機(jī)器學(xué)習(xí)算法與Python實(shí)踐之(二)支持向量機(jī)(SVM)初級(jí)
一�、引入
支持向量機(jī)(SupportVector Machines),這個(gè)名字可是響當(dāng)當(dāng)?shù)?���,?a href="http://www.3lll3.cn/view/20664.html" target="_blank">機(jī)器學(xué)習(xí)或者模式識(shí)別領(lǐng)域可是無(wú)人不知,無(wú)人不曉啊�����。八九十年代的時(shí)候���,和神經(jīng)網(wǎng)絡(luò)一決雌雄�,獨(dú)領(lǐng)風(fēng)騷�����,并吸引了大批為之狂熱和追隨的粉絲�。雖然幾十年過去了,但風(fēng)采不減當(dāng)年���,在模式識(shí)別領(lǐng)域依然占據(jù)著大遍江山���。王位穩(wěn)固了幾十年����。當(dāng)然了����,它也繁衍了很多子子孫孫,出現(xiàn)了很多基因改良的版本����,也發(fā)展了不少裙帶關(guān)系。但其中的睿智依然被世人稱道��,并將千秋萬(wàn)代�����!
好了���,買了那么久廣告����,不知道是不是高估了����。我們還是腳踏實(shí)地���,來看看傳說的SVM是個(gè)什么東西吧�。我們知道,分類的目的是學(xué)會(huì)一個(gè)分類函數(shù)或分類模型(或者叫做分類器)����,該模型能把數(shù)據(jù)庫(kù)中的數(shù)據(jù)項(xiàng)映射到給定類別中的某一個(gè),從而可以用于預(yù)測(cè)未知類別�����。對(duì)于用于分類的支持向量機(jī)����,它是個(gè)二分類的分類模型。也就是說��,給定一個(gè)包含正例和反例(正樣本點(diǎn)和負(fù)樣本點(diǎn))的樣本集合����,支持向量機(jī)的目的是尋找一個(gè)超平面來對(duì)樣本進(jìn)行分割,把樣本中的正例和反例用超平面分開����,但是不是簡(jiǎn)單地分看����,其原則是使正例和反例之間的間隔最大���。學(xué)習(xí)的目標(biāo)是在特征空間中找到一個(gè)分類超平面wx+b=0�,分類面由法向量w和截距b決定���。分類超平面將特征空間劃分兩部分���,一部分是正類,一部分是負(fù)類���。法向量指向的一側(cè)是正類����,另一側(cè)為負(fù)類�。
用一個(gè)二維空間里僅有兩類樣本的分類問題來舉個(gè)小例子。假設(shè)我們給定了下圖左圖所示的兩類點(diǎn)Class1和Class2(也就是正樣本集和負(fù)樣本集)�����。我們的任務(wù)是要找到一個(gè)線,把他們劃分開���。你會(huì)告訴我��,那簡(jiǎn)單����,揮筆一畫�����,洋洋灑灑五顏六色的線就出來了���,然后很得意的和我說,看看吧���,下面右圖����,都是你要的答案�����,如果你還想要,我還可以給你畫出無(wú)數(shù)條��。對(duì)�����,沒錯(cuò)��,的確可以畫出無(wú)數(shù)條���。那哪條最好呢���?你會(huì)問我,怎么樣衡量“好”�����?假設(shè)Class1和Class2分別是兩條村子的人�����,他們因?yàn)閮蓷l村子之間的地盤分割的事鬧僵了���,叫你去說個(gè)理��,到底怎么劃分才是最公平的����。這里的“好”,可以理解為對(duì)Class1和Class2都是公平的�。然后你二話不說,指著黑色那條線�����,說“就它了��!正常人都知道!在兩條村子最中間畫條線很明顯對(duì)他們就是公平的,誰(shuí)也別想多���,誰(shuí)也沒拿少”�����。這個(gè)例子可能不太恰當(dāng)�����,但道理還是一樣的����。對(duì)于分類來說,我們需要確定一個(gè)分類的線�����,如果新的一個(gè)樣本到來�,如果落在線的左邊,那么這個(gè)樣本就歸為class1類�����,如果落在線的右邊���,就歸為class2這一類�。那哪條線才是最好的呢����?我們?nèi)匀徽J(rèn)為是中間的那條,因?yàn)檫@樣��,對(duì)新的樣本的劃分結(jié)果我們才認(rèn)為最可信��,那這里的“好”就是可信了�。另外���,在二維空間,分類的就是線���,如果是三維的�,分類的就是面了���,更高維���,也有個(gè)霸氣的名字叫超平面。因?yàn)樗詺?����,所以一般將任何維的分類邊界都統(tǒng)稱為超平面���。
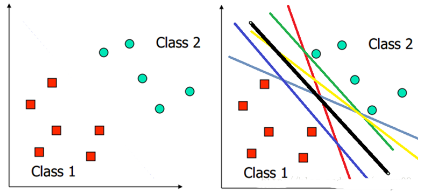
