用交叉驗證改善模型的預測表現(xiàn)-著重k重交叉驗證
機器學習技術在應用之前使用“訓練+檢驗”的模式(通常被稱作”交叉驗證“)�����。
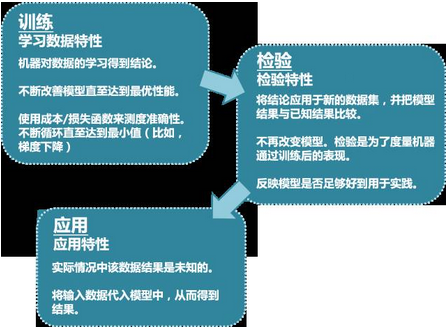
預測模型為何無法保持穩(wěn)定����?
讓我們通過以下幾幅圖來理解這個問題:
此處我們試圖找到尺寸(size)和價格(price)的關系。三個模型各自做了如下工作:
第一個模型使用了線性等式。對于訓練用的數(shù)據點����,此模型有很大誤差���。這樣的模型在初期排行榜和最終排行榜都會表現(xiàn)不好�。這是“擬合不足”(“Under fitting”)的一個例子��。此模型不足以發(fā)掘數(shù)據背后的趨勢�。
第二個模型發(fā)現(xiàn)了價格和尺寸的正確關系��,此模型誤差低/概括程度高。
第三個模型對于訓練數(shù)據幾乎是零誤差�����。這是因為此關系模型把每個數(shù)據點的偏差(包括噪聲)都納入了考慮范圍,也就是說���,這個模型太過敏感����,甚至會捕捉到只在當前數(shù)據訓練集出現(xiàn)的一些隨機模式。這是“過度擬合”(“Over fitting”)的一個例子。這個關系模型可能在初榜和終榜成績變化很大����。
在應用中��,一個常見的做法是對多個模型進行迭代�����,從中選擇表現(xiàn)更好的。然而��,最終的分數(shù)是否會有改善依然未知����,因為我們不知道這個模型是更好的發(fā)掘潛在關系了��,還是過度擬合了���。為了解答這個難題��,我們應該使用交叉驗證(cross validation)技術。它能幫我們得到更有概括性的關系模型。
實際上���,機器學習關注的是通過訓練集訓練過后的模型對測試樣本的分類效果����,我們稱之為泛化能力���。左右兩圖的泛化能力就不好。在機器學習中�����,對偏差和方差的權衡是機器學習理論著重解決的問題。
什么是交叉驗證�?
交叉驗證意味著需要保留一個樣本數(shù)據集�,不用來訓練模型�。在最終完成模型前����,用這個數(shù)據集驗證模型��。
交叉驗證包含以下步驟:
保留一個樣本數(shù)據集�����。--測試集
用剩余部分訓練模型���。--訓練集
用保留的數(shù)據集(測試集)驗證模型��。
這樣做有助于了解模型的有效性。如果當前的模型在此數(shù)據集也表現(xiàn)良好��,那就帶著你的模型繼續(xù)前進吧����!它棒極了����!
交叉驗證的常用方法是什么�����?
交叉驗證有很多方法���。下面介紹其中幾種:
1. “驗證集”法
保留 50% 的數(shù)據集用作驗證���,剩下 50% 訓練模型�����。之后用驗證集測試模型表現(xiàn)�。不過,這個方法的主要缺陷是�����,由于只使用了 50% 數(shù)據訓練模型���,原數(shù)據中一些重要的信息可能被忽略���。也就是說�,會有較大偏誤。
2. 留一法交叉驗證 ( LOOCV )
這種方法只保留一個數(shù)據點用作驗證����,用剩余的數(shù)據集訓練模型。然后對每個數(shù)據點重復這個過程���。這個方法有利有弊:
由于使用了所有數(shù)據點��,所以偏差較低����。
驗證過程重復了 n 次( n 為數(shù)據點個數(shù))��,導致執(zhí)行時間很長。
由于只使用一個數(shù)據點驗證,這個方法導致模型有效性的差異更大�����。得到的估計結果深受此點的影響���。如果這是個離群點�,會引起較大偏差����。
3.K 層交叉驗證(K- fold cross validation)
從以上兩個驗證方法中�,我們學到了:
應該使用較大比例的數(shù)據集來訓練模型�����,否則會導致失敗���,最終得到偏誤很大的模型。
驗證用的數(shù)據點�,其比例應該恰到好處。如果太少��,會導致驗證模型有效性時�,得到的結果波動較大����。
訓練和驗證過程應該重復多次(迭代)。訓練集和驗證集不能一成不變�。這樣有助于驗證模型有效性。
是否有一種方法可以兼顧這三個方面���?
