R語(yǔ)言︱詞典型情感分析文本操作技巧匯總(打標(biāo)簽�����、詞典與數(shù)據(jù)匹配等)
情感分析中對(duì)文本處理的數(shù)據(jù)的小技巧要求比較高�����,筆者在學(xué)習(xí)時(shí)候會(huì)為一些小技巧感到頭疼不已���。
主要包括以下內(nèi)容:
1 批量讀取txt字符文件(導(dǎo)入、文本內(nèi)容逐行讀取、加入文檔名字)�����、
2��、文本清洗(一級(jí)清洗��,去標(biāo)點(diǎn)�;二級(jí)清洗去內(nèi)容;三級(jí)清洗��,去停用詞)
3�����、詞典之間匹配(有主鍵join�����、詞庫(kù)匹配%in%)
4��、分詞之后檔案id+label的加入
5��、情感打分(關(guān)聯(lián)情感詞join�����、情感分?jǐn)?shù)aggerate�、情感偏向)
————————————————————————————————————————————
1、批量讀取txt字符文件
難題:一個(gè)文件夾有許多txt文件�����,如何導(dǎo)入��,并且讀出來���,還要加上文檔名字��?
1.1 如何導(dǎo)入����?
如何用函數(shù)批量導(dǎo)入文本�����,并且能夠留在R的環(huán)境之中?循環(huán)用read.table����,怎么解決每個(gè)文本文件命名問題?
list函數(shù)能夠有效的讀入,并且存放非結(jié)構(gòu)化數(shù)據(jù)��。
[plain]view plaincopyprint?
-
reviewpath <- "F:/R語(yǔ)言/train2"
-
completepath <- list.files(reviewpath, pattern = "*.txt$", full.names = TRUE)
代碼解讀:reviewpath為文件夾的目錄名字����,completepath為讀取文件夾中所有的文件,生成字符串(character)格式�����。
詳細(xì)的文本文件讀取方法����,可見博客。
1.2 如何讀取單文本內(nèi)容�����?
前面文檔導(dǎo)入�����,相當(dāng)于是給每個(gè)文檔定了位�,現(xiàn)在需要讀入單個(gè)文檔內(nèi)的文本信息。
文本文檔讀取的時(shí)候會(huì)出現(xiàn)很多問題��,比如分隔符、制表符等���,而出現(xiàn)亂碼,需要逐行讀取����。
[plain]view plaincopyprint?
######批量讀入文本
read.txt <- function(x) { des <- readLines(x) #每行讀取
return(paste(des, collapse = "")) #沒有return則返回最后一個(gè)函數(shù)對(duì)象
}
review <- lapply(completepath, read.txt)
#如果程序警告,這里可能是部分文件最后一行沒有換行導(dǎo)致���,不用擔(dān)心�����。
代碼解讀:read.txt是一個(gè)簡(jiǎn)單的逐行讀取的函數(shù)���,readLines函數(shù),是將一段文字分成以下的形式�,需要粘貼起來;
[plain]view plaincopyprint?
[1] ""
[2] "剛買的這款電腦���,在自提點(diǎn)打開的���,就發(fā)現(xiàn)鍵盤已經(jīng)壞了�����,有個(gè)按鍵都快掉了��,自提點(diǎn)不管�����,讓去聯(lián)系退換貨部門�����,退換貨部門說鍵盤壞了不管退換�,讓去惠普自己更換新鍵盤�。"
[3] ""
[4] "在京東剛買的東西出現(xiàn)問題就要四處跑去修理,他們把責(zé)任推的一干二凈�����,現(xiàn)在除非你出具惠普的質(zhì)檢報(bào)告��,他們才給受理��。"
[5] ""
return(paste)函數(shù)將每一行粘貼在一起��,最后返回完整的文本內(nèi)容;
lapply表示逐文本讀取�。
1.3 加入文檔名字
讀取了每個(gè)文檔到list之中,怎么跟每個(gè)文檔名字匹配在一起�����?
