R語言從SNPedia批量提取搜索數(shù)據(jù)
SNP是單核苷酸多態(tài)性,人的基因是相似的���,有些位點(diǎn)上存在差異����,這種某個(gè)位點(diǎn)的核苷酸差異就做單核苷酸多態(tài)性�����,它影響著生物的性狀����,影響著對(duì)某些疾病的易感性。SNPedia是一個(gè)SNP調(diào)査百科���,它引用各種已經(jīng)發(fā)布的文章����,或者數(shù)據(jù)庫信息對(duì)SNP位點(diǎn)進(jìn)行描述,共享著人類基因組變異的信息�����。我們可以搜索某個(gè)SNP位點(diǎn)來尋找與之相關(guān)的信息�,也可以根據(jù)相關(guān)疾病,癥狀來尋找相關(guān)的SNP��。
初次使用SNPedia
??SNPedia主頁網(wǎng)址為http://snpedia.com/index.php/SNPedia��,比如我想查找與crouzon綜合癥相關(guān)的SNP����,只需要在SNPedia中搜索crouzon syndrome,即會(huì)出現(xiàn)許多相關(guān)的SNP搜索結(jié)果
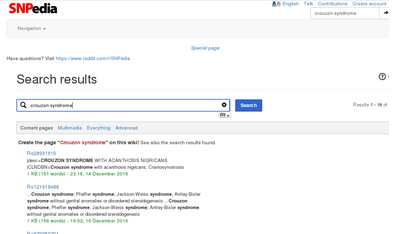
??如果這時(shí)候我想看每個(gè)SNP的相關(guān)信息,我就要每個(gè)鏈接分別點(diǎn)進(jìn)去
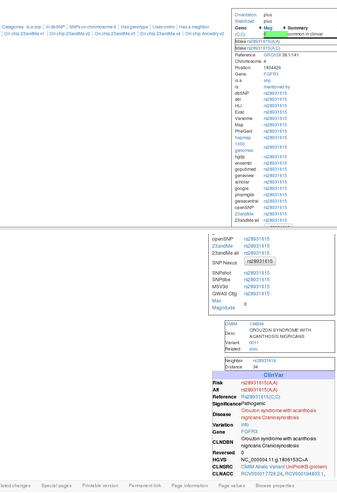
??后來發(fā)現(xiàn)我們只需要提取里面的部分信息��,Orientation����,Stabilized,Reference��,Chromosome��,Position����,Gene����,還有clinvar表格信息���,這時(shí)候我們就可以從網(wǎng)頁中利用RCurl包,XML包�����,正則表達(dá)是把所需要的內(nèi)容提取出來�,有效抓取有用信息。
知識(shí)準(zhǔn)備
RCurl包和XML包
?? readHTMLTable(doc) #doc 是XML或者HTML格式文本���,可以是文件名���,也可以是剛剛parse的html對(duì)象,該函數(shù)返回XML或HTML中的表格
正則表達(dá)式
這里闡述基本的正則表達(dá)式使用
??[ ]中括號(hào)���,匹配中括號(hào)里面的任意字符�����,例如[a]匹配"a"
??[a-z]表示匹配a到z任意字母�,[A-Z]匹配大寫A到Z,[0-9]匹配0-9任意數(shù)字
??[ ]*中括號(hào)加*表示匹配任意次����,[ ]+表示匹配至少一次,例如[a-zA-z,;: ]+表示匹配小寫和大寫字母,;:和空格至少一次
??[ a|b ] 匹配a或者b
??直接輸入字符���,實(shí)現(xiàn)精確定位�。比如"apple[a-zA-z,;: ]+",定位到apple開頭的后面匹配小寫和大寫字母,;:和空格至少一次的內(nèi)容
??[\u4E00-\u9FA5]匹配漢字
R語言gregexpr函數(shù)
??使用方法:gregexpr(pattern,istring���, fixed = FALSE) #pattern就是要匹配正則表達(dá)是����,istring是待匹配的字符串矢量,比如c("abc","cdf")�,fixed, 如果設(shè)置為true,默認(rèn)pattern是真正的字符串,不會(huì)作為其它使用����,相當(dāng)于轉(zhuǎn)義, 函數(shù)返回列表�,包括每個(gè)字符串的匹配長(zhǎng)度和是否匹配)
實(shí)例
?這里直接上代碼,代碼里面有著詳細(xì)解釋�,許多函數(shù)以后可以直接復(fù)制使用�,或者放進(jìn)一個(gè)自己做的R包
#!/usr/bin/env Rscript
download <- function(strURL){
#輸入網(wǎng)址返回html樹格式文件
#strURL:網(wǎng)頁鏈接地址 return: html樹文件
h <- basicTextGatherer()# 查看服務(wù)器返回的頭信息
txt <- getURL(strURL, headerfunction = h$update,.encoding="gbk") ## 字符串形式
htmlParse(txt,asText=T,encoding="gbk") #選擇gbk進(jìn)行網(wǎng)頁的解析
}
getinf <- function(strURL){
#主要提取網(wǎng)頁信息函數(shù)
#strURL:網(wǎng)頁鏈接網(wǎng)址 return:包括所要的所有信息的data.frame
doc<- download(strURL)
#寫如標(biāo)題
info<- data.frame("Title"=strsplit(xmlValue(getNodeSet(doc,'//title')[[1]])," -")[[1]][1]) #"rs... - SNPedia"進(jìn)行split
#寫入"Geno Mag Summary "table
GMS_table <- readHTMLTable(doc)
GMS_index <- 0
for (p in 1:6){
if (length(GMS_table[[p]])==3){
GMS_index <- p
}
}
if (GMS_index!=0){
for (i in 1:length(GMS_table[[GMS_index]])){
tmp <- ""
for (t in 1:nrow(GMS_table[[GMS_index]][i])){
if(tmp==""){tmp <-as.vector(GMS_table[[GMS_index]][i][t,1])}else{
tmp <- paste(tmp,as.vector(GMS_table[[GMS_index]][i][t,1]),sep=";")
}
}
if (i==1){info$Geno <-tmp}
else if (i==2){info$Mag <-tmp}
else if (i==3){info$Summary <- tmp
tmp <- ""
