一、正態(tài)分布參數(shù)檢驗
例1. 某種原件的壽命X(以小時計)服從正態(tài)分布N(μ, σ)其中μ, σ2均未知?����,F(xiàn)測得16只元件的壽命如下:
159 280 101 212 224 379 179 264
222 362 168 250 149 260 485 170
問是否有理由認(rèn)為元件的平均壽命大于255小時���?
解:按題意�,需檢驗
H0: μ ≤ 225 H1: μ > 225
此問題屬于單邊檢驗問題
可以使用R語言t.test
t.test(x,y=NULL,
alternative=c("two.sided","less","greater"),
mu=0,paired=FALSE,var.equal=FALSE,
conf.level=0.95)
其中x,y是又?jǐn)?shù)據(jù)構(gòu)成e向量�����,(如果只提供x,則作單個正態(tài)總體的均值檢驗����,如果提供x,y則作兩個總體的均值檢驗),alternative表示被則假設(shè)��,two.sided(缺省)����,雙邊檢驗(H1:μ≠H0),less表示單邊檢驗(H1:μ<μ0),greater表示單邊檢驗(H1:μ>μ0)�����,mu表示原假設(shè)μ0����,conf.level置信水平�,即1-α,通常是0.95����,var.equal是邏輯變量,var.equal=TRUE表示兩樣品方差相同��,var.equal=FALSE(缺?��。┍硎緝蓸颖痉讲畈煌?��。
R代碼:
X<-c(159, 280, 101, 212, 224, 379, 179, 264,
222, 362, 168, 250, 149, 260, 485, 170)
t.test(X,alternative = "greater",mu=225)
結(jié)果:

可見P值為0.257 > 0.05 ,不能拒絕原假設(shè)����,接受H0,即平均壽命不大于225小時��。
例2.在平爐上進(jìn)行的一項試驗以確定改變操作方法的建議是否會增加剛的得率,試驗時在同一個平爐上進(jìn)行的��,每煉一爐剛時除操作方法外�����,其它條件都盡可能做到相同���,先用標(biāo)準(zhǔn)方法煉一爐,然后用新方法煉一爐��,以后交替進(jìn)行���,各煉了10爐�����,其得率分別為
標(biāo)準(zhǔn)方法 78.1 72.4 76.2 74.3 77.4 78.4 76.0 75.5 76.7 77.3
新方法 79.1 81.0 77.3 79.1 80.0 79.1 79.1 77.3 80.2 82.1
設(shè)這兩個樣本相互獨立����,且分別來自正態(tài)總體N(μ1, σ2)和N(μ2, σ2)��,其中μ1�����,μ2和σ2未知��。問新的操作能否提高得率?(取α=0.05)
解1:根據(jù)題意��,需要假設(shè)
H0: μ1 ≥ μ2 H1: μ1 < μ2
這里假定σ12=σ22=σ2��,因此選擇t.test,var.equal=TRUE
R代碼:
X<-c(78.1,72.4,76.2,74.3,77.4,78.4,76.0,75.5,76.7,77.3)
Y<-c(79.1,81.0,77.3,79.1,80.0,79.1,79.1,77.3,80.2,82.1)
t.test(X,Y,var.equal = TRUE,alternative = "less")
結(jié)果:

可見P值<0.05�,接受備擇假設(shè)�,即新的操作能夠提高得率���。
二、二項分布參數(shù)檢驗
例3.有一批蔬菜種子的平均發(fā)芽率p0=0.85����,現(xiàn)隨即抽取500粒,用種衣劑進(jìn)行浸種處理�,結(jié)果有445粒發(fā)芽。試檢驗種衣劑對種子發(fā)芽率有無效果�。
解:根據(jù)題意����,所檢驗的問題為
H0:p=p0=0.85����, H1:p≠p0
可以用R語言的binom.test
binom.test(x, n, p = 0.5,
alternative = c("two.sided", "less", "greater"),
conf.level = 0.95)
其中x是成功的次數(shù)���;或是一個由成功數(shù)和失敗數(shù)組成的二維向量��。n是試驗總數(shù)����,當(dāng)x是二維向量時,此值無效����。P是原假設(shè)的概率。
R語言代碼:
binom.test(445,500,p=0.85)
結(jié)果:

