關(guān)于如何解釋機(jī)器學(xué)習(xí)的一些方法
到現(xiàn)在你可能聽說過種種奇聞?shì)W事,比如機(jī)器學(xué)習(xí)算法通過利用大數(shù)據(jù)能夠預(yù)測(cè)某位慈善家是否會(huì)捐款給基金會(huì)啦���,預(yù)測(cè)一個(gè)在新生兒重癥病房的嬰兒是否會(huì)罹患敗血癥啦��,或者預(yù)測(cè)一位消費(fèi)者是否會(huì)點(diǎn)擊一個(gè)廣告啦����,等等。甚至于���,機(jī)器學(xué)習(xí)算法還能駕駛汽車�,以及預(yù)測(cè)大選結(jié)果�!…
呃,等等�����。它真的能嗎���?我相信它肯定可以���,但是,這些高調(diào)的論斷應(yīng)該在數(shù)據(jù)工作者(無論這些數(shù)據(jù)是否是『大』數(shù)據(jù))以及機(jī)器學(xué)習(xí)工作者心里留下些非常困難的問題:我能否理解我的數(shù)據(jù)����?我能否理解機(jī)器學(xué)習(xí)算法給予我的模型和結(jié)果��?以及����,我是否信任這些結(jié)果�?不幸的是,模型的高復(fù)雜度賜予了機(jī)器學(xué)習(xí)算法無與倫比的預(yù)測(cè)能力�����,然而也讓算法結(jié)果難以理解�,甚至還可能難以采信。
盡管�����,我們可能能夠強(qiáng)制自變量-因變量關(guān)系函數(shù)是滿足單調(diào)性約束的(譯者注:單調(diào)性的意思是�,遞增地改變自變量,只會(huì)導(dǎo)致因變量要么一直遞增����,要么一直遞減),機(jī)器學(xué)習(xí)算法一直有傾向產(chǎn)生非線性�、非單調(diào)、非多項(xiàng)式形式�����、甚至非連續(xù)的函數(shù)���,來擬合數(shù)據(jù)集中自變量和因變量之間的關(guān)系����。(這種關(guān)系也可以描述為����,基于自變量的不同取值,因變量條件分布的變化)���。這些函數(shù)可以根據(jù)新的數(shù)據(jù)點(diǎn)���,對(duì)因變量進(jìn)行預(yù)測(cè)——比如某位慈善家是否會(huì)捐款給基金會(huì),一個(gè)在新生兒重癥病房的嬰兒是否會(huì)罹患敗血癥����,一位消費(fèi)者是否會(huì)點(diǎn)擊一個(gè)廣告,諸如此類��。相反地��,傳統(tǒng)線性模型傾向于給出線性、單調(diào)�����、連續(xù)的函數(shù)用于估計(jì)這些關(guān)系��。盡管它們不總是最準(zhǔn)確的預(yù)測(cè)模型�,線性模型的優(yōu)雅、簡單使得他們預(yù)測(cè)的結(jié)果易于解釋�����。
如果說����,好的(數(shù)據(jù))科學(xué)對(duì)能夠理解、信任模型以及結(jié)果是一個(gè)一般性要求的話���,那么在諸如銀行�、保險(xiǎn)以及其他受監(jiān)管的垂直行業(yè)中��,模型的可解釋性則是重要的法律規(guī)范�����。商業(yè)分析師、醫(yī)生以及行業(yè)研究員必須理解以及信任他們自己的模型�,以及模型給出的結(jié)果?�;谶@個(gè)原因���,線性模型幾十年來都是應(yīng)用預(yù)測(cè)模型中最易于上手的工具,哪怕是放棄幾個(gè)百分點(diǎn)的精度�����。今天����,大量機(jī)構(gòu)和個(gè)人開始在預(yù)測(cè)模型任務(wù)中擁抱機(jī)器學(xué)習(xí)算法,但是『不易解釋』仍然給機(jī)器學(xué)習(xí)算法的廣泛應(yīng)用帶來了一些阻礙��。
在這篇文章中���,為了進(jìn)行數(shù)據(jù)可視化和機(jī)器學(xué)習(xí)模型/結(jié)果解釋�����,我在最常用的一些準(zhǔn)確性度量����、評(píng)估圖表以外,提供了額外的幾種方法�。我誠摯建議用戶根據(jù)自己的需要,對(duì)這些技巧進(jìn)行一些混搭����。只要有可能,在這篇文章中出現(xiàn)的每一個(gè)技巧里�����,『可解釋性』都被解構(gòu)為幾個(gè)更基本的方面:模型復(fù)雜程度���,特征尺度�,理解���,信任
—— 接下來我首先就來簡單對(duì)這幾點(diǎn)做個(gè)介紹���。
待解釋的響應(yīng)函數(shù)(譯者注:因變量關(guān)于自變量的函數(shù))的復(fù)雜程度
線性單調(diào)函數(shù):由線性回歸算法創(chuàng)建的函數(shù)可能是最容易解釋的一類模型了。這些模型被稱為『線性的�����、單調(diào)的』,這意味著任何給定的自變量的變化(有時(shí)也可能是自變量的組合�,或者自變量的函數(shù)的變化),因變量都會(huì)以常數(shù)速率向同一個(gè)方向變動(dòng)�,變動(dòng)的強(qiáng)度可以根據(jù)已知的系數(shù)表達(dá)出來。單調(diào)性也使得關(guān)于預(yù)測(cè)的直覺性推理甚至是自動(dòng)化推理成為可能�����。舉例來說����,如果一個(gè)貸款的借方拒絕了你的信用卡申請(qǐng)���,他們能夠告訴你�����,根據(jù)他們的『貸款違約概率模型』推斷�����,你的信用分?jǐn)?shù)�����、賬戶余額以及信用歷史與你對(duì)信用卡賬單的還款能力呈現(xiàn)單調(diào)相關(guān)����。當(dāng)這些解釋條文被自動(dòng)化生成的時(shí)候,它們往往被稱作『原因代碼』����。當(dāng)然,線性單調(diào)的響應(yīng)函數(shù)也能夠提供變量重要性指標(biāo)的計(jì)算����。線性單調(diào)函數(shù)在機(jī)器學(xué)習(xí)的可解釋性中有幾種應(yīng)用,在更下面的第一部分和第二部分討論中�����,我們討論了利用線性�、單調(diào)函數(shù)讓機(jī)器學(xué)習(xí)變得更為可解釋的很多種辦法。
非線性單調(diào)函數(shù):盡管大部分機(jī)器學(xué)習(xí)學(xué)到的響應(yīng)函數(shù)都是非線性的���,其中的一部分可以被約束為:對(duì)于任意給定的自變量�,都能呈現(xiàn)單調(diào)性關(guān)系�����。我們無法給出一個(gè)單一的系數(shù)來表征某個(gè)特定自變量的改變對(duì)響應(yīng)函數(shù)帶來的影響程度,不過非線性單調(diào)函數(shù)實(shí)際上能夠做到『只朝著一個(gè)方向前進(jìn)』(譯者注:前進(jìn)的速度有快有慢)�。一般來說,非線性單調(diào)的響應(yīng)函數(shù)允許同時(shí)生成『原因代碼』以及自變量的『相對(duì)重要性指標(biāo)』�����。非線性單調(diào)的響應(yīng)函數(shù)在監(jiān)管類的應(yīng)用中���,是具備高度可解釋性的���。
(當(dāng)然�����,機(jī)器學(xué)習(xí)能夠憑借多元自適應(yīng)回歸樣條方法���,建立『線性非單調(diào)』的響應(yīng)曲線���。在此我們不強(qiáng)調(diào)這些函數(shù)的原因,是因?yàn)橐环矫?��,它們的預(yù)測(cè)精度低于非線性非單調(diào)的預(yù)測(cè)模型�,另一方面,它們跟線性單調(diào)的模型比起來又缺乏解釋性����。)
非線性非單調(diào)函數(shù):大部分機(jī)器學(xué)習(xí)算法建立了非線性、非單調(diào)的響應(yīng)函數(shù)��。給定任意一個(gè)自變量�����,響應(yīng)函數(shù)可能以任何速率�����、向任何方向發(fā)生變動(dòng)���,因此這類函數(shù)最難以解釋�。一般來說��,唯一可以標(biāo)準(zhǔn)化的解釋性指標(biāo)就是變量的『相對(duì)重要性指標(biāo)』����。你可能需要組織一些本文將要展示的技術(shù)作為額外手段����,來解釋這些極端復(fù)雜的模型��。
可解釋性的特征尺度
全局可解釋性:某些下文展示的技巧���,無論是對(duì)機(jī)器學(xué)習(xí)算法��,算法得到的預(yù)測(cè)結(jié)果�����,還是算法學(xué)習(xí)到的自變量-因變量關(guān)系而言����,都能夠提供全局的可解釋性(比如條件概率模型)�����。全局可解釋性可以根據(jù)訓(xùn)練出來的響應(yīng)函數(shù)��,幫助我們理解所有的條件分布�����,不過全局可解釋性一般都是『近似』的或者是『基于平均值』的�。
局部可解釋性:局部可解釋性提高了對(duì)于小區(qū)域內(nèi)條件分布的理解,比如輸入值的聚類��,聚類類別對(duì)應(yīng)的預(yù)測(cè)值和分位點(diǎn)�,以及聚類類別對(duì)應(yīng)的輸入值記錄。因?yàn)樾【植績?nèi)的條件分布更有可能是線性的�����、單調(diào)的�,或者數(shù)據(jù)分布形式較好,因此局部可解釋性要比全局可解釋性更準(zhǔn)確���。
理解與信任
機(jī)器學(xué)習(xí)算法以及他們?cè)谟?xùn)練過程中得到的響應(yīng)函數(shù)錯(cuò)綜復(fù)雜�����,缺少透明度��。想要使用這些模型的人���,具有最基本的情感需求:理解它們,信任它們——因?yàn)槲覀円蕾囁鼈儙兔ψ龀鲋匾獩Q策��。對(duì)于某些用戶來說,在教科書���、論文中的技術(shù)性描述�,已經(jīng)為完全理解這些機(jī)器學(xué)習(xí)模型提供了足夠的洞見��。對(duì)他們而言���,交叉驗(yàn)證�、錯(cuò)誤率指標(biāo)以及評(píng)估圖表已經(jīng)提供了足以采信一個(gè)模型的信息�。不幸的是,對(duì)于很多應(yīng)用實(shí)踐者來說�,這些常見的定義與評(píng)估,并不足以提供對(duì)機(jī)器學(xué)習(xí)模型與結(jié)論的全然理解和信任��。在此����,我們提到的技巧在標(biāo)準(zhǔn)化實(shí)踐的基礎(chǔ)上更進(jìn)一步,以產(chǎn)生更大的理解和信任感�����。這些技巧要么提高了對(duì)算法原理���,以及響應(yīng)函數(shù)的洞察���,要么對(duì)模型產(chǎn)生的結(jié)果給出了更詳盡的信息。
對(duì)于機(jī)器學(xué)習(xí)算法���,算法學(xué)習(xí)到的響應(yīng)函數(shù)���,以及模型預(yù)測(cè)值的穩(wěn)定性/相關(guān)性,使用以下的技巧可以讓用戶通過觀測(cè)它們��、確認(rèn)它們來增強(qiáng)使用它們的信心����。
?
