用Python處理數(shù)據(jù)集中的缺失值
現(xiàn)實(shí)生活中的數(shù)據(jù)經(jīng)常存在缺失值�����。產(chǎn)生缺失值的原因有很多�,如觀(guān)察資料未被記錄、數(shù)據(jù)損壞等�。由于很多機(jī)器學(xué)習(xí)算法不支持存在缺失值的數(shù)據(jù)集,正確處理缺失值就顯得比較重要了�����。本文向大家介紹一些使用Python處理數(shù)據(jù)集中缺失值的方法���,旨在幫助大家了解以下內(nèi)容:
1�、如何將數(shù)據(jù)集中無(wú)效或損壞的值標(biāo)記為缺失值;
2���、如何刪除數(shù)據(jù)集中的缺失值�����;
3�、如何通過(guò)均值估算數(shù)據(jù)集中存在的缺失值��。
注意:運(yùn)行本文的示例代碼前�,請(qǐng)確保已經(jīng)安裝Python2或者Python3,并安裝好了Pandas, NumPy和Scikit-Learn����,另外Scikit-Learn需要0.18及以上版本。
概覽
本文分為以下六個(gè)部分的內(nèi)容:
1�����、皮馬印第安人糖尿病數(shù)據(jù)集(Pima Indians Diabetes Dataset)--該部分將介紹給大家一個(gè)已知存在缺失值的數(shù)據(jù)集
2��、標(biāo)記缺失值--該部分用來(lái)學(xué)習(xí)如何標(biāo)記數(shù)據(jù)集中的缺失值
3��、缺失值可能會(huì)帶來(lái)的問(wèn)題--該部分將了解到當(dāng)數(shù)據(jù)集中存在缺失值時(shí)會(huì)對(duì)機(jī)器學(xué)習(xí)算法存在怎樣的負(fù)面影響
4����、刪除存在缺失值的行--該部分介紹如何刪除數(shù)據(jù)集中包含缺失值的行
5、估算缺失值--該部分介紹如何使用估算值來(lái)替換缺失值
6��、支持存在缺失值數(shù)據(jù)集的一些算法--該部分將了解到一些支持缺失值的算法
首先���,先來(lái)認(rèn)識(shí)下我們的樣例數(shù)據(jù)集��。
1��、皮馬印第安人糖尿病數(shù)據(jù)集(Pima Indians Diabetes Dataset)
皮馬印第安人糖尿病數(shù)據(jù)集涉及基于給定的醫(yī)療措施預(yù)測(cè)皮馬印第安人5年內(nèi)糖尿病的發(fā)病情況���。這是一個(gè)二分類(lèi)問(wèn)題,每一類(lèi)對(duì)應(yīng)的觀(guān)測(cè)值數(shù)量并不均衡���。該數(shù)據(jù)集共有768組觀(guān)測(cè)值�,每組觀(guān)測(cè)值有8個(gè)輸入變量和1個(gè)輸出變量�。變量名稱(chēng)及含義如下所示:
0列為懷孕次數(shù);
1列為口服葡萄糖耐量試驗(yàn)中2小時(shí)后的血漿葡萄糖濃度�;
2列為舒張壓(單位:mm Hg)
3列為三頭肌皮褶厚度(單位:mm)
4列為餐后血清胰島素(單位:mm)
5列為體重指數(shù)(體重(公斤)/ 身高(米)^2)
6列為糖尿病家系作用
7列為年齡
8列為分類(lèi)變量(0或1)
多數(shù)情況下,預(yù)測(cè)模型的基準(zhǔn)水平大約為65%的分辨精度�����,最高則能達(dá)到接近77%的分類(lèi)精度。
數(shù)據(jù)集的前五組觀(guān)測(cè)值如下所示:
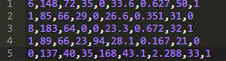
該數(shù)據(jù)集已知存在缺失值�,某些列中存在的缺失值被標(biāo)記為0。通過(guò)這些列中指標(biāo)的定義和相應(yīng)領(lǐng)域的常識(shí)可以證實(shí)上述觀(guān)點(diǎn)��,譬如體重指數(shù)和血壓兩列中的0作為指標(biāo)數(shù)值來(lái)說(shuō)是無(wú)意義的���。
點(diǎn)擊此處下載數(shù)據(jù)集到你的當(dāng)前工作路徑���,并重命名為pima-indians-diabetes.csv。
2���、標(biāo)記缺失值
在這一部分���,我們將學(xué)習(xí)如何鑒別和標(biāo)記缺失值。
借助散點(diǎn)圖和統(tǒng)計(jì)指標(biāo)��,我們能夠識(shí)別缺失或損壞的數(shù)據(jù)�。
如下圖所示,先將數(shù)據(jù)加載到Pandas模塊提供的DataFrame中�,然后打印出每個(gè)變量的統(tǒng)計(jì)信息。

