R之回歸分析廣義線性模型(Generalized Linear Model)glm
1. 介紹
廣義線性模型(Generalized Linear
Model)是一般線性模型的推廣,它使因變量的總體均值通過一個非線性連接函數(shù)而依賴于線性預測值�����,允許響應概率分布為指數(shù)分布族中的任何一員。許多廣泛應用的統(tǒng)計模型都屬于廣義線性模型��,如常用于研究二元分類響應變量的Logistic回歸��、Poisson回歸和負二項回歸模型等�����。一個廣義線性模型包含以下三個部分:
①隨機成分����。
②線性成分。
③連接函數(shù)g����。
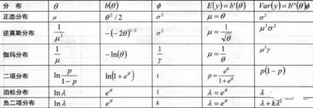
各種常見的指數(shù)型分布及其主要參數(shù)
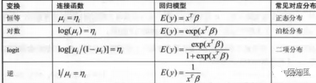
典型的連接函數(shù)及對應分布
廣義線性模型的參數(shù)估計一般不能用最小二乘估計,常用加權最小二乘法或最大似然法估計���,各回歸系數(shù)β需用迭代方法求解���。
2. 實現(xiàn)
R提供了擬合廣義線性模型的函數(shù)glm(),其調用格式為
glm(formula, family = gaussian, data, weights, subset,
na.action, start = NULL, etastart, mustart, offset,
control = list(...), model = TRUE, method = "glm.fit",
x = FALSE, y = TRUE, contrasts = NULL, ...)
其中,
formula為擬合公式��,與函數(shù)lm()中的參數(shù)formula用法相同;
family用于指定分布族,包括正態(tài)分布(gaussian)��、二項分布(binomial)�、泊松分布(poisson)和偽伽馬分布(Gamma);
分布族還可以通過選項link來指定連接函數(shù)����,默認值為family=gaussian (link=identity),二項分布默認值為family=binomial(link=logit);
data指定數(shù)據(jù)集;
offset指定線性函數(shù)的常數(shù)部分,通常反映已知信息;
control用于對待估參數(shù)的范圍進行設置�����。
例:
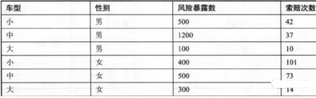
車險保單索賠次數(shù)分組數(shù)據(jù)
已知索賠次數(shù)服從泊松分布����,相應的連接函數(shù)常用對數(shù)連接函數(shù),模型可以寫為
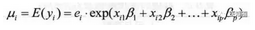
下面用R實現(xiàn)��,首先建立數(shù)據(jù)集����,分類變量直接輸入定性的取值即可,glm()分析時會自動轉換成矩陣X,注意參數(shù)family的寫法���。
> dat=data.frame(
y=c(42, 37, 10, 101, 73, 14),
n=c(500, 1200, 100, 400, 500, 300),
type=rep(c('小','中','大'),2),
gender=rep(c('男','女'),each=3)
)
> dat$logn=log(dat$n) #風險暴露數(shù)取對數(shù)
#offset風險單位數(shù)事先已知
> dat.glm=glm(y~type+gender,offset=logn,data=dat,family=poisson(link=log))
> summary(dat.glm) #glm的輸出結果
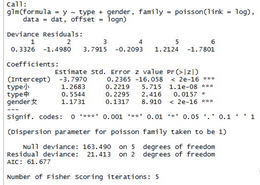
估計的回歸系數(shù)都是非常顯著的;Null deviance可以認為是模型的殘差��,它的值越小說明模型擬合效果越好;模型的AIC統(tǒng)計量為61.68�,它和deviance一起可以用來作為判斷標準����,選取合適的分布族和鏈接函數(shù)。
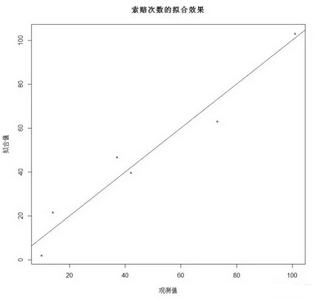
下面通過作圖來觀察模型擬合的效果���,首先提取模型的預測值�,注意函數(shù)predict()提取的是線性部分的擬合值����,在對數(shù)連接函數(shù)下,要得到Y的擬合值��,應當再做一次指數(shù)變換���。以實際觀測值為橫坐標�����,模型擬合值為縱坐標作圖��,散點越接近直線y=x��,說明模型的擬合效果越好���。
> dat.pre=predict(dat.glm)
> layout(1) #取消繪圖區(qū)域分割
> plot(y,exp(dat.pre),xlab='觀測值',ylab='擬合值',main="索賠次數(shù)的擬合效果",pch="*")
> abline(0,1) #添加直線y=x��,截距為0����,斜率為1
若假設上例中的索賠次數(shù)服從負二項分布���,在R中應輸入指令:
> library(MASS)
> attach(dat)
> dat.glmnb=glm.nb(y~type+gender+offset(logn)) #負二項回歸
> summary(dat.glmnb) #輸出結果
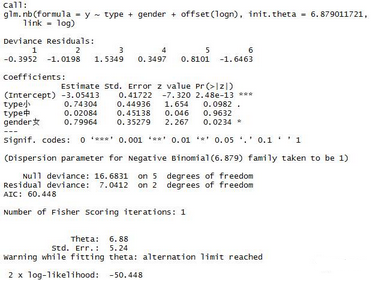
負二項回歸擬合的模型AIC為60.45���,殘差Null deviance為16.6831,小于泊松回歸擬合的殘差值�����,說明負二項分布的廣義線性模型更加穩(wěn)定���,但從回歸系數(shù)的顯著性上看�,泊松回歸擬合的變量系數(shù)更加顯著����。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330