這些技巧被組織成為三部分:第一部分涵蓋了在訓(xùn)練和解釋機(jī)器學(xué)習(xí)算法中��,觀察和理解數(shù)據(jù)的方法�����;第二部分介紹了在模型可解釋性極端重要的場(chǎng)合下����,整合線性模型和機(jī)器學(xué)習(xí)模型的技巧����;第三部分描述了一些理解和驗(yàn)證那些極端復(fù)雜的預(yù)測(cè)模型的方法��。
第一部分:觀察你的數(shù)據(jù)
大部分真實(shí)的數(shù)據(jù)集都難以觀察�,因?yàn)樗鼈冇泻芏嗔凶兞浚约昂芏嘈袛?shù)據(jù)�����。就像大多數(shù)的『視覺型』人類一樣��,在理解信息這方面我大量依賴我的『視覺』感覺����。對(duì)于我來說,查看數(shù)據(jù)基本等價(jià)于了解數(shù)據(jù)�。然而,我基本上只能理解視覺上的二維或者三維數(shù)據(jù)——最好是二維�。此外,在人類看到不同頁面����、屏幕上的信息時(shí),一種被稱作『變化盲視』的效應(yīng)往往會(huì)干擾人類做出正確的推理分析����。因此�,如果一份數(shù)據(jù)集有大于兩三個(gè)變量,或者超過一頁/一屏幕數(shù)據(jù)行時(shí)�,如果沒有更先進(jìn)的技巧而是只漫無止境的翻頁的話,我們確實(shí)難以知道數(shù)據(jù)中發(fā)生了什么���。
當(dāng)然�����,我們有大量的方法對(duì)數(shù)據(jù)集進(jìn)行可視化���。接下來的強(qiáng)調(diào)的大部分技巧,是用于在二維空間中描述所有的數(shù)據(jù)����,不僅僅是數(shù)據(jù)集中的一兩列(也就是僅同時(shí)描述一兩個(gè)變量)。這在機(jī)器學(xué)習(xí)中很重要���,因?yàn)榇蟛糠?a href='/map/jiqixuexi/' style='color:#000;font-size:inherit;'>機(jī)器學(xué)習(xí)算法自動(dòng)提取變量之間的高階交互作用(意味著超過兩三種變量在一起形成的效果)��。傳統(tǒng)單變量和雙變量圖表依然很重要�,你還是需要使用它們,但他們往往和傳統(tǒng)線性模型的語境更相關(guān)�;當(dāng)眾多變量之間存在任意高階交互作用時(shí),僅靠使用傳統(tǒng)圖表就想理解這類非線性模型�����,幫助就不大了�。
圖形符號(hào)

圖1. 使用圖形符號(hào)代表操作系統(tǒng)和網(wǎng)頁瀏覽器類型。感謝Ivy Wang和H2O.ai團(tuán)隊(duì)友情提供圖片
圖形符號(hào)(Glyph)是一種用來表征數(shù)據(jù)的視覺符號(hào)�����。圖形符號(hào)的顏色���、材質(zhì)以及排列形式�,可以用來表達(dá)數(shù)據(jù)不同屬性(譯者注:即變量)的值����。在圖1中,彩色的圓圈被定義為表達(dá)不同種類的操作系統(tǒng)以及網(wǎng)絡(luò)瀏覽器�。使用特定方式對(duì)圖形符號(hào)進(jìn)行排列后,它們就可以表征數(shù)據(jù)集中的一行行數(shù)據(jù)了��。
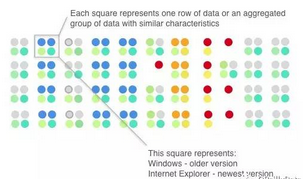
圖2. 將圖形符號(hào)進(jìn)行組織,表達(dá)數(shù)據(jù)集中的多行�。感謝Ivy Wang以及H2O.ai團(tuán)隊(duì)友情提供圖片
關(guān)于如何使用圖形符號(hào)表示一行行數(shù)據(jù),圖2在這里給出了一個(gè)例子���。每4個(gè)符號(hào)形成的小組既可以表示特定數(shù)據(jù)集中的某一行數(shù)據(jù),也可以表示其中的很多行的匯總數(shù)據(jù)����。圖形中被突出的『Windows+IE瀏覽器』這種組合在數(shù)據(jù)集中十分常見(用藍(lán)色,茶葉色�,以及綠色表示),同理『OS
X+Safari瀏覽器』這種組合也不少(上面是兩個(gè)灰色點(diǎn))�。在數(shù)據(jù)集中,這兩種組合分別構(gòu)成了兩大類數(shù)據(jù)�����。同時(shí)我們可以觀察到��,一般來說�����,操作系統(tǒng)版本有比瀏覽器版本更舊的傾向���,以及���,使用Windows的用戶更傾向用新版的操作系統(tǒng)����,使用Safari的用戶更傾向于用新版的瀏覽器�����,而Linux用戶以及網(wǎng)絡(luò)爬蟲機(jī)器人則傾向于使用舊版的操作系統(tǒng)和舊版的瀏覽器��。代表機(jī)器人的紅點(diǎn)在視覺上很有沖擊力(除非您是紅綠色盲)�����。為那些數(shù)據(jù)離群點(diǎn)(Outlier)選擇鮮明的顏色和獨(dú)特的排列�����,在圖形符號(hào)表達(dá)法中�,是標(biāo)注重要數(shù)據(jù)或異常數(shù)據(jù)值的好辦法。
相關(guān)圖
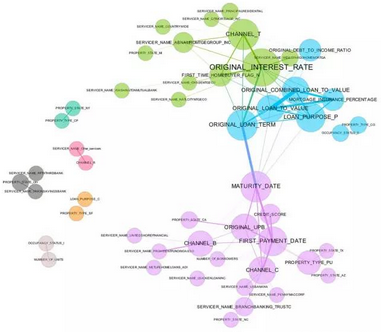
圖3. 來自一家大型金融公司����,用于表征貸款業(yè)務(wù)的相關(guān)圖���。感謝Patrick Hall和H2O.ai團(tuán)隊(duì)友情提供圖形
相關(guān)圖是體現(xiàn)數(shù)據(jù)集中數(shù)據(jù)關(guān)系(相關(guān)性)的二維表達(dá)方法。盡管在圖3中����,過多的細(xì)節(jié)實(shí)際上是可有可無的,這張圖還有一定改進(jìn)空間�����,然而就相關(guān)圖本身而言�,這一方法仍然是觀察�����、理解各變量相關(guān)性的有力工具���。利用這種技巧����,哪怕是上千個(gè)變量的數(shù)據(jù)集�����,也能畫在一張二維圖形上。
在圖3中�,圖的結(jié)點(diǎn)(node)表示某個(gè)貸款數(shù)據(jù)集中的變量,圖中的連邊(edge)的權(quán)重���,也就是線條的粗細(xì)��,是由兩兩之間皮爾遜相關(guān)系數(shù)的絕對(duì)值來定義的���。為了簡單起見,低于特定某個(gè)閾值的絕對(duì)值沒有畫出來��。結(jié)點(diǎn)的大小����,由結(jié)點(diǎn)向外連接的數(shù)目(即結(jié)點(diǎn)的度,degree)決定����。結(jié)點(diǎn)的顏色是圖的社群聚類算法給出的。結(jié)點(diǎn)所在的位置是通過力導(dǎo)向圖生成的���。相關(guān)圖使我們能夠觀察到相關(guān)變量形成的大組���,識(shí)別出孤立的非相關(guān)變量����,發(fā)現(xiàn)或者確認(rèn)重要的相關(guān)性信息以引入機(jī)器學(xué)習(xí)模型�。以上這一切,二維圖形足以搞定��。
在如圖3所展示的數(shù)據(jù)集中�,若要建立以其中某個(gè)變量為目標(biāo)的有監(jiān)督模型,我們希望使用變量選擇的技巧��,從淺綠�����、藍(lán)色����、紫色的大組里挑選一到兩個(gè)變量出來�����;我們能夠預(yù)計(jì)到����,跟目標(biāo)變量連線較粗的變量在模型中會(huì)較為重要��,以及『CHANNEL_R』這種無連線的變量在模型中重要性較低��。在圖3中也體現(xiàn)出了一些常識(shí)性的重要關(guān)系�,比如『FIRST_TIME_HOMEBUYER_FLAG_N』(是否為首次購房者)以及『ORIGINAL_INTEREST_RATE』(原始基準(zhǔn)利率)�,這種關(guān)系應(yīng)該在一個(gè)可靠的模型中有所體現(xiàn)。
2D投影

圖4. 基于著名的784維的MNIST手寫數(shù)據(jù)集制作的二維投影圖�����。左圖使用了主成分分析��,右圖使用了堆疊式消噪自編碼機(jī)����。感謝Patrick Hall和H2O.ai團(tuán)隊(duì)友情提供圖片
把來自數(shù)據(jù)集中原始高維空間的行向量映射到更容易觀察的低維空間(理想情況是2到3維),此類方法可謂多種多樣���。流行的技巧包括:
主成分分析(Principal Component Analysis�,PCA)
多維縮放(Multidimensional Scaling����,MDS)
t分布隨機(jī)近鄰嵌入(t-distributed Stochastic Neighbor Embedding,t-SNE)
自編碼機(jī)神經(jīng)網(wǎng)絡(luò)(Autoencoder Networks)
每一種方法都有它的優(yōu)點(diǎn)和弱勢(shì)�����,但他們有一個(gè)共同的主旨,就是把數(shù)據(jù)的行轉(zhuǎn)化到有意義的低維空間上��。這些數(shù)據(jù)集包括圖像���、文本�,甚至商業(yè)數(shù)據(jù)�����,它們往往具有很多難以畫在一張圖上的變量����。但這些通過找到把高維數(shù)據(jù)有效映射到低維表達(dá)的投影方法,讓古老而可靠的散點(diǎn)圖迎來了第二春�。一個(gè)散點(diǎn)圖所體現(xiàn)的高質(zhì)量映射�,應(yīng)該反映出數(shù)據(jù)集中各方面的重要結(jié)構(gòu),比如數(shù)據(jù)點(diǎn)形成的聚類�,層次結(jié)構(gòu),稀疏性�����,以及離群點(diǎn)等。