運(yùn)行上述代碼將產(chǎn)生以下結(jié)果:
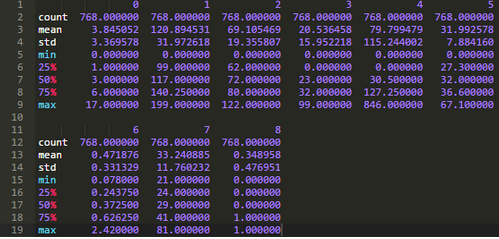
這個(gè)結(jié)果非常有用:從結(jié)果中我們可以看到很多列的最小值為0。而在一些特定列代表的變量中��,0值并沒(méi)有意義���,這就表名該值無(wú)效或?yàn)槿笔е怠?
具體來(lái)說(shuō),下列變量的最小值為0時(shí)數(shù)據(jù)無(wú)意義:
1���、血漿葡萄糖濃度
2���、舒張壓
3、肱三頭肌皮褶厚度
4�、餐后血清胰島素
5、體重指數(shù)
讓我們確認(rèn)一下原始數(shù)據(jù)���,下述代碼打印了數(shù)據(jù)集的前二十條數(shù)據(jù)�����。

代碼運(yùn)行后�����,可以很清楚得看到第2��、3����、4、5列的0值�����。
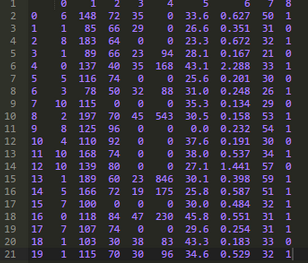
輸出結(jié)果容易看出上述幾列中每一列缺失值的個(gè)數(shù)���。我們可以把DataFrame中感興趣的包含0值的那部分子集標(biāo)記為T(mén)rue����,然后計(jì)算出對(duì)應(yīng)列中值為T(mén)rue的數(shù)量����。

上述代碼的運(yùn)行結(jié)果如下:
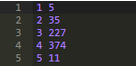
結(jié)果顯示,第1�、2、5列中0值較少���;相比較而言��,第3���、4列中的0值多出數(shù)倍�,接近總量的一半����。
值得注意的是,為了確保有足夠的數(shù)據(jù)量來(lái)訓(xùn)練模型�����,針對(duì)不同的列需要有不同的缺失值判斷策略���。
在Python中,尤其Pandas�����、Numpy�、Scikit-Learn模塊中,我們用NaN來(lái)標(biāo)記缺失值����。值為NaN的數(shù)據(jù)均不參與如求和、計(jì)數(shù)類(lèi)的運(yùn)算�����。
在Pandas的DataFrame中,通過(guò)replace()函數(shù)可以很方便的將我們感興趣的數(shù)據(jù)子集的值標(biāo)記為NaN��。
標(biāo)記完缺失值之后��,可以利用isnull()函數(shù)將數(shù)據(jù)集中所有的NaN值標(biāo)記為T(mén)rue����,然后就可以得到每一列中缺失值的數(shù)量了。
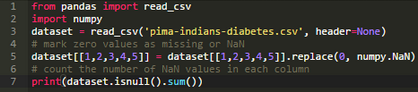
上述代碼打印了每一列中的缺失值����。結(jié)果顯示,第1-5列中標(biāo)記后的缺失值的數(shù)量和之前打印的0值的數(shù)量相等�����,這表明我們已經(jīng)正確識(shí)別了缺失值�����。
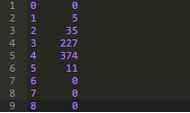
這是一個(gè)很有用的概要��。不過(guò)為了確保數(shù)據(jù)準(zhǔn)確��,我們通常還是會(huì)瀏覽一下原數(shù)據(jù)。
以下是代碼示例����,這里只打印了前二十條數(shù)據(jù)。
以上代碼運(yùn)行后����,我們可以很清楚地看到第2、3�、4、5列的NaN值���。由于第一列中只有5個(gè)缺失值,所以在前二十列中看不到值為NaN的情況也挺正常����。
從原數(shù)據(jù)中可以很清楚地看到,對(duì)缺失值進(jìn)行標(biāo)記達(dá)到了預(yù)期的效果�����。
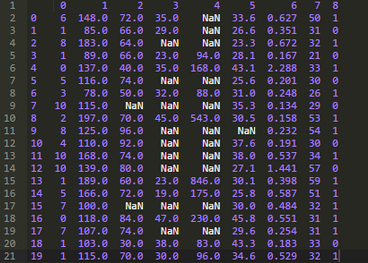
在開(kāi)始著手處理缺失值之前���,讓我們先來(lái)演示下存在缺失值的數(shù)據(jù)集將會(huì)帶來(lái)什么問(wèn)題����。
3、缺失值帶來(lái)的問(wèn)題
在一些機(jī)器學(xué)習(xí)算法中使用存在缺失值的數(shù)據(jù)集將會(huì)產(chǎn)生運(yùn)行錯(cuò)誤�。
在本節(jié)中,我們將嘗試評(píng)估帶有缺失值的數(shù)據(jù)對(duì)線(xiàn)性判別分析(LDA)算法的影響�����。當(dāng)數(shù)據(jù)集存在缺失值時(shí)���,該算法將停止工作���。
以下的代碼用上一部分的方法標(biāo)記了數(shù)據(jù)集中的缺失值,然后嘗試用3倍交叉驗(yàn)證來(lái)求LDA算法的值并打印其平均精度���。
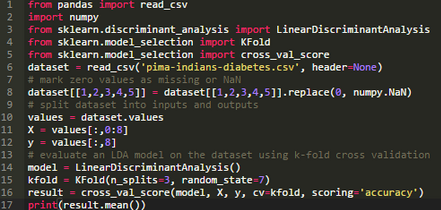
正如所料�����,代碼運(yùn)行過(guò)程中產(chǎn)生了如下錯(cuò)誤:

在有缺失值的數(shù)據(jù)集上應(yīng)用LDA算法(以及其他算法)求值的過(guò)程中我們碰到了問(wèn)題��。接下來(lái)�����,我們開(kāi)始學(xué)習(xí)處理缺失值的方法�。
4、刪除存在缺失值的行
處理缺失值最簡(jiǎn)單的策略是刪除存在缺失值的記錄���。通過(guò)創(chuàng)建一個(gè)刪除缺失值后的新的Pandas數(shù)據(jù)框可以實(shí)現(xiàn)以上效果�。Pandas的dropna()函數(shù)可以用來(lái)刪除存在缺失值的行或列���。如下所示��,利用dropna()函數(shù)我們可以刪除所有存在缺失值的行��。
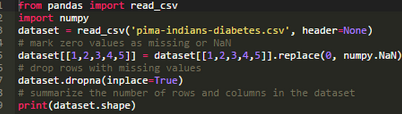
上述代碼運(yùn)行后��,由于所有存在NaN值的行全部被刪除了�,可以看到數(shù)據(jù)集的行數(shù)由原來(lái)的768大幅減少到392�����。

經(jīng)過(guò)處理后的數(shù)據(jù)集已經(jīng)可以應(yīng)用到LDA這類(lèi)對(duì)缺失值比較敏感的算法上來(lái)�����。
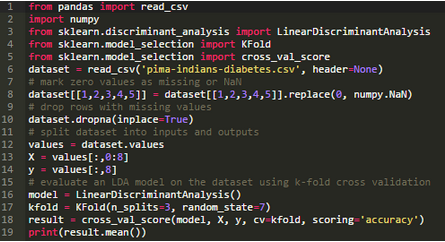
代碼運(yùn)行成功后會(huì)打印模型的預(yù)測(cè)精度�����。

