R語(yǔ)言中plyr包
apply族函數(shù)是R語(yǔ)言中很有特色的一類函數(shù)���,包括了apply、sapply�����、lapply�����、tapply���、aggregate等等。這一類函數(shù)本質(zhì)上是將數(shù)據(jù)進(jìn)行分割�、計(jì)算和整合。它們?cè)跀?shù)據(jù)分析的各個(gè)階段都有很好的用處。例如在數(shù)據(jù)準(zhǔn)備階段��,我們可以按某個(gè)標(biāo)準(zhǔn)將數(shù)據(jù)分組����,然后獲得各組的統(tǒng)計(jì)描述?��;蚴窃诮kA段���,為不同組的數(shù)據(jù)建立模型并比較建模結(jié)果。apply族函數(shù)與Google提出的mapreduce策略有著一致的思路���。因?yàn)閙apreduce的思路也是將數(shù)據(jù)進(jìn)行分割�、計(jì)算和整合����。只不過它是將分割后的數(shù)據(jù)分發(fā)給多個(gè)處理核心進(jìn)行運(yùn)算。如果你熟悉了apply族函數(shù)���,那么將數(shù)據(jù)轉(zhuǎn)為并行運(yùn)算是輕而易舉的事情�。plyr包則可看作是apply族函數(shù)的擴(kuò)展��,使之更容易運(yùn)用,功能更為強(qiáng)大���。
??plyr包的主函數(shù)是**ply形式的��,其中首字母可以是(d����、l�����、a)���,第二個(gè)字母可以是(d����、l�、a�����、_)���,不同的字母表示不同的數(shù)據(jù)格式��,d表示數(shù)據(jù)框格式�,l表示列表,a表示數(shù)組���,_則表示沒有輸出���。第一個(gè)字母表示輸入的待處理的數(shù)據(jù)格式,第二個(gè)字母表示輸出的數(shù)據(jù)格式��。例如ddply函數(shù)��,即表示輸入一個(gè)數(shù)據(jù)框��,輸出也是一個(gè)數(shù)據(jù)框����。
??plyr包是Hadley Wickham大神為解決split – apply – combine問題而寫的一個(gè)包,其動(dòng)機(jī)在與提供超越for循環(huán)和內(nèi)置的apply函數(shù)族的一個(gè)一攬子解決方案����。使用plyr包可以針對(duì)不同的數(shù)據(jù)類型,在一個(gè)函數(shù)內(nèi)同時(shí)完成split – apply – combine三個(gè)步驟�。
??plyr 的功能已經(jīng)遠(yuǎn)遠(yuǎn)超出數(shù)據(jù)整容的范圍��,Hadley在plyr中應(yīng)用了split-apply-combine的數(shù)據(jù)處理哲學(xué)��,即:先將數(shù)據(jù)分離����,然后應(yīng)用某些處理函數(shù)���,最后將結(jié)果重新組合成所需的形式返回���。某些人士喜歡用“揉”來(lái)表述這樣的數(shù)據(jù)處理;“揉”�����,把數(shù)據(jù)當(dāng)面團(tuán)搗來(lái)?yè)v去��,很哲�����,磚家們的磚頭落下來(lái)���,拍死人絕不償命�����。
??先別哲了�����,來(lái)點(diǎn)實(shí)際的:plyr的函數(shù)命名方式比較規(guī)律����,很容易記憶和使用�。比如 a開頭的函數(shù)aaply, adply 和 alply 將數(shù)組(array)分別轉(zhuǎn)成數(shù)組、數(shù)據(jù)框和列表��;daply, ddply 和 dlply 將數(shù)據(jù)框分別轉(zhuǎn)成數(shù)組��、數(shù)據(jù)框和列表��;而laply, ldaply, llply將列表(list)分別轉(zhuǎn)成數(shù)組����、數(shù)據(jù)框和列表。
目錄
?1. 數(shù)據(jù)轉(zhuǎn)換: split – apply – combine 模式
?2. 知識(shí)點(diǎn)_1
?3. 知識(shí)點(diǎn)_2
?4. 知識(shí)點(diǎn)_3
?5. 知識(shí)點(diǎn)_4
?6. 參考資料
數(shù)據(jù)轉(zhuǎn)換: split – apply – combine 模式
??按:這一篇是讀Hadley Wickham的文章The Split-Apply-Combine Strategy for Data Analysis的筆記���。
??在數(shù)據(jù)分析中��,有許多問題可以由類似的類型和方法步驟解決��,可稱之為模式��,設(shè)計(jì)模式或者分析模式�。下面要討論的是數(shù)據(jù)轉(zhuǎn)換的一個(gè)常用模式:split – apply – combine。其解決之道�����,在R語(yǔ)言中�,有3種方式:
??(1) for 顯式循環(huán),但是這種方式的缺點(diǎn)也很明顯,代碼長(zhǎng)��,易出錯(cuò)�����,也難以并行化���;
??(2) 拜R語(yǔ)言的向量計(jì)算特點(diǎn)所賜�,在R當(dāng)中�����,大多數(shù)問題不需要用顯示循環(huán)方式,而代之以base包中的apply函數(shù)族及其它的一些函數(shù)�����,直接對(duì)向量�,數(shù)組��,列表和數(shù)據(jù)框?qū)崿F(xiàn)循環(huán)的操作��。