好了。對(duì)于人來說����,我們可以輕易的找到這條線或者超平面(當(dāng)然了,那是因?yàn)槟憧梢钥吹綐颖揪唧w的分布是怎樣的���,如果樣本的維度大于三維的話���,我們就沒辦法把這些樣本像上面的圖一樣畫出來了�����,這時(shí)候就看不到了����,這時(shí)候靠人的雙眼也無(wú)能為力了�����?�!叭绻夷芸吹靡?���,生命也許完全不同,可能我想要的��,我喜歡的我愛的�����,都不一樣……”),但計(jì)算機(jī)怎么知道怎么找到這條線呢����?我們?cè)趺窗盐覀兊恼疫@條線的方法告訴他,讓他按照我們的方法來找到這條線呢��?呃��,我們要建模?���。?��!把我們的意識(shí)“強(qiáng)加”給計(jì)算機(jī)的某個(gè)數(shù)學(xué)模型��,讓他去求解這個(gè)模型���,得到某個(gè)解�����,這個(gè)解就是我們的這條線�����,那這樣目的就達(dá)到了。那下面就得開始建模之旅了����。
二、線性可分SVM與硬間隔最大化
其實(shí)上面這種分類思想就是SVM的思想���??梢员磉_(dá)為:SVM試圖尋找一個(gè)超平面來對(duì)樣本進(jìn)行分割��,把樣本中的正例和反例用超平面分開����,但是不是很敷衍地簡(jiǎn)單的分開,而是盡最大的努力使正例和反例之間的間隔margin最大�����。這樣它的分類結(jié)果才更加可信�����,而且對(duì)于未知的新樣本才有很好的分類預(yù)測(cè)能力(機(jī)器學(xué)習(xí)美其名曰泛化能力)。
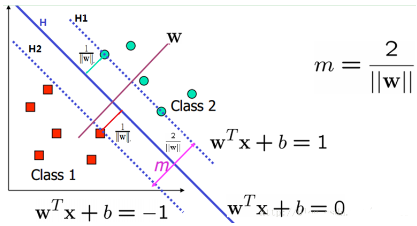
我們的目標(biāo)是尋找一個(gè)超平面�����,使得離超平面比較近的點(diǎn)能有更大的間距��。也就是我們不考慮所有的點(diǎn)都必須遠(yuǎn)離超平面��,我們關(guān)心求得的超平面能夠讓所有點(diǎn)中離它最近的點(diǎn)具有最大間距�。
我們先用數(shù)學(xué)公式來描述下。假設(shè)我們有N個(gè)訓(xùn)練樣本{(x1, y1),(x2, y2), …, (xN, yN)}��,x是d維向量��,而yi?{+1, -1}是樣本的標(biāo)簽���,分別代表兩個(gè)不同的類��。這里我們需要用這些樣本去訓(xùn)練學(xué)習(xí)一個(gè)線性分類器(超平面):f(x)=sgn(wTx + b)��,也就是wTx + b大于0的時(shí)候����,輸出+1�,小于0的時(shí)候�,輸出-1����。sgn()表示取符號(hào)�����。而g(x) =wTx + b=0就是我們要尋找的分類超平面�,如上圖所示。剛才說我們要怎么做了���?我們需要這個(gè)超平面最大的分隔這兩類�����。也就是這個(gè)分類面到這兩個(gè)類的最近的那個(gè)樣本的距離相同�,而且最大����。為了更好的說明,我們?cè)谏蠄D中找到兩個(gè)和這個(gè)超平面平行和距離相等的超平面:H1: y = wTx + b=+1 和 H2: y = wTx + b=-1���。
好了����,這時(shí)候我們就需要兩個(gè)條件:(1)沒有任何樣本在這兩個(gè)平面之間;(2)這兩個(gè)平面的距離需要最大��。(對(duì)任何的H1和H2�����,我們都可以歸一化系數(shù)向量w���,這樣就可以得到H1和H2表達(dá)式的右邊分別是+1和-1了)���。先來看條件(2)。我們需要最大化這個(gè)距離�����,所以就存在一些樣本處于這兩條線上��,他們叫支持向量(后面會(huì)說到他們的重要性)����。那么它的距離是什么呢?我們初中就學(xué)過�����,兩條平行線的距離的求法,例如ax+by=c1和ax+by=c2��,那他們的距離是|c2-c1|/sqrt(x2+y2)(sqrt()表示開根號(hào))�����。注意的是���,這里的x和y都表示二維坐標(biāo)。而用w來表示就是H1:w1x1+w2x2=+1和H2:w1x1+w2x2=-1����,那H1和H2的距離就是|1+1|/ sqrt(w12+w12)=2/||w||。也就是w的模的倒數(shù)的兩倍���。也就是說�����,我們需要最大化margin=2/||w||�,為了最大化這個(gè)距離����,我們應(yīng)該最小化||w||���,看起來好簡(jiǎn)單哦。同時(shí)我們還需要滿足條件(2)�,也就是同時(shí)要滿足沒有數(shù)據(jù)點(diǎn)分布在H1和H2之間:
