次性的���,只對(duì)當(dāng)前的python解釋器進(jìn)程有效,關(guān)掉python重啟后就失效了����。
(2)直接修改環(huán)境變量:在windows中是 “ set 變量=‘路徑’ ” 例如:set PYTHONPATH=‘C:\test\...’ 查看是否設(shè)置成功用echo %PYTHONPATH%,而且進(jìn)到python解釋器中查看sys.path,會(huì)發(fā)現(xiàn)已經(jīng)有了新增加的路徑了。這 種方式是永久的���,一次設(shè)置以后一直都有效���。在Linux中是 "export 變量=‘路徑’ “�����,查看是" echo $變量 "
通過修改path是通用的方法����,因?yàn)?a href='/map/python/' style='color:#000;font-size:inherit;'>python解釋器就是通過sys.path去一個(gè)地方一個(gè)地方的尋找模塊的��。
筆者實(shí)踐一般用第二種辦法�,__init__.py文件,同時(shí)譬如現(xiàn)在有這樣的目錄結(jié)構(gòu):
C:\\Users\\filename\\function_file\\file.function.py
file.function.py里面裝著function1函數(shù)����。
[python] view plain copy
print?
import sys
ImportPath = 'C:\\Users\\filename'
sys.path.append(ImportPath)
from function_file.function import function1
如果報(bào)錯(cuò):
[python] view plain copy
print?
python ImportError: cannot import name
一般是.pyc文件的問題,找到對(duì)應(yīng)的pyc刪除掉
參考博客:原來可以 RUN 的 突然出現(xiàn)此提示 ImportError: cannot import name webdriver
解決ImportError: cannot import name webdriver
————————————————————————————————————————
六�、數(shù)據(jù)讀入、寫出
1�、python的read_csv
[html] view plain copy
print?
#數(shù)據(jù)導(dǎo)入
df = pd.read_csv('./cpu.csv',header=0)
#中文encoding = 'gbk'
約等于R中的read.csv('./cpu.csv',header=T,encoding= UTF-8)
[html] view plain copy
print?
pd.read_csv("C:\\Users\\long\\Desktop\\ex2.csv",header=None,names=["a","b","c","e","message"],index_col=["message","a"])
其中:header=None,就代表沒有行名稱�����,names代表另外命名行名稱����,index_col代表列�。
其中讀入數(shù)據(jù)的時(shí)候��,不要出現(xiàn)中文�,不然讀不進(jìn)去。
會(huì)出現(xiàn)以下的錯(cuò)誤:
[html] view plain copy
print?
IOError: File C:\Users\long\Desktop\ch06\ex2.csv does not exist
如果出現(xiàn)中文��,中文導(dǎo)入����、導(dǎo)出都需要加上:
[html] view plain copy
print?
df = pd.read_csv("001.csv",encoding="gbk")
dataname.to_csv("001.csv",encoding="gbk")
2��、python的to_csv
to_csv=write.csv
[html] view plain copy
print?
#數(shù)據(jù)導(dǎo)出
df.to_csv('uk_rain.csv') #write.csv(df,"uk_rain.csv")
約等于R中的write.csv(df,"uk_rain.csv"),其中df是數(shù)據(jù)集的名稱��,跟前面的read_csv不太一樣����。
更一般的表現(xiàn)形式:
pd.read_table("./marks.csv", sep=",")
3、txt文件導(dǎo)入——np.loadtxt
用numpy中的一個(gè)函數(shù)可以實(shí)現(xiàn)txt文件的導(dǎo)入��。
[html] view plain copy
print?
np.loadtxt("/caffe/examples/lmdb_test/train/synset.txt", str, delimiter='\t')
————————————————————————————————————————————————————
七�����、數(shù)據(jù)查看——行列名��、查看
R中常有的兩種方式——$ []:
data$colnames
data["colnames",]
函數(shù)使用辦法都是:sum(data)
python中通過 . 傳導(dǎo)式的:
data.sum
1、數(shù)據(jù)查看
查看數(shù)據(jù)的前5個(gè)��,后5個(gè)����。
data.head(5)
data.tail(5)
在R中為head(data)/tail(data)
2、數(shù)據(jù)類型
type(data)
3���、列數(shù)量����、行數(shù)量 len(R中的length)
len(data) #行數(shù)
len(data.T) #列數(shù)
其中data.T是數(shù)據(jù)轉(zhuǎn)置�,就可以知道數(shù)據(jù)的行數(shù)、列數(shù)�����。
————————————————————————————————————————
延伸一:遍歷文件方法
筆者作為小白在遍歷文件的時(shí)候����,看到幾種辦法挺好的:os.listdir 和 os.walk
[html] view plain copy
print?
os.listdir返回的是該文件夾下的所有文件名稱;
os.walk可以返回父文件夾路徑+文件夾下路徑��,貌似比較給力。
網(wǎng)上有幫他們打包成函數(shù)的博客:Python遍歷目錄的4種方法實(shí)例介紹
[html] view plain copy
print?
