使用R語言預測泰坦尼克號乘客生存率
1912年4月10日�,號稱 “世界工業(yè)史上的奇跡”的豪華客輪泰坦尼克號開始了自己的處女航�,從英國的南安普頓出發(fā)駛往美國紐約�����,4月14日晚���,泰坦尼克號在北大西洋撞上冰山而傾覆��,1502人葬生海底����,705人得救。造成了當時在和平時期最嚴重的一次航海事故�����,也是迄今為止最著名的一次海難���。38歲的查爾斯·萊特勒是泰坦尼克二副��,他是最后一個從冰冷的海水中被拖上救生船��、職位最高的生還者����。在他寫的回憶錄中�,列舉幾個讓人震撼的情景:
在第一艘救生艇下水后,我對甲板上一名姓斯特勞的女人說:你能隨我一起到那只救生艇上去嗎�?沒想到她搖了搖頭:不,我想還是呆在船上好��。她的丈夫問:你為什么不愿意上救生艇呢?這名女人竟笑著回答:不���,我還是陪著你�����。此后����,我再也沒有見到過這對夫婦…
亞斯特四世(當時世界第一首富)把懷著五個月身孕的妻子瑪?shù)铝账蜕?號救生艇后����,站在甲板上��,帶著他的狗���,點燃一根雪茄煙��,對劃向遠處的小艇最后呼喊:我愛你們����!一副默多克曾命令亞斯特上船��,被亞斯特憤怒的拒絕:我喜歡最初的說法(保護弱者)!然后�,把唯一的位置讓給三等艙的一個愛爾蘭婦女……
斯特勞斯是世界第二巨富,美國梅西百貨公司創(chuàng)始人����。他無論用什么辦法,他的太太羅莎莉始終拒絕上八號救生艇���,她說:多少年來����,你去哪我去哪����,我會陪你去你要去的任何地方。八號艇救生員對67歲的斯特勞斯先生提議:我保證不會有人反對像您這樣的老先生上小艇�����。斯特勞斯堅定地回答:我絕不會在別的男人之前上救生艇�����。然后挽著63歲羅莎莉的手臂�,一對老夫婦蹣姍地走到甲板的藤椅上坐下�,等待著最后的時刻…
新婚燕爾的麗德帕絲同丈夫去美國渡蜜月��,她死死抱住丈夫不愿獨自逃生���,丈夫在萬 般無奈中一拳將她打昏�,麗德帕絲醒來時��,她已在一條海上救生艇上了���。此后����,她終生未再嫁�����,以此懷念亡夫…
在這種生死存亡的緊要關頭���,我們常常認為社會等級越高、影響力越大���,公眾認可度越高的人物��,生存的概率應該越大�,其次,乘客家庭成員多�����,成員間的協(xié)作和對求生的渴望度越高�����,生存的概率越高�。然而,很多時候����,事情產(chǎn)生這樣的結果的原因并非我們主觀臆測的那樣,我們需要通過對真實數(shù)據(jù)進行科學的分析�,才能發(fā)現(xiàn)很多事情并非我們想象的那樣簡單,事情產(chǎn)生的本質�����,往往隱藏在數(shù)據(jù)之中
下面我們就使用R語言根據(jù)已知存活情況的數(shù)據(jù)建立分析模型來預測其他一部分乘客的存活情況
一.數(shù)據(jù)的導入和查看
#有些包需要安裝,我們專門建立一個packagemanger.R文件來管理它門,在工程主入口文件中先進行編譯后導入進行使用
source('D:/R/RStudioWorkspace/titanic_test/utils/packageManager.R',encoding = 'UTF-8')
library('ggplot2') # 可視化
library('ggthemes') # 可視化
library('scales') # 可視化
library('dplyr') # 數(shù)據(jù)處理
library('mice') # 填充缺失數(shù)據(jù)
library('randomForest') # 分類算法
train <- read.csv('D:/R/RStudioWorkspace/Titanic dataset from Kaggle/train.csv',stringsAsFactors= FALSE)
test <- read.csv('D:/R/RStudioWorkspace/Titanic dataset from Kaggle/test.csv',stringsAsFactors= FALSE)
# 合并兩個數(shù)據(jù)框,查看相關變量名稱
total_data <- bind_rows(train,test)
str(total_data)
查看的數(shù)據(jù)結果如下:
'data.frame': 1309 obs. of 12 variables:
$ PassengerId: int 1 2 3 4 5 6 7 8 9 10 ...