在圖4中�,著名的MNIST數(shù)據(jù)集(數(shù)字的手寫數(shù)據(jù)集)被兩種算法從原始的784維映射到了2維上:一種是主成分分析�,另一種是自編碼機(jī)神經(jīng)網(wǎng)絡(luò)。糙快猛的主成分分析能夠把標(biāo)注為0和1的這兩類數(shù)據(jù)區(qū)分的很好�,這兩種數(shù)字對(duì)應(yīng)的手寫圖像被投影在兩類較為密集的點(diǎn)簇中����,但是其他數(shù)字對(duì)應(yīng)的類普遍地發(fā)生了覆蓋�。在更精巧(然而計(jì)算上也更費(fèi)時(shí))的自編碼機(jī)映射中,每個(gè)類自成一簇���,同時(shí)長的像的數(shù)字在降維后的二維空間上也比較接近�����。這種自編碼機(jī)投影抓住了預(yù)期中的聚簇結(jié)構(gòu)以及聚簇之間的相對(duì)遠(yuǎn)近關(guān)系���。有意思的是,這兩張圖都能識(shí)別出一些離群點(diǎn)����。
投影法在用于復(fù)查機(jī)器學(xué)習(xí)建模結(jié)果時(shí),能提供一定程度上的額外『可信性』。比如說�����,如果在2維投影中能夠觀測(cè)到訓(xùn)練集/驗(yàn)證集里存在類別�����、層級(jí)信息和聚簇形態(tài)的信息���,我們也許可以確認(rèn)一個(gè)機(jī)器學(xué)習(xí)算法是否正確的把它們識(shí)別出來�。其次�����,相似的點(diǎn)會(huì)投影到相近的位置���,不相似的點(diǎn)會(huì)投影到較遠(yuǎn)的位置�,這些都是可以加以確認(rèn)的����。我們考察一下用于做市場(chǎng)細(xì)分的分類或者聚類的模型:我們預(yù)計(jì)機(jī)器學(xué)習(xí)模型會(huì)把老年有錢客戶和年輕且不那么富裕的客戶放在不同的組里,并且它們?cè)诮?jīng)過映射后�����,分別屬于完全分離的兩大組稠密的點(diǎn)簇��。哪怕訓(xùn)練集��、驗(yàn)證集中存在一些擾動(dòng)�,這種結(jié)果也應(yīng)該是穩(wěn)定的,而且對(duì)有擾動(dòng)/無擾動(dòng)兩組樣本分別進(jìn)行映射�,可以考察模型的穩(wěn)定性,或者考察模型是否表現(xiàn)出潛在的隨時(shí)間變化的模式���。
偏相關(guān)圖
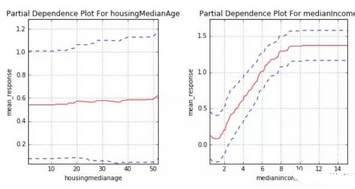
圖5. 在著名的加州房產(chǎn)數(shù)據(jù)集上建立GBDT集成模型后得到的一維偏相關(guān)圖����。感謝Patrick Hall和H2O.ai團(tuán)隊(duì)友情提供圖片
當(dāng)我們只關(guān)心一兩個(gè)自變量取值發(fā)生變化����,而其他自變量都處于平均水準(zhǔn)對(duì)機(jī)器學(xué)習(xí)模型響應(yīng)函數(shù)所造成的影響時(shí),偏相關(guān)圖可以為我們展現(xiàn)這種關(guān)系�。在我們感興趣的自變量存在較為復(fù)雜的交互作用時(shí),用雙自變量偏相關(guān)圖進(jìn)行可視化顯得尤為有效�����。當(dāng)存在單調(diào)性約束時(shí),偏相關(guān)圖可以用于確認(rèn)響應(yīng)函數(shù)對(duì)于自變量的單調(diào)性��;在極端復(fù)雜的模型里�,它也可以用于觀察非線性性、非單調(diào)性����、二階交叉效應(yīng)。如果它顯示的二元變量關(guān)系與領(lǐng)域知識(shí)相符���,或者它隨時(shí)間遷移呈現(xiàn)出可預(yù)計(jì)的變化模式或者穩(wěn)定性���,或者它對(duì)輸入數(shù)據(jù)的輕微擾動(dòng)呈現(xiàn)不敏感,此時(shí)我們對(duì)模型的信心都會(huì)有所提高�。
偏相關(guān)圖對(duì)于數(shù)據(jù)集的不同數(shù)據(jù)行而言,是全局性的����;但對(duì)數(shù)據(jù)的不同列,也就是不同自變量而言���,是局部性的����。僅當(dāng)我們需要考察1-2個(gè)自變量和因變量的關(guān)系時(shí)我們才能使用這種圖。一種較新���,不太為人所知的偏相關(guān)圖的改進(jìn)版本,稱為『個(gè)體條件期望圖』(Individual conditional expectation����,ICE),它使用類似偏相關(guān)圖的思想���,能夠給出對(duì)數(shù)據(jù)更局部性的解釋��。在多個(gè)自變量存在較強(qiáng)的相關(guān)關(guān)系時(shí)��,ICE圖顯得尤其好用�����。
殘差分析
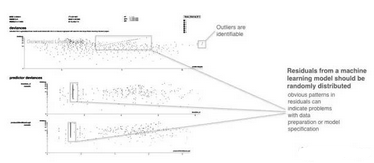
圖6. 一個(gè)來自殘差分析應(yīng)用的截圖�。感謝Micah Stubbs和H2O.ai團(tuán)隊(duì)友情提供的截圖
『殘差』�����,是指數(shù)據(jù)集每一行中��,因變量的測(cè)量值和預(yù)測(cè)值之差。一般來說���,在擬合得不錯(cuò)的模型中���,殘差應(yīng)該呈現(xiàn)出隨機(jī)分布,因?yàn)橐粋€(gè)好的模型�����,會(huì)描述數(shù)據(jù)集中除了隨機(jī)誤差以外的絕大部分重要現(xiàn)象����。繪制『殘差-預(yù)測(cè)值』這種評(píng)估手段,是一種用二維圖形檢查模型結(jié)果的好辦法�,飽經(jīng)時(shí)間考驗(yàn)。如果在殘差圖中觀測(cè)到了很強(qiáng)的相關(guān)性模式��,這不啻為一種死亡訊息:要么你的數(shù)據(jù)有問題�,要么你的模型有問題——要么兩者都有問題!反之����,如果模型產(chǎn)生了隨機(jī)分布的殘差,那這就是一種強(qiáng)烈的信號(hào):你的模型擬合較好���,可靠����,可信;如果其他擬合指標(biāo)的值也合理(比如�����,R^2���,AUC等指標(biāo)),那就更加如此了��。
在圖6中�,方框指出了殘差中具有很強(qiáng)線性模式的部分。這里不僅有傳統(tǒng)的『預(yù)測(cè)值-殘差圖』�,也有特定自變量跟殘差形成的二維散點(diǎn)圖。把殘差跟不同自變量畫在一起���,可以提供更細(xì)粒度的信息����,以便于推理出到底什么原因?qū)е铝朔请S機(jī)模式的產(chǎn)生���。殘差圖對(duì)識(shí)別離群點(diǎn)也有幫助�����,圖6就指出了離群點(diǎn)�。很多機(jī)器學(xué)習(xí)算法都使徒最小化誤差平方和,這些高殘差的點(diǎn)對(duì)大部分模型都會(huì)帶來較強(qiáng)的影響���,通過人工分析判斷這些離群點(diǎn)的真實(shí)性可以較大的提高模型精度。
現(xiàn)在我們已經(jīng)展現(xiàn)了幾種數(shù)據(jù)可視化的技巧�,我們通過提幾個(gè)簡單問題,來回顧以下幾個(gè)大概念:尺度��,復(fù)雜性��,對(duì)數(shù)據(jù)的理解�,以及模型的可信性��。我們也會(huì)對(duì)后面的章節(jié)中出現(xiàn)的技術(shù)提出相同的問題�����。
數(shù)據(jù)可視化提供的可解釋性,是局部性的還是全局性的��?
都有��。大部分數(shù)據(jù)可視化技術(shù)��,要么用于對(duì)整個(gè)數(shù)據(jù)集進(jìn)行粗糙的觀測(cè)�,要么用于對(duì)局部數(shù)據(jù)提供細(xì)粒度檢查��。理想情況家,高級(jí)可視化工具箱能夠讓用戶容易地縮放圖形或者向下鉆取數(shù)據(jù)���。如若不然���,用戶還可以自己用不同尺度對(duì)數(shù)據(jù)集的多個(gè)局部進(jìn)行可視化。
數(shù)據(jù)可視化能夠幫助我們理解什么復(fù)雜級(jí)別的響應(yīng)函數(shù)�����?
數(shù)據(jù)可視化可以幫我們解釋各種復(fù)雜程度的函數(shù)��。
數(shù)據(jù)可視化如何幫我們提高對(duì)數(shù)據(jù)的理解�?
對(duì)大部分人而言����,數(shù)據(jù)結(jié)構(gòu)(聚簇����,層級(jí)結(jié)構(gòu),稀疏性���,離群點(diǎn))以及數(shù)據(jù)關(guān)系(相關(guān)性)的可視化表達(dá)比單純?yōu)g覽一行行數(shù)據(jù)并觀察變量的取值要容易理解��。
數(shù)據(jù)可視化如何提高模型的可信程度�����?