答案是肯定的��!這種方法就是“ K 層交叉驗證”這種方法簡單易行���。簡要步驟如下:
把整個數(shù)據集隨機分成 K“層”
用其中 K-1 層訓練模型,然后用第K層驗證��。
記錄從每個預測結果獲得的誤差。
重復這個過程���,直到每“層”數(shù)據都作過驗證集。
記錄下的k 個誤差的平均值����,被稱為交叉驗證誤差(cross-validation error)��?�?梢员挥米龊饬磕P捅憩F(xiàn)的標準。
把整個數(shù)據集隨機分成 K“層”
對于每一份來說:
1).以該份作為測試集����,其余作為訓練集; (用其中 K-1 層訓練模型,然后用第K層驗證)
2).在訓練集上得到模型��;
3).在測試集上得到生成誤差,這樣對每一份數(shù)據都有一個預測結果�;(記錄從每個預測結果獲得的誤差)
記錄下的 k 個誤差的平均值�����,被稱為交叉驗證誤差(cross-validation error)���。可以被用做衡量模型表現(xiàn)的標準
取誤差最小的那一個模型��。
通常。此算法的缺點是計算量較大�。
當 k=10 時�,k 層交叉驗證示意圖如下:
這里一個常見的問題是:“如何確定合適的k值?”
記住���,K 值越小,偏誤越大���,所以越不推薦。另一方面�,K 值太大,所得結果會變化多端���。K 值小,則會變得像“驗證集法”�����;K 值大,則會變得像“留一法”(LOOCV)����。所以通常建議的值是k=10。
如何衡量模型的偏誤/變化程度��?
K 層交叉檢驗之后�����,我們得到 K 個不同的模型誤差估算值(e1, e2 …..ek)��。理想的情況是�����,這些誤差值相加得 0 。要計算模型的偏誤�,我們把所有這些誤差值相加���。平均值越低,模型越優(yōu)秀����。
模型表現(xiàn)變化程度的計算與之類似。取所有誤差值的標準差���,標準差越小說明模型隨訓練數(shù)據的變化越小。
我們應該試圖在偏誤和變化程度間找到一種平衡�。降低變化程度�����、控制偏誤可以達到這個目的����。這樣會得到更好的預測模型����。進行這個取舍,通常會得出復雜程度較低的預測模型�。
Python Code
from sklearn import cross_validation
model = RandomForestClassifier(n_estimators=100)
#簡單K層交叉驗證,10層�����。
cv = cross_validation.KFold(len(train), n_folds=10, indices=False)
results = []
# "Error_function" 可由你的分析所需的error function替代
for traincv, testcv in cv:
probas = model.fit(train[traincv], target[traincv]).predict_proba(train[testcv])
results.append( Error_function )
print "Results: " + str( np.array(results).mean() )
R Code
library(data.table)
library(randomForest)
data <- iris
str(data)
#交叉驗證����,使用rf預測sepal.length
k = 5
data$id <- sample(1:k, nrow(data), replace = TRUE)
list <- 1:k
# 每次迭代的預測用數(shù)據框,測試用數(shù)據框
# the folds
prediction <- data.table()
testsetCopy <- data.table()
# 寫一個進度條,用來了解CV的進度
progress.bar <- create_progress_bar("text")
progress.bar$init(k)
#k層的函數(shù)
for(i in 1:k){
# 刪除id為i的行�,創(chuàng)建訓練集
# 選id為i的行��,創(chuàng)建訓練集
trainingset <- subset(data, id %in% list[-i])
testset <- subset(data, id %in% c(i))
#運行一個隨機森林模型
mymodel <- randomForest(trainingset$Sepal.Length ~ ., data = trainingset, ntree = 100)
#去掉回應列1, Sepal.Length
temp <- as.data.frame(predict(mymodel, testset[,-1]))
# 將迭代出的預測結果添加到預測數(shù)據框的末尾
prediction <- rbind(prediction, temp)
# 將迭代出的測試集結果添加到測試集數(shù)據框的末尾
# 只保留Sepal Length一列
testsetCopy <- rbind(testsetCopy, as.data.frame(testset[,1]))
progress.bar$step()
}
# 將預測和實際值放在一起
result <- cbind(prediction, testsetCopy[, 1])
names(result) <- c("Predicted", "Actual")
result$Difference <- abs(result$Actual - result$Predicted)
# 用誤差的絕對平均值作為評估
summary(result$Difference)
CDA數(shù)據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330