入門級攻略:機器學(xué)習(xí) VS. 深度學(xué)習(xí)
機器學(xué)習(xí)和深度學(xué)習(xí)現(xiàn)在很火,你會發(fā)現(xiàn)突然間很多人都在談?wù)撍鼈?�。如下圖所示���,機器學(xué)習(xí)和深度學(xué)習(xí)的趨勢對比(來自Google trend�,縱軸表示搜索熱度):
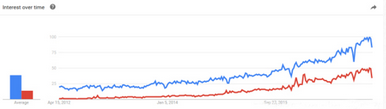
本文將會以簡單易懂的語言及示例為大家詳細解釋深度學(xué)習(xí)和機器學(xué)習(xí)的區(qū)別��,并介紹相關(guān)用途。
機器學(xué)習(xí)和深度學(xué)習(xí)簡介
機器學(xué)習(xí)
Tom Mitchell 關(guān)于機器學(xué)習(xí)的定義被廣泛引用�����,如下所示:
對于某類任務(wù)T和性能度量P����,如果一個計算機程序在T上以P衡量的性能隨著經(jīng)驗E而不斷自我完善�����,那么我們稱這個計算機程序在從經(jīng)驗E學(xué)習(xí)�����。
“A
computer program is said to learn from experience E with respect to
some class of tasks T and performance measure P if its performance at
tasks in T, as measured by P, improves with experience E ”
上面的抽象定義可能使你感到困惑����,相信下面幾個簡單的示例會讓你恍然大悟。
【例1 根據(jù)身高預(yù)測體重】
假設(shè)你要創(chuàng)建一個根據(jù)人的身高預(yù)測體重的系統(tǒng)����。第一步是收集數(shù)據(jù),收集完之后畫出數(shù)據(jù)分布圖如下所示���。圖中的每個點都代表一條數(shù)據(jù)����,橫坐標表示身高,縱坐標表示體重���。
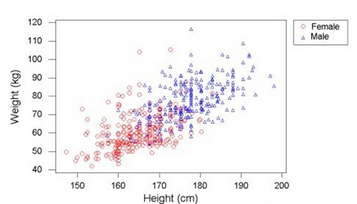
我們可以畫一條簡單的直線來根據(jù)身高預(yù)測體重��,比如:
Weight (in kg) = Height (in cm) – 100
如果這條直線預(yù)測身高很準確�,那怎樣來衡量它的性能呢���?比如以預(yù)測值和真實值之間的差值來衡量預(yù)測模型的性能。當(dāng)然���,源數(shù)據(jù)越多����,模型效果就越好�。如果效果不好,那么可以使用其他方法來提升模型性能�,如增加變量(如性別)或者改變預(yù)測直線。
【例2 風(fēng)暴預(yù)測系統(tǒng)】
假定要構(gòu)建一個風(fēng)暴預(yù)測系統(tǒng)���,你手頭上有過去發(fā)生的風(fēng)暴數(shù)據(jù)以及這些風(fēng)暴發(fā)生前三個月的天氣數(shù)據(jù)����。那么怎樣構(gòu)建一個風(fēng)暴預(yù)測系統(tǒng)呢?
