sas字符變量基于bad_rate分組
最近因?yàn)槟P蛿M合的不理想的原因�����,sas信用評(píng)分的內(nèi)容可能要停更一兩周了,因?yàn)槲疫€沒(méi)能進(jìn)行到模型評(píng)分卡這一步就被跨期驗(yàn)證給拍下來(lái)了�,我做的模型,訓(xùn)練的數(shù)據(jù)以及測(cè)試的數(shù)據(jù)指標(biāo)都還不錯(cuò)���,跨期驗(yàn)證指標(biāo)掉的厲害����。希望有經(jīng)驗(yàn)的大神可以在留言區(qū)給我點(diǎn)建議�����,因?yàn)槟銈兊慕ㄗh可以讓我少走很多彎路。我現(xiàn)在要重新調(diào)整�����,至于怎么調(diào)整的內(nèi)容�,我后面會(huì)做一個(gè)總結(jié)的文章,講對(duì)于指標(biāo)達(dá)不到指標(biāo)的時(shí)候可以有什么方便調(diào)整下指標(biāo)���,在這些方法之后還調(diào)整不了指標(biāo)的再回頭看變量。
這次分享的代碼是字符變量依據(jù)bad_rate做的一個(gè)分組�。之前分享過(guò)給予基尼系數(shù),給予iv值的��,那么這次就叫基于bad_rate的吧���。這次的代碼可能會(huì)比之前的代碼容易理解很多��,而這次的代碼也是我的partner陳先生寫(xiě)的�。不要問(wèn)我陳先生是誰(shuí)��,這是個(gè)秘密���。
%macrodatasplit(data,target,group);
proc sql;
create table csm_CASH_MODEL_Train_rank1(
table_name varchar(100)
,col_name varchar(50)
,rank_name numeric
,low numeric
,up numeric
,cnt numeric
,rate numeric
,n1 numeric
,bad_rate numeric
,woe numeric
,iv numeric
,split_type numeric);
quit;
proc sql;
create table csm_CASH_MODEL_Train_rank2(
table_name varchar(100)
,col_name varchar(50)
,rank_name varchar(2000)
,lownumeric ,, ,up numeric
,cnt numeric
,rate numeric
,n1 numeric
,bad_rate numeric
,woe numeric
,iv numeric
,split_type numeric);
quit;
proc sql;/*獲得總記錄數(shù)�����、總壞客戶(hù)數(shù)����、總好客戶(hù)數(shù)*/
select count(*),SUM(&target.),count(*)-SUM(&target.) into :record_cnt,
:bad_cnt,
:good_cnt
from &data.;
quit;
proc contents/*獲取輸入數(shù)據(jù)集的所有變量信息*/
data=&data.
out=CASH_SELECT_MODEL_VALID_V10_CONT
noprint;
run;
data CASH_SELECT_MODEL_VALID_V10_CONT;
set CASH_SELECT_MODEL_VALID_V10_CONT;
where name ^='&target.';
run;
data _null_;
set CASH_SELECT_MODEL_VALID_V10_CONT;
call symput(compress("numobs"),compress(_n_));
run;
%doi=1%to&numobs;
%put&NUMOBS.||&i.;
data _null_;
pointer=&i.;
set CASH_SELECT_MODEL_VALID_V10_CONT POINT=POINTER;
call symput('col_name', NAME);
call symput('TYPE', put(TYPE,1.));
stop;
run;
%if&TYPE.=2%then%do;
proc sql;
create table &col_name.as select
&col_name.
,sum(&target.)/count(1) as bad_rate
,sum(&target.) as &target.
,count(1) as num
from &data.
group by &col_name.;
quit;
%put&col_name;
%put&type;
proc sql;
select count(1) into:valuenum from &col_name;
quit;
%if&valuenum.>&group.%then%do;
proc rank data= &col_name out = data_rank ties = mean groups = &group.descending;
var bad_rate;
ranks group_name;
run;
proc sql;
create table &data.as
select *,
b.group_name as new_&col_name.
from &data.a
left join data_rank b
ona.&col_name.=b.&col_name.;
quit;
proc sql;
insert into csm_CASH_MODEL_Train_rank1(table_name ,col_name ,rank_name ,low ,up,cnt,rate,n1,bad_rate,woe,iv,split_type)
select"csm_CASH_MODEL_Train_rank","&col_name",group_name ,min(bad_rate) ,max(bad_rate) ,sum(num)
,sum(num)/&record_cnt
,sum(&target.)