??(3) Hadley Wickham大神覺得apply族還是不夠簡(jiǎn)潔���,所以開發(fā)了pylr包��,以更少的代碼來(lái)解決split – apply – combine問題���。
split – apply – combine 模式
??大型數(shù)據(jù)集通常是高度結(jié)構(gòu)化的,結(jié)構(gòu)使得我們可以按不同的方式分組���,有時(shí)候我們需要關(guān)注單個(gè)組的數(shù)據(jù)片斷��,有時(shí)需要聚合不同組內(nèi)的信息�����,并相互比較���。
??因此對(duì)數(shù)據(jù)的轉(zhuǎn)換��,可以采用split – apply – combine模式來(lái)進(jìn)行處理:
????split:把要處理的數(shù)據(jù)分割成小片斷���;
????apply:對(duì)每個(gè)小片斷獨(dú)立進(jìn)行操作;
????combine:把片斷重新組合����。
??利用這種模式解決問題在很多數(shù)據(jù)分析或編程問題中都會(huì)出現(xiàn):
????Python當(dāng)中,是map( )�����,filter( )����,reduce( );
????Google 有MapReduce�;
????R 當(dāng)中是split( ),*apply( )����,aggregate( )…��,以及plyr包����。
分劃:split函數(shù)
??在R當(dāng)中�����,split這個(gè)步驟是由split( )����,subset( )等等函數(shù)完成的����。
??下面主要介紹split這個(gè)函數(shù)。
??函數(shù)split()可以按照分組因子��,把向量�,矩陣和數(shù)據(jù)框進(jìn)行適當(dāng)?shù)姆纸M。它的返回值是一個(gè)列表�,代表分組變量每個(gè)水平的觀測(cè)。這個(gè)列表可以使用sapply(),lappy()進(jìn)行處理(apply – combine步驟)���,得到問題的最終結(jié)果���。
??split( )的基本用法是:group <- split(X,f)
??其中X 是待分組的向量��,矩陣或數(shù)據(jù)框����。f是分組因子����。
???例1:對(duì)向量分組
> library(MASS)
#使用Cars93數(shù)據(jù)集,利用其中的Origin變量(兩個(gè)水平)�����,對(duì)Price變量分組
> g<-split(Cars93$Price,Cars93$Origin)
#分組結(jié)果是個(gè)列表:
$USA
[1] 15.7 20.8 23.7 26.3 34.7 40.1 13.4 11.4 15.1 15.9 16.3 16.6 18.8 38.0
[15] 18.4 15.8 29.5 9.2 11.3 13.3 19.0 15.6 25.8 12.2 19.3 7.4 10.1 11.3
[29] 15.9 14.0 19.9 20.2 20.9 34.3 36.1 14.1 14.9 13.5 16.3 19.5 20.7 14.4
[43] 9.0 11.1 17.7 18.5 24.4 11.1
$`non-USA`
[1] 15.9 33.9 29.1 37.7 30.0 8.4 12.5 19.8 12.1 17.5 8.0 10.0 10.0 13.9
[15] 47.9 28.0 35.2 8.3 11.6 16.5 19.1 32.5 31.9 61.9 10.3 26.1 11.8 15.7
[29] 19.1 21.5 28.7 8.4 10.9 19.5 8.6 9.8 18.4 18.2 22.7 9.1 19.7 20.0
[43] 23.3 22.7 26.7
#計(jì)算組的長(zhǎng)度和組內(nèi)均值
> sapply(g,length) USA non-USA
48 45
> sapply(g,mean) USA non-USA
18.57292 20.50889
#用lapply也可以���,返回值是列表
> lapply(g,mean)
$USA
[1] 18.57292
$`non-USA`
[1] 20.50889
???例2:對(duì)矩陣分組(按列)
> m<-cbind(x=1:10,y=11:20)
> split(m,col(m))
$`1`
[1] 1 2 3 4 5 6 7 8 9 10
$`2`
[1] 11 12 13 14 15 16 17 18 19 20
???例3:對(duì)數(shù)據(jù)框進(jìn)行分組
#還是利用Cars93,它就是個(gè)數(shù)據(jù)框
g<-split(Cars93,Cars93$Origin)
#分組結(jié)果
> summary(g) Length Class Mode
USA 27 data.frame list
non-USA 27 data.frame list
??split還有一個(gè)逆函數(shù)���,unsplit,可以讓分組完好如初。在base包里和split功能接近的函數(shù)有cut(對(duì)屬性數(shù)據(jù)分劃),strsplit(對(duì)字符串分劃)以及subset(對(duì)向量��,矩陣或數(shù)據(jù)框按給定條件取子集)等��。