刪除存在缺失值的行對(duì)部分預(yù)測(cè)模型來(lái)說(shuō)存在諸多局限性����,另一種方法是估算缺失值。
5�、估算缺失值
估算是指利用模型計(jì)算的結(jié)果來(lái)替代缺失值。
在進(jìn)行缺失值替換時(shí)我們有很多選擇�,例如:
在域內(nèi)具有含義且不同于所有其他值的一個(gè)常量,例如0
使用另一條隨機(jī)選取的記錄中的對(duì)應(yīng)值
該列的均值����、中值或者眾數(shù)
由另一個(gè)預(yù)測(cè)模型估算的值
對(duì)于訓(xùn)練數(shù)據(jù)及進(jìn)行的任何估算,必須在將來(lái)使用最終確定的模型進(jìn)行預(yù)測(cè)時(shí)���,對(duì)新的數(shù)據(jù)集執(zhí)行相同的操作���。
例如,如果你選擇使用列的均值進(jìn)行缺失值估算�,這些列的均值需要保存在文件中供將來(lái)存在缺失值的線(xiàn)數(shù)據(jù)集使用。
Pandas提供了fillna()函數(shù)來(lái)實(shí)現(xiàn)用特定值來(lái)替換缺失值��。
如下所示�����,通過(guò)fillna()函數(shù)我們用每列的均值替換了該列中的缺失值。
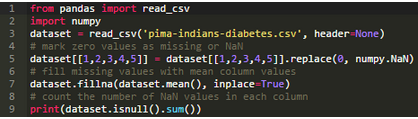
代碼的最后一行打印了每一列中的缺失值數(shù)量�����,結(jié)果顯示經(jīng)過(guò)處理已經(jīng)不存在缺失值了��。
scikit-learn庫(kù)提供了Imputer()預(yù)處理類(lèi)用來(lái)替換缺失值�����。
Impuer是一個(gè)很靈活的類(lèi)���,既可以用除了NaN之外的特定值替換缺失值����,也可以指定固定的運(yùn)算結(jié)果(如均值����、中值�、眾數(shù))來(lái)進(jìn)行替換。Imputer類(lèi)直接在NumPy的數(shù)組上進(jìn)行運(yùn)算而不是Pandas的DataFrame�。
下面的代碼利用Imputer類(lèi)使用每一列的均值對(duì)缺失值進(jìn)行了替換�,并打印了轉(zhuǎn)置矩陣中NaN值的數(shù)量���。
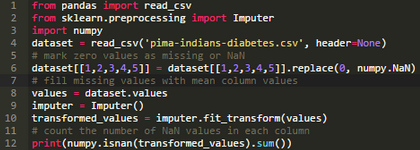
運(yùn)行結(jié)果顯示所有的NaN值均被成功替換��。

使用上述兩個(gè)方法的任意一種�����,我們都可以對(duì)轉(zhuǎn)化后的數(shù)據(jù)集中使用對(duì)NaN值敏感的算法進(jìn)行訓(xùn)練�����,如前面提到的LDA���。
下述代碼顯示了在使用估算方法轉(zhuǎn)換后的數(shù)據(jù)集上訓(xùn)練LDA算法的過(guò)程。
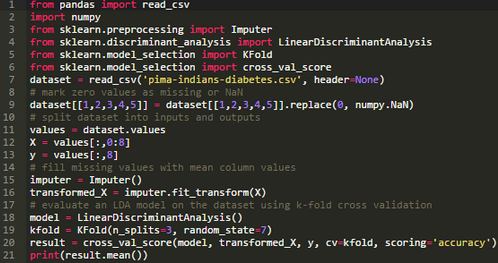
運(yùn)行結(jié)果打印出了使用轉(zhuǎn)換后數(shù)據(jù)集訓(xùn)練得出的LDA模型的平均精度����。

嘗試用其他數(shù)值來(lái)替換缺失值,然后看一下是否能夠提升模型的預(yù)測(cè)精度���。
在某些情景中���,數(shù)據(jù)集的缺失值具有一定的意義����。下一部分將會(huì)學(xué)習(xí)一些在建模過(guò)程中將缺失值作為“值”來(lái)處理的一些算法的運(yùn)用�����。
6�、支持存在缺失值數(shù)據(jù)集的一些算法
當(dāng)數(shù)據(jù)集中存在缺失值時(shí),并不是所有算法都會(huì)失效���。
有一些算法對(duì)缺失值的處理比較靈活�����,例如K最近鄰分類(lèi)算法(k-Nearest Neighbors)遇到缺失值時(shí)�,可以將其不計(jì)入距離測(cè)量�。
另外還有一類(lèi)算法在建立訓(xùn)練模型時(shí)會(huì)將數(shù)據(jù)集中的缺失值作為唯一的數(shù)值來(lái)處理,例如分類(lèi)和回歸樹(shù)算法�����。
不幸的是�,盡管已經(jīng)在考慮當(dāng)中����,scikit-learn模塊中決策樹(shù)和K最近鄰分類(lèi)算法的應(yīng)用中對(duì)缺失值的處理并不夠健壯���。
即便如此,如果你準(zhǔn)備使用諸如xgboost之類(lèi)的其他算法實(shí)現(xiàn)或者開(kāi)發(fā)自己的算法�����,這仍然是一個(gè)選擇��。
總結(jié)
在本教程中�����,你學(xué)習(xí)了如何處理機(jī)器中存在缺失值的數(shù)據(jù)集��。
具體來(lái)說(shuō)����,你學(xué)到了:
如何將數(shù)據(jù)集中的缺失值標(biāo)記為numpy的NaN值
如何刪除數(shù)據(jù)集中存在缺失值的行
如何使用有意義的數(shù)值替代數(shù)據(jù)集中的缺失值
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫(kù)��,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�����;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330