}
}
}else{
info$Geno <-" "
info$Mag <-" "
info$Summary <- " "
}
#寫入剩下table信息
mes <- getNodeSet(doc,'//td')
mes2 <- list()
for (c in mes){
d <- xmlValue(c)
if (mes==""){
mes2=d
}else{
mes2=c(mes2,d)
}
}
tmp <- greg_return_string("Make[-A-Za-z0-9_.%;\\(\\), ]+",mes2)
if (length(tmp)==2){info$"Make"=paste(strsplit(tmp[[1]]," ")[[1]][2],strsplit(tmp[[2]]," ")[[1]][2],sep=";")}else{info$"Make"=" "}
for (i in (1:length(pattlistMainTable))){
tmp <- greg_return_index(pattlistMainTable[[i]],mes2)
if (i==1 && length(tmp)==1){info$"Orientation"=strsplit(mes2[[tmp+1]],"\n")[[1]]}else if (i==1 && length(tmp)!=1){info$"Orientation"=" "}
else if (i==2 && length(tmp)==1){info$"Stabilized"=strsplit(mes2[[tmp+1]],"\n")[[1]]}else if (i==2 && length(tmp)!=1){info$"Stabilized"=" "}
else if (i==3 && length(tmp)==1){info$"Reference"=strsplit(mes2[[tmp+1]],"\n")[[1]]}else if (i==3 && length(tmp)!=1){info$"Reference"=" "}
else if (i==4 && length(tmp)==1){info$"Chromosome"=strsplit(mes2[[tmp+1]],"\n")[[1]]}else if (i==4 && length(tmp)!=1){info$"Chromosome"=" "}
else if (i==5 &&length(tmp)==1){info$"Position"=strsplit(mes2[[tmp+1]],"\n")[[1]]}else if (i==5 && length(tmp)!=1){info$"Position"=" "}
else if (i==6&&length(tmp)==1){info$"Gene"=strsplit(mes2[[tmp+1]],"\n")[[1]]}else if (i==6 && length(tmp)!=1){info$"Gene"=" "}
}
#寫入clivar
mes <- getNodeSet(doc,'//tr')
mes2 <- list()
for (c in mes){
d <- xmlValue(c)
if (mes==""){
mes2=d
}else{
mes2=c(mes2,d)
}
}
for (i in (1:length(pattlistClinvar))){
tmp <- greg_return_string(pattlistClinvar[i],mes2)
if (length(tmp)!=0){tmp <- tmp[[1]]}
if (i==1 && length(tmp)!=0){info$"Risk"=strsplit(tmp,"\n")[[1]][3]}else if (i==1 && length(tmp)==0){info$"Risk"=" "}
else if (i==2 && length(tmp)!=0){info$"Alt"=strsplit(tmp,"\n")[[1]][3]}else if (i==2 && length(tmp)==0){info$"Alt"=" "}
else if (i==3 && length(tmp)!=0){info$"ReferenceBase"=strsplit(tmp,"\n")[[1]][3]}else if (i==3&& length(tmp)==0){info$"ReferenceBase"=" "}
else if (i==4 && length(tmp)!=0){info$"Significance"=strsplit(tmp,"\n")[[1]][2]}else if (i==4 && length(tmp)==0){info$"Significance"=" "}
else if (i==5&& length(tmp)!=0){info$"Disease "=strsplit(tmp,"\n")[[1]][3]}else if (i==5 && length(tmp)==0){info$"Disease "=" "}
else if (i==6 && length(tmp)!=0){info$"CLNDBN"=strsplit(tmp,"\n")[[1]][3]}else if (i==6 && length(tmp)==0){info$"CLNDBN"=" "}
else if (i==7 && length(tmp)!=0){info$"Reversed"=strsplit(tmp,"\n")[[1]][3]}else if (i==7 && length(tmp)==0){info$"Reversed"=" "}
else if (i==8 && length(tmp)!=0){info$"HGVS"=strsplit(tmp,"\n")[[1]][3]}else if (i==8 && length(tmp)==0){info$"HGVS"=" "}
else if (i==9 && length(tmp)!=0){info$"CLNSRC"=strsplit(tmp,"\n")[[1]][3]}else if (i==9 && length(tmp)==0){info$"CLNSRC"=" "}
