sas字符變量基于iv值的最優(yōu)分類
1.IV的用途
IV的全稱是Information Value��,中文意思是信息價(jià)值����,或者信息量。
我們?cè)谟?a href="http://www.3lll3.cn/view/20436.html" target="_blank">邏輯回歸�、決策樹(shù)等模型方法構(gòu)建分類模型時(shí),經(jīng)常需要對(duì)自變量進(jìn)行篩選���。比如我們有200個(gè)候選自變量�,通常情況下,不會(huì)直接把200個(gè)變量直接放到模型中去進(jìn)行擬合訓(xùn)練���,而是會(huì)用一些方法����,從這200個(gè)自變量中挑選一些出來(lái)���,放進(jìn)模型���,形成入模變量列表。那么我們?cè)趺慈ヌ暨x入模變量呢�����?
挑選入模變量過(guò)程是個(gè)比較復(fù)雜的過(guò)程���,需要考慮的因素很多����,比如:變量的預(yù)測(cè)能力�����,變量之間的相關(guān)性����,變量的簡(jiǎn)單性(容易生成和使用),變量的強(qiáng)壯性(不容易被繞過(guò))�����,變量在業(yè)務(wù)上的可解釋性(被挑戰(zhàn)時(shí)可以解釋的通)等等���。但是�,其中最主要和最直接的衡量標(biāo)準(zhǔn)是變量的預(yù)測(cè)能力��。
“變量的預(yù)測(cè)能力”這個(gè)說(shuō)法很籠統(tǒng)�,很主觀,非量化���,在篩選變量的時(shí)候我們總不能說(shuō):“我覺(jué)得這個(gè)變量預(yù)測(cè)能力很強(qiáng)�����,所以他要進(jìn)入模型”吧����?我們需要一些具體的量化指標(biāo)來(lái)衡量每自變量的預(yù)測(cè)能力,并根據(jù)這些量化指標(biāo)的大小��,來(lái)確定哪些變量進(jìn)入模型�。IV就是這樣一種指標(biāo),他可以用來(lái)衡量自變量的預(yù)測(cè)能力�����。類似的指標(biāo)還有信息增益���、基尼系數(shù)等等���。
2.對(duì)IV的直觀理解
從直觀邏輯上大體可以這樣理解“用IV去衡量變量預(yù)測(cè)能力”這件事情:我們假設(shè)在一個(gè)分類問(wèn)題中,目標(biāo)變量的類別有兩類:Y1��,Y2���。對(duì)于一個(gè)待預(yù)測(cè)的個(gè)體A���,要判斷A屬于Y1還是Y2,我們是需要一定的信息的���,假設(shè)這個(gè)信息總量是I��,而這些所需要的信息�����,就蘊(yùn)含在所有的自變量C1���,C2,C3����,……,Cn中�����,那么��,對(duì)于其中的一個(gè)變量Ci來(lái)說(shuō)�����,其蘊(yùn)含的信息越多�,那么它對(duì)于判斷A屬于Y1還是Y2的貢獻(xiàn)就越大�����,Ci的信息價(jià)值就越大���,Ci的IV就越大,它就越應(yīng)該進(jìn)入到入模變量列表中���。
3.IV的計(jì)算
前面我們從感性角度和邏輯層面對(duì)IV進(jìn)行了解釋和描述����,那么回到數(shù)學(xué)層面��,對(duì)于一個(gè)待評(píng)估變量�����,他的IV值究竟如何計(jì)算呢��?為了介紹IV的計(jì)算方法����,我們首先需要認(rèn)識(shí)和理解另一個(gè)概念——WOE,因?yàn)镮V的計(jì)算是以WOE為基礎(chǔ)的。