首先要做的是清洗數(shù)據(jù)并找到數(shù)據(jù)中的隱藏模式���,比如導(dǎo)致風(fēng)暴產(chǎn)生的條件���。我們可以對一些條件建模,比如溫度是否大于40攝氏度����,濕度是否介于80到100之間,然后將這些特征輸入模型�。
你要做的就是充分利用歷史數(shù)據(jù),然后預(yù)測是否會產(chǎn)生風(fēng)暴����。在這個例子中,評價的指標是正確預(yù)測風(fēng)暴發(fā)生的次數(shù)�����。我們可以重復(fù)預(yù)測過程多次��,然后將性能結(jié)果返回系統(tǒng)。
回到最初機器學(xué)習(xí)的定義�,我們將風(fēng)暴預(yù)測系統(tǒng)定義如下:任務(wù)T是找到造成風(fēng)暴的大氣條件,性能P是在模型參數(shù)學(xué)習(xí)好之后��,正確預(yù)測的次數(shù)��,經(jīng)驗E是系統(tǒng)的迭代過程�。
深度學(xué)習(xí)
深度學(xué)習(xí)其實很早之前就出現(xiàn)了,隨著近幾年的炒作�,又逐漸火起來了。
深度學(xué)習(xí)是一種特殊的機器學(xué)習(xí)�����,它將現(xiàn)實世界表示為嵌套的層次概念體系(由較簡單概念間的聯(lián)系定義復(fù)雜概念�����,從一般抽象概括到高級抽象表示)�����,從而獲得強大的性能與靈活性��。
Deep
learning is a particular kind of machine learning that achieves great
power and flexibility by learning to represent the world as nested
hierarchy of concepts, with each concept defined in relation to simpler
concepts, and more abstract representations computed in terms of less
abstract ones.
【例1 圖形檢測】
假設(shè)我們要將矩形和其他圖形區(qū)別開���。人眼首先是檢測這個圖形是否有4條邊(簡單概念)��。如果有4條邊���,在檢測它們是否相連,閉合且垂直��,以及是否相等(嵌套層次概念)���。事實上����,我們將一個復(fù)雜的任務(wù)(矩形識別)分解成一些簡單低抽象層次的任務(wù)�。深度學(xué)習(xí)本質(zhì)上是在更大的范圍內(nèi)做這件事。

【例2 貓還是狗】
這個案例是構(gòu)建一個能夠識別圖片中動物是貓或者狗的系統(tǒng)�����。
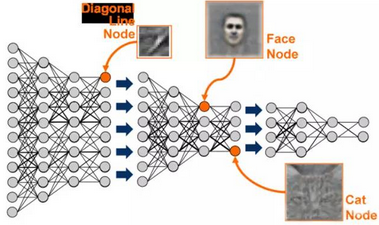
如果使用機器學(xué)習(xí)解決這個問題�,首先要定義一些特征,比如該動物是否有胡須����、耳朵���;如果有耳朵,那么耳朵是否是尖的���。簡單地說�����,我們要定義面部特征����,然后讓系統(tǒng)識別出在動物分類中哪些是重要特征�。而深度學(xué)習(xí)會一次性完成這些任務(wù),深度學(xué)習(xí)會自動找到對分類任務(wù)重要的特征��,而機器學(xué)習(xí)不得不人工指定�����。
深入學(xué)習(xí)工作流程如下:
1. 首先在圖片中找到和貓或者狗最相關(guān)的邊界�����;
2. 然后找到形狀和邊界的組合�,如是否能找到胡須和耳朵;
3. 在復(fù)雜概念的連續(xù)分層識別后����,就能夠確定哪些特征對識別貓狗起重要作用。
機器學(xué)習(xí)和深度學(xué)習(xí)的對比
數(shù)據(jù)依賴
