大數(shù)據(jù)分析你不能不懂的6個核心技術
目前�,大數(shù)據(jù)領域每年都會涌現(xiàn)出大量新的技術���,成為大數(shù)據(jù)獲取、存儲���、處理分析或可視化的有效手段��。大數(shù)據(jù)技術能夠將大規(guī)模數(shù)據(jù)中隱藏的信息和知識挖掘出來�����,為人類社會經濟活動提供依據(jù)�����,提高各個領域的運行效率�����,甚至整個社會經濟的集約化程度����。
1大數(shù)據(jù)生命周期
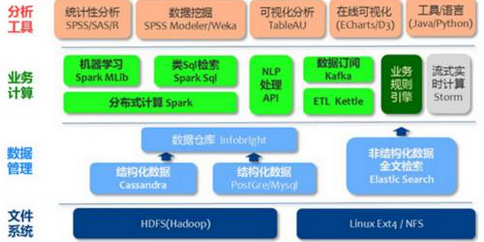
圖1 大數(shù)據(jù)技術棧
圖1展示了一個典型的大數(shù)據(jù)技術棧。底層是基礎設施��,涵蓋計算資源���、內存與存儲和網絡互聯(lián)��,具體表現(xiàn)為計算節(jié)點��、集群���、機柜和數(shù)據(jù)中心�����。在此之上是數(shù)據(jù)存儲和管理�,包括文件系統(tǒng)��、數(shù)據(jù)庫和類似YARN的資源管理系統(tǒng)����。然后是計算處理層,如Hadoop����、MapReduce和Spark,以及在此之上的各種不同計算范式�,如批處理、流處理和圖計算等�����,包括衍生出編程模型的計算模型�,如BSP���、GAS
等����。數(shù)據(jù)分析和可視化基于計算處理層。分析包括簡單的查詢分析��、流分析以及更復雜的分析(如機器學習��、圖計算等)��。查詢分析多基于表結構和關系函數(shù)�����,流分析基于數(shù)據(jù)���、事件流以及簡單的統(tǒng)計分析���,而復雜分析則基于更復雜的數(shù)據(jù)結構與方法,如圖���、矩陣����、迭代計算和線性代數(shù)。一般意義的可視化是對分析結果的展示�。但是通過交互式可視化,還可以探索性地提問��,使分析獲得新的線索����,形成迭代的分析和可視化?�;诖笠?guī)模數(shù)據(jù)的實時交互可視化分析以及在這個過程中引入自動化的因素是目前研究的熱點����。
有2個領域垂直打通了上述的各層,需要整體�����、協(xié)同地看待����。一是編程和管理工具,方向是機器通過學習實現(xiàn)自動最優(yōu)化����、盡量無需編程����、無需復雜的配置����。另一個領域是數(shù)據(jù)安全����,也是貫穿整個技術棧。除了這兩個領域垂直打通各層�����,還有一些技術方向是跨了多層的���,例如“內存計算”事實上覆蓋了整個技術棧�����。
2大數(shù)據(jù)技術生態(tài)
大數(shù)據(jù)的基本處理流程與傳統(tǒng)數(shù)據(jù)處理流程并無太大差異�,主要區(qū)別在于:由于大數(shù)據(jù)要處理大量�、非結構化的數(shù)據(jù),所以在各處理環(huán)節(jié)中都可以采用并行處理。目前����,Hadoop、MapReduce和Spark等分布式處理方式已經成為大數(shù)據(jù)處理各環(huán)節(jié)的通用處理方法�����。
Hadoop是一個能夠讓用戶輕松架構和使用的分布式計算平臺�����。用戶可以輕松地在Hadoop上開發(fā)和運行處理海量數(shù)據(jù)的應用程序�����。Hadoop
是一個數(shù)據(jù)管理系統(tǒng)�����,作為數(shù)據(jù)分析的核心�����,匯集了結構化和非結構化的數(shù)據(jù)���,這些數(shù)據(jù)分布在傳統(tǒng)的企業(yè)數(shù)據(jù)棧的每一層�。Hadoop也是一個大規(guī)模并行處理框架,擁有超級計算能力����,定位于推動企業(yè)級應用的執(zhí)行。Hadoop又是一個開源社區(qū)�����,主要為解決大數(shù)據(jù)的問題提供工具和軟件����。雖然Hadoop提供了很多功能���,但仍然應該把它歸類為多個組件組成的Hadoop生態(tài)圈�,這些組件包括數(shù)據(jù)存儲�����、數(shù)據(jù)集成��、數(shù)據(jù)處理和其他進行數(shù)據(jù)分析的專門工具��。圖2