base包中的apply()函數(shù)族
??接下來(lái)的apply – combine步驟主要由apply函數(shù)族完成�。對(duì)于R的初學(xué)者來(lái)說(shuō),apply函數(shù)族以其強(qiáng)大的向量運(yùn)算功能���,把for循環(huán)語(yǔ)句送到了被遺忘的角落���,這種震撼效果���,無(wú)異于天賜神器。但是,這些冠以*apply的函數(shù)�����,也經(jīng)常讓人使用混亂,找不著方向。
??那么apply包括哪些函數(shù)呢�����?在 R console中鍵入??apply,可以看到在base包中包含如下函數(shù):(apply在別的包里還有起到各自功能的相關(guān)函數(shù)����,我們只看涉及數(shù)據(jù)轉(zhuǎn)換的這些個(gè))
apply :Apply Functions Over Array Margins
by :Apply a Function to a Data Frame Split by Factors
eapply :Apply a Function Over Values in an Environment
lapply :Apply a Function over a List or Vector
mapply :Apply a Function to Multiple List or Vector Arguments
rapply :Recursively Apply a Function to a List
tapply :Apply a Function Over a Ragged Array
??除此之外�,還有可作為lapply變形的sapply,vapply和 replicate�����,共計(jì)10個(gè)函數(shù)���。具體的內(nèi)容�,見apply()函數(shù)族的詳細(xì)講解?����。。?br />
知識(shí)點(diǎn)_1
??(1)下面我們看看如何使用ldply函數(shù)將ath1121501.db包中的KEGG列表數(shù)據(jù)轉(zhuǎn)成數(shù)據(jù)框:
> library(ath1121501.db)
> keggs <- as.list(ath1121501PATH[mappedkeys(ath1121501PATH)])
> head(ldply(keggs, paste, collapse='; '))
.id V1
1 261579_at 00190
2 261569_at 04712
3 261583_at 00010; 00020; 00290; 00620; 00650; 01100; 01110
4 261574_at 00903; 00945; 01100; 01110
5 261043_at 00051; 00520; 01100
6 261044_at 04122
??(2)對(duì)于簡(jiǎn)單的問題����,plyr和apply函數(shù)的效果差不多
> m <- matrix(c(1:4,1,4,1:6),ncol=3)
> apply(m,1,mean)
[1] 1.666667 3.333333 3.000000 4.000000
> aaply(m,1,mean)
1 2 3 4
1.666667 3.333333 3.000000 4.000000
??plyr包的函數(shù)較多,不再一一介紹�,更多用法請(qǐng)參考它的在線幫助,Hadley 也寫了很詳細(xì)的tutorial:http://plyr.had.co.nz/09-user/
知識(shí)點(diǎn)_2
??下面首先來(lái)用一個(gè)簡(jiǎn)單的例子說(shuō)明一下用法�����。還是用iris數(shù)據(jù)集,其中包括了一個(gè)分類變量和四個(gè)數(shù)值變量����。我們希望數(shù)據(jù)按不同類別,分別計(jì)算數(shù)值變量的均值�����。下面我們分別用三種方法來(lái)得到同樣的結(jié)果���。
library(plyr)
library(reshape2) # 用aggregate函數(shù)進(jìn)行數(shù)據(jù)匯總
aggregate(iris[1:4],list(iris$Species),mean) # 用reshape2包進(jìn)行數(shù)據(jù)匯總
data.melt <- melt(iris,id=c('Species'))
dcast(data.melt,Species~variable,mean) # 用ddply函數(shù)進(jìn)行數(shù)據(jù)匯總
# 原代碼是 ddply(iris,.(Species),function(df) mean(df[1:4]))
# 錯(cuò)誤在于數(shù)據(jù)框的統(tǒng)計(jì)應(yīng)該用colMeans
ddply(iris,.(Species),function(df) colMeans(df[1:4]))
# 這個(gè)例子并沒有顯示出什么優(yōu)勢(shì),但我們可以學(xué)習(xí)到plyr的基礎(chǔ)使用方式�����,即對(duì)于**ply這種格式的函數(shù)���,其第一個(gè)數(shù)據(jù)參數(shù)是數(shù)據(jù)源,其他參數(shù)可以用?來(lái)查詢.