可知P值0.01207<0.05����,拒絕原假設(shè),說明種衣劑對種子的發(fā)芽率有顯著效果�����。
三��、其它重要的非參數(shù)檢驗法
3.1.理論分布完全已知的情況下
3.1.1.皮爾森擬合優(yōu)度檢驗
例5.某消費者協(xié)會為了確定市場上消費者對5種品牌啤酒的喜好情況����,隨即抽取了1000名啤酒愛好者作為樣品進(jìn)行試驗:每個人得到5種品牌的啤酒各一瓶,但未標(biāo)明牌子����。這5種啤酒分別按著A、B�����、C�����、D�����、E字母的5張紙片隨即的順序送給每一個人。下表是根據(jù)樣本資料整理的各種品牌啤酒愛好者的頻數(shù)分布�����。試根據(jù)這些數(shù)據(jù)判斷消費者對這5種品牌啤酒的愛好有無明顯差異����?
最喜歡的牌子 A B C D E
人數(shù)X 210 312 170 85 223
解:如果消費者對5種品牌的啤酒無顯著差異,那么���,就可以認(rèn)為喜好這5種拍品啤酒的人呈均勻分布�,即5種品牌啤酒愛好者人數(shù)各占20%�。據(jù)此假設(shè)
H0:喜好5種啤酒的人數(shù)分布均勻
可以使用Pearson χ2擬合優(yōu)度檢驗,R語言中調(diào)用chisq.test(X)
chisq.test(x, y = NULL, correct = TRUE,
p = rep(1/length(x), length(x)), rescale.p = FALSE,
simulate.p.value = FALSE, B = 2000)
其中x是由觀測數(shù)據(jù)構(gòu)成的向量或者矩陣���,y是數(shù)據(jù)向量(當(dāng)x為矩陣時����,y無效)����。correct是邏輯變量����,標(biāo)明是否用于連續(xù)修正��,TRUE(缺省值)表示修正�����,F(xiàn)ALSE表示不修正����。p是原假設(shè)落在小區(qū)間的理論概率�����,缺省值表示均勻分布���,rescale.p是邏輯變量����,選擇FALSE(缺省值)時�����,要求輸入的p滿足和等于1;選擇TRUE時�,并不要求這一點,程序?qū)⒅匦掠嬎鉷值����。simulate.p.value邏輯變量(缺省值為FALSE),當(dāng)為TRUE��,將用仿真的方法計算p值����,此時,B表示仿真的此值。
R語言代碼:
X<-c(210, 312, 170, 85, 223)
chisq.test(X)
結(jié)果:

3.1.2.正態(tài)W檢驗
例7.已知15名學(xué)生體重如下��,問是否服從正態(tài)分布

解:
R語言代碼:
w <- c(75.0, 64.0, 47.4, 66.9, 62.2, 62.2, 58.7, 63.5,
66.6, 64.0, 57.0, 69.0, 56.9, 50.0, 72.0)
shapiro.test(w)
P值>0.05�,接受原假設(shè),認(rèn)為來自正態(tài)分布總體�。
3.2.理論分布依賴于若干個未知參數(shù)的情況
3.2.1Kolmogorov-Smirnov 檢驗
例8.對一臺設(shè)備進(jìn)行壽命檢驗,記錄10次無故障工作時間��,并按從小到大的次序排列如下:(單位)
420 500 920 1380 1510 1650 1760 2100 2300 2350
試用Kolmogorov-Smirnov K 檢驗方法檢驗此設(shè)備無故障工作時間分布是否服從λ = 1/1500的指數(shù)分布��?
解: R語言進(jìn)行Kolmogorov-Smirnov K 檢驗使用ks.test( )
ks.test(x, y, ...,
alternative = c("two.sided", "less", "greater"),
exact = NULL) # x是待檢測的樣品構(gòu)成的向量����,y是原假設(shè)的數(shù)據(jù)向量或是原假設(shè)的字符串�。
R語言代碼:
X<-c(420, 500, 920, 1380, 1510, 1650, 1760, 2100, 2300, 2350)
ks.test(X, "pexp", 1/1500)