對(duì)數(shù)據(jù)集中呈現(xiàn)的結(jié)構(gòu)和相關(guān)性進(jìn)行觀察����,會(huì)讓它們易于理解�����。一個(gè)準(zhǔn)確的機(jī)器學(xué)習(xí)模型給出的預(yù)測(cè)��,應(yīng)當(dāng)能夠反映出數(shù)據(jù)集中所體現(xiàn)的結(jié)構(gòu)和相關(guān)性。要明確一個(gè)模型給出的預(yù)測(cè)是否可信�����,對(duì)這些結(jié)構(gòu)和相關(guān)性進(jìn)行理解是首當(dāng)其沖的��。
在特定情況下�,數(shù)據(jù)可視化能展現(xiàn)敏感性分析的結(jié)果,這種分析是另一種提高機(jī)器學(xué)習(xí)結(jié)果可信度的方法����。一般來說,為了檢查你的線上應(yīng)用能否通過穩(wěn)定性測(cè)試或者極端情況測(cè)試���,會(huì)通過使用數(shù)據(jù)可視化技術(shù)�����,展現(xiàn)數(shù)據(jù)和模型隨時(shí)間的變化,或者展現(xiàn)故意篡改數(shù)據(jù)后的結(jié)果�����。有時(shí)這一技術(shù)本身即被認(rèn)為是一種敏感性分析��。
第二部分:在受監(jiān)管的行業(yè)使用機(jī)器學(xué)習(xí)
對(duì)于在受監(jiān)管行業(yè)中工作的分析師和數(shù)據(jù)科學(xué)家來說,盡管機(jī)器學(xué)習(xí)可能會(huì)帶來『能極大提高預(yù)測(cè)精度』這一好處��,然而它可能不足以彌補(bǔ)內(nèi)部文檔需求以及外部監(jiān)管責(zé)任所帶來的成本��。對(duì)于實(shí)踐者而言����,傳統(tǒng)線性模型技術(shù)可能是預(yù)測(cè)模型中的唯一選擇。然而���,創(chuàng)新和競(jìng)爭(zhēng)的驅(qū)動(dòng)力并不因?yàn)槟阍谝粋€(gè)受監(jiān)管的模式下工作就會(huì)止息�����。在銀行�,保險(xiǎn)以及類似受監(jiān)管垂直領(lǐng)域里�����,數(shù)據(jù)科學(xué)家和分析師正面對(duì)著這樣一個(gè)獨(dú)一無二的難題:他們必須要找到使預(yù)測(cè)越來越精準(zhǔn)的方案�����,但前提是�,保證這些模型和建模過程仍然還是透明�、可解釋的�。
在這一節(jié)中所展現(xiàn)的技巧,有些使用了新型的線性模型�����,有些則是對(duì)傳統(tǒng)線性模型做出改進(jìn)所得到的方法���。對(duì)于線性模型進(jìn)行解釋的技巧是高度精妙的���,往往是有一個(gè)模型就有一種解釋,而且線性模型進(jìn)行統(tǒng)計(jì)推斷的特性和威力是其他類型的模型難以企及的�����。對(duì)于那些對(duì)機(jī)器學(xué)習(xí)算法的可解釋性心存疑慮而不能使用它們的實(shí)踐者�,本節(jié)中的技巧正適合他們。這些模型產(chǎn)生了線性�、單調(diào)的響應(yīng)函數(shù)(至少也是單調(diào)的!)���,和傳統(tǒng)線性模型一樣能保證結(jié)果是全局可解釋的,但通過機(jī)器學(xué)習(xí)算法獲得了預(yù)測(cè)精度的提高�。
普通最小二乘(Ordinary Least Square,OLS)回歸的替代品
受懲罰的回歸(Penalized Regression)
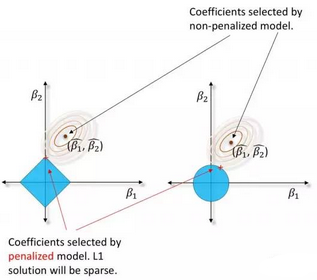
圖7. 左圖:經(jīng)過L1/LASSO懲罰的回歸系數(shù)處于縮小可行域中。右圖:經(jīng)過L2/嶺回歸懲罰的回歸系數(shù)�。感謝Patrick Hall, Tomas Nykodym以及H2O.ai團(tuán)隊(duì)友情提供圖片
普通最小二乘法(Ordinary least squares,OLS)回歸有著200年的歷史�����。也許我們是時(shí)候該向前發(fā)展一點(diǎn)了��?作為一個(gè)替代品��,帶懲罰項(xiàng)的回歸技術(shù)也許是通往機(jī)器學(xué)習(xí)之路上輕松的一課?��,F(xiàn)在���,帶懲罰項(xiàng)的回歸技術(shù)常常混合使用兩種混合:為了做變量選擇所使用的L1/LASSO懲罰��,以及為了保證模型穩(wěn)健性的Tikhonov/L2/ridge(嶺回歸)懲罰�。這種混合被稱為elastic net。相比OLS回歸����,它們對(duì)于數(shù)據(jù)所作出的假設(shè)更少。不同于傳統(tǒng)模型直接解方程���,或者使用假設(shè)檢驗(yàn)來做變量選擇���,帶懲罰項(xiàng)的回歸通過最小化帶約束的目標(biāo)函數(shù),來找到給定數(shù)據(jù)集中的一組最優(yōu)回歸系數(shù)��。一般而言����,這就是一組表征線性關(guān)系的參數(shù),但是針對(duì)『給共線性或者無意義自變量以較大的回歸系數(shù)』這一點(diǎn)���,模型可以加以一定的懲罰�����。你可以在統(tǒng)計(jì)學(xué)習(xí)基礎(chǔ)(Elements of Statistical Learning, ESL)一書中學(xué)到關(guān)于帶懲罰項(xiàng)回歸的方方面面,但是在此��,我們的目的只是要強(qiáng)調(diào)一下,你很可能需要嘗試一下『帶懲罰項(xiàng)的回歸』這一模型���。
帶懲罰項(xiàng)的回歸被廣泛地應(yīng)用于不少研究領(lǐng)域���,但是對(duì)于具有很多列�,列數(shù)大于行數(shù)�����,列中存在大量多重共線性的商業(yè)業(yè)務(wù)數(shù)據(jù)集�����,它們?nèi)匀贿m用����。L1/LASSO懲罰把無足輕重的回歸系數(shù)拉回到0���,能夠選取一小部分有代表性的變量進(jìn)行回歸系數(shù)估計(jì)����,供線性模型使用����,從而規(guī)避了那些靠前向�、后向���、逐步變量選擇法(forward,
backward, stepwise variable
selection)所帶來的多模型比較困難的問題��。Tikholov/L2/嶺回歸(ridge)
懲罰可以增加模型參數(shù)的穩(wěn)定性���,甚至在變量數(shù)目過多、多重共線性較強(qiáng)����、重要的預(yù)測(cè)變量與其他變量存在相關(guān)性時(shí)也能保持穩(wěn)定。我們需要知道的重點(diǎn)是:懲罰項(xiàng)回歸并非總能為回歸系數(shù)給出置信區(qū)間�,t-檢驗(yàn)值或者p-value(譯者注:t-檢驗(yàn)值和p-value都是檢查模型顯著有效性的統(tǒng)計(jì)量)。這些統(tǒng)計(jì)量往往只能通過額外花時(shí)間進(jìn)行迭代計(jì)算��,或者自助采樣法(bootstrapping)才能得到�。
廣義加性模型(Generalized Additive Models, GAMs)

圖8. 使用廣義加性模型對(duì)多個(gè)自變量建立樣條函數(shù)。感謝Patrick Hall以及H2O.ai團(tuán)隊(duì)友情提供圖表
廣義加性模型能夠通過對(duì)一部分變量進(jìn)行標(biāo)準(zhǔn)線性回歸�,對(duì)另一部分變量進(jìn)行非線性樣條函數(shù)的擬合的方式,手動(dòng)調(diào)整模型����,讓你在遞增的模型精度和遞減的模型可解釋性之間找到一個(gè)權(quán)衡。同時(shí),大部分GAM能夠方便地為擬合好的樣條函數(shù)生成圖形���。根據(jù)你所承受的外部監(jiān)管或者內(nèi)部文檔要求的不同����,你也許可以在模型中直接使用這些樣條函數(shù)來讓模型預(yù)測(cè)的更準(zhǔn)確���。如果不能直接使用的話,你可以用肉眼觀測(cè)出擬合出的樣條函數(shù)����,然后用更具可解釋性的多項(xiàng)式函數(shù)、對(duì)數(shù)函數(shù)�����、三角函數(shù)或者其他簡單的函數(shù)應(yīng)用于預(yù)測(cè)變量之上���,這樣也能讓預(yù)測(cè)精度提高���。同時(shí),你也可以靠查閱《統(tǒng)計(jì)學(xué)習(xí)基礎(chǔ)》(Elements
of Statistical Learning)加深對(duì)GAM的理解��。
分位數(shù)回歸
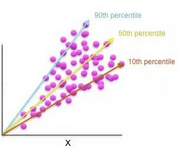
圖9. 將分位數(shù)回歸繪制為二維圖表�����。感謝Patrick Hall以及H2O.ai團(tuán)隊(duì)友情提供圖表
分位數(shù)回歸讓你能夠使用傳統(tǒng)可解釋的線性模型對(duì)訓(xùn)練數(shù)據(jù)的分位點(diǎn)進(jìn)行回歸。這種回歸允許你對(duì)不同的消費(fèi)者市場(chǎng)細(xì)分或者不同賬戶投資組合行為細(xì)分��,建立不同的模型���,你可以使用不同的預(yù)測(cè)變量����,也可以在模型中給予預(yù)測(cè)變量不同的回歸系數(shù)�����。對(duì)低價(jià)值客戶和高價(jià)值客戶使用完全不同的兩套預(yù)測(cè)變量和回歸系數(shù)聽上去還算合理����,分位數(shù)回歸對(duì)這種做法提供了一套理論框架。
回歸的這些替代品提供的是全局性的還是局部性的可解釋性�?
回歸的替代品往往能夠提供全局可解釋的函數(shù),這些函數(shù)是線性的�、單調(diào)的,根據(jù)其回歸系數(shù)的大小以及其他傳統(tǒng)回歸的評(píng)估量����、統(tǒng)計(jì)量�����,具備可解釋性�。
作為回歸的替代品���,這些回歸函數(shù)的復(fù)雜程度如何?
這些回歸函數(shù)一般來說是線性的�����、單調(diào)的函數(shù)����。不過,使用GAM可能導(dǎo)致相當(dāng)復(fù)雜的非線性響應(yīng)函數(shù)�。
這些技術(shù)如何幫我們提高對(duì)模型的理解?
比較少的模型假設(shè)意味著比較少的負(fù)擔(dān)���,可以不使用可能帶來麻煩的多元統(tǒng)計(jì)顯著性檢驗(yàn)而進(jìn)行變量選擇����,可以處理存在多重共線性的重要變量,可以擬合非線性的數(shù)據(jù)模式��,以及可以擬合數(shù)據(jù)條件分布的不同分位點(diǎn)(這可不止是擬合條件分布)��,這些特性都可能讓我們更準(zhǔn)確的理解模型所表征的現(xiàn)象���。
回歸函數(shù)的這些替代品如何提高模型的可信度��?