$ Survived : int 0 1 1 1 0 0 0 0 1 1 ...
$ Pclass : int 3 1 3 1 3 3 1 3 3 2 ...
$ Name : chr "Braund, Mr. Owen Harris" "Cumings, Mrs. John Bradley (Florence Briggs Thayer)" "Heikkinen" ...
$ Sex : chr "male" "female" "female" "female" ...
$ Age : num 22 38 26 35 35 NA 54 2 27 14 ...
$ SibSp : int 1 1 0 1 0 0 0 3 0 1 ...
$ Parch : int 0 0 0 0 0 0 0 1 2 0 ...
$ Ticket : chr "A/5 21171" "PC 17599" "STON/O2. 3101282" "113803" ...
$ Fare : num 7.25 71.28 7.92 53.1 8.05 ...
$ Cabin : chr "" "C85" "" "C123" ...
$ Embarked : chr "S" "C" "S" "S" ...
我們觀察到一共有1309條數(shù)據(jù)�����,每一條數(shù)據(jù)有12個相關變量
$ PassengerId: 乘客編號
$ Survived :存活情況(存活:1 ; 死亡:0)
$ Pclass : 客場等級
$ Name : 乘客姓名
$ Sex : 性別
$ Age : 年齡
$ SibSp : 同乘的兄弟姐妹/配偶數(shù)
$ Parch : 同乘的父母/小孩數(shù)
$ Ticket : 船票編號
$ Fare : 船票價格
$ Cabin :客艙號
$ Embarked : 登船港口
二.特征工程
特征工程: 為了達到預測模型性能更佳,不僅要選取最好的算法��,還要盡可能的從原始數(shù)據(jù)中獲取更多的信息�。挖掘出更好的訓練數(shù)據(jù),就是特征工程建立的過程
2.1 觀察乘客名稱
注意到在乘客名字(Name)中��,有一個非常顯著的特點:乘客頭銜每個名字當中都包含了具體的稱謂或者說是頭銜���,將這部分信息提取出來后可以作為非常有用一個新變量���,可以幫助我們進行預測。此外也可以用乘客的姓代替家庭����,生成家庭變量。
# 從名稱中挖掘
# 從乘客名字中提取頭銜
#R中的grep�、grepl�、sub、gsub�����、regexpr�、gregexpr等函數(shù)都使用正則表達式的規(guī)則進行匹配����。默認是egrep的規(guī)則�����,sub函數(shù)只實現(xiàn)第一個位置的替換��,gsub函數(shù)實現(xiàn)全局的替換����。
total_data$Title <- gsub('(.*, )|(\\..*)', '', total_data$Name)
# 查看按照性別劃分的頭銜數(shù)量
table(total_data$Sex, total_data$Title)
結果如下:
Capt Col Don Dona Dr Jonkheer Lady Major Master Miss Mlle Mme Mr Mrs Ms Rev Sir the Countess
female 0 0 0 1 1 0 1 0 0 260 2 1 0 197 2 0 0 1
male 1 4 1 0 7 1 0 2 61 0 0 0 757 0 0 8 1 0
我們發(fā)現(xiàn)頭銜的類別太多,并且好多出現(xiàn)的頻次是很低的����,我們可以將這些類別進行合并
# 合并低頻頭銜為一類
rare_title <- c('Dona', 'Lady', 'the Countess','Capt', 'Col', 'Don',
'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer')
# 重命名稱呼
total_data$Title[total_data$Title == 'Mlle'] <- 'Miss'
total_data$Title[total_data$Title == 'Ms'] <- 'Miss'