P值大于0.05���,無法拒絕原假設(shè)�,因此認(rèn)為此設(shè)備無故障工作時間的分布服從λ = 1/1500的指數(shù)分布����。
例9.假定從分布函數(shù)未知的F(x)和G(x)的總體中分別抽出25個和20個觀察值的隨即樣品���,其數(shù)據(jù)由下表所示?,F(xiàn)檢驗F(x)和G(x)是否相同���。
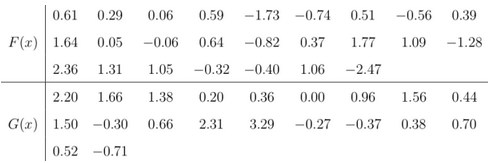
R語言代碼:
X<-scan( )
0.61 0.29 0.06 0.59 -1.73 -0.74 0.51 -0.56
1.64 0.05 -0.06 0.64 -0.82 0.37 1.77
2.36 1.31 1.05 -0.32 -0.40 1.06 -2.47
0.39 1.09 -1.28
Y<-scan( )
2.20 1.66 1.38 0.20 0.36 0.00
0.96 1.56 0.44 1.50 -0.30 0.66
2.31 3.29 -0.27 -0.37 0.38 0.70
0.52 -0.71
ks.test(X,Y)
P值>0.05,無法拒絕原假設(shè)���,說明F(x)和G(x)分布函數(shù)相同。
3.2.2.列聯(lián)表數(shù)據(jù)的檢驗
例10.為了研究吸煙是否與患肺癌相關(guān)�����,對63位肺癌患者及43名非肺癌患者(對照組)調(diào)查了其中的吸煙人數(shù)�����,得到2x2列聯(lián)表,如下表所示

解:
進(jìn)行Pearson卡方檢驗
R語言代碼:
x<-c(60, 3, 32, 11)
dim(x)<- c(2,2)
chisq.test(x,correct = F)

P值<0.05����,拒絕原假設(shè),認(rèn)為吸煙與患肺癌相關(guān)����。
3.2.3.符號檢驗
例13.聯(lián)合國人員在世界上66個大城市的生活花費指數(shù)(以紐約市1996年12月為100)按自小至大的次序排列如下(這里北京的指數(shù)為99):
66 75 78 80 81 81 82 83 83 83 83
84 85 85 86 86 86 86 87 87 88 88
88 88 88 89 89 89 89 90 90 91 91
91 91 92 93 93 96 96 96 97 99 100
101 102 103 103 104 104 104 105 106 109 109
110 110 110 111 113 115 116 117 118 155 192
假設(shè)這個樣品是從世界許多大城市中隨即抽樣得到的。試用符號檢驗分析�,北京是在中位數(shù)之上,還是在中位數(shù)之下����。
解:樣本的中位數(shù)(M)作為城市生活水平的中間值,因此需要檢驗:
H 0 : M ≥ 99, H 1 : M < 99.
輸入數(shù)據(jù)���,作二項檢驗�。
R語言代碼:
X <- c(66,75, 78 ,80 ,81 ,81 ,82, 83, 83, 83, 83,
84 , 85, 85, 86, 86, 86, 86, 87 ,87, 88, 88,
88, 88, 88, 89 ,89, 89, 89, 90 ,90 ,91 ,91,
91 ,91, 92, 93, 93, 96, 96, 96, 97, 99, 100,
101, 102, 103, 103 ,104, 104, 104 ,105, 106, 109, 109,
110 ,110, 110, 111, 113, 115, 116, 117 ,118, 155 ,192)
binom.test(sum(X>99), length(X), al="l")

在程序中�,sum(x>99)表示樣本中大于99的個數(shù)。al是alternative的縮寫���,"l"是"less"的縮寫���。計算出的P值小于0.05����,拒絕原假設(shè)���,也就是說��,北京的生活水平高于世界的中位水平���。
3.3.4.符號秩檢驗
例16.假定某電池廠宣稱該廠生產(chǎn)的某種型號電池壽命的中位數(shù)為140安培小時����。為了檢驗改廠生產(chǎn)的電池是否符合其規(guī)定的標(biāo)準(zhǔn),現(xiàn)從新近生產(chǎn)的一批電池中抽取了隨即樣本�,并對這20個電池的壽命進(jìn)行了測試,其結(jié)果如下(單位:安培小時):
137.0 140.0 138.3 139.0 144.3 139.1 141.7 137.3 133.5 138.2
141.1 139.2 136.5 136.5 135.6 138.0 140.9 140.6 136.3 134.1
試用Wilcoxon符號秩檢驗分析該廠生產(chǎn)的電池是否符合其標(biāo)準(zhǔn)����。
解:根據(jù)題意假設(shè):
H0:電池中位數(shù)M≥ 140安培小時;
H1:電池中位數(shù)<140安培小時�����。
在R語言中進(jìn)行符號秩檢驗可以使用wilcox.test( )
wilcox.test(x, y = NULL,
alternative = c("two.sided", "less", "greater"),
mu = 0, paired = FALSE, exact = NULL, correct = TRUE,
conf.int = FALSE, conf.level = 0.95, ...)
其中x,y是觀察數(shù)據(jù)構(gòu)成的數(shù)據(jù)向量。alternative是備擇假設(shè)�,有單側(cè)檢驗和雙側(cè)檢驗,mu待檢參數(shù)���,如中位數(shù)M0.paired是邏輯變量���,說明變量x,y是否為成對數(shù)據(jù)。exact是邏輯變量����,說明是否精確計算P值,當(dāng)樣本量較小時��,此參數(shù)起作用��,當(dāng)樣本兩較大時�����,軟件采用正態(tài)分布近似計算P值����。correct是邏輯變量,說明是否對P值的計算采用連續(xù)性修正���,相同秩次較多時����,統(tǒng)計量要校正。conf.int是邏輯變量���,說明是否給出相應(yīng)的置信區(qū)間��。
R語言代碼:
X<-scan()
137.0 140.0 138.3 139.0 144.3 139.1 141.7 137.3 133.5 138.2 141.1 139.2 136.5 136.5 135.6 138.0 140.9 140.6 136.3 134.1
wilcox.test(X, mu=140, alternative="less",
exact=FALSE,correct=FALSE, conf.int=TRUE)