??初看起來(lái)plyr包所具備的功能并不很出彩�,下面我們看一個(gè)略為復(fù)雜例子。還是用iris數(shù)據(jù)��,我們希望對(duì)每一種花做一個(gè)簡(jiǎn)單回歸��。
# 首先定義回歸函數(shù)
model <- function(x) {
lm(Petal.Length~Petal.Width,data=x)
} # 如果用普通的函數(shù)則需要如下的分割���、計(jì)算����、整合三個(gè)步驟共四條命令
# Split函數(shù)的作用是將數(shù)據(jù)框按照指定字段分組,但不做后續(xù)計(jì)算�����。lapply函數(shù)可以對(duì)每組數(shù)據(jù)都執(zhí)行同樣的算法����。Split和lapply兩者結(jié)合可以實(shí)現(xiàn)本案例�����。
pieces <- split(iris,list(iris$Species))
models <- lapply(pieces,model)
result <- lapply(models,coef) do.call('rbind',result) # 用plyr包只用下面兩個(gè)函數(shù)��,每個(gè)函數(shù)都內(nèi)置了分割�、計(jì)算、整合的功能����。
result1 <- dlply(iris,.(Species),model)
result2 <- ldply(result1,function(x) coef(x))
??plyr包中還有兩個(gè)比較特別的函數(shù),分別是rply和mply��,它們分別對(duì)應(yīng)的是replicate和mapply函數(shù)。
replicate(20,mean(runif(100)))
rdply(20, mean(runif(100)))
mapply(rnorm,mean=1:5,sd=1:5, n=2)
mdply(data.frame(mean = 1:5, sd = 1:5), rnorm, n = 2)
??最后我們來(lái)看一個(gè)mdply函數(shù)的應(yīng)用��,我們希望用神經(jīng)網(wǎng)絡(luò)包來(lái)為不同的花進(jìn)行分類�����,使用BP神經(jīng)網(wǎng)絡(luò)需要的一個(gè)參數(shù)就是隱藏層神經(jīng)元的個(gè)數(shù)�����。我們來(lái)嘗試用1到10這十個(gè)參數(shù)運(yùn)行模型十次�����,并觀察十個(gè)建模結(jié)果的預(yù)測(cè)準(zhǔn)確率�。但我們并不需要手動(dòng)運(yùn)行十次。而是使用mdply函數(shù)來(lái)完成這個(gè)任務(wù)��。
library(nnet) # 確定建模函數(shù)
nnet.m <- function(...) {
nnet(Species~.,data=iris,trace=F,...)