基本上���,這些技巧都是值得信任的線性模型,只是使用它們的方式比較新奇��。如果在你的線上應(yīng)用中這些技巧帶來了更精確的預(yù)測(cè)結(jié)果�,那么我們就可以更加信任它們。
為機(jī)器學(xué)習(xí)模型建立基準(zhǔn)測(cè)試模型

圖10. 考慮交叉效應(yīng)的線性模型與機(jī)器學(xué)習(xí)模型比較���,并繪制評(píng)估圖��。感謝Patrick Hall以及H2O.ai團(tuán)隊(duì)提供圖表
機(jī)器學(xué)習(xí)算法和傳統(tǒng)線性模型的兩個(gè)主要區(qū)別���,一個(gè)是機(jī)器學(xué)習(xí)算法在預(yù)測(cè)時(shí)引入了很多變量的高階交叉作用,并不直觀�,另一個(gè)是機(jī)器學(xué)習(xí)算法會(huì)產(chǎn)生非線性�、非多項(xiàng)式���、非單調(diào)甚至非連續(xù)的響應(yīng)函數(shù)��。
如果一個(gè)機(jī)器學(xué)習(xí)算法的預(yù)測(cè)表現(xiàn)碾壓了傳統(tǒng)線性模型��,我們可以對(duì)自變量和目標(biāo)變量建立一磕決策樹��。在決策樹相鄰層的分叉所使用的變量�����,一般來說會(huì)有強(qiáng)交叉效應(yīng)。我們可以試著把這些變量的交叉效應(yīng)加入到線性模型中�,甚至樹的連續(xù)幾層所涉及到變量的高階交叉效應(yīng)也可以加入進(jìn)來。如果一個(gè)機(jī)器學(xué)習(xí)算法較大地超越了傳統(tǒng)線性模型����,我們可以考慮把數(shù)據(jù)建模為分段線性的模型。為了要觀察機(jī)器學(xué)習(xí)學(xué)到的響應(yīng)函數(shù)如何受到一個(gè)變量各種取值的影響����,或者要獲得一些如何使用分段線性模型的洞見,可以使用GAM以及偏相關(guān)圖����?��!憾嘧兞孔赃m應(yīng)回歸樣條法』,是一種可以自動(dòng)發(fā)現(xiàn)條件分布中存在的復(fù)雜非線性部分��,并對(duì)其不同區(qū)域分別進(jìn)行擬合的統(tǒng)計(jì)手段����。你可以嘗試著直接使用多變量自適應(yīng)回歸樣條法,對(duì)分段模型進(jìn)行擬合���。
面向機(jī)器學(xué)習(xí)模型的基準(zhǔn)測(cè)試模型能提供全局性還是局部性的可解釋性���?
如果線性性和單調(diào)性能夠得以保留,建模過程就會(huì)產(chǎn)生全局可解釋的線性單調(diào)響應(yīng)函數(shù)�����。如果使用分段函數(shù)����,對(duì)機(jī)器學(xué)習(xí)模型建立基準(zhǔn)測(cè)試可以放棄全局解釋性,轉(zhuǎn)而尋求局部可解釋性��。
面向機(jī)器學(xué)習(xí)模型的基準(zhǔn)測(cè)試模型能夠生成什么復(fù)雜度的響應(yīng)函數(shù)?
如果謹(jǐn)慎��、克制的建立面向機(jī)器學(xué)習(xí)模型的基準(zhǔn)測(cè)試模型�,并加以驗(yàn)證,對(duì)機(jī)器學(xué)習(xí)模型建立的基準(zhǔn)模型可以維持像傳統(tǒng)線性模型那樣的線性性和單調(diào)性��。然而�����,如果加入了太多的交叉效應(yīng)���,或者是在分段函數(shù)中加入了太多小段��,將會(huì)導(dǎo)致響應(yīng)函數(shù)依然極端復(fù)雜����。
面向機(jī)器學(xué)習(xí)模型的基準(zhǔn)測(cè)試模型如何提升我們對(duì)模型的理解����?
這種流程把傳統(tǒng)��、可信的模型用出了新花樣����。如果使用類似GAM��,偏相關(guān)圖����,多元自適應(yīng)回歸樣條法這些技巧進(jìn)行更進(jìn)一步的數(shù)據(jù)探索�����,對(duì)機(jī)器學(xué)習(xí)模型建立相似的基準(zhǔn)測(cè)試模型�����,可以讓模型的可理解性大大提高��,對(duì)數(shù)據(jù)集中出現(xiàn)的交叉效應(yīng)以及非線性模式的理解也會(huì)加深�����。
面向機(jī)器學(xué)習(xí)模型的基準(zhǔn)測(cè)試模型如何提高模型的可信度����?
這種流程把傳統(tǒng)、可信的模型用出了新花樣�。如果使用類似GAM�����,偏相關(guān)圖��,多元自適應(yīng)回歸樣條法這些技巧進(jìn)行更進(jìn)一步的數(shù)據(jù)探索����,通過建立面向機(jī)器學(xué)習(xí)模型的基準(zhǔn)測(cè)試模型���,能夠讓這些模型更準(zhǔn)確地表達(dá)出數(shù)據(jù)集中我們感興趣的那部分模式���,從而提高我們對(duì)模型的信任程度。
在傳統(tǒng)分析流程中使用機(jī)器學(xué)習(xí)
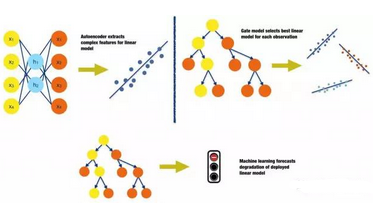
圖11. 在傳統(tǒng)分析流程中�,使用機(jī)器學(xué)習(xí)的幾種可能的方式,以圖形呈現(xiàn)�����。感謝Vinod Iyengar以及H2O.ai團(tuán)隊(duì)友情提供圖形
相較于直接使用機(jī)器學(xué)習(xí)的預(yù)測(cè)來做分析決策����,我們可以通過一些機(jī)器學(xué)習(xí)的技術(shù)�,對(duì)傳統(tǒng)分析的生命周期流程(比如數(shù)據(jù)準(zhǔn)備加模型部署)進(jìn)行一些增強(qiáng)�����,從而有潛力達(dá)到比滿足監(jiān)管的線性�����、單調(diào)性的模型精度更高的預(yù)測(cè)��。圖11簡要描述了三種可能的場(chǎng)合��,在這些場(chǎng)合中��,傳統(tǒng)分析流程靠著機(jī)器學(xué)習(xí)的加持得以增強(qiáng)效果:
在傳統(tǒng)的線性模型中�,加入(加工過的)復(fù)雜自變量:
把交叉效應(yīng)���、多項(xiàng)式函數(shù)或者把變量經(jīng)過簡單函數(shù)的映射加入到線性模型中算得上是標(biāo)準(zhǔn)做法了�����。機(jī)器學(xué)習(xí)模型可以產(chǎn)生各種各樣非線性�����、非多項(xiàng)式的自變量�,甚至還能表征原有自變量之間存在的高階交叉效應(yīng)。產(chǎn)生這些自變量的方法有不少選擇����。例如,從自編碼機(jī)神經(jīng)網(wǎng)絡(luò)中提取非線性特征���,或者從決策樹的葉子節(jié)點(diǎn)中獲得最優(yōu)化分箱��。
使用多個(gè)帶門限的線性模型:
根據(jù)重要的數(shù)據(jù)屬性�,或者根據(jù)不同的時(shí)間段對(duì)數(shù)據(jù)分成小組����,再對(duì)每一個(gè)小組分別建模,可以獲得更準(zhǔn)確的模型��。對(duì)于一個(gè)企業(yè)而言���,同時(shí)部署多個(gè)線性模型來處理不同的細(xì)分市場(chǎng)數(shù)據(jù)��,或者處理不同年份的數(shù)據(jù)���,這類情況也并非少見。要決定如何手動(dòng)融合這些不同的模型,對(duì)于數(shù)據(jù)分析師和數(shù)據(jù)科學(xué)家而言是個(gè)瑣碎的活計(jì)����。不過���,如果關(guān)于歷史模型表現(xiàn)的數(shù)據(jù)也能收集起來的話�,這個(gè)流程就可以實(shí)現(xiàn)自動(dòng)化:建立一個(gè)門限模型���,讓它來決定在遇到觀測(cè)點(diǎn)時(shí)���,究竟使用哪個(gè)線性模型來對(duì)它進(jìn)行預(yù)測(cè)。
預(yù)測(cè)線性模型的退化行為:
在大部分情況下����,模型是根據(jù)靜態(tài)數(shù)據(jù)快照建立的,它們會(huì)在后來的數(shù)據(jù)快照上進(jìn)行驗(yàn)證�����。盡管這是一種被廣泛采納的實(shí)踐方式����,但是當(dāng)訓(xùn)練集、驗(yàn)證集數(shù)據(jù)所代表的真實(shí)世界中的數(shù)據(jù)模式發(fā)生變化時(shí),這樣做會(huì)導(dǎo)致模型發(fā)生退化����。當(dāng)市場(chǎng)中的競(jìng)爭(zhēng)者進(jìn)入或者退出,當(dāng)宏觀經(jīng)濟(jì)指標(biāo)發(fā)生變動(dòng)�����,當(dāng)客戶追逐的潮流發(fā)生了改變��,或者其他各種因素發(fā)生時(shí)�����,都可能引起這種退化���。如果關(guān)于市場(chǎng)���、經(jīng)濟(jì)指標(biāo)和舊模型表現(xiàn)的數(shù)據(jù)能夠被上收上來,我們就可以基于此數(shù)據(jù)另外建立一個(gè)模型���,來預(yù)估我們所部署的傳統(tǒng)模型大概多久需要重新訓(xùn)練一次(譯者注:僅調(diào)整模型參數(shù))�,或者多久需要被全新的模型(譯者注:模型結(jié)構(gòu)發(fā)生了改變)所替代���。就像在需要保養(yǎng)之前就替換掉一個(gè)昂貴的機(jī)械部件一樣,我們也可以在模型的預(yù)測(cè)效力降低之前就進(jìn)行重新訓(xùn)練�,或者以新模型取而代之��。(我之前寫過一遍文章是有關(guān)應(yīng)用機(jī)器學(xué)習(xí)時(shí)導(dǎo)致的驗(yàn)證誤差�,以及如何正確地在真實(shí)世界中使用機(jī)器學(xué)習(xí)的��。)
當(dāng)然,還有很多在傳統(tǒng)模型的生命周期中引入機(jī)器學(xué)習(xí)技巧的機(jī)會(huì)��。你可能現(xiàn)在就已經(jīng)有更好的想法和實(shí)踐了���!
在傳統(tǒng)分析流程中使用機(jī)器學(xué)習(xí)�����,能提供全局性還是局部性的可解釋性?
一般來說����,這種方法致力于保持傳統(tǒng)線性模型所具有的全局可解釋性。然而�,在線性模型中加入機(jī)器學(xué)習(xí)算法所生成的特征,會(huì)降低全局可解釋性��。
在傳統(tǒng)分析流程中使用機(jī)器學(xué)習(xí)��,能產(chǎn)生何種復(fù)雜程度的響應(yīng)函數(shù)?
