python實(shí)現(xiàn)六大分群質(zhì)量評(píng)估指標(biāo)(蘭德系數(shù)、互信息��、輪廓系數(shù))
1 R語(yǔ)言中的分群質(zhì)量——輪廓系數(shù)
因?yàn)橄惹皯T用R語(yǔ)言����,那么來(lái)看看R語(yǔ)言中的分群質(zhì)量評(píng)估,節(jié)選自筆記︱多種常見(jiàn)聚類模型以及分群質(zhì)量評(píng)估(聚類注意事項(xiàng)�、使用技巧):
沒(méi)有固定標(biāo)準(zhǔn),一般會(huì)3-10分群���?�;蛘哂靡恍┲笜?biāo)評(píng)價(jià)�����,然后交叉驗(yàn)證不同群的分群指標(biāo)�。
一般的指標(biāo):輪廓系數(shù)silhouette(-1,1之間��,值越大�,聚類效果越好)(fpc包),蘭德指數(shù)rand�����;R語(yǔ)言中有一個(gè)包用30種方法來(lái)評(píng)價(jià)不同類的方法(NbClust)��,但是速度較慢
商業(yè)上的指標(biāo):分群結(jié)果的覆蓋率�����;分群結(jié)果的穩(wěn)定性;分群結(jié)果是否從商業(yè)上易于理解和執(zhí)行
輪廓系數(shù)旨在將某個(gè)對(duì)象與自己的簇的相似程度和與其他簇的相似程度進(jìn)行比較�����。輪廓系數(shù)最高的簇的數(shù)量表示簇的數(shù)量的最佳選擇����。
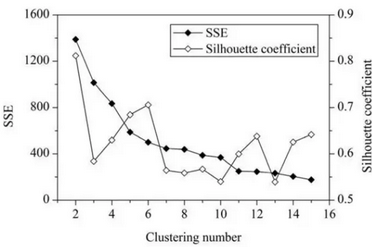
一般來(lái)說(shuō),平均輪廓系數(shù)越高�,聚類的質(zhì)量也相對(duì)較好。在這�,對(duì)于研究區(qū)域的網(wǎng)格單元,最優(yōu)聚類數(shù)應(yīng)該是2�����,這時(shí)平均輪廓系數(shù)的值最高�����。但是�����,聚類結(jié)果(k=2)的 SSE 值太大了���。當(dāng) k=6 時(shí)��,SEE 的值會(huì)低很多��,但此時(shí)平均輪廓系數(shù)的值非常高�����,僅僅比 k=2 時(shí)的值低一點(diǎn)����。因此��,k=6 是最佳的選擇�。
2 python中的分群質(zhì)量
主要參考來(lái)自官方文檔:Clustering
部分內(nèi)容來(lái)源于:機(jī)器學(xué)習(xí)評(píng)價(jià)指標(biāo)大匯總
個(gè)人比較偏好的三個(gè)指標(biāo)有:Calinski-Harabaz Index(未知真實(shí)index的模型評(píng)估)、Homogeneity, completeness and V-measure(聚類數(shù)量情況)���、輪廓系數(shù)
1.1 Adjusted Rand index 調(diào)整蘭德系數(shù)

>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.adjusted_rand_score(labels_true, labels_pred)
0.24
1.2 Mutual Information based scores 互信息

Two different normalized versions of this measure are available, Normalized Mutual Information(NMI) and Adjusted Mutual Information(AMI). NMI is often used in the literature while AMI was proposed more recently and is normalized against chance:
>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.adjusted_mutual_info_score(labels_true, labels_pred)
0.22504
1.3 Homogeneity, completeness and V-measure
同質(zhì)性homogeneity:每個(gè)群集只包含單個(gè)類的成員����。
完整性completeness:給定類的所有成員都分配給同一個(gè)群集���。
>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.homogeneity_score(labels_true, labels_pred)
0.66...
>>> metrics.completeness_score(labels_true, labels_pred)
0.42...
兩者的調(diào)和平均V-measure:
>>> metrics.v_measure_score(labels_true, labels_pred)
0.51...
1.4 Fowlkes-Mallows scores
The Fowlkes-Mallows score FMI is defined as the geometric mean of the pairwise precision and recall:

>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>>
>>> metrics.fowlkes_mallows_score(labels_true, labels_pred)
0.47140...
1.5 Silhouette Coefficient 輪廓系數(shù)

>>> import numpy as np
>>> from sklearn.cluster import KMeans
>>> kmeans_model = KMeans(n_clusters=3, random_state=1).fit(X)
>>> labels = kmeans_model.labels_
>>> metrics.silhouette_score(X, labels, metric='euclidean')
...
0.55...
1.6 Calinski-Harabaz Index
這個(gè)計(jì)算簡(jiǎn)單直接����,得到的Calinski-Harabasz分?jǐn)?shù)值ss越大則聚類效果越好。Calinski-Harabasz分?jǐn)?shù)值ss的數(shù)學(xué)計(jì)算公式是:

也就是說(shuō)���,類別內(nèi)部數(shù)據(jù)的協(xié)方差越小越好�,類別之間的協(xié)方差越大越好�����,這樣的Calinski-Harabasz分?jǐn)?shù)會(huì)高��。
在scikit-learn中�, Calinski-Harabasz Index對(duì)應(yīng)的方法是metrics.calinski_harabaz_score.
在真實(shí)的分群label不知道的情況下,可以作為評(píng)估模型的一個(gè)指標(biāo)����。
同時(shí),數(shù)值越小可以理解為:組間協(xié)方差很小����,組與組之間界限不明顯。
與輪廓系數(shù)的對(duì)比����,筆者覺(jué)得最大的優(yōu)勢(shì):快�!相差幾百倍���!毫秒級(jí)
>>> import numpy as np
>>> from sklearn.cluster import KMeans
>>> kmeans_model = KMeans(n_clusters=3, random_state=1).fit(X)
>>> labels = kmeans_model.labels_
>>> metrics.calinski_harabaz_score(X, labels)
560.39...
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫(kù)��,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330