} # 確定輸入?yún)?shù)
opts <- data.frame(size=1:10,maxiter=50) # 建立預(yù)測(cè)準(zhǔn)確率的函數(shù)
accuracy <- function(mod,true) {
pred <- factor(predict(mod,type='class'),levels=levels(true))
tb <- table(pred,true)
sum(diag(tb))/sum(tb)
} # 用mlply函數(shù)建立包括10個(gè)元素的列表����,每個(gè)元素包括了一個(gè)建模結(jié)果
models <- mlply(opts,nnet.m) # 再用ldply函數(shù)讀取列表,計(jì)算后得到最終結(jié)果
ldply(models,'accuracy',true=iris$Species)
??下面是其他操作函數(shù)
each():each(min, max)等價(jià)于function(x) c(min = min(x), max = max(x))����。
colwise():colwise(median)將計(jì)算列的中位數(shù)����。
arrange():超級(jí)順手的函數(shù)�����,可以方便的給dataframe排序����。
rename():又是一個(gè)handy的函數(shù),按變量名而不是變量位置重命名����。
count():返回unique值�,等價(jià)于length(unique(**))。
match_df():方便的配合count()等���,選出符合條件的行��,有點(diǎn)像merge(…,all=F)的感覺����。
join():對(duì)于習(xí)慣SQL的童鞋���,可能比merge()用起來(lái)更順手吧(當(dāng)然也更快一點(diǎn))����,不過靈活性還是比不上merge()。
知識(shí)點(diǎn)_3
??pylr包的使用
(1)命名規(guī)則
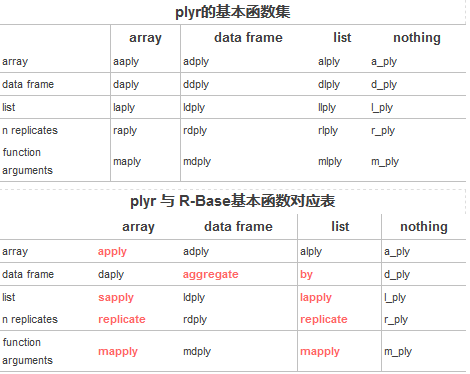
??命名規(guī)則:前三行是基本類型����。
??根據(jù)輸入類型和輸出類型:a=array,d=data frame����,l=list,_ 表示輸出放棄����。第一個(gè)字母表示輸入,第2個(gè)字母表示輸出�����。
??后兩行是對(duì)應(yīng)apply族的replicates和mapply這兩個(gè)函數(shù)�����,分別表示n次重復(fù)和多元函數(shù)參數(shù)的情況,第2個(gè)字母還是表示輸出類型�����。
??從命名特點(diǎn)來(lái)看����,我們不需要列出每個(gè)函數(shù)的情況了,只要從輸入和輸出兩方面分別討論即可����。
(2)參數(shù)說(shuō)明
a*ply(.data, .margins, .fun, ..., .progress = "none")
d*ply(.data, .variables, .fun, ..., .progress = "none")
l*ply(.data, .fun, ..., .progress = "none")
??這些函數(shù)有兩到三個(gè)主要的參數(shù),依賴于輸入的類型:
??參數(shù).data是我們要用來(lái)分片-計(jì)算-合并的�����;參數(shù).margins或者.variables描述了分片的方式�����;參數(shù).fun表示用來(lái)處理的函數(shù)��,其它更多的參數(shù)(...)是傳遞給處理函數(shù)的��;參數(shù).progress用來(lái)控制顯示一個(gè)進(jìn)度條�。
(3) 輸入
??輸入類型有三種,每一種類型給出了如何進(jìn)行分片的不同方法��。
??簡(jiǎn)單來(lái)說(shuō):
???a*ply( ):數(shù)組(包括矩陣和向量)按維數(shù)分為低維的片�。
???d*ply( ):數(shù)據(jù)框被變量組合分成子集。
???l*ply( ):列表的每個(gè)元素就是一個(gè)分片����。
??因此,對(duì)輸入數(shù)據(jù)集的分片���,不是取決于數(shù)據(jù)的結(jié)構(gòu)�,而是取決于所采用的方法�。
???1. 一個(gè)對(duì)象采用 a*ply( )分片必須對(duì)應(yīng)dim( )且接受多維的索引;
???2. 采用 d*ply( )分片�,要利用split( )并強(qiáng)制轉(zhuǎn)換為列表;
???3. 采用 l*ply( )����,需要用 length() and [[。
??所以數(shù)據(jù)框可以被傳遞給 a * ply( )���,可以象2維的矩陣那樣處理�����,也可以傳遞給l*ply( )�,被視為一個(gè)向量的列表。
??三種類型各自的特點(diǎn):
??(a): 輸入數(shù)組( a*ply() )
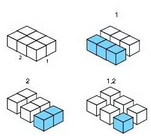
??a*ply()的分片特點(diǎn)在于.margins參數(shù)���,它和apply很相似��。對(duì)于2維數(shù)組�, .margins 可以取1����,2,或者c(1:2)�,對(duì)應(yīng)2維數(shù)組的3種分片方式。
? .margins = 1: Slice up into rows.
? .margins = 2: Slice up into columns.
? .margins = c(1,2): Slice up into individual cells.