我們的目標(biāo)仍然是繼續(xù)使用線性����、單調(diào)性的響應(yīng)函數(shù)����,不過是以一種更加有效���、更加自動(dòng)化的方式來實(shí)現(xiàn)這一目的�����。
在傳統(tǒng)分析流程中使用機(jī)器學(xué)習(xí),如何幫助我們更好的理解數(shù)據(jù)��?
在傳統(tǒng)分析流程中引入機(jī)器學(xué)習(xí)模型的目的�,是為了更有效、更準(zhǔn)確地使用線性����、可解釋的模型�。究竟是什么驅(qū)動(dòng)力導(dǎo)致了數(shù)據(jù)表現(xiàn)出非線性、時(shí)間趨勢(shì)�����、模式遷移���?如果在線性模型中引入非線性項(xiàng)���,使用門限模型�,或者預(yù)測(cè)模型失效等等手段能夠讓你更深入地掌握這種知識(shí)的話��,那么對(duì)數(shù)據(jù)的理解自然就加深了。
在傳統(tǒng)分析流程中使用機(jī)器學(xué)習(xí)�,如何讓我們更加信任模型?
這種手段使我們可以理解的模型更加精確����。如果對(duì)特征的增加確實(shí)導(dǎo)致了精度提升,這就暗示著數(shù)據(jù)中的關(guān)聯(lián)現(xiàn)象確實(shí)以一種更可靠的形式被建模���。
對(duì)可解釋的模型進(jìn)行小型的模型集成(ensemble)
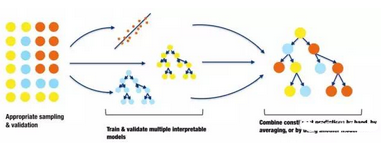
圖12. 一個(gè)小型�、堆疊的集成算法圖����。感謝Vinod Iyengar以及H2O.ai團(tuán)隊(duì)友情提供圖形
很多企業(yè)如此擅長使用傳統(tǒng)的線性模型建模技巧��,以至于他們幾乎無法再對(duì)單獨(dú)某一個(gè)模型壓榨出更高的精度��。一種在不太損失可解釋性的條件下提高精度的可能辦法是���,把數(shù)個(gè)已經(jīng)理解透徹的模型組合起來進(jìn)行預(yù)測(cè)。最終預(yù)測(cè)結(jié)果可以是對(duì)這些結(jié)果簡單取平均���,手動(dòng)對(duì)它們進(jìn)行加權(quán)�,或者用更復(fù)雜的數(shù)學(xué)方式組合起來��。舉例說明�,針對(duì)某種特定用途,總體表現(xiàn)最好的模型���,可以和那些處理極端情況特別好的模型組合起來�����。對(duì)一名數(shù)據(jù)分析師或者數(shù)據(jù)科學(xué)家而言,他們可以通過實(shí)驗(yàn)來決定為對(duì)每一個(gè)模型選取最優(yōu)加權(quán)系數(shù)進(jìn)行簡單集成���;為了保證模型的輸入和預(yù)測(cè)仍然滿足單調(diào)性關(guān)系����,可以使用偏相關(guān)圖進(jìn)行確認(rèn)。
如果你傾向于�����,或者需要使用一種更嚴(yán)格的方式來整合模型的預(yù)測(cè)��,那么『超級(jí)學(xué)習(xí)器(super learners)』是一個(gè)很棒的選擇��。在上世紀(jì)90年代早期���,Wolpert介紹了『堆疊泛化法』(stacked generalization)��,超級(jí)學(xué)習(xí)器是它的某種實(shí)現(xiàn)�����。堆疊泛化法使用了一種組合模型來為集成模型中的每個(gè)小部分賦予權(quán)重。在堆砌模型時(shí)��,過擬合是個(gè)很嚴(yán)重的問題�����。超級(jí)學(xué)習(xí)器要求使用交叉驗(yàn)證����,并對(duì)集成模型中各個(gè)部分的權(quán)重加上約束項(xiàng),通過這種方法來控制過擬合�,增加可解釋性。圖12的圖示表明���,兩個(gè)決策樹模型和一個(gè)線性回歸模型分別交叉驗(yàn)證�����,并且通過另外一個(gè)決策樹模型把它們堆疊在一起���。
可解釋模型的小型集成提供了局部性還是全局性的可解釋性?
這種集成可以增加精度��,但是它會(huì)降低全局可解釋性��。這種集成并不影響其中的每一個(gè)小模型,但是集成在一起的模型會(huì)難以解釋。
可解釋模型的小型集成產(chǎn)生了何種復(fù)雜程度的響應(yīng)函數(shù)�����?
它們會(huì)導(dǎo)致很復(fù)雜的響應(yīng)函數(shù)�����。為了確?���?山忉屝?���,使用盡可能少的模型進(jìn)行集成,使用模型的簡單線性組合�,以及使用偏相關(guān)圖來確保線性����、單調(diào)性關(guān)系依然存在����。
可解釋模型的小型集成怎樣讓我們更好的理解數(shù)據(jù)�?
如果這種把可解釋模型組合在一起的流程能夠讓我們對(duì)數(shù)據(jù)中出現(xiàn)的模式更熟悉、更敏感�����,對(duì)未來數(shù)據(jù)進(jìn)行預(yù)測(cè)、泛化時(shí)能夠有所裨益����,那么它就可以說是提高了我們對(duì)數(shù)據(jù)的理解�。
可解釋模型的小型集成如何讓我們對(duì)模型更加信任�����?
這種集成讓我們?cè)跊]有犧牲太多可解釋的情況下�,對(duì)傳統(tǒng)的可靠模型的精度進(jìn)行一定的提升。精度提高意味著����,數(shù)據(jù)中的有關(guān)模式以一種更可信�����、更可靠的方式被建模出來�。當(dāng)數(shù)個(gè)模型互為補(bǔ)充,做出符合人類預(yù)期或者領(lǐng)域知識(shí)的預(yù)測(cè)時(shí)�,這種小型集成就顯得更加可靠。
單調(diào)性約束
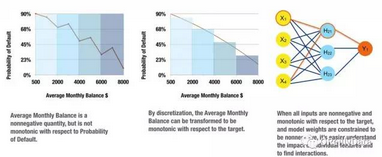
圖13. 在神經(jīng)網(wǎng)絡(luò)中為數(shù)據(jù)和模型加入單調(diào)性約束的示意圖�。感謝Vinod Iyengar以及H2O.ai團(tuán)隊(duì)友情提供圖表
單調(diào)性約束能夠把難以解釋的非線性、非單調(diào)模型轉(zhuǎn)化成為高度可解釋的���、符合監(jiān)管要求的非線性單調(diào)模型��。我們之所以認(rèn)為單調(diào)性很重要���,是基于兩個(gè)原因:
監(jiān)管方希望模型滿足單調(diào)性。無論數(shù)據(jù)樣本是如何的��,監(jiān)管方總是希望見到模型具有單調(diào)性的表現(xiàn)��。比如,考慮信貸評(píng)分模型中的賬戶余額�����。賬戶余額高����,傾向于代表著賬戶所有者更值得授信,低賬戶余額則代表著有潛在的違約風(fēng)險(xiǎn)�。如果某一批特定的數(shù)據(jù)包含著的大量樣本中,含有很多『儲(chǔ)蓄賬戶余額高但貸款違約』的個(gè)體以及『儲(chǔ)蓄賬戶余額低但正在還貸款』的個(gè)體�,那么���,基于這份訓(xùn)練數(shù)據(jù)進(jìn)行機(jī)器學(xué)習(xí)學(xué)出的響應(yīng)函數(shù)對(duì)于賬戶余額這個(gè)變量自然會(huì)是非單調(diào)的����。監(jiān)管方是不會(huì)對(duì)這種預(yù)測(cè)函數(shù)感到滿意的���,因?yàn)樗蛶资陙沓恋硐聛淼念I(lǐng)域?qū)<业囊庖姳车蓝Y�����,因而會(huì)降低模型本身或者數(shù)據(jù)樣本的可信度�����。
單調(diào)性能夠令生成的『原因代碼』保持一貫性��。具有一貫性的原因代碼生成一般被認(rèn)為是模型可解釋性的金標(biāo)準(zhǔn)�。如果在一個(gè)信貸評(píng)分模型中,單調(diào)性得以保證�����,為信貸申請(qǐng)結(jié)果分析原因不但直觀��,而且能夠自動(dòng)化��。如果某個(gè)人的儲(chǔ)蓄賬戶余額低���,那么他的信用水平自然也低���。一旦我們能夠保證單調(diào)性,對(duì)于一次授信決定(譯者注:一般指拒絕授信)的原因解釋可以根據(jù)最大失分法(max-points-lost)可靠地進(jìn)行排序����。最大失分法把一個(gè)個(gè)體放在機(jī)器學(xué)習(xí)所得到的、具有單調(diào)性的響應(yīng)曲面上���,并度量他和曲面上最優(yōu)點(diǎn)(也就是理想的��、可能具有最高信用水平的客戶)的距離���。這個(gè)人與理想客戶之間��,在哪個(gè)坐標(biāo)軸(也就是自變量)距離最遠(yuǎn)��,也就說明拒絕授信時(shí)�����,哪個(gè)負(fù)面因素最重要�;而這個(gè)這個(gè)人與理想客戶之間�,在哪個(gè)坐標(biāo)軸(也就是自變量)距離最近,也就說明這個(gè)原因代碼產(chǎn)生的負(fù)面影響最不重要���;根據(jù)這個(gè)人和『理想客戶』的相對(duì)位置來計(jì)算,其他自變量的影響都排在這二者之間��。在使用最大失分法時(shí)����,單調(diào)性可以簡單地確保我們能做出清晰的����、符合邏輯的判斷:在單調(diào)性模型下��,一個(gè)在貸款業(yè)務(wù)中被授信的客戶����,其儲(chǔ)蓄賬戶余額絕不可能低于一個(gè)被拒絕貸款的客戶(譯者注:在其他條件都接近的情況下)。
在輸入數(shù)據(jù)上加約束��,以及對(duì)生成的模型加約束�����,都可以產(chǎn)生單調(diào)性�����。圖13顯示�,仔細(xì)選擇并處理非負(fù)、單調(diào)變量�,把它們與單隱層神經(jīng)網(wǎng)絡(luò)結(jié)合使用,達(dá)到了使擬合系數(shù)始終為正的約束效果�。這種訓(xùn)練組合產(chǎn)生了非線性、單調(diào)的響應(yīng)函數(shù)�����,根據(jù)響應(yīng)函數(shù)可以對(duì)『原因代碼』進(jìn)行計(jì)算;通過分析模型的系數(shù)�����,可以檢測(cè)高階交叉效應(yīng)�。尋找以及制造這些非負(fù)、單調(diào)的自變量的工作十分枯燥��、費(fèi)時(shí)���,還需要手動(dòng)試錯(cuò)�。幸運(yùn)的是����,神經(jīng)網(wǎng)絡(luò)和樹模型的響應(yīng)函數(shù)往往能夠在規(guī)避枯燥的數(shù)據(jù)預(yù)處理的同時(shí),滿足單調(diào)性的約束�。使用單調(diào)性神經(jīng)網(wǎng)絡(luò)意味著可以定制化模型結(jié)構(gòu),使得生成模型參數(shù)的取值滿足約束����。對(duì)于基于樹的模型來說����,使用均勻分叉往往可以強(qiáng)制保證單調(diào)性:使用某個(gè)自變量分的叉上����,總是能保證當(dāng)自變量取值往某個(gè)方向前進(jìn)時(shí)����,因變量在其所有子節(jié)點(diǎn)上的平均值遞增;自變量取值往另一個(gè)方向前進(jìn)時(shí)�,因變量在其所有子節(jié)點(diǎn)上的平均值遞減。在實(shí)踐中��,為不同類型模型實(shí)現(xiàn)單調(diào)性約束的方法千變?nèi)f化�����,這是一種隨模型而改變的模型解釋性技術(shù)�。
單調(diào)性約束提供了全局性還是局部性的可解釋性?