total_data$Title[total_data$Title == 'Mme'] <- 'Mrs'
total_data$Title[total_data$Title %in% rare_title] <- 'Rare Title'
# 再次查看按照性別劃分的頭銜數(shù)量
table(total_data$Sex, total_data$Title)
得到如下結果:
Master Miss Mr Mrs Rare Title
female 0 264 0 198 4
male 61 0 757 0 25
最后,從名稱中獲取到姓氏
#sapply()函數(shù):根據(jù)傳入?yún)?shù)規(guī)則重新構建一個合理的數(shù)據(jù)類型返回
total_data$Surname <- sapply(total_data$Name, function(x) strsplit(x, split = '[,.]')[[1]][1])
2.2家庭成員數(shù)量的影響
既然我們已經(jīng)根據(jù)乘客的名字劃分成一些新的變量,我們可以把它進一步做一些新的家庭變量�。首先我們要做一個基于兄弟姐妹/配偶數(shù)量(s)和兒童/父母數(shù)量的家庭規(guī)模變量。
# 創(chuàng)建一個包含乘客自己的家庭規(guī)模變量
total_data$Fsize <- total_data$SibSp + total_data$Parch + 1
# Create a family variable
total_data$Family <- paste(total_data$Surname, total_data$Fsize, sep='_')
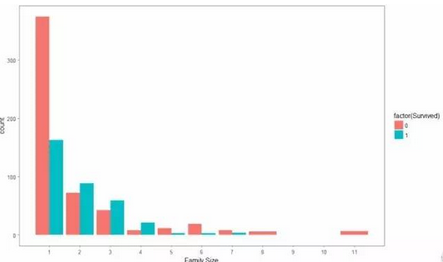
# 為了直觀顯示�����,我們可以用ggplot2 畫出家庭成員數(shù)量和生存家庭數(shù)情況的圖形
ggplot(total_data[1:891,], aes(x = Fsize, fill = factor(Survived))) +
geom_bar(stat='count', position='dodge') +
scale_x_continuous(breaks=c(1:11)) +
labs(x = 'Family Size') +
theme_few()
結果如下:
2.3客艙位置的影響
可以發(fā)現(xiàn)在乘客客艙變量 passenger cabin 也存在一些有價值的信息如客艙層數(shù) deck,但是這個變量的缺失值太多�,無法做出新的有效的變量,暫時放棄這個變量的挖掘
三.缺失數(shù)據(jù)的處理
觀察文件中的數(shù)據(jù),我們會發(fā)現(xiàn)有些乘客的信息參數(shù)并不完整��,由于所給的數(shù)據(jù)集并不大���,我們不能通過刪除一行或者一列來處理缺失值��,因而對于我們關注的一些字段參數(shù)���,我們需要根據(jù)統(tǒng)計學的描述數(shù)據(jù)(平均值、中位數(shù)等等)來合理給出缺失值
我們可以通過函數(shù)查看缺失數(shù)據(jù)的變量在第幾條數(shù)據(jù)出現(xiàn)缺失和總共缺失的個數(shù)
3.1年齡的缺失和填補
#統(tǒng)計年齡的缺失個數(shù)
age_null_count <- sum(is.na(total_data$Age))
#age_null_count = 263
通常我們會使用 rpart (recursive partitioning for regression) 包來做缺失值預測 在這里我將使用 mice 包進行處理�����。我們先要對因子變量(factor variables)因子化����,然后再進行多重插補法。
#統(tǒng)計年齡的缺失處理
age_null_count <- sum(is.na(total_data$Age))
# 使自變量因子化
factor_vars <- c('PassengerId','Pclass','Sex','Embarked',
'Title','Surname','Family','Fsize')
#lapply()返回一個長度與X一致的列表���,每個元素為FUN計算出的結果�����,且分別對應到X中的每個元素。