else if (i==10 && length(tmp)!=0){info$"CLNACC "=strsplit(tmp,"\n")[[1]][3]}else if (i==10 && length(tmp)==0){info$"CLNACC "=" "}
}
info
}
greg_return_string <- function(pattern,stringlist){
#greg_return_stirng 指定匹配全部字符串列表��,返回匹配的字符串
#pattern:匹配模式,比如"abc[a-z]*" stringlist:字符串列表���,list("abc","abcde","cdfe") return : 列表里字符串匹配結(jié)果�����,"abc""abcde"
findlist <- gregexpr(pattern,stringlist)
needlist <- list()
for (i in which(unlist(findlist)>0)){
preadress <- substr(stringlist[i],findlist[[i]],findlist[[i]]+attr(findlist[[i]],'match.length')-1)
needlist<- c(needlist,list(preadress))
}
return(needlist)
}
greg_return_index <- function(pattern,stringlist){
#greg_return_stirng 指定匹配全部字符串列表,返回存在匹配的字符串列表index
#pattern:匹配模式 stringlst:待匹配字符串列表 return:存在返回匹配的字符串在列表中的index
findlist <- gregexpr(pattern,stringlist)
needlist <- list()
which(unlist(findlist)>0)
}
extradress <- function(strURL){
#將strURL網(wǎng)頁里面我們所需要鏈接提取出來并加工
#strURL:網(wǎng)頁鏈接網(wǎng)址 return:網(wǎng)址列表����,包括所有提取加工后的網(wǎng)址鏈接
pattern <- "/index.php/Rs[0-9]+"
prefix <- "http://snpedia.com"
links <- getHTMLLinks(strURL)
needlinks <- gregexpr(pattern,links)
needlinkslist <- list()
for (i in which(unlist(needlinks)>0)){
preadress <- substr(links[i],needlinks[[i]],needlinks[[i]]+attr(needlinks[[i]],'match.length')-1)
needlinkslist<- c(needlinkslist,list(preadress))
adresses <- lapply(needlinkslist,function(x)paste(prefix,x,sep=""))
}
adresses
}
greg <- function(pattern,istring){
#greg函數(shù)查看單個(gè)字符串istring,并且返回匹配的部分,不匹配返回空
gregout <- gregexpr(pattern,istring)
substr(istring,gregout[[1]],gregout[[1]]+attr(gregout[[1]],'match.length')-1)
}
library(RCurl)
library(XML)
#自定義部分
strURL <- "http://snpedia.com/index.php?title=Special%3ASearch&profile=default&fulltext=Search&search=Congenital+adrenal+hyperplasia"
output <- "ouput.txt"
message(paste("[prog]",strURL,output,sep=" "))
strURLs <- extradress(strURL)
pattlistMainTable <- list("Orientation$","Stabilized$","Reference$","Chromosome$","Position$","Gene$")
#此匹配模式列表用于返回該字符串所在index�,而對(duì)應(yīng)的值是index是該index+1
pattlistClinvar <- list("Risk\n\n[-A-Za-z0-9_.%;\\(\\), ]+","Alt\n\n[-A-Za-z0-9_.%;\\(\\), ]+",
"Reference\n\n[-A-Za-z0-9_.%;\\(\\) ]+","Significance \n[A-Za-z ]+","Disease \n\n[A-Za-z ]+",
"CLNDBN \n\n[-A-Za-z0-9_.% ]+","Reversed \n\n[0-9]+", "HGVS \n\n[-A-Za-z0-9_.%:> ]+","CLNSRC \n\n[-A-Za-z0-9_.% ]+","CLNACC \n\n[-A-Za-z0-9_.%, ]+")
#此匹配模式列表用于返回相應(yīng)clinvar
inf <- " "
for ( strURL in strURLs){
dat <- getinf(strURL)
if (inf==" "){
inf <- dat
}else{
inf <- rbind(inf,dat)
}
}
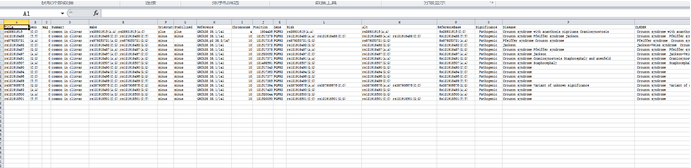
write.table(inf, file = output, row.names = F, col.names=T,quote = F, sep="\t") # tab 分隔的文件
message("完成!")
結(jié)果可以用直接打開�,也可以用excel的自文本打開,方便查看
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330