展示了Hadoop
的生態(tài)系統(tǒng),主要由HDFS�、MapReduce、Hbase���、Zookeeper�、Oozie�����、Pig����、Hive等核心組件構成,另外還包括Sqoop��、Flume等框架����,用來與其他企業(yè)融合。同時����,Hadoop
生態(tài)系統(tǒng)也在不斷增長,新增Mahout�����、Ambari、Whirr�、BigTop 等內容,以提供更新功能����。
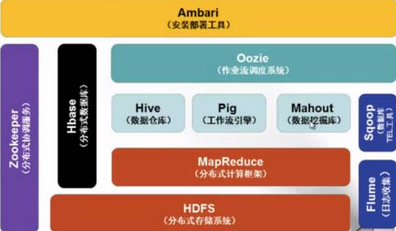
圖2 Hadoop生態(tài)系統(tǒng)
低成本、高可靠�、高擴展、高有效��、高容錯等特性讓Hadoop成為最流行的大數(shù)據(jù)分析系統(tǒng)��,然而其賴以生存的HDFS
和MapReduce
組件卻讓其一度陷入困境——批處理的工作方式讓其只適用于離線數(shù)據(jù)處理�����,在要求實時性的場景下毫無用武之地����。因此�����,各種基于Hadoop的工具應運而生。為了減少管理成本��,提升資源的利用率�,有當下眾多的資源統(tǒng)一管理調度系統(tǒng),例如Twitter
的Apache Mesos���、Apache 的YARN����、Google 的Borg�、騰訊搜搜的Torca、Facebook
Corona(開源)等�����。Apache Mesos是Apache孵化器中的一個開源項目����,使用ZooKeeper實現(xiàn)容錯復制,使用Linux
Containers
來隔離任務���,支持多種資源計劃分配(內存和CPU)��。提供高效����、跨分布式應用程序和框架的資源隔離和共享,支持Hadoop�����、MPI���、Hypertable�����、Spark
等�。YARN 又被稱為MapReduce 2.0�,借鑒Mesos�,YARN 提出了資源隔離解決方案Container,提供Java
虛擬機內存的隔離�。對比MapReduce
1.0,開發(fā)人員使用ResourceManager��、ApplicationMaster與NodeManager代替了原框架中核心的JobTracker
和TaskTracker��。在YARN平臺上可以運行多個計算框架����,如MR���、Tez、Storm��、Spark等�����。
基于業(yè)務對實時的需求����,有支持在線處理的Storm、Cloudar
Impala�����、支持迭代計算的Spark
及流處理框架S4��。Storm是一個分布式的�、容錯的實時計算系統(tǒng),由BackType開發(fā)�,后被Twitter捕獲。Storm屬于流處理平臺,多用于實時計算并更新數(shù)據(jù)庫���。Storm也可被用于“連續(xù)計算”(Continuous
Computation)��,對數(shù)據(jù)流做連續(xù)查詢�����,在計算時就將結果以流的形式輸出給用戶���。它還可被用于“分布式RPC”,以并行的方式運行昂貴的運算���。Cloudera
Impala是由Cloudera開發(fā)��,一個開源的Massively Parallel Processing(MPP)查詢引擎����。與Hive
相同的元數(shù)據(jù)�����、SQL語法��、ODBC 驅動程序和用戶接口(HueBeeswax)���,可以直接在HDFS 或HBase 上提供快速���、交互式SQL
查詢。Impala是在Dremel的啟發(fā)下開發(fā)的�,不再使用緩慢的Hive+MapReduce
批處理,而是通過與商用并行關系數(shù)據(jù)庫中類似的分布式查詢引擎(由Query Planner�����、Query Coordinator 和Query
