sas信用評(píng)分之第二步變量篩選
今天介紹變量初步選擇�����。這部分的內(nèi)容我就只介紹information –value,我這次做的模型用的邏輯回歸����,后面會(huì)更新以基尼系數(shù)或者信息熵基礎(chǔ)的篩選變量��,期待我把���。
Iv值的介紹你們已經(jīng)很熟悉了,我這次就簡單粗暴的說下變量iv值到那個(gè)數(shù)就可以用的啦���。
(1):在很多書上說要達(dá)到0.1-0.3才是中等相關(guān)���,達(dá)到0.3是強(qiáng)相關(guān),但是這里必須提及�,變量的iv值本來就是變量多個(gè)分段的iv值的相加。所以我們做這部分工作的時(shí)候就發(fā)現(xiàn)�,一個(gè)變量我要是變態(tài)一點(diǎn),分成1000分�,他可以達(dá)到1.5,iv值是很高啊���,這個(gè)變量你一旦用下聚類或者是決策樹分下類��,就發(fā)現(xiàn)iv值其實(shí)是很低的�����,所以這個(gè)iv值的計(jì)算我們需要大概的給個(gè)分多少段���。
(2):在第一點(diǎn)中提到分幾份����,但是分幾份是針對連續(xù)變量�,對于字符變量的。我建議可以先使用最優(yōu)分段分下組再進(jìn)行計(jì)算iv值�。但是如果字符變量的分類在4-10類的話還是可以直接計(jì)算iv值的。
(3):對于在日常的建模中���,其實(shí)并不是iv值大于0.1才會(huì)被篩選出來��,我就在建模中碰見一個(gè)問題���,就是iv值大于0.1都是同類變量�,相關(guān)性極高,這些變量雖然iv值很高���,但是丟進(jìn)邏輯回歸中是不會(huì)被全部選中的�����,因?yàn)槲覀兌贾拦簿€性強(qiáng)的變量對于我們模型其實(shí)是不好的����。講了這么多就是為了說,變量初步選擇的時(shí)候我一般是大于iv值0.02我會(huì)篩選出來����,不為什么,寧可錯(cuò)殺一千��,不可放過一個(gè)�,我對變量就是這么殘暴。在這里我考慮到一點(diǎn)��,就是可能一個(gè)變量單獨(dú)對因變量的預(yù)測力不是很強(qiáng)���,但是跟其他變量結(jié)合的時(shí)候����,可能會(huì)產(chǎn)生不一樣的結(jié)果哈����。
例如哈,我舉一個(gè)很不恰當(dāng)?shù)睦庸磺‘?dāng)?shù)睦庸?,不要噴我。譬如婚姻狀況和年紀(jì)����,可能這兩個(gè)變量單獨(dú)對因變量沒什么明顯的體現(xiàn),但是結(jié)合在一起呢��,譬如25歲下離婚的人是不是會(huì)比25歲以上離婚不一樣呢����。你們順著這個(gè)思路想下去就可以啦,我再說下去25歲以下離婚怎么怎么樣�����,我就要被噴了�。畢竟我還是怕鍵盤俠。
這篇文章的代碼我之前是發(fā)過的��。路徑在這里:sas輸出變量的基尼系數(shù)以及iv值��。在這篇文章中我介紹下結(jié)果:
代碼的使用在上面路徑中有介紹���,點(diǎn)下去就可以看了。介紹下結(jié)果�����,score2是分組后的變量就是譬如說年齡中52歲分組后是第3組,那么他觀測的值就是3�����。score3輸出基尼系數(shù)����,這部分的內(nèi)容之后用到基尼系數(shù)再說哈。我們著重說下score4以及score5.
Score4的表格是長這樣子的:
你看到的var_name這一列的變量是每個(gè)變量名價(jià)格前綴“p_”如果是字符變量就不加前綴“p_”,_freq_這一變量是分組數(shù)�,我這邊設(shè)定的是分成5組,你問我為什么上面寫著6��,因?yàn)槲疫@批數(shù)據(jù)中有缺失���,缺失不參與分組����,就是第6組啦�����。最后一列就是iv值啦,我剛才說的同類變量iv值都很高啦����,就是這個(gè)圖,q_開頭的都是同類的變量�����,iv值基本相近����,假設(shè)說這些都進(jìn)去模型的,模型也不會(huì)全都要了�。
score5的表格是長這樣子的:

這圖可能在這里比較小,但是你單獨(dú)點(diǎn)開還是可以看的�。
score5是score4的具體每段的iv值的分布,其中m就是觀測缺失的組別����。后面的start
end這兩個(gè)變量是這個(gè)組別的區(qū)間。這里的woe值其實(shí)我不建議使用��,因?yàn)槲疫@邊的分區(qū)是全部都是等分的5份���,但是某些變量有更好的分法����,后面對于篩選出來的變量也會(huì)進(jìn)行進(jìn)一次的最優(yōu)分段再計(jì)算woe值�,這里的woe只是為計(jì)算iv,順便顯示在數(shù)據(jù)集中�����。
其實(shí)到了這里���,iv值的代碼以及iv值運(yùn)用����,我也都講完了���。但是在業(yè)務(wù)上�,還會(huì)做這樣子一個(gè)步驟���,就是對于iv值極高的變量會(huì)單獨(dú)拿出來再分析���。下面分享一個(gè)其中的一個(gè)的分析例子,這部分的工作可能不是全部公司都會(huì)做�,因?yàn)楹芎馁M(fèi)時(shí)間�����。
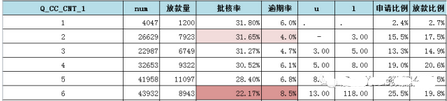
這是建模中我的一個(gè)次數(shù)變量至于代表是什么變量因?yàn)楣镜谋C苄再|(zhì)�����,所以我就不說了����。分區(qū)是計(jì)算iv值時(shí)分段出來的���。假設(shè)這個(gè)是撥打貸款公司的電話的次數(shù)���,當(dāng)他打的次數(shù)是3次以下的時(shí)候,批核率以及逾期率是比較高的���,但是當(dāng)達(dá)到13次以上的時(shí)候��,批核率不僅降了9%左右�����,而且逾期率也高了4%,那么這個(gè)變量就可以跟領(lǐng)導(dǎo)討論一下�����,將這條規(guī)則做到前端����,讓審批審核人員多了一個(gè)可以參考的條件����,當(dāng)然這個(gè)變量的體現(xiàn)可能相對于其他變量來說是很明顯的。但是真正做成規(guī)則或者說人工審批的決策還可能不能�����。具體的情況還是要看自己公司的數(shù)據(jù)��,我這里也只是分享我工作中的一個(gè)小小的經(jīng)驗(yàn)����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330