total_data[factor_vars] <- lapply(total_data[factor_vars],function(x) as.factor(x))
# 設置隨機值
set.seed(129)
# 執(zhí)行多重插補法,剔除一些沒什么用的變量:
mice_mod <- mice(total_data[, !names(total_data) %in% c('PassengerId','Name','Ticket','Cabin','Family','Surname','Survived')], method='rf')
# 保存完成的輸出
mice_output <- complete(mice_mod)
讓我們來比較一下我們得到的結果與原來的乘客的年齡分布以確保沒有明顯的偏差
# 繪制直方圖
par(mfrow=c(1,2))
hist(total_data$Age, freq=F, main='Age: Original Data',
col='darkgreen', ylim=c(0,0.04))
hist(mice_output$Age, freq=F, main='Age: MICE Output',
col='lightgreen', ylim=c(0,0.04))
結果如下,右邊圖和左邊圖有很高的相似度
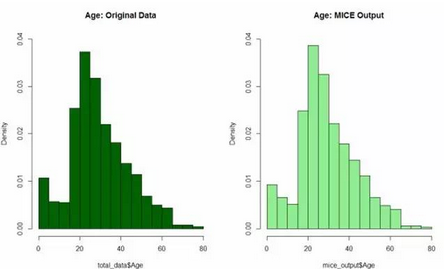
所以�,我們可以用mice模型的結果對原年齡數(shù)據(jù)進行替換。
# 用mice模型數(shù)據(jù)替換原始數(shù)據(jù)
full$Age <- mice_output$Age
# 再次查看年齡的缺失值數(shù)據(jù)
sum(is.na(full$Age))
# 0
3.2票價的缺失處理
#查看票價的缺失值
getFareNullID <- function(total_data){
count <- 0
for(i in 1:nrow(total_data))
if(is.na(total_data$Fare[i])){
#打印缺失票價的具體行數(shù)
print(i);
count <- count+1
}
return(count)
}
fare_null_count <- getFareNullID(total_data)
#fare_null_count = 1
得到票價缺失個數(shù)為1 �,缺失行數(shù)為第1044行
查看這一行我們會發(fā)現(xiàn)
total_data[1044,]
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin
1044 1044 NA 3 Storey, Mr. Thomas male 60.5 0 0 3701 NA
Embarked Title Surname Fsize Family
1044 S Mr Storey 1 Storey_1
我們發(fā)現(xiàn)港口和艙位是完整的,我們可以根據(jù)相同的港口和相同的艙位來大致估計該乘客的票價�����,我們?nèi)∵@些類似乘客的中位數(shù)來替換缺失的值
#從港口Southampton ('S')出發(fā)的三等艙乘客��。 從相同港口出發(fā)且處于相同艙位的乘客數(shù)目
same_farenull <- sum(total_data$Pclass == '3' & total_data$Embarked == 'S')
# 基于出發(fā)港口和客艙等級���,替換票價缺失值
total_data$Fare[1044] <- median(total_data[total_data$Pclass == '3' & total_data$Embarked == 'S', ]$Fare, na.rm = TRUE)
3.3登船港口號的缺失處理
#登船港口號的缺失值函數(shù)
getEmbarkedNullCount <- function(total_data) {
count0 <- 0
count <- 0
for(i in 1:nrow(total_data))
if(total_data$Embarked[i] == ""){
#可以打印出缺失的所在行數(shù)
print(i);
count <- count +1
}
return(count)
}