Exec Engine這3部分組成)�,可以直接從HDFS 或者HBase 中用SELECT、JOIN 和統(tǒng)計函數(shù)查詢數(shù)據(jù)���,從而大大降低了延遲��。
Hadoop社區(qū)正努力擴展現(xiàn)有的計算模式框架和平臺�����,以便解決現(xiàn)有版本在計算性能��、計算模式���、系統(tǒng)構架和處理能力上的諸多不足�,這正是Hadoop2.0
版本“ YARN”的努力目標����。各種計算模式還可以與內存計算模式混合,實現(xiàn)高實時性的大數(shù)據(jù)查詢和計算分析����。混合計算模式之集大成者當屬UC
Berkeley AMP Lab 開發(fā)的Spark生態(tài)系統(tǒng)�,如圖3所示。Spark 是開源的類Hadoop
MapReduce的通用的數(shù)據(jù)分析集群計算框架�,用于構建大規(guī)模、低延時的數(shù)據(jù)分析應用����,建立于HDFS之上。Spark提供強大的內存計算引擎��,幾乎涵蓋了所有典型的大數(shù)據(jù)計算模式���,包括迭代計算���、批處理計算、內存計算��、流式計算(Spark
Streaming)�����、數(shù)據(jù)查詢分析計算(Shark)以及圖計算(GraphX)�。Spark 使用Scala
作為應用框架,采用基于內存的分布式數(shù)據(jù)集�����,優(yōu)化了迭代式的工作負載以及交互式查詢��。與Hadoop 不同的是�����,Spark 和Scala
緊密集成�����,Scala 像管理本地collective
對象那樣管理分布式數(shù)據(jù)集�。Spark支持分布式數(shù)據(jù)集上的迭代式任務,實際上可以在Hadoop文件系統(tǒng)上與Hadoop一起運行(通過YARN����、Mesos等實現(xiàn))�����。另外����,基于性能���、兼容性�����、數(shù)據(jù)類型的研究��,還有Shark��、Phoenix�����、Apache
Accumulo�����、Apache Drill���、Apache Giraph、Apache Hama����、Apache Tez、Apache
Ambari
等其他開源解決方案����。預計未來相當長一段時間內,主流的Hadoop平臺改進后將與各種新的計算模式和系統(tǒng)共存��,并相互融合����,形成新一代的大數(shù)據(jù)處理系統(tǒng)和平臺。
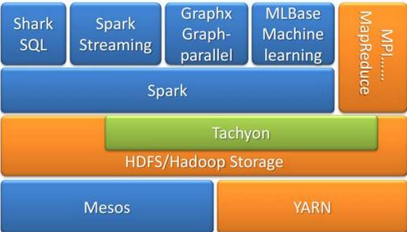
圖3 Spark生態(tài)系統(tǒng)
3大數(shù)據(jù)采集與預處理
在大數(shù)據(jù)的生命周期中�,數(shù)據(jù)采集處于第一個環(huán)節(jié)。根據(jù)MapReduce產生數(shù)據(jù)的應用系統(tǒng)分類����,大數(shù)據(jù)的采集主要有4種來源:管理信息系統(tǒng)、Web信息系統(tǒng)����、物理信息系統(tǒng)�、科學實驗系統(tǒng)��。對于不同的數(shù)據(jù)集��,可能存在不同的結構和模式�,如文件、XML
樹����、關系表等,表現(xiàn)為數(shù)據(jù)的異構性�����。對多個異構的數(shù)據(jù)集�,需要做進一步集成處理或整合處理,將來自不同數(shù)據(jù)集的數(shù)據(jù)收集�����、整理�����、清洗、轉換后���,生成到一個新的數(shù)據(jù)集�����,為后續(xù)查詢和分析處理提供統(tǒng)一的數(shù)據(jù)視圖。針對管理信息系統(tǒng)中異構數(shù)據(jù)庫集成技術���、Web
信息系統(tǒng)中的實體識別技術和DeepWeb集成技術�、傳感器網絡數(shù)據(jù)融合技術已經有很多研究工作����,取得了較大的進展,已經推出了多種數(shù)據(jù)清洗和質量控制工具�����,例如�,美國SAS公司的Data