[plain]view plaincopyprint?
docname <- list.files(reviewpath, pattern = "*.txt$")
reviewdf <- as.data.frame(cbind(docname, unlist(review)),
stringsAsFactors = F)
colnames(reviewdf) <- c("id", "msg") #列名
代碼解讀:list.files中���,full.names=F代表返回文檔名字(默認(rèn)),full.names=T則定位文檔�����;
利用as.data.frame成為一個(gè)數(shù)據(jù)框�����,并且不變成因子型���,stringsAsFactors是因?yàn)槲臋n名字列���,很容易變成字符因子型,需要關(guān)閉這功能���;
colnames修改列名�����,還有names也可以達(dá)到同樣的效果����。

圖 1
————————————————————————————————————————————
2、文本清洗工作
文本挖掘中����,對(duì)文本的清洗工作尤為重要,會(huì)出現(xiàn)比如:英文逗號(hào)�、波浪線、英文單引號(hào)����、英文雙引號(hào)、分隔符等
2.1 一級(jí)清洗——去標(biāo)點(diǎn)
如圖1,所示的msg���,對(duì)其進(jìn)行一些標(biāo)點(diǎn)清洗�,比如雙引號(hào)����,波浪號(hào)等�����。
[plain]view plaincopyprint?
reviewdf$msg <- gsub(pattern = " ", replacement ="", reviewdf$msg) #gsub是字符替換函數(shù)�,去空格
reviewdf$msg <- gsub("\t", "", reviewdf$msg) #有時(shí)需要使用\\\t
reviewdf$msg <- gsub(",", "�,", reviewdf$msg)#文中有英文逗號(hào)會(huì)報(bào)錯(cuò),所以用大寫的“��,”
reviewdf$msg <- gsub("~|'", "", reviewdf$msg)#替換了波浪號(hào)(~)和英文單引號(hào)(')�,它們之間用“|”符號(hào)隔開,表示或的關(guān)系
reviewdf$msg <- gsub("\\\"", "", reviewdf$msg)#替換所有的英文雙引號(hào)(")���,因?yàn)殡p引號(hào)在R中有特殊含義,所以要使用三個(gè)斜杠(\\\)轉(zhuǎn)義
代碼解讀:英文單引號(hào)(')����、英文雙引號(hào)(")、波浪號(hào)(~)����,都會(huì)引起讀取時(shí)發(fā)生警告,帶來csv文件或txt文件讀取不完整的后果��。還有一些字符型會(huì)出現(xiàn)亂碼的標(biāo)點(diǎn)等�,詳見博客:R語(yǔ)言︱文本(字符串)處理與正則表達(dá)式
2.2 二級(jí)清洗——去內(nèi)容
如圖1 ,msg�����,對(duì)文檔進(jìn)行二級(jí)清洗�����,比如清楚全英文字符����、清除數(shù)字等�����。
[plain]view plaincopyprint?
sentence <- as.vector(test$msg) #文本內(nèi)容轉(zhuǎn)化為向量sentence
sentence <- gsub("[[:digit:]]*", "", sentence) #清除數(shù)字[a-zA-Z]
sentence <- gsub("[a-zA-Z]", "", sentence) #清除英文字符
sentence <- gsub("\\.", "", sentence) #清除全英文的dot符號(hào)
sentence <- sentence[!is.na(sentence)] #清除對(duì)應(yīng)sentence里面的空值(文本內(nèi)容)��,要先執(zhí)行文本名
sentence <- sentence[!nchar(sentence) < 2] #`nchar`函數(shù)對(duì)字符計(jì)數(shù)���,英文嘆號(hào)為R語(yǔ)言里的“非”函數(shù)
代碼解讀:在進(jìn)行二級(jí)清洗的過程中�,需要先轉(zhuǎn)化為向量形式�,as.vector;
字符數(shù)過小的文本也需要清洗�,nchar就是字符計(jì)數(shù)函數(shù)。
2.3 三級(jí)清理——停用詞清理(哎呦,哎�����,啊...)
去除原理就是導(dǎo)入停用詞列表�����,是一列chr[1:n]的格式���;
先與情感詞典匹配���,在停用詞庫(kù)去掉情感詞典中的單詞,以免刪除了很多情感詞�,構(gòu)造新的停用詞;
再與源序列匹配����,在原序列中去掉停用詞�����。
第一種方法:
[plain]view plaincopyprint?
stopword <- read.csv("F:/R語(yǔ)言/R語(yǔ)言與文本挖掘/情感分析/數(shù)據(jù)/dict/stopword.csv", header = T, sep = ",", stringsAsFactors = F)
stopword <- stopword[!stopword$term %in% posneg$term,]#函數(shù)`%in%`在posneg$term中查找stopword的元素��,如果查到了就返回真值,沒查到就返回假
#結(jié)果是一個(gè)和stopword等長(zhǎng)的波爾值向量����,“非”函數(shù)將布爾值反向
testterm <- testterm[!testterm$term %in% stopword,]#去除停用詞
代碼解讀:
管道函數(shù)A %in% B,代表在A中搜索B�,存在則生成(TRUE,FALSE,TRUE)布爾向量,其中TURE代表A/B共有的。形成一個(gè)與原序列的等長(zhǎng)的波爾值向量��,“非”函數(shù)將布爾值反向就可以去除停用詞�。
stopword[!stopword$term %in% posneg$term,],去掉stopword中與posneg共有的詞���;
testterm[!testterm$term %in% stopword$term,]�����,去掉testtrerm(原序列)與stopword共有的詞�����。
第二種方法:
[plain]view plaincopyprint?