#登船港口號的缺失個數(shù)
embarked_null_count <- getEmbarkedNullCount(total_data)
#embarked_null_count =2
得到登船港口號缺失的個數(shù)為2 �,分別為 62 ��、830����,我估計對于有相同艙位等級(passenger class)和票價(Fare)的乘客也許有著相同的 登船港口位置embarkment .我們可以看到他們支付的票價分別為: $ 80 和 $ 80 同時他們的艙位等級分別是: 1 和 1 . 我們可以用箱線圖繪制出這三者之間關系圖
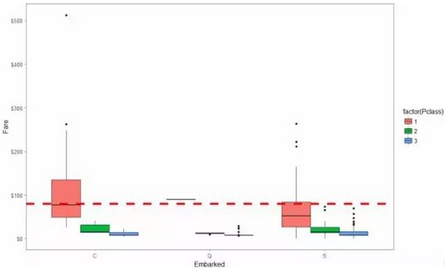
從港口 (‘C’)出發(fā)的頭等艙支付的票價的中位數(shù)正好為80。因此我們可以放心的把處于頭等艙且票價在$80的乘客62和830 的出發(fā)港口缺失值替換為’C’
total_data$Embarked[c(62, 830)] <- 'C'
我們基本上完成了重要參數(shù)缺失值的處理�����,我們的數(shù)據(jù)集變得更加完整了呢�����,接下來,需要根據(jù)新的數(shù)據(jù)集創(chuàng)建出新的特征工程
四.新特征工程的建立
通過上面缺失值填補的完成�,我們試著在新的數(shù)據(jù)集中挖掘出對乘客的存活有影響的一些因素,根據(jù)文章剛開始的幾段真實場景預測��,我們考慮在這種災難性的時刻��,小孩和老人相對于青年或者中年人應該會得到更好的照顧��,生存的概率應該更高��,其次���,如果你是一位母親�,你相比于其他成年女性是否會有更高的存活可能���?其實我還有一個想法����,那就是乘客的社會地位或者說階層 和當時的收入水平層次可能對生存有一定的影響����,當然這兩個因素對于現(xiàn)在的我們來說非常難以獲取�,畢竟事情發(fā)生在100多年前�����,或許當時的政府����,也需要很長時間才能準確的獲取到覺大部分人的這些側面信息���。
4.1年齡的劃分
我們考慮將年齡劃分成三個階段����,小于18歲算小孩�,18歲及以上至50歲為青壯年,50歲以上為老年人
#將年齡劃分成3個階段
total_data$AgeGroup[total_data$Age < 18] <- 'child'
total_data$AgeGroup[total_data$Age >= 18 & total_data$Age <= 50] <- 'young'
total_data$AgeGroup[total_data$Age > 50] <- 'old'
table(total_data$AgeGroup,total_data$Survived)
#得到如下結果
0 1
child 70 63
old 51 24
young 428 255
相比于成人�����,小孩的生存概率接近50%����,小孩得到的照顧比成年高的多
4.2是否為母親
我們從性別和頭銜中提煉出一位成年女性是否為一位母親,看看她的生存概率如何
# Adding Mother variable
total_data$IsMother <- 'Not'
total_data$IsMother[total_data$Sex == 'female' & total_data$Parch > 0 & total_data$Age > 18 & total_data$Title != 'Miss'] <- 'Yes'
# Show counts
table(total_data$IsMother, total_data$Survived)
#結果如下:
0 1
Not 534 303
Yes 15 39
我們發(fā)現(xiàn)����,如果是一位母親����,那么你生存下來的概率高達70%,之后���,我們整合上面兩個新變量到原數(shù)據(jù)集
# 完成因子化
total_data$AgeGroup <- factor(total_data$AgeGroup)
total_data$IsMother <- factor(total_data$IsMother)
#mice 包中顯示缺失數(shù)據(jù)的一種模式�。
md.pattern(total_data)
五.預測
到了最激動人心的時刻了有沒有����,前面四個步驟都是為了預測在做前期準備,如何進行預測呢�?