Flux、美國IBM 公司的Data Stage�����、美國Informatica 公司的Informatica Power Center。
4大數(shù)據(jù)存儲與管理
傳統(tǒng)的數(shù)據(jù)存儲和管理以結構化數(shù)據(jù)為主��,因此關系數(shù)據(jù)庫系統(tǒng)(RDBMS)可以一統(tǒng)天下滿足各類應用需求����。大數(shù)據(jù)往往是半結構化和非結構化數(shù)據(jù)為主,結構化數(shù)據(jù)為輔����,而且各種大數(shù)據(jù)應用通常是對不同類型的數(shù)據(jù)內容檢索、交叉比對����、深度挖掘與綜合分析。面對這類應用需求�,傳統(tǒng)數(shù)據(jù)庫無論在技術上還是功能上都難以為繼。因此����,近幾年出現(xiàn)了oldSQL、NoSQL
與NewSQL
并存的局面���??傮w上,按數(shù)據(jù)類型的不同����,大數(shù)據(jù)的存儲和管理采用不同的技術路線,大致可以分為3類��。第1類主要面對的是大規(guī)模的結構化數(shù)據(jù)����。針對這類大數(shù)據(jù),通常采用新型數(shù)據(jù)庫集群�����。它們通過列存儲或行列混合存儲以及粗粒度索引等技術��,結合MPP(Massive
Parallel Processing)架構高效的分布式計算模式����,實現(xiàn)對PB
量級數(shù)據(jù)的存儲和管理�。這類集群具有高性能和高擴展性特點,在企業(yè)分析類應用領域已獲得廣泛應用�����;第2類主要面對的是半結構化和非結構化數(shù)據(jù)。應對這類應用場景���,基于Hadoop開源體系的系統(tǒng)平臺更為擅長����。它們通過對Hadoop生態(tài)體系的技術擴展和封裝�,實現(xiàn)對半結構化和非結構化數(shù)據(jù)的存儲和管理;第3類面對的是結構化和非結構化混合的大數(shù)據(jù)����,因此采用MPP
并行數(shù)據(jù)庫集群與Hadoop 集群的混合來實現(xiàn)對百PB 量級、EB量級數(shù)據(jù)的存儲和管理���。一方面��,用MPP
來管理計算高質量的結構化數(shù)據(jù)����,提供強大的SQL和OLTP型服務���;另一方面�����,用Hadoop實現(xiàn)對半結構化和非結構化數(shù)據(jù)的處理�,以支持諸如內容檢索、深度挖掘與綜合分析等新型應用�����。這類混合模式將是大數(shù)據(jù)存儲和管理未來發(fā)展的趨勢��。
5大數(shù)據(jù)計算模式與系統(tǒng)
計算模式的出現(xiàn)有力推動了大數(shù)據(jù)技術和應用的發(fā)展�����,使其成為目前大數(shù)據(jù)處理最為成功�、最廣為接受使用的主流大數(shù)據(jù)計算模式。然而��,現(xiàn)實世界中的大數(shù)據(jù)處理問題復雜多樣���,難以有一種單一的計算模式能涵蓋所有不同的大數(shù)據(jù)計算需求。研究和實際應用中發(fā)現(xiàn)��,由于MapReduce主要適合于進行大數(shù)據(jù)線下批處理�����,在面向低延遲和具有復雜數(shù)據(jù)關系和復雜計算的大數(shù)據(jù)問題時有很大的不適應性。因此���,近幾年來學術界和業(yè)界在不斷研究并推出多種不同的大數(shù)據(jù)計算模式��。
所謂大數(shù)據(jù)計算模式�����,即根據(jù)大數(shù)據(jù)的不同數(shù)據(jù)特征和計算特征����,從多樣性的大數(shù)據(jù)計算問題和需求中提煉并建立的各種高層抽象(abstraction)或模型(model)����。例如,MapReduce
是一個并行計算抽象��,加州大學伯克利分校著名的Spark系統(tǒng)中的“分布內存抽象RDD”����,CMU 著名的圖計算系統(tǒng)GraphLab