深度學(xué)習(xí)和傳統(tǒng)機器學(xué)習(xí)最重要的區(qū)別是它的性能隨著數(shù)據(jù)量的增加而增強�。如果數(shù)據(jù)很少,深度學(xué)習(xí)算法性能并不好����,這是因為深度學(xué)習(xí)算法需要大量數(shù)據(jù)才能很好理解其中蘊含的模式。這種情況下����,使用人工指定規(guī)則的傳統(tǒng)機器學(xué)習(xí)占據(jù)上風(fēng)。如下圖所示:
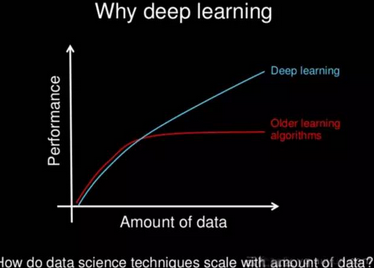
硬件支持
深度學(xué)習(xí)算法嚴重依賴于高端機�����,而傳統(tǒng)機器學(xué)習(xí)在低端機上就可以運行�����。因為深度學(xué)習(xí)需要進行大量矩陣乘法操作�,而GPU可以有效優(yōu)化這些操作,所以GPU成為其中必不可少的一部分。
特征工程
特征工程將領(lǐng)域知識輸入特征提取器�,降低數(shù)據(jù)復(fù)雜度,使數(shù)據(jù)中的模式對學(xué)習(xí)算法更加明顯����,得到更優(yōu)秀的結(jié)果。從時間和專業(yè)性方面講����,這個過程開銷很高。機器學(xué)習(xí)中�,大部分使用的特征都是由專家指定或根據(jù)先驗知識確定每個數(shù)據(jù)域和數(shù)據(jù)類型。比如�,特征可以是像素值,形狀�,紋理,位置�����,方向�。大多數(shù)機器學(xué)習(xí)方法的性能依賴于識別和抽取這些特征的準確度。
深度學(xué)習(xí)算法試圖從數(shù)據(jù)中學(xué)習(xí)高層特征����,這是深度學(xué)習(xí)與眾不同的一部分���,同時也是超越傳統(tǒng)機器學(xué)習(xí)的重要一步�。深度學(xué)習(xí)將每個問題歸結(jié)為開發(fā)新特征提取器,如卷積神經(jīng)網(wǎng)絡(luò)在底層學(xué)習(xí)如邊和直線種種低層特征���,然后是面部部分特征��,最后是人臉的高層特征���。

問題解決方案
當(dāng)使用傳統(tǒng)機器學(xué)習(xí)方法解決問題時,經(jīng)常采取化整為零�����,分別解決��,再合并結(jié)果求解的策略�����。而深度學(xué)習(xí)主張end-to-end模型��,輸入訓(xùn)練數(shù)據(jù)�����,直接輸出最終結(jié)果,讓網(wǎng)絡(luò)自己學(xué)習(xí)如何提取關(guān)鍵特征����。
比如說你要進行目標檢測,需要識別出目標的類別并指出在圖中的位置��。

典型機器學(xué)習(xí)方法將這個問題分為兩步:目標檢測與目標識別��。首先��,使用邊框檢測技術(shù)�����,如grabcut�����,掃描全圖找到所有可能的對象��,對這些對象使用目標識別算法���,如HOG/SVM�����,識別出相關(guān)物體�����。
深度學(xué)習(xí)方法按照end-to-end方式處理這個問題�����,比如YOLO net通過卷積神經(jīng)網(wǎng)絡(luò)���,就能夠?qū)崿F(xiàn)目標的定位與識別。也就是原始圖像輸入到卷積神經(jīng)網(wǎng)絡(luò)中��,直接輸出圖像中目標的位置和類別����。
執(zhí)行時間
通常,深度學(xué)習(xí)需要很長時間訓(xùn)練���,因為深度學(xué)習(xí)中很多參數(shù)都需要遠超正常水平的時間訓(xùn)練�。ResNet大概需要兩周時間從零開始完成訓(xùn)練��,而機器學(xué)習(xí)只需要從幾秒到幾小時不等的訓(xùn)練時間。測試所需要的時間就完全相反�,深度學(xué)習(xí)算法運行需要很少的時間。然而��,和KNN(K近鄰��,一種機器學(xué)習(xí)算法)相比���,測試時間會隨著測試數(shù)據(jù)量的增加而增加���。不過并非所有的機器學(xué)習(xí)算法都需要很長時間,某些也只需要很少的測試時間��。