??對(duì)于2維數(shù)組�����,則有3種分片方式:
??對(duì)于3維數(shù)組���,則有7種分片方式:
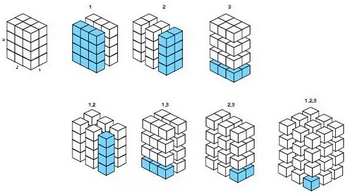
??.margins對(duì)應(yīng)更高維的情況�,可能會(huì)面臨一種爆發(fā)式的組合����。
??(b)輸入數(shù)據(jù)框( d*ply() )
??使用d*ply時(shí),需要特別指定分組所用的變量或變量函數(shù)��,它們會(huì)被首先計(jì)算�����,然后才是整個(gè)數(shù)據(jù)框����。
有下面幾種指定方式:
? .(var1)。按照變量var1的值來(lái)對(duì)數(shù)據(jù)框分組
? 多重變量 .(a,b,c)����。將按照三個(gè)變量的交互值來(lái)分組。
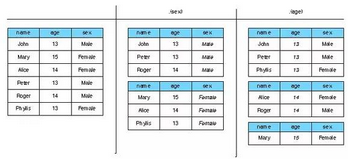
??這種形式輸出的時(shí)候�,有點(diǎn)復(fù)雜。如果輸出為數(shù)組�����,則數(shù)組會(huì)有三個(gè)維度�,分別以 a,b,c 的值作為維數(shù)名。如果輸出為數(shù)據(jù)框�����,將會(huì)包含 a,b,c 取值的三個(gè)額外的列。如果輸出為列表����,則列表元素名為按周期分割的 a,b,c 的值。
? 作為列名的字符向量:c("var1", "var2")�����。
? 公式~ var1 + var2���。
??(c) 輸入列表( l*ply() )
?? l * ply() 不需要描述如何分片的函數(shù)��,因?yàn)榱斜肀旧砭褪前凑赵氐姆謩?��。使用l * ply()相當(dāng)于a*ply()作用于一維數(shù)組的效果。
知識(shí)點(diǎn)_4
??plyr包案例集
??本文給出幾個(gè)關(guān)于使用plyr包來(lái)進(jìn)行數(shù)據(jù)處理的例子�����。重點(diǎn)在于plyr包的應(yīng)用�����,而不是深入地探討數(shù)據(jù)的分析�����。
1. 點(diǎn)球成金
??此例來(lái)源于 Wickham 的論文[ Hadley Wickham :The Split-Apply-Combine Strategy for Data Analysis Journal of Statistical Software�,April 2011, Volume 40, Issue 1. ]。案例里的圖形是我作的�����。
??布拉德.皮特在《點(diǎn)球成金》里用數(shù)據(jù)方法發(fā)掘棒球運(yùn)動(dòng)員的價(jià)值���,我們也可以來(lái)試試����。plyr 包的baseball數(shù)據(jù)集包括了1887-2007年間1228位美國(guó)職業(yè)棒球運(yùn)動(dòng)員15年以上的擊球記錄�。
> library(plyr)
> data(baseball)
> dim(baseball)
[1] 21699 22
??下面的分析,是要研究擊球手的表現(xiàn)�。
??關(guān)注四個(gè)變量:
id:運(yùn)動(dòng)員的身份;
year:紀(jì)錄的年份�;
rbi:跑壘得分,運(yùn)動(dòng)員在賽季內(nèi)的跑動(dòng)數(shù)目����;
ad:輪到擊球或者面對(duì)投手的次數(shù)。
??先來(lái)計(jì)算“職業(yè)年份”����,就是運(yùn)動(dòng)員開始職業(yè)生涯以來(lái)的年數(shù)����。
??對(duì)某一位運(yùn)動(dòng)員:
> baberuth <- subset(baseball, id == "ruthba01")
> # 在baberuth里加入cyear
> baberuth <- transform(baberuth, cyear = year - min(year) + 1)
??對(duì)所有的運(yùn)動(dòng)員:
> baseball <- ddply(baseball, .(id), transform, cyear = year - min(year) + 1)
??先看看Babe Ruth這位運(yùn)動(dòng)員的模式���,畫rbi/ab(每次擊球的跑動(dòng))的時(shí)間序列圖:
> library(ggplot2)
> cyear <- baberuth$cyear
> ra <- (baberuth$rbi)/(baberuth$ab)
> a <- data.frame(cyear,ra)
> p <- ggplot(a,aes(cyear,ra))
> p + geom_line()
> # 或者(畫圖代碼)
> # qplot(cyear, rbi / ab, data = baberuth, geom = "line")