中的“圖并行抽象”(Graph Parallel
Abstraction)等。傳統(tǒng)的并行計算方法����,主要從體系結構和編程語言的層面定義了一些較為底層的并行計算抽象和模型�,但由于大數(shù)據(jù)處理問題具有很多高層的數(shù)據(jù)特征和計算特征�����,因此大數(shù)據(jù)處理需要更多地結合這些高層特征考慮更為高層的計算模式���。
根據(jù)大數(shù)據(jù)處理多樣性的需求和以上不同的特征維度�����,目前出現(xiàn)了多種典型和重要的大數(shù)據(jù)計算模式�����。與這些計算模式相適應���,出現(xiàn)了很多對應的大數(shù)據(jù)計算系統(tǒng)和工具。由于單純描述計算模式比較抽象和空洞���,因此在描述不同計算模式時���,將同時給出相應的典型計算系統(tǒng)和工具�,如表1所示�,這將有助于對計算模式的理解以及對技術發(fā)展現(xiàn)狀的把握���,并進一步有利于在實際大數(shù)據(jù)處理應用中對合適的計算技術和系統(tǒng)工具的選擇使用���。
表1典型大數(shù)據(jù)計算模式

6
大數(shù)據(jù)分析與可視化
在大數(shù)據(jù)時代,人們迫切希望在由普通機器組成的大規(guī)模集群上實現(xiàn)高性能的以機器學習算法為核心的數(shù)據(jù)分析�,為實際業(yè)務提供服務和指導,進而實現(xiàn)數(shù)據(jù)的最終變現(xiàn)��。與傳統(tǒng)的在線聯(lián)機分析處理OLAP不同��,對大數(shù)據(jù)的深度分析主要基于大規(guī)模的機器學習技術���,一般而言����,機器學習模型的訓練過程可以歸結為最優(yōu)化定義于大規(guī)模訓練數(shù)據(jù)上的目標函數(shù)并且通過一個循環(huán)迭代的算法實現(xiàn)�,如圖4所示。因而與傳統(tǒng)的OLAP相比較��,基于機器學習的大數(shù)據(jù)分析具有自己獨特的特點���。

圖4 基于機器學習的大數(shù)據(jù)分析算法目標函數(shù)和迭代優(yōu)化過程
(1)迭代性:由于用于優(yōu)化問題通常沒有閉式解�����,因而對模型參數(shù)確定并非一次能夠完成���,需要循環(huán)迭代多次逐步逼近最優(yōu)值點��。
(2)容錯性:機器學習的算法設計和模型評價容忍非最優(yōu)值點的存在��,同時多次迭代的特性也允許在循環(huán)的過程中產生一些錯誤�,模型的最終收斂不受影響�����。
(3)參數(shù)收斂的非均勻性:模型中一些參數(shù)經過少數(shù)幾輪迭代后便不再改變��,而有些參數(shù)則需要很長時間才能達到收斂����。
這些特點決定了理想的大數(shù)據(jù)分析系統(tǒng)的設計和其他計算系統(tǒng)的設計有很大不同,直接應用傳統(tǒng)的分布式計算系統(tǒng)應用于大數(shù)據(jù)分析���,很大比例的資源都浪費在通信���、等待、協(xié)調等非有效的計算上�����。
傳統(tǒng)的分布式計算框架MPI(message
passing
interface��,信息傳遞接口)雖然編程接口靈活功能強大��,但由于編程接口復雜且對容錯性支持不高���,無法支撐在大規(guī)模數(shù)據(jù)上的復雜操作�,研究人員轉而開發(fā)了一系列接口簡單容錯性強的分布式計算框架服務于大數(shù)據(jù)分析算法�����,以MapReduce�����、Spark和參數(shù)服務器ParameterServer等為代表���。
分布式計算框架MapReduce將對數(shù)據(jù)的處理歸結為Map和Reduce兩大類操作����,從而簡化了編程接口并且提高了系統(tǒng)的容錯性。但是MapReduce受制于過于簡化的數(shù)據(jù)操作抽象�����,而且不支持循環(huán)迭代��,因而對復雜的機器學習算法支持較差�����,基于MapReduce的分布式機器學習庫Mahout需要將迭代運算分解為多個連續(xù)的Map