可解釋性
假定使用深度學(xué)習(xí)給文章自動評分���,你會發(fā)現(xiàn)性能會很不錯�����,并且接近人類評分水準����。但它不能解釋為什么給出這樣的分數(shù)��。在運行過程中,你可以發(fā)現(xiàn)深度神經(jīng)網(wǎng)絡(luò)的哪些節(jié)點被激活��,但你不知道這些神經(jīng)元是對什么進行建模以及這每層在干什么��,所以無法解釋結(jié)果���。
另一方面�����,機器學(xué)習(xí)算法如決策樹按照規(guī)則明確解釋每一步做出選擇的原因,因此像決策樹和線性/邏輯斯蒂回歸這類算法由于可解釋性良好���,在工業(yè)界應(yīng)用很廣泛�。
機器學(xué)習(xí)和深度學(xué)習(xí)應(yīng)用場景
Wiki上面介紹了一些機器學(xué)習(xí)的應(yīng)用領(lǐng)域:
1. 計算機視覺:如車牌號識別��,人臉識別����;
2. 信息檢索:如搜索引擎,文本檢索����,圖像檢索����;
3. 營銷:自動郵件營銷�,目標識別;
4. 醫(yī)療診斷:癌癥診斷����,異常檢測;
5. 自然語言處理:語義分析����,照片標記;
6. 在線廣告�,等等。
下圖總結(jié)了機器學(xué)習(xí)的應(yīng)用領(lǐng)域��,總的來說應(yīng)用范圍十分廣泛����。

谷歌是業(yè)內(nèi)有名的使用機器學(xué)習(xí)/深度學(xué)習(xí)的公司,如下圖所示�����,谷歌將深度學(xué)習(xí)應(yīng)用到不同的產(chǎn)品����。
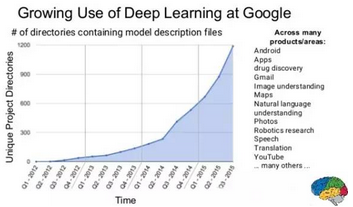
即時測試
為了評估你是否真正理解了機器學(xué)習(xí)和深度學(xué)習(xí)的區(qū)別��,這里將會有一個快速測試���,可以在這里提交答案。你要做的就是分別使用機器學(xué)習(xí)和深度學(xué)習(xí)解決下面的問題��,并決定哪個方法更好����。
【場景1】 假設(shè)你要開發(fā)一個無人駕駛汽車系統(tǒng),該系統(tǒng)以相機拍攝的原始數(shù)據(jù)作為輸入�,然后預(yù)測方向盤轉(zhuǎn)動的方向及角度�����。
【場景2】給定一個人的信用憑證和背景信息��,評估是否可以給他發(fā)放貸款�。
【場景3】創(chuàng)建一個將俄語文本翻譯為印度語的系統(tǒng)。
未來趨勢
前面總結(jié)了機器學(xué)習(xí)和深度學(xué)習(xí)的區(qū)別�,本節(jié)對二者未來趨勢:
1. 鑒于工業(yè)界使用數(shù)據(jù)科學(xué)和機器學(xué)習(xí)呈增加的趨勢,在業(yè)務(wù)中使用機器學(xué)習(xí)對那些想要生存下來的公司變得越發(fā)重要����。同時�����,了解更多的基礎(chǔ)知識也十分有必要�����。
2. 深度學(xué)習(xí)給人越來越多的驚喜�,將來也會一直是這樣�。深度學(xué)習(xí)被證明是已有技術(shù)中最先進的最好的技術(shù)之一。
3. 深度學(xué)習(xí)和機器學(xué)習(xí)和研究還在繼續(xù)����,不像以前那樣在學(xué)術(shù)界發(fā)展受限。目前機器學(xué)習(xí)和深度學(xué)習(xí)在工業(yè)界和學(xué)術(shù)界呈爆炸式發(fā)展�。并且受到比以前更多的基金支持,很有可能成為人類發(fā)展的關(guān)鍵點之一�����。
尾聲
本文將深度學(xué)習(xí)和機器學(xué)習(xí)進行了詳細對比�,希望能夠激勵大家去學(xué)到更多知識
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330