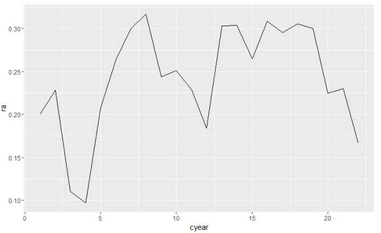
??下面使用d_ply函數(shù)按下面的方式對(duì)各位運(yùn)動(dòng)員們畫圖并保存為pdf格式:
??(1)按照運(yùn)動(dòng)員的平均rbi / ab值對(duì)運(yùn)動(dòng)員排序����,這樣確保如果某個(gè)圖畫不出的時(shí)候可以畫出其它的���。
??(2)只取ab大于25的運(yùn)動(dòng)員
> baseball <- subset(baseball, ab >= 25)
> xlim <- range(baseball$cyear, na.rm=TRUE)
> ylim <- range(baseball$rbi / baseball$ab, na.rm=TRUE)
> plotpattern <- function(df) {
+ qplot(cyear, rbi / ab, data = df, geom = "line", xlim = xlim, ylim = ylim)
+ }
> pdf("paths.pdf", width = 8, height = 4)
> d_ply(baseball, .(reorder(id, rbi / ab)), failwith(NA, plotpattern), .print = TRUE)
> dev.off()
??這些圖里能看出大概的線性趨勢(shì)���。來(lái)對(duì)每個(gè)運(yùn)動(dòng)員擬合一下線性模型。先看Babe Ruth的:
> model <- function(df) {
+ lm(rbi / ab ~ cyear, data = df)
+ }
> model(baberuth)
Call:
lm(formula = rbi/ab ~ cyear, data = df)
Coefficients:
(Intercept) cyear
0.203200 0.003413
??然后用dlply對(duì)所有的運(yùn)動(dòng)員:
> bmodels <- dlply(baseball, .(id), model)
??這樣共有1145個(gè)模型的列表��,下面提取這些模型的系數(shù)(slope and intercept)和R^2��,
> rsq <- function(x) summary(x)$r.squared
> bcoefs <- ldply(bmodels, function(x) c(coef(x), rsquare = rsq(x)))
> names(bcoefs)[2:3] <- c("intercept", "slope")
> head(bcoefs)
>
id intercept slope rsquare 1 aaronha01 0.18329371 0.0001478121 0.000862425 2 abernte02 0.00000000 NA 0.000000000
3 adairje01 0.08670449 -0.0007118756 0.010230121
4 adamsba01 0.05905337 0.0012002168 0.030184694 5 adamsbo03 0.08867684 -0.0019238835 0.108372596
6 adcocjo01 0.14564821 0.0027382939 0.229040266
??把所有模型的R^2繪直方圖:(代碼有問題�����??��?沒畫出來(lái)����?�??待修改)
> qplot(rsquare, data=bcoefs, geom="histogram", binwidth=0.01)
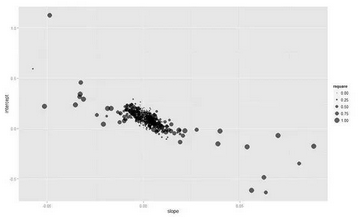
??可以看出這些模型整體來(lái)說(shuō)擬合的效果是很差的����。
??下面把那些擬合效果好的模型找出來(lái):先利用系數(shù)進(jìn)行“合并”,再挑出R^2為1的模型:
> baseballcoef <- merge(baseball, bcoefs, by = "id")
> subset(baseballcoef, rsquare > 0.999)$id
>
[1] "bannifl01" "bannifl01" "bedrost01" "bedrost01"
[5] "burbada01" "burbada01" "carrocl02" "carrocl02"
[9] "cookde01" "cookde01" "davisma01" "davisma01"
[13] "jacksgr01" "jacksgr01" "lindbpa01" "lindbpa01"
[17] "oliveda02" "oliveda02" "penaal01" "penaal01"
[21] "powerte01" "powerte01" "splitpa01" "splitpa01"
[25] "violafr01" "violafr01" "wakefti01" "wakefti01"
