R語言數(shù)據(jù)分析利器data.table包—數(shù)據(jù)框結(jié)構(gòu)處理精講
R語言data.table包是自帶包data.frame的升級版����,用于數(shù)據(jù)框格式數(shù)據(jù)的處理,最大的特點(diǎn)快�。包括兩個方面,一方面是寫的快���,代碼簡潔��,只要一行命令就可以完成諸多任務(wù)����,另一方面是處理快,內(nèi)部處理的步驟進(jìn)行了程序上的優(yōu)化���,使用多線程�����,甚至很多函數(shù)是使用C寫的����,大大加快數(shù)據(jù)運(yùn)行速度�����。因此�,在對大數(shù)據(jù)處理上,使用data.table無疑具有極高的效率�。這里我們主要講的是它對數(shù)據(jù)框結(jié)構(gòu)的快捷處理。
和data.frame的高度兼容
DT = data.table(x=rep(c("b","a","c"),each=3), y=c(1,3,6), v=1:9)
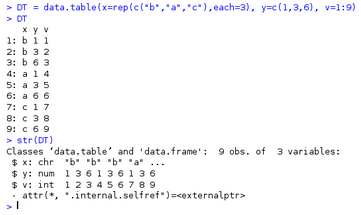
下面DT都是用這個data.table
可見它是屬于data.table和data.frame類�����,并且取列�����,維數(shù),都可以采用data.frame的方法�。
DF = data.frame(x=rep(c("b","a","c"),each=3), y=c(1,3,6), v=1:9)
DT = data.table(x=rep(c("b","a","c"),each=3), y=c(1,3,6), v=1:9)
DF
DT
identical(dim(DT), dim(DF)) # TRUE
identical(DF$a, DT$a) # TRUE
is.list(DF) # TRUE
is.list(DT) # TRUE
is.data.frame(DT) # TRUE
不過data.frame默認(rèn)將非數(shù)字轉(zhuǎn)化為因子;而data.table 會將非數(shù)字轉(zhuǎn)化為字符

data.table數(shù)據(jù)框也可使用dplyr包的管道��,這里不作闡述�����。
data.table常用的函數(shù)
as.data.table(x, keep.rownames=FALSE, ...)?將一個R對象轉(zhuǎn)化為data.table�,R可以時矢量��,列表����,data.frame等,keep.rownames決定是否保留行名或者列表名�,默認(rèn)FALSE,如果TRUE,將行名存在"rn"行中,keep.rownames="id",行名保存在"id"行中���。
DF = data.frame(x=rep(c("b","a","c"),each=3), y=c(1,3,6), v=1:9) #新建data.frame DF
DT=as.data.table(DF,keep.rownames=TRUE)

setDT(x, keep.rownames=FALSE, key=NULL, check.names=FALSE)?把一個R對象轉(zhuǎn)化為data.table����,比as.data.table快�,因?yàn)橐詡鞯刂返姆绞街苯有薷脑瓕ο?,沒有拷貝
copy(x)?深度拷貝一個data.table�,x即data.table對象。data.table為了加快速度����,會直接在對象地址修改,因此如果需要就要在修改前copy���,直接修改的命令有:=添加一列��,set系列命令比如下面提到的setattr,setnames,setorder等���;當(dāng)使用dt_names = names(DT)的時候,修改dt_names會修改原data.table的列名����,如果不想被修改,這個時候應(yīng)copy原data.table��,也可以使用dt_names <- copy(names(DT))直接copy列名�����,這樣不必copy整個data.table。
kDT=copy(DT) #kDT時DT的一個copy
rowid(..., prefix=NULL) ?產(chǎn)生unique的id�����,prefix參數(shù)在id前面加前綴

setattr?設(shè)置DT的屬性���,setattr(x,name,value) x時data.table,list或者data.frame,而name時屬性名����,value時屬性值�,setnames(x,old,new)���,設(shè)置x的列名���,old是舊列名或者數(shù)字位置,new是新列名

setcolorder(x,neworder)?重新安排列的順序�����,neworder字符矢量或者行數(shù)