3.1WOE
WOE的全稱是“Weight of Evidence”���,即證據(jù)權(quán)重����。WOE是對(duì)原始自變量的一種編碼形式��。
要對(duì)一個(gè)變量進(jìn)行WOE編碼��,需要首先把這個(gè)變量進(jìn)行分組處理(也叫離散化����、分箱等等�����,說(shuō)的都是一個(gè)意思)��。分組后�����,對(duì)于第i組���,WOE的計(jì)算公式如下:
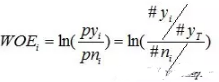
其中����,pyi是這個(gè)組中響應(yīng)客戶(風(fēng)險(xiǎn)模型中,對(duì)應(yīng)的是違約客戶����,總之,指的是模型中預(yù)測(cè)變量取值為“是”或者說(shuō)1的個(gè)體)占所有樣本中所有響應(yīng)客戶的比例��,pni是這個(gè)組中未響應(yīng)客戶占樣本中所有未響應(yīng)客戶的比例��,#yi是這個(gè)組中響應(yīng)客戶的數(shù)量��,#ni是這個(gè)組中未響應(yīng)客戶的數(shù)量�����,#yT是樣本中所有響應(yīng)客戶的數(shù)量��,#nT是樣本中所有未響應(yīng)客戶的數(shù)量��。
從這個(gè)公式中我們可以體會(huì)到�,WOE表示的實(shí)際上是“當(dāng)前分組中響應(yīng)客戶占所有響應(yīng)客戶的比例”和“當(dāng)前分組中沒(méi)有響應(yīng)的客戶占所有沒(méi)有響應(yīng)的客戶的比例”的差異。
對(duì)這個(gè)公式做一個(gè)簡(jiǎn)單變換�����,可以得到:
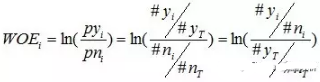
變換以后我們可以看出,WOE也可以這么理解���,他表示的是當(dāng)前這個(gè)組中響應(yīng)的客戶和未響應(yīng)客戶的比值�,和所有樣本中這個(gè)比值的差異����。這個(gè)差異是用這兩個(gè)比值的比值,再取對(duì)數(shù)來(lái)表示的����。WOE越大���,這種差異越大�����,這個(gè)分組里的樣本響應(yīng)的可能性就越大��,WOE越小����,差異越小,這個(gè)分組里的樣本響應(yīng)的可能性就越小����。
關(guān)于WOE編碼所表示的意義,大家可以自己再好好體會(huì)一下��。
3.2 IV的計(jì)算公式
有了前面的介紹�����,我們可以正式給出IV的計(jì)算公式����。對(duì)于一個(gè)分組后的變量,第i 組的WOE前面已經(jīng)介紹過(guò)�,是這樣計(jì)算的:
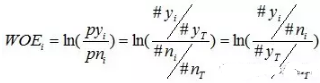
同樣,對(duì)于分組i���,也會(huì)有一個(gè)對(duì)應(yīng)的IV值�,計(jì)算公式如下:
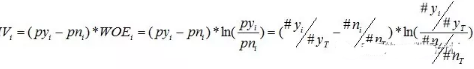
有了一個(gè)變量各分組的IV值��,我們就可以計(jì)算整個(gè)變量的IV值��,方法很簡(jiǎn)單�����,就是把各分組的IV相加:
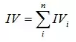
其中,n為變量分組個(gè)數(shù)�����。
還是簡(jiǎn)單粗暴上代碼吧��!
