R語言中的回歸診斷-car包
如何判斷我們的線性回歸模型是正確的��?
1�����、回歸診斷的基本方法
opar<-par(no.readOnly=TRUE)
fit <- lm(weight ~ height, data = women)
par(mfrow = c(2, 2))
plot(fit)
par(opar)
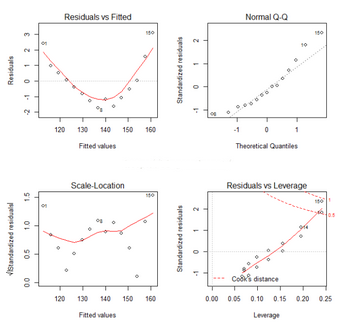
為理解這些圖形���,我們來回顧一下OLS回歸的統(tǒng)計(jì)假設(shè)。
(1)正態(tài)性(主要使用QQ圖)當(dāng)預(yù)測變量值固定時(shí)�,因變量成正態(tài)分布,則殘差值也應(yīng)該是一個(gè)均值為0的正態(tài)分布��。正態(tài)Q-Q圖(Normal Q-Q���,右上)是在正態(tài)分布對應(yīng)的值下�����,標(biāo)準(zhǔn)化殘差的概率圖�。若滿足正態(tài)假設(shè),那么圖上的點(diǎn)應(yīng)該落在呈45度角的直線上�����;若不是如此��,那么就違反了正態(tài)性的假設(shè)����。
(2)獨(dú)立性 你無法從這些圖中分辨出因變量值是否相互獨(dú)立,只能從收集的數(shù)據(jù)中來驗(yàn)證��。上面的例子中����,沒有任何先驗(yàn)的理由去相信一位女性的體重會(huì)影響另外一位女性的體重。假若你發(fā)現(xiàn)數(shù)據(jù)是從一個(gè)家庭抽樣得來的���,那么可能必須要調(diào)整模型獨(dú)立性的假設(shè)����。
(3)線性(使用左上角的圖�,該曲線盡量擬合所有點(diǎn))
若因變量與自變量線性相關(guān)���,那么殘差值與預(yù)測(擬合)值就沒有任何系統(tǒng)關(guān)聯(lián)����。換句話說,除了白噪聲���,模型應(yīng)該包含數(shù)據(jù)中所有的系統(tǒng)方差�����。在“殘差圖與擬合圖”Residuals
vs Fitted�����,左上)中可以清楚的看到一個(gè)曲線關(guān)系���,這暗示著你可能需要對回歸模型加上一個(gè)二次項(xiàng)。
(4)同方差性(左下角�����,點(diǎn)隨機(jī)分布在曲線的周圍)
若滿足不變方差假設(shè)��,那么在位置尺度圖(Scale-Location
Graph,左下)中��,水平線周圍的點(diǎn)應(yīng)該隨機(jī)分布����。該圖似乎滿足此假設(shè)。最后一幅“殘差與杠圖”(Residuals vs
Leverage��,右下)提供了你可能關(guān)注的單個(gè)觀測點(diǎn)的信息����。從圖形可以鑒別出離群點(diǎn)、高杠桿值點(diǎn)和強(qiáng)影響點(diǎn)
通過看圖重新修改模型
newfit <- lm(weight ~ height + I(height^2), data = women[-c(13, 15),])
par(mfrow = c(2, 2))
plot(newfit)
par(opar)
2���、使用改進(jìn)的方法進(jìn)行
主要使用的car包��,進(jìn)行回歸診斷

(1)自變量的正態(tài)分布
qqPlot()函數(shù)提供了更為精確的正態(tài)假設(shè)檢驗(yàn)方法
library(car)
fit <- lm(Murder ~ Population + Illiteracy + Income +
Frost, data = states)
qqPlot(fit, labels = FALSE, simulate = TRUE, main = "Q-Q Plot")
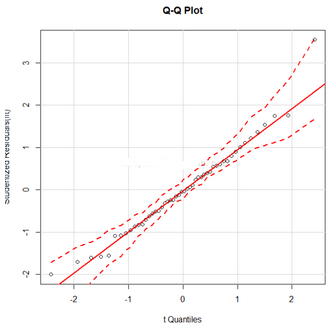
(2)誤差的獨(dú)立性
durbinWatsonTest(fit)
lag Autocorrelation D-W Statistic p-value
1 -0.2006929 2.317691 0.248
Alternative hypothesis: rho != 0
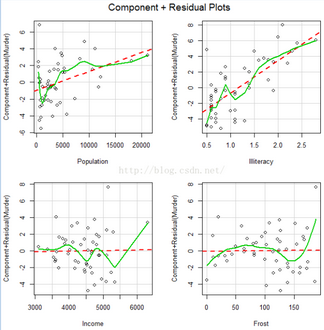
(3)線性相關(guān)性
crPlots(fit, one.page = TRUE, ask = FALSE)
(4)同方差性
1�、car包提供了兩個(gè)有用的函數(shù)�,可以判斷誤差方差是否恒定。ncvTest()函數(shù)生成一個(gè)計(jì)分檢驗(yàn)����,零假設(shè)為誤差方差不變,備擇假設(shè)為誤差方差隨著擬合值水平的變化而變化�。
2���、spreadLevelPlot()函數(shù)創(chuàng)建一個(gè)添加了最佳擬合曲線的散點(diǎn)圖,展示標(biāo)準(zhǔn)化殘差絕對值與擬合值的關(guān)系
library(car)
ncvTest(fit)
Non-constant Variance Score Test
Variance formula: ~ fitted.values
Chisquare = 1.746514 Df = 1 p = 0.1863156
滿足方差不變 p = 0.1863156
spreadLevelPlot(fit)
3��、線性模型假設(shè)的綜合驗(yàn)證
library(gvlma)
gvmodel <- gvlma(fit)
summary(gvmodel)
Call:
lm(formula = Murder ~ Population + Illiteracy + Income + Frost,
data = states)
Residuals:
Min 1Q Median 3Q Max
-4.7960 -1.6495 -0.0811 1.4815 7.6210
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.235e+00 3.866e+00 0.319 0.7510
Population 2.237e-04 9.052e-05 2.471 0.0173 *
Illiteracy 4.143e+00 8.744e-01 4.738 2.19e-05 ***
Income 6.442e-05 6.837e-04 0.094 0.9253
Frost 5.813e-04 1.005e-02 0.058 0.9541
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.535 on 45 degrees of freedom
Multiple R-squared: 0.567, Adjusted R-squared: 0.5285
F-statistic: 14.73 on 4 and 45 DF, p-value: 9.133e-08
ASSESSMENT OF THE LINEAR MODEL ASSUMPTIONS
USING THE GLOBAL TEST ON 4 DEGREES-OF-FREEDOM:
Level of Significance = 0.05
Call:
gvlma(x = fit)
Value p-value Decision
Global Stat 2.7728 0.5965 Assumptions acceptable.