,sum(&target.)/sum(num)
,log((ifn(sum(&target.)=0,0.001,sum(&target.))/&bad_cnt)/((sum(num)-sum(&target.))/&good_cnt))
,(sum(&target.)/&bad_cnt-(sum(num)-sum(&target.))/&good_cnt)*log((ifn(sum(&target.)=0,0.001,sum(&target.))/&bad_cnt)/((sum(num)-sum(&target.))/&good_cnt))
,&group.
from data_rank
group by group_name;
quit;
%end;
%if&valuenum.<=&group.%then%do;
proc sql;
insert into csm_CASH_MODEL_Train_rank2( table_name ,col_name ,rank_name ,low,up,cnt,rate ,n1 ,bad_rate,woe ,iv ,split_type)
select"csm_CASH_MODEL_Train_rank","&col_name",&col_name.,min(bad_rate) ,max(bad_rate) ,sum(num),sum(num)/&record_cnt
,sum(&target.),sum(&target.)/sum(num)
,log((ifn(sum(&target.)=0,0.001,sum(&target.))/&bad_cnt)/((sum(num)-sum(&target.))/&good_cnt))
,(sum(&target.)/&bad_cnt-(sum(num)-sum(&target.))/&good_cnt)*log((ifn(sum(&target.)=0,0.001,sum(&target.))/&bad_cnt)/((sum(num)-sum(&target.))/&good_cnt))
,&valuenum
from &col_name.
group by &col_name.;
quit;
%end;
%end;
%end;
data csm_CASH_MODEL_Train_rank1;
set csm_CASH_MODEL_Train_rank1;
rank_name1=put(rank_name,$8.);
drop rank_name;
rename rank_name1=rank_name;
run;
data csm_CASH_MODEL_Train_rank;
set csm_CASH_MODEL_Train_rank1 csm_CASH_MODEL_Train_rank2;
run;
%mend;
關(guān)于這個(gè)代碼的使用呢,就是下面這樣子啦���。
Data:填入你的數(shù)據(jù)集��,重點(diǎn)來(lái)啦�,這個(gè)數(shù)據(jù)集也是等下的產(chǎn)出的數(shù)據(jù)集��,所以你突然覺(jué)得�,慘了,我拿錯(cuò)數(shù)據(jù)集�����,那么你就得重新跑下這個(gè)數(shù)據(jù)集����,因?yàn)榻?jīng)過(guò)這個(gè)過(guò)程他已經(jīng)被改變了。
Target:因變量
Group;你要分的組數(shù)。
還有說(shuō)下這個(gè)代碼��,因?yàn)槭轻槍?duì)字符的分組�,就意味著要是有點(diǎn)變量的觀測(cè)情況就只用3種,那怎么分五組呢�,譬如性別啊,你活生生的要是把男女分成5組�����,這就不道德了哈�,所以代碼中對(duì)于觀測(cè)情況少于你的分組數(shù)的就不分組了。
說(shuō)下結(jié)果哈:
變量指標(biāo)統(tǒng)計(jì)表:

產(chǎn)出的表中就有圖中的這些指標(biāo)���,low以及up是bad_rate的區(qū)間。Cnt是分組統(tǒng)計(jì)的人數(shù)��,n1是壞客戶(hù)的數(shù)量��。后面的split_type是分成幾組�。宏里面設(shè)定的5組,所以顯示的是5�。
碼表:
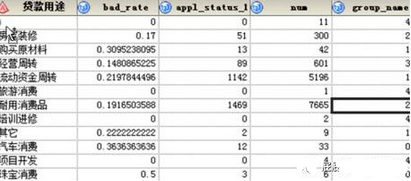
這張表是碼表。名字為每個(gè)變量的名字���,譬如你這個(gè)變量叫l(wèi)oan_cnt�,那么你找到一個(gè)數(shù)據(jù)叫l(wèi)oan_cnt就是loan_cnt的碼表。這個(gè)碼表不是你等下一個(gè)一個(gè)按照主表去leftjoin的哈�。這個(gè)主表只要是想你之后要生成評(píng)分或者做數(shù)據(jù)集驗(yàn)證的時(shí)候可以用的。數(shù)據(jù)分析師培訓(xùn)
最后就是主表:
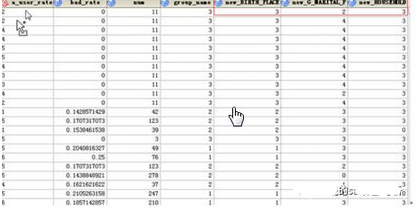
為什么剛才說(shuō)碼表不是主表連的呢�����,因?yàn)樯傻闹鞅砝锩嬉呀?jīng)有新的分組����,new_開(kāi)頭的就是新生成的變量。便于后面的區(qū)分�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)��,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情����;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330