options compress=yes mprint validvarname=any;
libname center1 oracle user=datacenter password=datacenter path=datacenter schema=MFBMSAPP;
libname center oracle user=datacenter password=datacenter path=datacenter;
libname oracle oracle user=DATAHOUSE password=DATAHOUSE path=DATAHOUSE schema=DATAHOUSE;
libname mydata oracle user=zhanpx password=000000 path=DATAHOUSE ;
libname raw"F:\data";
%macro GValue(BinDS, Method, M_Value);
proc sql noprint;
%local i j R N;
select max(bin) into : R from &BinDS;
select sum(total) into : N from &BinDS;
%do i=1 %to &R;
%local N_&i._1 N_&i._2 N_&i._s N_s_1 N_s_2;
Select sum(Ni1) into :N_&i._1 from &BinDS where Bin =&i ;
Select sum(Ni2) into :N_&i._2 from &BinDS where Bin =&i ;
Select sum(Total) into :N_&i._s from &BinDS where Bin =&i ;
Select sum(Ni1) into :N_s_1 from &BinDS ;
Select sum(Ni2) into :N_s_2 from &BinDS ;
%end;
quit;
%if (&Method=4) %then %do; /* Information value */
%local IV;
%let IV=0;
%do i=1 %to &r;
%if (&&N_&i._1=.) or (&&N_&i._1=0) or
(&&N_&i._2=.) or (&&N_&i._2=0) or
(&N_s_1=) or (&N_s_1=0) or
(&N_s_2=) or (&N_s_2=0) %then %do ;
%let &M_Value=.;
%return;
%end;
end;
%do i=1 %to &r;
%let IV = %sysevalf(&IV + (&&N_&i._1/&N_s_1 - &&N_&i._2/&N_s_2)*%sysfunc(log(%sysevalf(&&N_&i._1*&N_s_2/(&&N_&i._2*&N_s_1)))) );
%end;
%let &M_Value=&IV;
%end;
%mend;
%macro CalcMerit(BinDS, ix, method, M_Value);
%local n_11 n_12 n_21 n_22 n_1s n_2s n_s1 n_s2;
proc sql noprint;
select sum(Ni1) into :n_11 from &BinDS where i<=&ix;
select sum(Ni1) into :n_21 from &BinDS where i> &ix;
select sum(Ni2) into : n_12 from &BinDS where i<=&ix ;
select sum(Ni2) into : n_22 from &binDS where i> &ix ;
select sum(total) into :n_1s from &BinDS where i<=&ix ;
select sum(total) into :n_2s from &BinDS where i> &ix ;
select sum(Ni1) into :n_s1 from &BinDS;
select sum(Ni2) into :n_s2 from &BinDS;
quit;
%if (&method=4) %then %do;
%local IV;
%let IV=%sysevalf( ((&n_11/&n_s1)-(&n_12/&n_s2))*%sysfunc(log(%sysevalf((&n_11*&n_s2)/(&n_12*&n_s1))))
+((&n_21/&n_s1)-(&n_22/&n_s2))*%sysfunc(log(%sysevalf((&n_21*&n_s2)/(&n_22*&n_s1)))) );
%let &M_Value=&IV;
%return;
%end;
%mend;
%macro BestSplit(BinDs, Method, BinNo);
%local mb i value BestValue BestI;
proc sql noprint;
select count(*) into: mb from &BinDs where Bin=&BinNo;
quit;
%let BestValue=0;
%let BestI=1;
%do i=1 %to %eval(&mb-1);
%let value=;
%CalcMerit(&BinDS, &i, &method, Value);
%if %sysevalf(&BestValue<&value) %then %do;
%let BestValue=&Value;
%let BestI=&i;
%end;
%end;
data &BinDS;
set &BinDS;
if i<=&BestI then Split=1;
else Split=0;
drop i;
run;
proc sort data=&BinDS;
by Split;
run;
data &BinDS;
retain i 0;
set &BinDs;
by Split;
if first.split then i=1;
else i=i+1;
run;
%mend;
%macro CandSplits(BinDS, Method, NewBins);
proc sort data=&BinDS;
by Bin PDV1;
run;
%local Bmax i value;
proc sql noprint;
select max(bin) into: Bmax from &BinDS;