Skewness 1.5374 0.2150 Assumptions acceptable.
Kurtosis 0.6376 0.4246 Assumptions acceptable.
Link Function 0.1154 0.7341 Assumptions acceptable.
Heteroscedasticity 0.4824 0.4873 Assumptions acceptable.
4�����、多重共線性
如何檢測多重共線性
library(car)
vif(fit)
Population Illiteracy Income Frost
1.245282 2.165848 1.345822 2.082547
sqrt(vif(fit)) > 2
Population Illiteracy Income Frost
FALSE FALSE FALSE FALSE
如何解決多重共線性��?
逐步回歸法(此法最常用的�����,也最有效)
R語言回歸分析中的異常值點(diǎn)的介紹
(1)離群點(diǎn)
如何識別離群點(diǎn)���?
1、Q-Q圖���,落在置信區(qū)間帶[-2�,2]外的點(diǎn)即可被認(rèn)為是離群點(diǎn)���。
2���、一個(gè)粗糙的判斷準(zhǔn)則:標(biāo)準(zhǔn)化殘差值大于2或者小于2的點(diǎn)可能是離群
3���、library(car)
outlierTest(fit) 顯示離群點(diǎn)
rstudent unadjusted p-value Bonferonni p
Nevada 3.542929 0.00095088 0.047544
(2)高杠桿值點(diǎn)
它們是由許多異常的預(yù)測變量值組合起來的,與響應(yīng)變量值沒有關(guān)系
高杠桿值的觀測點(diǎn)可通過帽子統(tǒng)計(jì)量(hat statistic)判斷
hat.plot <- function(fit){
p <- length(coefficients(fit))
n <- length(fitted(fit))
plot(hatvalues(fit), main = "Index Plot of Hat Values")
abline(h = c(2, 3) * p/n, col = "red", lty = 2)
identify(1:n, hatvalues(fit), names(hatvalues(fit)))
}
hat.plot(fit)
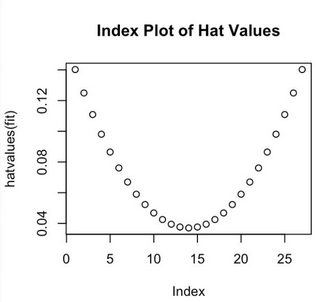
(3)強(qiáng)影響點(diǎn)
強(qiáng)影響點(diǎn)��,即對模型參數(shù)估計(jì)值影響有些比例失衡的點(diǎn)�����。例如�,若移除模型的一個(gè)觀測點(diǎn)時(shí)模型會(huì)發(fā)生巨大的改變,那么你就需要檢測一下數(shù)據(jù)中是否存在強(qiáng)影響點(diǎn)了
cutoff <- 4/(nrow(states) - length(fit$coefficients) - 2)
plot(fit, which = 4, cook.levels = cutoff)
abline(h = cutoff, lty = 2, col = "red")
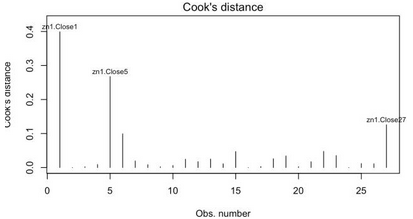
4���、如何對線性模型進(jìn)行改進(jìn)����?
1�、刪除觀測點(diǎn);
刪除離群點(diǎn)通??梢蕴岣邤?shù)據(jù)集對于正態(tài)假設(shè)的擬合度,而強(qiáng)影響點(diǎn)會(huì)干擾結(jié)果�����,通常也會(huì)被刪除。刪除最大的離群點(diǎn)或者強(qiáng)影響點(diǎn)后����,模型需要重新擬合
2、變量變換:

Box-Cox正態(tài)變換
library(car)
summary(powerTransform(states$Murder))
library(car)
boxTidwell(Murder ~ Population + Illiteracy, data = states)
3�、添加或刪除變量;
4����、使用其他回歸方法���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330