set(DT,rownum,colnum,value)直接修改某個位置的值�����,rownum行號,colnum���,列號����,行號列號推薦使用整型��,保證最快速度����,方法是在數(shù)字后面加L,比如1L�,value是需要賦予的值。比:=還快�����,通常和循環(huán)配合使用
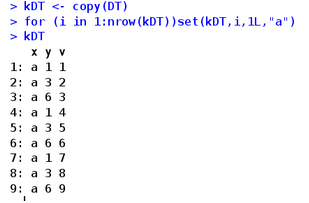
至于這個操作究竟有多快�����,可以看一下(參照官方manual的命令)���,另外個人覺得最牛的三個函數(shù)是set(),fread,和fwrite
fread
fread(input, sep="auto", sep2="auto", nrows=-1L, header="auto", na.strings="NA", file,
stringsAsFactors=FALSE, verbose=getOption("datatable.verbose"), autostart=1L,
skip=0L, select=NULL, drop=NULL, colClasses=NULL,
integer64=getOption("datatable.integer64"),
# default: "integer64"
dec=if (sep!=".") "." else ",", col.names,
check.names=FALSE, encoding="unknown", quote="\"",
strip.white=TRUE, fill=FALSE, blank.lines.skip=FALSE, key=NULL,
showProgress=getOption("datatable.showProgress"), # default: TRUE
data.table=getOption("datatable.fread.datatable") # default: TRUE
)
input輸入的文件����,或者字符串(至少有一個"\n");
sep列之間的分隔符��;
sep2����,分隔符內(nèi)再分隔的分隔符,功能還沒有應(yīng)用���;
nrow�,讀取的行數(shù)���,默認(rèn)-l全部,nrow=0僅僅返回列名���;
header第一行是否是列名�;
na.strings,對NA的解釋�����;
file文件路徑�����,再確保沒有執(zhí)行shell命令時很有用,也可以在input參數(shù)輸入;
stringsASFactors是否轉(zhuǎn)化字符串為因子�,
verbose,是否交互和報告運(yùn)行時間�;
autostart,機(jī)器可讀這個區(qū)域任何行號�,默認(rèn)1L,如果這行是空,就讀下一行;
skip跳過讀取的行數(shù)�����,為1則從第二行開始讀��,設(shè)置了這個選項(xiàng)��,就會自動忽略autostart選項(xiàng)����,也可以是一個字符,skip="string",那么會從包含該字符的行開始讀;
select,需要保留的列名或者列號��,不要其它的���;
drop,需要取掉的列名或者列號���,要其它的���;
colClasses,類字符矢量���,用于罕見的覆蓋而不是常規(guī)使用�����,只會使一列變?yōu)楦叩念愋?,不能降低類型?br />
integer64,讀如64位的整型數(shù);
dec,小數(shù)分隔符����,默認(rèn)"."不然就是","
col.names,給列名,默認(rèn)試用header或者探測到的���,不然就是V+列號;
encoding,默認(rèn)"unknown"��,其它可能"UTF-8"或者"Latin-1"�����,不是用來重新編碼的,而是允許處理的字符串在本機(jī)編碼;
quote,默認(rèn)"""�,如果以雙引開頭,fread強(qiáng)有力的處理里面的引號���,如果失敗了就會用其它嘗試��,如果設(shè)置quote="",默認(rèn)引號不可用
strip.white��,默認(rèn)TRUE�,刪除結(jié)尾空白符����,如果FALSE,只取掉header的結(jié)尾空白符;
fill,默認(rèn)FALSE��,如果TRUE��,不等長的區(qū)域可以自動填上�����,利于文件順利讀入���;
blank.lines.skip,默認(rèn)FALSE,如果TRUE��,跳過空白行
key�����,設(shè)置key����,用一個或多個列名,會傳遞給setkey
showProgress,TRUE會顯示腳本進(jìn)程���,R層次的C代碼
data.table,TRUE返回data.table�,F(xiàn)ALSE返回data.frame
實(shí)例如下�,1.8GB的數(shù)據(jù)讀入94秒,可見讀入文件速度非?�??����,