這里V=34是wicoxon的統(tǒng)計量����,P值<0.05���,即拒絕原假設(shè)��,接受備擇假設(shè),中位值小于小于140安培小時����。
例19.某醫(yī)院用某種藥物治療兩型慢性支氣管炎患者共216例,療效由下表所示�����,試分析該藥物對兩型慢性支氣管炎的治療是否相同。

解:我們想象各病人的療效用4個不同的值表示(1表示最好����,4表示最差),這樣就可以位這216名排序�����,因此��,可用Wilcoxon秩和檢驗來分析問題��。
R語言代碼:
x<-rep(1:4, c(62, 41, 14,11)); y<-rep(1:4, c(20, 37, 16, 15))
wilcox.test(x, y, exact=FALSE)

P值<0.05�����,拒絕原假設(shè)���,即認(rèn)為該藥物對兩型慢性支氣管炎的治療是不相同的����。因為數(shù)據(jù)有結(jié)點存在��,故無法精確計算P值�����,其參數(shù)為exact=FALSE。
3.3.5.二元數(shù)據(jù)相關(guān)檢驗
例20.某種礦石中兩種有用成分A�,B,取10個樣品���,每個樣品中成分A的含量百分?jǐn)?shù)x(%)���,及B的含量百分?jǐn)?shù)y(%)的數(shù)據(jù)下表所示,對兩組數(shù)據(jù)進(jìn)行相關(guān)性檢驗��。

解:進(jìn)行相關(guān)性檢驗��,在R語言中可以使用cor.test( )
cor.test(x, y,
alternative = c("two.sided", "less", "greater"),
method = c("pearson", "kendall", "spearman"),
exact = NULL, conf.level = 0.95, ...)
#其中x,y是數(shù)據(jù)長度相同的向量�,alternative是備擇假設(shè),缺省值為"two.sided"����,method是檢驗方法�����,缺省值是Pearson檢驗���,conf.level是置信區(qū)間水平��,缺省值為0.95
cor.test( )還有另一種使用格式
cor.test(formula,
data, subset, na.action, ...) #其中formula是公式����,形如'~u+v' , 'u', 'v'
必須是具有相同長度的數(shù)值向量,data是數(shù)據(jù)框��,subset是可選擇向量�����,表示觀察值的子集��。
假設(shè)此例中兩組數(shù)據(jù)均來自正態(tài)分布���,使用pearson相關(guān)性檢驗���,
R語言代碼:
ore<-data.frame(
x=c(67, 54, 72, 64, 39, 22, 58, 43, 46, 34),
y=c(24, 15, 23, 19, 16, 11, 20, 16, 17, 13)
)
cor.test(ore$x,ore$y)

可見P值<0.05,拒絕原假設(shè),認(rèn)為X與Y相關(guān)��。
例21.一項有六個人參加表演的競賽�����,有兩人進(jìn)行評定,評定結(jié)果用下表所示�,試用Spearman秩相關(guān)檢驗方法檢驗這兩個評定員對等級評定有無相關(guān)關(guān)系。數(shù)據(jù)分析師培訓(xùn)

解:
R語言代碼:
x<-c(1,2,3,4,5,6); y<-c(6,5,4,3,2,1)
cor.test(x, y, method = "spearman")

可見P值<0.05�,拒絕原假設(shè),認(rèn)為x與y相關(guān)�,rs=-1,表示這兩個量是完全負(fù)相關(guān)����,即兩人的結(jié)論有關(guān)系,但完全相反���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330