5.1.拆分測試和訓練數(shù)據(jù)集
#拆分數(shù)據(jù)集
train <- total_data[1:891,]
test <- total_data[892:1309,]
5.2 構建訓練模型
我們使用隨機森林法則作用于訓練數(shù)據(jù)集來構建我們需要的預測模型
#拆分數(shù)據(jù)集
train <- total_data[1:891,]
test <- total_data[892:1309,]
set.seed(754)
# 構建預測模型
rf_model <- randomForest(factor(Survived) ~ Pclass + Sex + Age + SibSp + Parch +
Fare + Embarked + Title +
Fsize + AgeGroup + IsMother,
data = train)
# 展示模型預測的錯誤率
# OOB:在構造單棵決策樹時我們只是隨機有放回的抽取了N個樣例,用沒有抽取到的樣例來測
# 試這棵決策樹的分類準確性��,這些樣例大概占總樣例數(shù)目的三分之一�;(一臉懵逼,該回去補補統(tǒng)計學的姿勢了有沒有-.-)
plot(rf_model, ylim=c(0,0.36))
mlabels <- factor(rf_model,levels = c(1,2,3),labels = c("OOB","0","1"))
legend('topright', colnames(rf_model$err.rate),levels(mlabels) ,col=1:3, fill=1:3)
結果如下
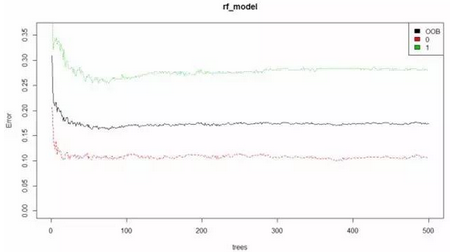
黑色那條線表示:整體誤差率(the overall error rate)低于20% 紅色和綠色分別表示:遇難與生還的誤差率 至此相對于生還來說,我們可以更準確的預測出死亡����。
5.3相關性檢測
通過隨機森林中所有決策樹的Gini 計算出其他變量相對于生存變量的相關性排行,我們可以看出那些因素對生存率影響較大
# 重要性系數(shù)
importance <- importance(rf_model)
varImportance <- data.frame(Variables = row.names(importance),
Importance = round(importance[ ,'MeanDecreaseGini'],2))
# 創(chuàng)建基于重要性系數(shù)排列的變量
rankImportance <- varImportance %>%
mutate(Rank = paste0('#',dense_rank(desc(Importance))))
# 使用 ggplot2 繪出重要系數(shù)的排名
ggplot(rankImportance, aes(x = reorder(Variables, Importance),
y = Importance, total_data = Importance)) +
geom_bar(stat='identity') +
geom_text(aes(x = Variables, y = 0.5, label = Rank),
hjust=0, vjust=0.55, size = 4, colour = 'red') +
labs(x = 'Variables') +
coord_flip() +
theme_few()
結果如下:
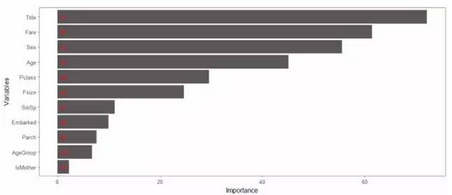
我們發(fā)現(xiàn)�����,頭銜稱號和船票價格及性別年齡對生存率的影響比較大,我們剛剛認為的小孩�、老人和是否為母親 這幾個特征應該有很大的生存幾率,但是結果并不是這樣�����,現(xiàn)實還是比較殘酷����!
5.4預測
最后����,我們使用訓練好的特征模型作用于測試數(shù)據(jù)上,得到我們的預測結果
#預測
prediction <- predict(rf_model, test)
# 保存數(shù)據(jù)結果passagerId 和survived參數(shù)
solution <- data.frame(PassengerID = test$PassengerId, Survived = prediction)
# 保存到文件
write.csv(solution, file = 'D:/R/RStudioWorkspace/titanic_test/output/predict_Solution.csv', row.names = F)
得到預測結果文件����,我們可以上傳到Kaggle,查看自己的排名情況,
就先分析到這吧����,感謝你的時間,后面靈感涌現(xiàn)挖掘到新的特征變量再添加到特征工程中�����,這樣預測結果應該會更加準確。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330