#!/usr/bin/python
import os
from glob import glob
def printSeparator(func):
def deco(path):
print("call method %s, result is:" % func.__name__)
print("-" * 40)
func(path)
print("=" * 40)
return deco
@printSeparator
def traverseDirByShell(path):
for f in os.popen('ls ' + path):
print f.strip()
@printSeparator
def traverseDirByGlob(path):
path = os.path.expanduser(path)
for f in glob(path + '/*'):
print f.strip()
@printSeparator
def traverseDirByListdir(path):
path = os.path.expanduser(path)
for f in os.listdir(path):
print f.strip()
@printSeparator
def traverseDirByOSWalk(path):
path = os.path.expanduser(path)
for (dirname, subdir, subfile) in os.walk(path):
#print('dirname is %s, subdir is %s, subfile is %s' % (dirname, subdir, subfile))
print('[' + dirname + ']')
for f in subfile:
print(os.path.join(dirname, f))
if __name__ == '__main__':
path = r'~/src/py'
traverseDirByGlob(path)
traverseDirByGlob(path)
traverseDirByListdir(path)
traverseDirByOSWalk(path)
1��、traverseDirByGlob�、traverseDirByOSWalk兩種函數(shù)可以拿到帶全部路徑的文件,類似:
[html] view plain copy
print?
/data/trainlmdb/val/test_female/image_00009.jpg
2���、traverseDirByListdir(path)可以拿到里面的文件名:
[html] view plain copy
print?
image_00009.jpg
當(dāng)然這個(gè)函數(shù)里面是print出來的��?���;诠P者的小白級(jí)寫函數(shù)方法��,筆者改進(jìn):
[html] view plain copy
print?
def traverseDirByGlob(path):
path = os.path.expanduser(path)
list={}
i=0
for f in glob(path + '/*'):
list[i]=f.strip()
i=i+1
return list
就可以跟其他的def函數(shù)一樣return出來���。
————————————————————————————————————————
延伸二:pickle模塊的基本使用:pkl文件
python的pickle模塊實(shí)現(xiàn)了基本的數(shù)據(jù)序列和反序列化。通過pickle模塊的序列化操作我們能夠?qū)⒊绦蛑羞\(yùn)行的對(duì)象信息保存到文件中去���,永久存儲(chǔ)�����;通過pickle模塊的反序列化操作��,我們能夠從文件中創(chuàng)建上一次程序保存的對(duì)象
保存:
[html] view plain copy
print?
#使用pickle模塊將數(shù)據(jù)對(duì)象保存到文件
import pickle
data1 = {'a': [1, 2.0, 3, 4+6j],
'b': ('string', u'Unicode string'),
'c': None}
selfref_list = [1, 2, 3]
selfref_list.append(selfref_list)
output = open('data.pkl', 'wb')
# Pickle dictionary using protocol 0.
pickle.dump(data1, output)
# Pickle the list using the highest protocol available.
pickle.dump(selfref_list, output, -1)
output.close()
讀?。?br />
[html] view plain copy
print?
with open(path, 'rb') as f:
labels = pickle.load(f)
path是pkl的路徑名
————————————————————————————————————————
延伸三:報(bào)錯(cuò)TypeError: 'str' object is not callable
因?yàn)橐恍┖瘮?shù)名字,被用來命名臨時(shí)變量了����。比如:
[html] view plain copy
print?
len=1
len(data)
TypeError: 'str' object is not callable
len這個(gè)函數(shù)被之前命名了。
————————————————————————————————————————
延伸四:在元組和list中添加元素
一般添加元素的辦法有用:
用加號(hào) 或者 append
兩者的使用效果不同����。
append是:list+list = 兩個(gè)list,list + 元素 = 一個(gè)list
+號(hào)是: 元組 + 元組 = 一個(gè)元組
list可以使用append�����,而元組不可以用append添加元素
————————————————————————————————————————
延伸五:去重
1��、for循環(huán)�,同時(shí)保持原來的位置
[html] view plain copy
print?
ids = [1,2,3,3,4,2,3,4,5,6,1]
news_ids = []
for id in ids:
if id not in news_ids:
news_ids.append(id)
print news_ids
保持之前的排列順序。
2����、set 可以去重+排序
[html] view plain copy
print?
ids = [1,4,3,3,4,2,3,4,5,6,1]
ids = set(ids)
3、count函數(shù)迭代去重
[python] view plain copy
print?
from collections import Counter\
ImagePath = traverseDirByGlob(root_dir)
Path = []
[Path.append(v) for _,v in ImagePath.items()]
Duplicate = [ (str(k),str(v)) for k,v in dict(Counter(tuple(Path))).items() if v>1]
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330