[29] "weathda01" "weathda01" "woodwi01" "woodwi01"
??所有這些擬合好的模型都只有兩個(gè)數(shù)據(jù)點(diǎn)����。
??換個(gè)角度看一下這些模型。
??繪制斜率和截距的散點(diǎn)圖:(代碼有問題��?���?��?沒畫出來(lái)�?���?��?待修改)
> p <- ggplot(bcoefs, aes(slope, intercept))
> p <- p + geom_point(aes( size = rsquare), alpha = 0.6)
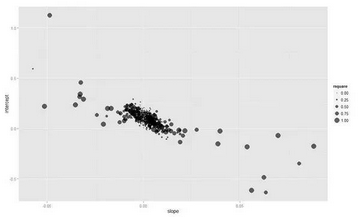
??放大局部:(代碼有問題��?��?�����?沒畫出來(lái)�??����?待修改)
> s <- subset(baseballcoef,slope>-0.01&slope<0.01)
> p <- ggplot(s, aes(slope, intercept))
> p <- p + geom_point(aes( size = rsquare), alpha = 0.6)
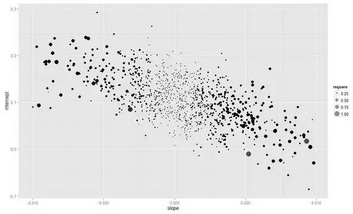
??可以看出,斜率和截距之間是負(fù)相關(guān)的���,且擬合壞的模型其估計(jì)值都接近于0��。
2. 起個(gè)好名字
??plyr包還有很多對(duì)于數(shù)據(jù)集操作的函數(shù)��。本文涉及summarise����,arrange,mutate
??數(shù)據(jù)集Baby name包括了美國(guó)從1880年到2008年間排名前1000位的嬰兒姓名�。數(shù)據(jù)集在課程主頁(yè)下載。
library(plyr)
library(ggplot2)
bnames <- read.csv("bnames2.csv.bz2")
births <- read.csv("births.csv")
# 先取一個(gè)名字看一看���,
steve<-subset(bnames,name == "Steve")
qplot(year, prop, data = steve, geom = "line")
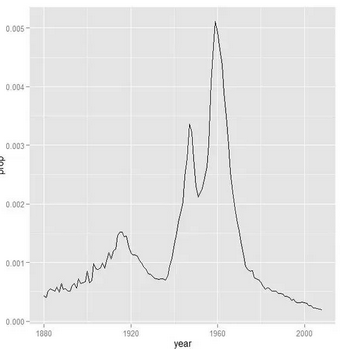
??蘋果教主生于1955年����,看來(lái)是個(gè)當(dāng)時(shí)的流行名字�。
# 在steve里求概括統(tǒng)計(jì)量
summarise(steve,least = year[prop == min(prop)],most = year[prop == max(prop)])
least most 1 2008 1959
# 按比例降序重排steve
arrange(steve, desc(prop)) # 在steve中增加一列per1000,取1000 * prop的整數(shù)
mutate(steve, per1000 = round(1000 * prop))
??下面來(lái)探索一下名字的趨勢(shì)�,
??這涉及到使用外部數(shù)據(jù)集��,下面合并bnames和 births
bnames2 <- join(bnames, births, by = c("year", "sex"))
bnames2 <- mutate(bnames2, n = round(prop * births))
??看看出生趨勢(shì)
qplot(year, births, data = births, geom = "line",color = sex)
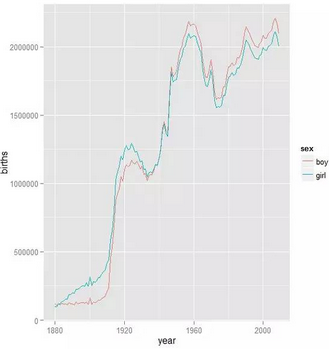
# 那些年���,有多少個(gè)steve出生呢
steve1<- subset(bnames2, name == "Steve")
summarise(steve1, sum(n))
sum(n) 1 237613數(shù)據(jù)分析師培訓(xùn)
# 對(duì)每個(gè)名字都算一下:(這就是split-apply-combine步驟了)
counts <- ddply(bnames2, "name", summarise, n=sum(n))
??把名字按數(shù)量重排一下:
best<-arrange(counts, desc(n))
??大眾款的名字是:
head(best)
name n 1 James 5043259
2 John 5036828
3 Robert 4771447
4 Michael 4226596
5 Mary 4111514
6 William 3966170
??稀有版:
tail(best)
name n 6777 Delina 4
6778 Delle 4
6779 Dema 4
6780 Dollye 4
6781 Eithel 4
6782 Elzada 4
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330