stopword <- read.csv("F:/R語(yǔ)言/R語(yǔ)言與文本挖掘/情感分析/數(shù)據(jù)/dict/stopword.csv", header = T, sep = ",", stringsAsFactors = F)
stopword <- setdiff(stopword$term,posneg$term)
testterm<- setdiff(testterm$term,stopword)
setdiff(x,y)�,代表在x中去掉xy共有的元素�。
setdiff與%in%都是集合運(yùn)算符號(hào),可見其他的一些符號(hào):R語(yǔ)言︱集合運(yùn)算
————————————————————————————————————————————
3�、文檔之間匹配
3.1 有主鍵的情況
如圖1 中的id��,就是一個(gè)主鍵�,建立主鍵之間的關(guān)聯(lián)可以用plyr中的Join函數(shù)��,`join`默認(rèn)設(shè)置下執(zhí)行左連接�。
[plain]view plaincopyprint?
#plyr包里的`join`函數(shù)會(huì)根據(jù)名稱相同的列進(jìn)行匹配關(guān)聯(lián),`join`默認(rèn)設(shè)置下執(zhí)行左連接
reviewdf <- join(表1,表2)
reviewdf <- 表1[!is.na(表1$label),] #非NA值的行賦值
代碼解讀:表1為圖1中的數(shù)據(jù)表�,表2是id+label;
join之后����,在表1中加入匹配到的表2的label;
并且通過[!x,]去掉了���,沒有l(wèi)abel的文本�。
其他關(guān)于主鍵合并的方法有�,dplyr包等,可見博客:R語(yǔ)言數(shù)據(jù)集合并��、數(shù)據(jù)增減
3.2 詞庫(kù)之間相互匹配
1��、集合運(yùn)算(%in%/setdiff())——做去除數(shù)據(jù)
在2.3的三級(jí)停用詞清理的過程中���,就會(huì)用到這個(gè)。兩個(gè)詞庫(kù),但是沒有主鍵��,兩個(gè)詞庫(kù)都有共有的一些詞語(yǔ)��,那么怎么建立兩個(gè)詞庫(kù)的連接呢����?
管道函數(shù)%in%,可以很好的解決����。A%in%B,代表在A中搜索B����,存在B則生成(TRUE,FALSE,TRUE)布爾向量,其中TURE代表A/B共有的。
向量長(zhǎng)度依存于A�,會(huì)生成一個(gè)與A相同長(zhǎng)度的布爾向量,通過A[布爾向量,]就可以直接使用��。
回憶一下�����,缺失值查找函數(shù)���,A[na.is(x)],也是生成布爾向量�。
詳細(xì)見2.3的停用詞刪除的用法。
2��、left_join——詞庫(kù)匹配打標(biāo)簽
以上%in%較為適合做去除數(shù)據(jù)來做��,因?yàn)榭梢陨刹紶栂蛄?��,作為過渡�。但是如何連接詞庫(kù)�,并且匹配過去標(biāo)簽?zāi)亍?
現(xiàn)在有兩個(gè)數(shù)據(jù):
[plain]view plaincopyprint?
> head(temp)
term df 阿波羅 0.0000573263
2 阿爾卑斯山 0.0000573263
3 阿富汗 0.0001719789
4 阿哥 0.0001146526
5 阿根廷 0.0000573263
6 阿拉伯 0.0001146526
> head(traintfidf[,1:3])
id label term
1 4995.txt 1 阿波羅
2 16443.txt 1 阿爾卑斯山
3 12897.txt 1 阿富汗
4 7001.txt 1 阿富汗
5 9427.txt 1 阿富汗
6 12368.txt 1 阿哥
通過left_join之后,就可以根據(jù)每個(gè)詞語(yǔ)匹配DF值�����,并且在源數(shù)據(jù)重復(fù)的情況下���,還是能夠順利匹配上�。
用在監(jiān)督式算法情感分析之中�,可見R語(yǔ)言︱監(jiān)督算法式的情感分析筆記。
[plain]view plaincopyprint?