fwrite
fwrite(x, file = "", append = FALSE, quote = "auto",
sep = ",", sep2 = c("","|",""),
eol = if (.Platform$OS.type=="windows") "\r\n" else "\n",
na = "", dec = ".", row.names = FALSE, col.names = TRUE,
qmethod = c("double","escape"),
logicalAsInt = FALSE, dateTimeAs = c("ISO","squash","epoch","write.csv"),
buffMB = 8L, nThread = getDTthreads(),
showProgress = getOption("datatable.showProgress"),
verbose = getOption("datatable.verbose"))
x,具有相同長度的列表���,比如data.frame和data.table等;
file���,輸出文件名,""意味著直接輸出到操作臺��;
append���,如果TRUE,在原文件的后面添加����;
quote�����,如果"auto",因子和列名只有在他們需要的時候才會被加上雙引號��,例如該部分包括分隔符�����,或者以"\n"結(jié)尾的一行��,或者雙引號它自己�,如果FALSE,那么區(qū)域不會加上雙引號���,如果TRUE���,就像寫入CSV文件一樣�,除了數(shù)字�����,其它都加上雙引號��;
sep,列之間的分隔符�;
sep2,對于是list的一列,寫出去時list成員間以sep2分隔��,它們是處于一列之內(nèi)�����,然后內(nèi)部再用字符分開�;
eol,行分隔符���,默認(rèn)Windows是"\r\n",其它的是"\n"����;
na,na值的表示,默認(rèn)""��;
dec��,小數(shù)點(diǎn)的表示�,默認(rèn)"."���;
row.names���,是否寫出行名,因?yàn)閐ata.table沒有行名��,所以默認(rèn)FALSE����;
col.names ,是否寫出列名����,默認(rèn)TRUE,如果沒有定義,并且append=TRUE和文件存在����,那么就會默認(rèn)使用FALSE;
qmethod,怎樣處理雙引號���,"escape",類似于C風(fēng)格����,用反斜杠逃避雙引�����,“double",默認(rèn)����,雙引號成對��;
logicalAsInt,邏輯值作為數(shù)字寫出還是作為FALSE和TRUE寫出���;
dateTimeAS, 決定 Date/IDate,ITime和POSIXct的寫出���,"ISO"默認(rèn),-2016-09-12, 18:12:16和2016-09-12T18:12:16.999999Z;"squash",-20160912,181216和20160912181216999;"epoch",-17056����,65536和1473703936;"write.csv"�,就像write.csv一樣寫入時間�����,僅僅對POSIXct有影響,as.character將digits.secs轉(zhuǎn)化字符并通過R內(nèi)部UTC轉(zhuǎn)回本地時間�����。前面三個選項(xiàng)都是用新的特定C代碼寫的�����,較快
buffMB,每個核心給的緩沖大小,在1到1024之間���,默認(rèn)80MB
nThread,用的核心數(shù)�。
showProgress,在工作臺顯示進(jìn)程���,當(dāng)用file==""時�,自動忽略此參數(shù)
verbose,是否交互和報告時間