%do i=1 %to &Bmax;
%local m&i;
create table Temp_BinC&i as select * from &BinDS where Bin=&i;
select count(*) into:m&i from Temp_BinC&i;
%end;
create table temp_allVals (BinToSplit num, DatasetName char(80), Value num);
run;quit;
%do i=1 %to &Bmax;
%if (&&m&i>1) %then %do;
%BestSplit(Temp_BinC&i, &Method, &i);
data temp_trysplit&i;
set temp_binC&i;
if split=1 then Bin=%eval(&Bmax+1);
run;
Data temp_main&i;
set &BinDS;
if Bin=&i then delete;
run;
Data Temp_main&i;
set temp_main&i temp_trysplit&i;
run;
%let value=;
%GValue(temp_main&i, &Method, Value);
proc sql noprint;
insert into temp_AllVals values(&i, "temp_main&i", &Value);
run;quit;
%end;
%end;
proc sort data=temp_allVals;
by descending value;
run;
data _null_;
set temp_AllVals(obs=1);
call symput("bin", compress(BinToSplit));
run;
Data &NewBins;
set Temp_main&Bin;
drop split;
run;
proc datasets nodetails nolist library=work;
delete temp_AllVals %do i=1 %to &Bmax; Temp_BinC&i temp_TrySplit&i temp_Main&i %end; ;
run;
quit;
%mend;
%macro ReduceCats(DSin, IVVar, DVVar, Method, Mmax, DSVarMap);
proc freq data=&DSin noprint;
table &IVVar*&DVvar /out=Temp_cross;
table &IVVar /out=Temp_IVtot;
run;
proc sort data=temp_cross;
by &IVVar;
run;
proc sort data= temp_IVTot;
by &IVvar;
run;
data temp_cont;
merge Temp_cross(rename=count=Ni2 ) temp_IVTot (rename=Count=total);
by &IVVar;
PDV1=Ni2/total;
Ni1=total-Ni2;
label Ni2= total=;
if &DVVar=1 then output;
drop percent &DVVar;
run;
proc sort data=temp_cont;
by PDV1;
run;
%local m;
data temp_cont;
set temp_cont (Rename=&IVVar=Var);
i=_N_;
Bin=1;
call symput("m", compress(_N_));
run;
%local Nbins ;
%let Nbins=1;
%DO %WHILE (&Nbins <&MMax);
%CandSplits(temp_cont, &method, Temp_Splits);
Data Temp_Cont;
set Temp_Splits;
run;
%let NBins=%eval(&NBins+1);
%end;
data &DSVarMap ;
set temp_cont(Rename=Var=&IVVar);
drop Ni2 PDV1 Ni1 i ;
label Bin ='New Category Group'
Category ='Old Category Group'
total ='Number of Records';
run;
proc sort data=&DSVarMap;
by Bin;
run;
proc datasets library=work nodetails nolist;
delete temp_cont temp_cross temp_ivtot temp_Splits;
run;quit;
%mend;
%let DSin=raw.jxl_total_3;
%let IVVar=PROVINCE;
%let DVVar=APPL_STATUS_1;
%let Method=4;
%let Mmax=5;
%let DSVarMap=aa;
%ReduceCats(&DSin., &IVVar., &DVVar., &Method., &Mmax.,&DSVarMap.);
DSin:填入原數(shù)據(jù)集��;
ivvar:填入要分段的變量
dvvar:因變量
method:這里就填4�����,至于為什么你別管��。
mmax:填入你想分幾組���;
DSVarMap:填入輸出的數(shù)據(jù)集;
代碼我已經(jīng)調(diào)試過(guò)了���,可以直接用的
現(xiàn)在我們來(lái)看前后結(jié)果:

PROVINCE_1是分段后的iv(0.06475553399)���,至于為什么是6組����,不是5組�,是因?yàn)檫€有缺失。PROVINCE是分段前的iv(0.0677179533)值���。首先我們知道iv值會(huì)隨著分的組數(shù)越多iv值就越高��。但是我們經(jīng)過(guò)最優(yōu)分段之后����,雖說(shuō)iv值小了�����,但是小的幅度是可以接受�����,降的基數(shù)也是比原來(lái)少了很多�,更有助我們之后的模型擬合。數(shù)據(jù)分析師培訓(xùn)
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)�,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330