和Reduce
操作�,通過讀寫HDFS文件方式將上一輪次循環(huán)的運算結果傳入下一輪完成數(shù)據(jù)交換。在此過程中��,大量的訓練時間被用于磁盤的讀寫操作���,訓練效率非常低效��。為了解決MapReduce上述問題����,Spark
基于RDD 定義了包括Map 和Reduce在內的更加豐富的數(shù)據(jù)操作接口��。不同于MapReduce 的是Job
中間輸出和結果可以保存在內存中,從而不再需要讀寫HDFS��,這些特性使得Spark能更好地適用于數(shù)據(jù)挖掘與機器學習等需要迭代的大數(shù)據(jù)分析算法�����?�;赟park實現(xiàn)的機器學習算法庫MLLIB已經顯示出了其相對于Mahout
的優(yōu)勢����,在實際應用系統(tǒng)中得到了廣泛的使用����。
近年來,隨著待分析數(shù)據(jù)規(guī)模的迅速擴張����,分析模型參數(shù)也快速增長,對已有的大數(shù)據(jù)分析模式提出了挑戰(zhàn)���。例如在大規(guī)模話題模型LDA
中���,人們期望訓練得到百萬個以上的話題,因而在訓練過程中可能需要對上百億甚至千億的模型參數(shù)進行更新,其規(guī)模遠遠超出了單個節(jié)點的處理能力��。為了解決上述問題��,研究人員提出了參數(shù)服務器(Parameter
Server)的概念��,如圖5所示����。在參數(shù)服務器系統(tǒng)中,大規(guī)模的模型參數(shù)被集中存儲在一個分布式的服務器集群中�,大規(guī)模的訓練數(shù)據(jù)則分布在不同的工作節(jié)點(worker)上,這樣每個工作節(jié)點只需要保存它計算時所依賴的少部分參數(shù)即可�,從而有效解決了超大規(guī)模大數(shù)據(jù)分析模型的訓練問題。目前參數(shù)服務器的實現(xiàn)主要有卡內基梅隆大學的Petuum����、PSLit等。
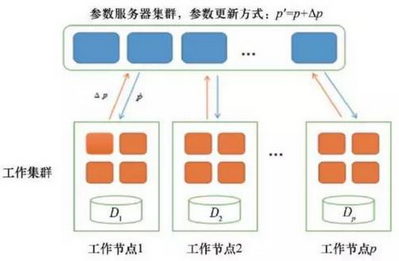
圖5 參數(shù)服務器工作原理
在大數(shù)據(jù)分析的應用過程中�����,可視化通過交互式視覺表現(xiàn)的方式來幫助人們探索和理解復雜的數(shù)據(jù)�。可視化與可視分析能夠迅速和有效地簡化與提煉數(shù)據(jù)流��,幫助用戶交互篩選大量的數(shù)據(jù),有助于使用者更快更好地從復雜數(shù)據(jù)中得到新的發(fā)現(xiàn)����,成為用戶了解復雜數(shù)據(jù)、開展深入分析不可或缺的手段���。大規(guī)模數(shù)據(jù)的可視化主要是基于并行算法設計的技術����,合理利用有限的計算資源�����,高效地處理和分析特定數(shù)據(jù)集的特性�。通常情況下�����,大規(guī)模數(shù)據(jù)可視化的技術會結合多分辨率表示等方法�����,以獲得足夠的互動性能��。在科學大規(guī)模數(shù)據(jù)的并行可視化工作中,主要涉及數(shù)據(jù)流線化����、任務并行化、管道并行化和數(shù)據(jù)并行化4
種基本技術�����。微軟公司在其云計算平臺Azure 上開發(fā)了大規(guī)模機器學習可視化平臺(Azure Machine
Learning)��,將大數(shù)據(jù)分析任務形式為有向無環(huán)圖并以數(shù)據(jù)流圖的方式向用戶展示��,取得了比較好的效果��。在國內�,阿里巴巴旗下的大數(shù)據(jù)分析平臺御膳房也采用了類似的方式,為業(yè)務人員提供的互動式大數(shù)據(jù)分析平臺�。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330