單調(diào)性約束為響應(yīng)函數(shù)提供了全局的可解釋性���。
單調(diào)性約束能夠?qū)е潞畏N復(fù)雜程度的響應(yīng)函數(shù)����?
它們產(chǎn)生了非線性且單調(diào)的響應(yīng)函數(shù)����。
單調(diào)性約束如何讓我們更好的理解數(shù)據(jù)�����?
它不僅可以確?�!涸虼a』能夠自動(dòng)化地生成����,同時(shí)在特定場(chǎng)景下(比如使用單隱層神經(jīng)網(wǎng)絡(luò)或者單棵決策樹時(shí))�����,變量之間重要的高階交叉效應(yīng)也能夠被自動(dòng)檢測(cè)出來。
單調(diào)性約束如何讓模型更可信賴�����?
當(dāng)單調(diào)性關(guān)系�����、『原因代碼』以及檢測(cè)出的交叉效應(yīng)能夠簡潔地符合領(lǐng)域?qū)<乙庖娀蛘吆侠眍A(yù)期的時(shí)候���,模型的可信度會(huì)得以提升���。如果數(shù)據(jù)中存在擾動(dòng)時(shí)結(jié)果依然保持穩(wěn)定,以及模型隨著時(shí)間產(chǎn)生預(yù)料之內(nèi)的變化的話�,通過敏感性分析也能夠提升模型的可信度。
第三部分:理解復(fù)雜的機(jī)器學(xué)習(xí)模型
在這一部分中我們所要展現(xiàn)的技術(shù)�����,可以為非線性����、非單調(diào)的響應(yīng)函數(shù)生成解釋。我們可以把它們與前兩部分提到的技巧結(jié)合起來��,增加所有種類模型的可解釋性�����。實(shí)踐者很可能需要使用下列增強(qiáng)解釋性技巧中的一種以上�����,為他們手中最復(fù)雜的模型生成令人滿意的解釋性描述�。
代理模型
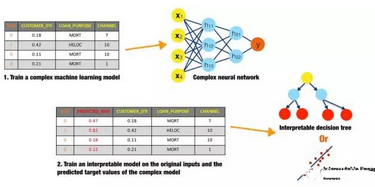
圖14. 為了解釋復(fù)雜神經(jīng)網(wǎng)絡(luò)而使用代理模型的示意圖����。感謝Patrick Hall以及H2O.ai團(tuán)隊(duì)友情提供圖形
代理模型是一種用于解釋復(fù)雜模型的簡單模型����。最常見的建立方法是����,對(duì)原始輸入和復(fù)雜模型給出的預(yù)測(cè)值建立簡單線性回歸或者決策樹模型���。代理模型中所展示的系數(shù)�、變量重要性、趨勢(shì)以及交互作用���,是復(fù)雜模型內(nèi)部機(jī)制的一種體現(xiàn)�����。不過�,幾乎沒有理論依據(jù)能夠保證簡單的代理模型能夠以高精度表達(dá)出更復(fù)雜的模型。
代理模型適用于何種尺度的可解釋性�?
一般而言�,代理模型是全局性的。一個(gè)簡單模型的全局可解釋特性會(huì)用于解釋一個(gè)更復(fù)雜模型的全局特性�。不過���,我們也無法排除代理模型對(duì)復(fù)雜模型條件分布的局部擬合能力�,例如先聚類,再用自變量擬合預(yù)測(cè)值、擬合預(yù)測(cè)值的分位點(diǎn)���、判斷樣本點(diǎn)屬于哪一類等等,能夠體現(xiàn)局部解釋性。因?yàn)闂l件分布的一小段傾向于是線性的���、單調(diào)的�,或者至少有較好的模式��,局部代理模型的預(yù)測(cè)精度往往比全局代理模型的表現(xiàn)更好�。模型無關(guān)的局部可解釋性描述(我們會(huì)在下一小節(jié)介紹)是一種規(guī)范化的局部代理模型建模方法。當(dāng)然����,我們可以把全局代理模型和局部代理模型一起使用,來同時(shí)獲得全局和局部的解釋性�。
代理模型能夠幫助我們解釋何種復(fù)雜程度的響應(yīng)函數(shù)?
代理模型能夠有助于解釋任何復(fù)雜程度的機(jī)器學(xué)習(xí)模型���,不過可能它們最有助于解釋非線性���、非單調(diào)的模型�。
代理模型如何幫我們提高對(duì)數(shù)據(jù)的理解����?
代理模型可以針對(duì)復(fù)雜模型的內(nèi)部機(jī)制向我們提供一些洞見,因此能提高我們對(duì)數(shù)據(jù)的理解�����。
代理模型如何讓模型更可信賴��?
當(dāng)代理模型的系數(shù)�����、變量重要性���、趨勢(shì)效應(yīng)和交叉效應(yīng)都符合人類的領(lǐng)域知識(shí),被建模的數(shù)據(jù)模式符合合理預(yù)期時(shí)����,模型的可信度會(huì)得以提升。當(dāng)數(shù)據(jù)中存在輕微的或者人為的擾動(dòng)時(shí)���,或者數(shù)據(jù)來自于我們感興趣領(lǐng)域的數(shù)據(jù)模擬���,又或者數(shù)據(jù)隨著時(shí)間改變時(shí)�,如果結(jié)合敏感性分析進(jìn)行檢驗(yàn)發(fā)現(xiàn)�����,對(duì)于模型的解釋是穩(wěn)定的�����,并且貼合人類領(lǐng)域經(jīng)驗(yàn)����,符合合理預(yù)期,那么模型的可信度會(huì)得以提升��。
模型無關(guān)的局部可解釋性描述(Local Interpretable Model-agnostic Explanation, LIME)
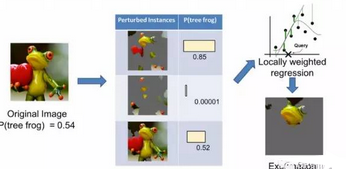
圖15. 對(duì)LIME流程的一個(gè)描述��,其中使用了加權(quán)線性模型幫助我們解釋一個(gè)復(fù)雜的神經(jīng)網(wǎng)絡(luò)是如何做出某個(gè)預(yù)測(cè)的���。感謝Marco Tulio Ribeiro友情提供圖片�。圖片使用已獲得許可
LIME是圍繞單個(gè)樣本建立局部代理模型的一種方法���。它的主旨在于厘清對(duì)于特定的幾個(gè)樣本���,分類器是如何工作的�。LIME需要找到�、模擬或者產(chǎn)生一組可解釋的樣本集。使用這組已經(jīng)被詳細(xì)研究過的樣本���,我們能夠解釋機(jī)器學(xué)習(xí)算法得到的分類器是如何對(duì)那些沒有被仔細(xì)研究過的樣本進(jìn)行分類的�。一個(gè)LIME的實(shí)現(xiàn)可以遵循如下流程:首先��,使用模型對(duì)這組可解釋的數(shù)據(jù)集進(jìn)行打分��;其次��,當(dāng)模型對(duì)另外的數(shù)據(jù)進(jìn)行分類時(shí)�����,使用解釋性數(shù)據(jù)集與另外的數(shù)據(jù)點(diǎn)的距離進(jìn)行加權(quán)����,以加權(quán)后的解釋性數(shù)據(jù)集作為自變量做L1正則化線性回歸��。這個(gè)線性模型的參數(shù)可以用來解釋�����,另外的數(shù)據(jù)是如何被分類/預(yù)測(cè)的。
LIME方法一開始是針對(duì)圖像���、文本分類任務(wù)提出的��,當(dāng)然它也適用于商業(yè)數(shù)據(jù)或者客戶數(shù)據(jù)的分析�����,比如對(duì)預(yù)測(cè)客戶群違約或者流失概率的百分位點(diǎn)進(jìn)行解釋����,或者對(duì)已知的成熟細(xì)分市場(chǎng)中的代表性客戶行為進(jìn)行解釋���,等等����。LIME有多種實(shí)現(xiàn)�,我最常見的兩個(gè),一個(gè)是LIME的原作者的實(shí)現(xiàn)�����,一個(gè)是實(shí)現(xiàn)了很多機(jī)器學(xué)習(xí)解釋工具的eli5包。
LIME提供的可解釋性的尺度如何�����?
LIME是一種提供局部可解釋性的技術(shù)�。
LIME能幫助我們解釋何種復(fù)雜程度的響應(yīng)函數(shù)?
LIME有助于解釋各種復(fù)雜程度的機(jī)器學(xué)習(xí)模型�����,不過它可能最適合解釋非線性���、非單調(diào)的模型�����。
LIME如何幫我們提高對(duì)模型的理解?
LIME提供了我們對(duì)重要變量的洞察力����,厘清這些變量對(duì)特定重要樣本點(diǎn)的影響以及呈現(xiàn)出的線性趨勢(shì)。對(duì)極端復(fù)雜的響應(yīng)函數(shù)更是如此�����。
LIME如何讓模型更加可信��?
