R語言-組間差異的非參數檢驗
7.5 組間差異的非參數檢驗
如果數據無法滿足t檢驗或ANOVA的參數假設,可以轉而使用非參數方法�����。舉例來說��,若結果變量在本質上就嚴重偏倚或呈現有序關系�����,那么你可能會希望使用本節(jié)中的方法���。
7.5.1 兩組的比較
若兩組數據獨立�,可以使用Wilcoxon秩和檢驗(更廣為人知的名字是Mann–Whitney U檢驗)來評估觀測是否是從相同的概率分布中抽得的(即����,在一個總體中獲得更高得分的概率是否比另一個總體要大)。調用格式為:
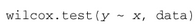
其中的y是數值型變量�����,而x是一個二分變量��。調用格式或為:

其中的y1和y2為各組的結果變量����。
可選參數data的取值為一個包含了這些變量的矩陣或數據框。
默認進行一個雙側檢驗。你可以添加參數exact來進行精確檢驗����,指定alternative="less"或alternative="greater"進行有方向的檢驗。
如果你使用Mann–Whitney U檢驗回答上一節(jié)中關于監(jiān)禁率的問題���,將得到這些結果:

你可以再次拒絕南方各州和非南方各州監(jiān)禁率相同的假設(p
<
0.001)���。Wilcoxon符號秩檢驗是非獨立樣本t檢驗的一種非參數替代方法��。它適用于兩組成對數據和無法保證正態(tài)性假設的情境��。調用格式與Mann–Whitney
U檢驗完全相同���,不過還可以添加參數paired=TRUE�����。讓我們用它解答上一節(jié)中的失業(yè)率問題:

你再次得到了與配對t檢驗相同的結論�。在本例中���,含參的t檢驗和與其作用相同的非參數檢驗得到了相同的結論�。當t檢驗的假設合理時,參數檢驗的功效更強(更容易發(fā)現存在的差異)�����。而非參數檢驗在假設非常不合理時(如對于等級有序數據)更適用�����。
7.5.2 多于兩組的比較
在要比較的組數多于兩個時��,必須轉而尋求其他方法���?���?紤]7.4節(jié)中的state.x77數據集��。它包含了美國各州的人口����、收入、文盲率�����、預期壽命、謀殺率和高中畢業(yè)率數據��。如果你想比較美國四個地區(qū)(東北部�����、南部�����、中北部和西部)的文盲率�,應該怎么做呢?這稱為單向設計(one-way design)�����,我們可以使用參數或非參數的方法來解決這個問題�����。如果無法滿足ANOVA設計的假設����,那么可以使用非參數方法來評估組間的差異�。如果各組獨立,則Kruskal—Wallis檢驗將是一種實用的方法。如果各組不獨立(如重復測量設計或隨機區(qū)組設計)�,那么Friedman檢驗會更合適。
Kruskal–Wallis檢驗的調用格式為:
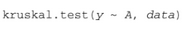
其中的y是一個數值型結果變量����, A是一個擁有兩個或更多水平的分組變量(grouping variable)。(若有兩個水平���,則它與Mann–Whitney U檢驗等價���。)而Friedman檢驗的調用格式為:
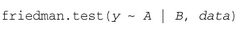
其中的y是數值型結果變量, A是一個分組變量�����, 而B是一個用以認定匹配觀測的區(qū)組變量 (blocking variable) �。在以上兩例中, data皆為可選參數�,它指定了包含這些變量的矩陣或數據框。
讓我們利用Kruskal–Wallis檢驗回答文盲率的問題��。首先����,你必須將地區(qū)的名稱添加到數據集中��。這些信息包含在隨R基礎安裝分發(fā)的state.region數據集中�。
現在就可以進行檢驗了:

顯著性檢驗的結果意味著美國四個地區(qū)的文盲率各不相同(p
<0.001)�。雖然你可以拒絕不存在差異的原假設,但這個檢驗并沒有告訴你哪些地區(qū)顯著地與其他地區(qū)不同��。要回答這個問題���,你可以使用Mann–Whitney
U檢驗每次比較兩組數據�����。一種更為優(yōu)雅的方法是在控制犯第一類錯誤的概率(發(fā)現一個事實上并不存在的差異的概率)的前提下�����,執(zhí)行可以同步進行的多組比較,這樣可以直接完成所有組之間的成對比較�����。
npmc包提供了所需要的非參數多組比較程序���。
說實話��,我將本章標題中基本的定義拓展了不止一點點���,但由于在這里講非常合適�����,所以希望你能夠容忍我的做法�。第一步����,請先安裝npmc包。此包中的npmc()函數接受的輸入為一個兩列的數據框�����,其中一列名為var(因變量)��,另一列名為class(分組變量)�。代碼清單7-20中包含了可以用來完成計算的代碼。

調用了npmc的語句生成了六對統(tǒng)計比較結果(東北部對南部�、東北部對中北部、東北部對西部�、南部對中北部、南部對西部���,以及中北部對西部)
���??梢詮碾p側的p值(p.value.2s)看出南部與其他三個地區(qū)顯著不同�����,而其他三個地區(qū)之間并沒有什么不同�����。在
處可以看到南部的文盲率中間值更高���。注意�����, npmc在計算積分時使用了隨機數��,所以每次計算的結果會有輕微的不同��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330