> head(traintfidf[,1:5])
id label term tf df
4995.txt 1 阿波羅 1 0.0000573263 16443.txt 1 阿爾卑斯山 1 0.0000573263
12897.txt 1 阿富汗 2 0.0001719789
7001.txt 1 阿富汗 1 0.0001719789
9427.txt 1 阿富汗 1 0.0001719789
12368.txt 1 阿哥 1 0.0001146526
————————————————————————————————————————————
4�����、分詞之后文檔如何整理�����?——構(gòu)造一個(gè)單詞一個(gè)文檔名一個(gè)label
分詞之后���,一個(gè)文檔可能就有很多單詞,應(yīng)該每個(gè)單詞都單獨(dú)列出來,并且一個(gè)單詞一個(gè)文檔名一個(gè)label���。
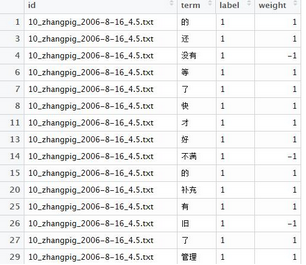
圖 2
[plain]view plaincopyprint?
system.time(x <- segmentCN(strwords = sentence))
#每次可能耗費(fèi)時(shí)間較長(zhǎng)的過程�,都要使用少量數(shù)據(jù)預(yù)估一下時(shí)間�����,這是一個(gè)優(yōu)秀的習(xí)慣
temp <- lapply(x, length) #每一個(gè)元素的長(zhǎng)度,即文本分出多少個(gè)詞
temp <- unlist(temp) #lapply返回的是一個(gè)list,所以3行unlist
id <- rep(test[, "id"], temp) #將每一個(gè)對(duì)應(yīng)的id復(fù)制相應(yīng)的次數(shù)�����,就可以和詞匯對(duì)應(yīng)了
label <- rep(test[, "label"], temp)#id對(duì)應(yīng)的情感傾向標(biāo)簽復(fù)制相同的次數(shù)
term <- unlist(x) #6行將list解散為向量
testterm <- as.data.frame(cbind(id, term, label), stringsAsFactors = F)
#將一一對(duì)應(yīng)的三個(gè)向量按列捆綁為數(shù)據(jù)框����,分詞整理就基本結(jié)束了
代碼解讀:segmentCN是分詞函數(shù);lapply求得每個(gè)文本單詞個(gè)數(shù)����;
unlist,可以讓單詞變成向量化,單詞操作的時(shí)候都需要這步驟,比如前面對(duì)單詞進(jìn)行清洗����,需要展平數(shù)據(jù)�;
rep,重復(fù)id以及l(fā)abel����,按照單詞個(gè)數(shù)���,rep(c("id","su"),c(2,1)),執(zhí)行之后為“id”“id”“su”。
————————————————————————————————————————————
5���、情感打分
5.1 關(guān)聯(lián)情感詞
現(xiàn)在有了圖2的數(shù)據(jù)以及情感詞典數(shù)據(jù)圖3�,以term為主鍵,進(jìn)行join合并�。情感詞典中沒有的詞,則刪除。
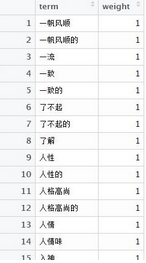
圖 3
[plain]view plaincopyprint?
library(plyr) testterm <- join(testterm, posneg)
testterm <- testterm[!is.na(testterm$weight), ]
head(testterm)
代碼解讀:join����,以term進(jìn)行左關(guān)聯(lián)合并�����,在A表中,會(huì)多出來weigh的一列��,但是會(huì)出現(xiàn)(1,NA,2�����,3��,NA)���,一些沒有匹配到的NA��,
用[is.na(testterm$weight),]來進(jìn)行刪除�。
5.2 情感分?jǐn)?shù)
有了圖2的id+weight列��,就可以直接分組匯總��,比如aggregate���,其他匯總函數(shù)可見比博客:R語(yǔ)言數(shù)據(jù)集合并、數(shù)據(jù)增減
[plain]view plaincopyprint?
dictresult <- aggregate(weight ~ id, data = testterm, sum)
對(duì)weight列以文本id分組求和���,即為情感打分�����。
5.3 情感偏向
有了情感分?jǐn)?shù)�,我想單單知道這些ID正負(fù)���,就像圖2中的label���。
可以利用布爾向量建立連接。數(shù)據(jù)分析師培訓(xùn)
[plain]view plaincopyprint?
dictlabel <- rep(-1, length(dictresult[, 1]))
dictlabel[dictresult$weight > 0] <- 1
dictresult <- as.data.frame(cbind(dictresult, dictlabel), stringsAsFactors = F)
先生成一個(gè)原數(shù)列長(zhǎng)度的-1數(shù)列;
在原數(shù)列$weight>0會(huì)生成一個(gè)布爾向量����,然后進(jìn)行賦值,就可以構(gòu)造label了。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫(kù)�����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330