SAS之DATA步運行機制
相信了解SAS軟件的朋友都知道,SAS主要由DATA步和PROC步組成,其中DATA步作為數(shù)據(jù)讀入、清洗、整理的主要程序步�����,學好DATA就顯得尤為重要��。而了解DATA步�,重中之重就得了解PDV(Logical Program Data Vector)�����。
首先
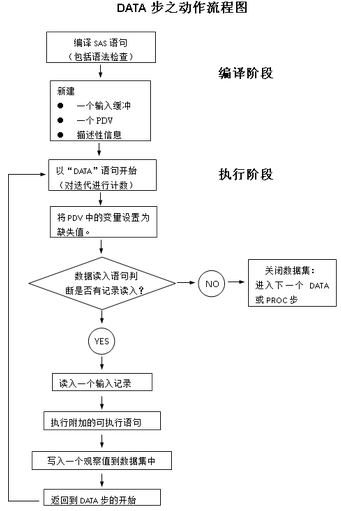
DATA步的處理分為兩個階段:
◇編譯 ◇執(zhí)行
編譯
由此可知����,PDV在DATA步的編譯階段就已存在,那在DATA步的編譯階段究竟發(fā)生了什么事呢��?
1檢查DATA步語句的語法
2創(chuàng)建一個輸入緩沖區(qū)(input buffer)
3創(chuàng)建一個程序數(shù)據(jù)向量( PDV)
4創(chuàng)建輸出數(shù)據(jù)集的描述部分(注:只創(chuàng)建描述部分�����,不賦初值)
執(zhí)行
1計算Data步迭代的次數(shù)(從Data語句開始)
2將PDV中的變量設成缺失值并初始化自動變量
3讀取輸入觀測(從原始文件或SAS數(shù)據(jù)集)
4執(zhí)行附加的處理或計算語句
5將一條數(shù)據(jù)記錄寫入輸出數(shù)據(jù)集并返回到DATA步語句
輸入緩沖區(qū):
SAS在使用input讀入外部數(shù)據(jù)之時,首先需要將外部數(shù)據(jù)讀入內存���,即輸入緩沖區(qū)�。(注:當使用set語句之時�,則無涉及到輸入緩沖區(qū)的工作。)
程序數(shù)據(jù)向量( PDV):
PDV為內存中的一個臨時邏輯區(qū)域���,SAS在建立數(shù)據(jù)集時�,先將每條觀測讀入PDV�,然后執(zhí)行一系列的語句之后����,在遇到output或run語句時,再將觀測寫入數(shù)據(jù)集(DATA
_NULL_除外)�。在PDV中,除當前變量外�,還包含兩個自動變量:_N_和_ERROR_,前者表示DATA步迭代的次數(shù)����,后者則表示此次迭代是否出錯��,若出錯則值為1��,反之為0����。除此之外�,還有END=,IN=,FIRST,LAST,POINT=等自動變量。其中END=可做set語句選項����,當讀入的觀測到達最后一行時,該值為1��;first�����、last則存在于使用by語句之時建立��,point=選項可用于選擇讀入某條觀測����,in=則是數(shù)據(jù)集選項,用于指示該觀測是否從某數(shù)據(jù)集讀入。 這些自動變量并不保存到生成的數(shù)據(jù)集中����,若需保存可將其負值給某一變量。
PDV示例:
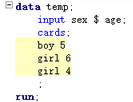
在提交此程序之后��,編譯時��,SAS建立一個讀入緩沖用以存儲原始數(shù)據(jù)��。
而后���,建立PDV及變量描述部分如下(長度默認為8)

執(zhí)行過程中���,將變量賦初值(數(shù)值型變量空值為.,字符型變量空值為空格)

然后��,讀入第一條觀測

此時DATA步會依次執(zhí)行data步中附加的語句(此程序示例中無其他執(zhí)行語句)����;直到遇到output或run語句時�����,將第一條觀測寫入temp數(shù)據(jù)集中��,后開始下一次迭代,直到所有觀測均讀入�����。數(shù)據(jù)分析師培訓
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經營許可證編號:京B2-20210330