當(dāng)LIME發(fā)現(xiàn)的重要變量及其對(duì)重要觀測(cè)點(diǎn)的影響貼合人類已有的領(lǐng)域知識(shí)�����,或者模型中體現(xiàn)的數(shù)據(jù)模式符合人類的預(yù)期時(shí)�����,我們對(duì)模型的信心會(huì)得到增強(qiáng)�����。結(jié)合下文將會(huì)提到的最大激發(fā)分析���,當(dāng)我們能明顯地看到,相似的數(shù)據(jù)被相似的內(nèi)部機(jī)制處理,全然不同的數(shù)據(jù)被不同的內(nèi)部機(jī)制處理��,在對(duì)多個(gè)不同的樣本使用不同處理方式上���,能夠保持一貫性�。同時(shí)����,在數(shù)據(jù)存在輕微擾動(dòng)時(shí),數(shù)據(jù)是由我們感興趣的場(chǎng)景模擬得出時(shí)�,或者數(shù)據(jù)隨時(shí)間改變時(shí)����,LIME可以被視為是敏感性分析的一種,幫助我們檢查模型是否依然能夠保持穩(wěn)定,是否依然貼合人類的領(lǐng)域知識(shí)���,以及數(shù)據(jù)模式是否依然符合預(yù)期����。
最大激發(fā)分析
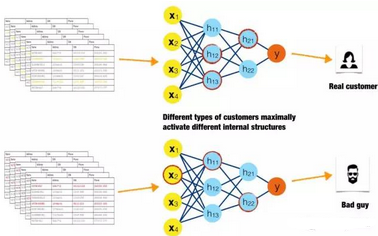
圖16. 不同輸入數(shù)據(jù)激發(fā)神經(jīng)網(wǎng)絡(luò)中不同神經(jīng)元的示意圖��。感謝Patrick Hall以及H2O.ai團(tuán)隊(duì)友情提供圖片
在最大激發(fā)分析中�,可以找到或者模擬出這樣的例子,它們總是會(huì)對(duì)特定的神經(jīng)元��、網(wǎng)絡(luò)層�、濾波器(filter)��、決策樹集成模型中的某棵樹進(jìn)行大量激發(fā)�。像第二部分所提到的單調(diào)性約束一樣,最大激發(fā)分析在實(shí)戰(zhàn)中����,是一種很常見的與模型相關(guān)的解釋性分析技術(shù)�����。
對(duì)于特定的一組樣本或者一類相似的樣本�,觀察它們能夠?qū)憫?yīng)函數(shù)的哪一部分進(jìn)行最大程度的激發(fā)(對(duì)于神經(jīng)元而言是激發(fā)強(qiáng)度最大��,對(duì)于樹模型而言是殘差最低,二者都可以算最大激發(fā))���,這種最大分析厘清了復(fù)雜模型的內(nèi)部工作機(jī)制�。同時(shí)�����,如果不同類型的樣本持續(xù)激發(fā)模型中相同的部分�����,那么這種分析也可以發(fā)現(xiàn)交叉效應(yīng)���。
圖16描繪了一種比較理想化的情況:一個(gè)好的客戶和一個(gè)欺詐型客戶分別以高強(qiáng)度激發(fā)了兩組不同的神經(jīng)元。紅圈表示兩類輸入數(shù)據(jù)所激發(fā)的強(qiáng)度排名前三的神經(jīng)元。對(duì)于這兩類數(shù)據(jù)而言���,最大激發(fā)的神經(jīng)元不同���,表示著對(duì)于不同類型的樣本��,神經(jīng)網(wǎng)絡(luò)的內(nèi)部結(jié)構(gòu)會(huì)以不同的方式對(duì)其進(jìn)行處理。如果對(duì)很多不同子類型的好客戶和欺詐型客戶而言這種模式依然存在�,那么這就是一種很強(qiáng)烈的信號(hào)�����,意味著模型內(nèi)部結(jié)構(gòu)是穩(wěn)定的���、可靠的��。
最大激發(fā)分析適用于哪種尺度的可解釋性����?
最大激發(fā)分析在尺度上是局部性的���,因?yàn)樗坍嬃艘粋€(gè)復(fù)雜響應(yīng)函數(shù)的不同部分是如何處理特定的一個(gè)或者一組觀測(cè)樣本的。
最大激發(fā)分析能夠幫助我們解釋何種復(fù)雜程度的響應(yīng)函數(shù)�����?
最大激發(fā)分析能夠解釋任意復(fù)雜的響應(yīng)函數(shù)�����,不過它可能最適合于解釋非線性、非單調(diào)的模型����。
最大激發(fā)分析如何讓我們更好的理解數(shù)據(jù)和模型?
最大激發(fā)函數(shù)通過像我們展示復(fù)雜模型的內(nèi)部結(jié)構(gòu)�����,提高我們對(duì)數(shù)據(jù)����、模型的理解。
最大激發(fā)分析如何讓模型變的更加可信�����?
上文討論過的LIME有助于解釋在一個(gè)模型中對(duì)條件分布的局部進(jìn)行建模并預(yù)測(cè)�����。最大激發(fā)分析可以強(qiáng)化我們對(duì)模型局部內(nèi)在機(jī)制的信心��。二者的組合可以為復(fù)雜的響應(yīng)函數(shù)建立詳細(xì)的局部解釋,它們是很棒的搭配�����。使用最大激發(fā)分析�����,當(dāng)我們能明顯地看到��,相似的數(shù)據(jù)被相似的內(nèi)部機(jī)制處理����,全然不同的數(shù)據(jù)被不同的內(nèi)部機(jī)制處理,對(duì)多個(gè)不同的樣本使用不同處理方式這一點(diǎn)保持一貫性����,模型中發(fā)現(xiàn)的交互作用貼合人類已有的領(lǐng)域知識(shí),或者符合人類的預(yù)期����,甚至把最大激發(fā)分析當(dāng)做一種敏感性分析來用,以上的種種都會(huì)讓我們對(duì)模型的信心得以提高����。同時(shí)�,在數(shù)據(jù)存在輕微擾動(dòng)時(shí),數(shù)據(jù)是由我們感興趣的場(chǎng)景模擬得出時(shí)�,或者數(shù)據(jù)隨時(shí)間改變時(shí),最大激發(fā)分析可以幫我們檢查模型對(duì)于樣本的處理是否依然保持穩(wěn)定���。
敏感性分析

圖17. 一個(gè)變量的分布隨著時(shí)間而改變的示意圖���。感謝Patrick Hall以及H2O.ai團(tuán)隊(duì)友情提供圖片
敏感性分析考察的是這樣一種特性:給數(shù)據(jù)加上人為的擾動(dòng),或者加上模擬出的變化時(shí)���,模型的行為以及預(yù)測(cè)結(jié)果是否仍然保持穩(wěn)定���。在傳統(tǒng)模型評(píng)估以外���,對(duì)機(jī)器學(xué)習(xí)模型預(yù)測(cè)進(jìn)行敏感性分析可能是最有力的機(jī)器學(xué)習(xí)模型驗(yàn)證技術(shù)�����。微小地改變變量的輸入值���,機(jī)器學(xué)習(xí)模型可能會(huì)給出全然不同的預(yù)測(cè)結(jié)論�。在實(shí)戰(zhàn)中�,因?yàn)樽宰兞恐g��、因變量與自變量之間都存在相關(guān)性,有不少線性模型的驗(yàn)證技巧是針對(duì)回歸系數(shù)的數(shù)值穩(wěn)定性的��。
對(duì)從線性建模技術(shù)轉(zhuǎn)向機(jī)器學(xué)習(xí)建模技術(shù)的人而言�����,少關(guān)注一些模型參數(shù)數(shù)值不穩(wěn)定性的情況�,多關(guān)心一些模型預(yù)測(cè)的不穩(wěn)定性�����,這種做法可能還算是比較謹(jǐn)慎。
如果我們能針對(duì)有趣的情況或者已知的極端情況做一些數(shù)據(jù)模擬����,敏感性分析也可以基于這些數(shù)據(jù)對(duì)模型的行為以及預(yù)測(cè)結(jié)果做一些驗(yàn)證。在整篇文章中提及或者不曾提及的不少技巧,都可以用來進(jìn)行敏感性分析�����。預(yù)測(cè)的分布�、錯(cuò)誤比率度量�、圖標(biāo)�����、解釋性技巧��,這些方法都可以用來檢查模型在處理重要場(chǎng)景中的數(shù)據(jù)時(shí)表現(xiàn)如何�����,表現(xiàn)如何隨著時(shí)間變化��,以及在數(shù)據(jù)包含人為損壞的時(shí)候模型是否還能保持穩(wěn)定����。
敏感性分析適用于什么尺度的可解釋性����?
敏感性分析可以是一種全局性的解釋技術(shù)��。當(dāng)使用單個(gè)的像代理模型這種全局性解釋技術(shù)時(shí)��,使用敏感性分析可以保證�,就算數(shù)據(jù)中存在輕微擾動(dòng)或者有人為造成的數(shù)據(jù)缺失�����,代理模型中所存在的主要交叉效應(yīng)依然穩(wěn)定存在��。
敏感性分析也可以是一種局部性的解釋技術(shù)��。例如,當(dāng)使用LIME這種局部性解釋技術(shù)時(shí)��,它可以判斷在宏觀經(jīng)濟(jì)承壓的條件下�,為某個(gè)細(xì)分市場(chǎng)的客戶進(jìn)行授信時(shí)�,模型中使用的重要變量是否依然重要。
敏感性分析能夠幫我們解釋何種復(fù)雜程度的響應(yīng)函數(shù)���?
敏感性分析可以解釋任何復(fù)雜程度的響應(yīng)函數(shù)�。不過它可能最適合于解釋非線性的,或者表征高階變量交叉特征的響應(yīng)函數(shù)��。在這兩種情況下�����,對(duì)自變量輸入值的輕微改變都可能引起預(yù)測(cè)值的大幅變動(dòng)�。
敏感性分析如何幫助我們更好的理解模型��?
敏感性分析通過向我們展現(xiàn)在重要的場(chǎng)景下���,模型及其預(yù)測(cè)值傾向于如何表現(xiàn),以及這種表現(xiàn)隨時(shí)間會(huì)如何變化����。因此敏感性分析可以加強(qiáng)我們對(duì)模型的理解。
敏感性分析如何提高模型的可信可信度���?
如果在數(shù)據(jù)輕微改變或者故意受損時(shí)�,模型的表現(xiàn)以及預(yù)測(cè)輸出仍然能表現(xiàn)穩(wěn)定�,那么穩(wěn)定性分析就可以提高我們對(duì)模型的信任。除此以外��,如果數(shù)據(jù)場(chǎng)景受到外來影響�����,或者數(shù)據(jù)模式隨時(shí)間發(fā)生變化時(shí)���,模型仍然能夠符合人類的領(lǐng)域知識(shí)或者預(yù)期的話�,模型的可信度也會(huì)上升�。
變量重要性的度量
對(duì)于非線性����、非單調(diào)的響應(yīng)函數(shù),為了量化衡量模型中自變量和因變量的關(guān)系�,往往只能度量變量重要性這一種方法可以選。變量重要性度量難以說明自變量大概是往哪個(gè)方向影響因變量的��。這種方法只能說明,一個(gè)自變量跟其他自變量相
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫���,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330