data.table數(shù)據(jù)框結(jié)構(gòu)處理語法
data.table[ i , j , by]
?? i 決定顯示的行,可以是整型���,可以是字符���,可以是表達(dá)式�����,j 是對數(shù)據(jù)框進(jìn)行求值��,決定顯示的列����,by對數(shù)據(jù)進(jìn)行指定分組,除了by ,也可以添加其它的一系列參數(shù):
keyby�����,with,nomatch,mult,rollollends,which,.SDcols,on�。
i 決定顯示的行
DT = data.table(x=rep(c("b","a","c"),each=3), y=c(1,3,6), v=1:9) #新建data.table對象DT
DT[2] #取第二行
DT[2:3] #取第二到第三行
DT[order(x)] #將DT按照X列排序���,簡化操作,另外排序也可以setkey(DT,x)����,出來的DT就已經(jīng)是按照x列排序的了。用haskey(DT)判斷DT是否已經(jīng)設(shè)置了key�,可以設(shè)置多個列作為key
DT[y>2] # DT$y>2的行
DT[!2:4] #除了2到4行剩余的行
DT["a",on="x"] #on 參數(shù)��,DT[D,on=c("x","y")]取DT上"x","y"列上與D上的列相關(guān)聯(lián)的行。比如此例取出DT 中 X 列為"a"的行���。on參數(shù)的第一列必須是DT的第一列
DT[.("a"), on="x"] #和上面一樣.()有類似與c()的作用
DT["a", on=.(x)] #和上面一樣
DT[x=="a"] # 和上面一樣,和使用on一樣�����,都是使用二分查找法���,所以它們速度比用data.frame的快��。也可以用setkey之后的DT,輸入DT["a"]或者DT["a",on=.(x)]如果有幾個key的話推薦用on
DT[x!="b" | y!=3] #x列不等于"b"或者y列不等于3的行
DT[.("b", 3), on=.(x, v)] #取DT的x,v列上x="b",v=3的行
j 對數(shù)據(jù)框進(jìn)行求值輸出
??j 參數(shù)對數(shù)據(jù)進(jìn)行運(yùn)算���,比如sum,max,min,tail等基本函數(shù),輸出基本函數(shù)的計(jì)算結(jié)果���,還可以用n輸出第n列�����,.N(總列數(shù)����,直接在j輸入.N取最后一列),:=(直接在data.table上添加列��,沒有copy過程�����,所以快����,有需要的話注意備份),.SD輸出子集,.SD[n]輸出子集的第n列��,DT[,.(a = .(), b = .())] 輸出一個a�、b列的數(shù)據(jù)框,.()就是要輸入的a���、b列的內(nèi)容,還可以將一系列處理放入大括號,如{tmp <- mean(y);.(a = a-tmp, b = b-tmp)}
DT[,y] #返回y列���,矢量
DT[,.(y)] #返回y列,返回data.table
DT[, sum(y)] #對y列求和
DT[, .(sv=sum(v))] #對y列求和��,輸出sv列�,列中的內(nèi)容就是sum(v)
DT[, .(sum(y)), by=x] # 對x列進(jìn)行分組后對各分組y列求總和
DT[, sum(y), keyby=x] #對x列進(jìn)行分組后對各分組y列求和,并且結(jié)果按照x排序
DT[, sum(y), by=x][order(x)] #和上面一樣�,采取data.table的鏈接符合表達(dá)式
DT[v>1, sum(y), by=v] #對v列進(jìn)行分組后,取各組中v>1的行出來,各組分別對定義的行中的y求和
DT[, .N, by=x] #用by對DT 用x分組后�����,取每個分組的總列數(shù)
DT[, .SD, .SDcols=x:y] #用.SDcols 定義SubDadaColums(子列數(shù)據(jù))���,這里取出x到之間的列作為子集,然后.SD 輸出所有子集
DT[2:5, cat(y, "\n")] #直接在j 用cat函數(shù)�,輸出2到5列的y值
DT[, plot(a,b), by=x] #直接在j用plot函數(shù)畫圖,對于每個x的分組畫一張圖
DT[, m:=mean(v), by=x] #對DT按x列分組���,直接在DT上再添加一列m,m的內(nèi)容是mean(v)����,直接修改并且不輸出到屏幕上
DT[, m:=mean(v), by=x] #加[]將結(jié)果輸出到屏幕上
DT[,c("m","n"):=list(mean(v),min(v)), by=x][] # 按x分組后同時添加m,n 兩列,內(nèi)容是分別是mean(v)和min(v)�����,并且輸出到屏幕
DT[, `:=`(m=mean(v),n=min(v)),by=x][] #內(nèi)容和上面一樣����,另外的寫法
DT[,(seq = min(y):max(v)), by=x] #輸出seq列,內(nèi)容是min(a)到max(b)
DT[, c(.(y=max(y)), lapply(.SD, min)), by=x, .SDcols=y:v] #對DT取y:v之間的列��,按x分組�,輸出max(y),對y到v之間的列每列求最小值輸出。
by���,on�,with等參數(shù)
by?對數(shù)據(jù)進(jìn)行分組

on?DT[D,on=c("x","y")]取DT上"x","y"列上與D上的列相關(guān)聯(lián)的行

DT[X, on="x"] #左聯(lián)接
X[DT, on="x"] #右聯(lián)接
DT[X, on="x", nomatch=0] #內(nèi)聯(lián)接,nomatch=0表示不返回不匹配的行,nomatch=NA表示以NA返回不匹配的值
with?默認(rèn)是TRUE���,列名能夠當(dāng)作變量使用����,即x相當(dāng)于DT$"x",當(dāng)是FALSE時,列名僅僅作為字符串����,可以用傳統(tǒng)data.frame方法并且返回data.table,x[, cols, with=FALSE] 和x[, .SD, .SDcols=cols]一樣

mult?當(dāng)有i 中匹配到的有多行時����,mult控制返回的行,"all"返回全部(默認(rèn))�����,"first",返回第一行��,"last"返回最后一行
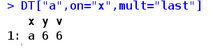
roll?當(dāng)i中全部行匹配只有某一行不匹配時�,填充該行空白,+Inf(或者TRUE)用上一行的值填充���,-Inf用下一行的值填充���,輸入某數(shù)字時,表示能夠填充的距離����,near用最近的行填充
rollends?填充首尾不匹配的行,TRUE填充�,F(xiàn)ALSE不填充,與roll一同使用

which?TRUE返回匹配的行號����,NA返回不匹配的行號,默認(rèn)FALSE返回匹配的行

.SDcols?取特定的列�����,然后.SD就包括了頁寫選定的特定列���,可以對這些子集應(yīng)用函數(shù)處理

allow.cartesian?FALSE防止結(jié)果超出nrow(x)+nrow(i)行��,常常因?yàn)閕中有重復(fù)的列而超出�����。這里的cartesian和傳統(tǒng)上的cartesian不一樣���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫���,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330