也就是,對(duì)于任何一個(gè)正樣本yi=+1�����,它都要處于H1的右邊�����,也就是要保證:y= wTx + b>=+1�����。對(duì)于任何一個(gè)負(fù)樣本yi=-1����,它都要處于H2的左邊,也就是要保證:y = wTx + b<=-1��。這兩個(gè)約束�����,其實(shí)可以合并成同一個(gè)式子:yi (wTxi + b)>=1。
所以我們的問題就變成:
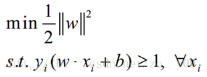
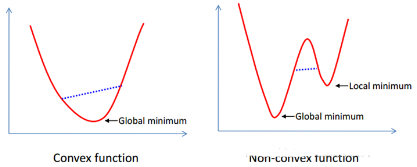
這是個(gè)凸二次規(guī)劃問題��。什么叫凸�����?凸集是指有這么一個(gè)點(diǎn)的集合��,其中任取兩個(gè)點(diǎn)連一條直線���,這條線上的點(diǎn)仍然在這個(gè)集合內(nèi)部,因此說“凸”是很形象的���。例如下圖��,對(duì)于凸函數(shù)(在數(shù)學(xué)表示上��,滿足約束條件是仿射函數(shù)�,也就是線性的Ax+b的形式)來說���,局部最優(yōu)就是全局最優(yōu)���,但對(duì)非凸函數(shù)來說就不是了��。二次表示目標(biāo)函數(shù)是自變量的二次函數(shù)�����。
好了���,既然是凸二次規(guī)劃問題,就可以通過一些現(xiàn)成的 QP (Quadratic Programming) 的優(yōu)化工具來得到最優(yōu)解����。所以,我們的問題到此為止就算全部解決了����。雖然這個(gè)問題確實(shí)是一個(gè)標(biāo)準(zhǔn)的 QP 問題,但是它也有它的特殊結(jié)構(gòu)����,通過 Lagrange Duality 變換到對(duì)偶變量 (dual variable) 的優(yōu)化問題之后,可以找到一種更加有效的方法來進(jìn)行求解�,而且通常情況下這種方法比直接使用通用的 QP 優(yōu)化包進(jìn)行優(yōu)化要高效得多。也就說���,除了用解決QP問題的常規(guī)方法之外���,還可以應(yīng)用拉格朗日對(duì)偶性����,通過求解對(duì)偶問題得到最優(yōu)解��,這就是線性可分條件下支持向量機(jī)的對(duì)偶算法��,這樣做的優(yōu)點(diǎn)在于:一是對(duì)偶問題往往更容易求解���;二者可以自然的引入核函數(shù),進(jìn)而推廣到非線性分類問題�。那什么是對(duì)偶問題?
三�����、Dual優(yōu)化問題
3.1��、對(duì)偶問題
在約束最優(yōu)化問題中����,常常利用拉格朗日對(duì)偶性將原始問題轉(zhuǎn)換為對(duì)偶問題�����,通過求解對(duì)偶問題而得到原始問題的解�。至于這其中的原理和推導(dǎo)參考文獻(xiàn)[3]講得非常好���。大家可以參考下。這里只將對(duì)偶問題是怎么操作的�。假設(shè)我們的優(yōu)化問題是:
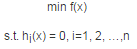
這是個(gè)帶等式約束的優(yōu)化問題。我們引入拉格朗日乘子�����,得到拉格朗日函數(shù)為:
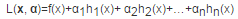
然后我們將拉格朗日函數(shù)對(duì)x求極值�,也就是對(duì)x求導(dǎo),導(dǎo)數(shù)為0�����,就可以得到α關(guān)于x的函數(shù)���,然后再代入拉格朗日函數(shù)就變成:
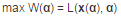
這時(shí)候�,帶等式約束的優(yōu)化問題就變成只有一個(gè)變量α(多個(gè)約束條件就是向量)的優(yōu)化問題,這時(shí)候的求解就很簡(jiǎn)單了�����。同樣是求導(dǎo)另其等于0����,解出α即可。需要注意的是���,我們把原始的問題叫做primal problem,轉(zhuǎn)換后的形式叫做dual problem����。需要注意的是,原始問題是最小化,轉(zhuǎn)化為對(duì)偶問題后就變成了求最大值了��。對(duì)于不等式約束�����,其實(shí)是同樣的操作。簡(jiǎn)單地來說,通過給每一個(gè)約束條件加上一個(gè) Lagrange multiplier(拉格朗日乘子)����,我們可以將約束條件融和到目標(biāo)函數(shù)里去���,這樣求解優(yōu)化問題就會(huì)更加容易。(這里其實(shí)涉及到很多蠻有趣的東西的����,大家可以參考更多的博文)
3.2、SVM優(yōu)化的對(duì)偶問題
對(duì)于SVM�����,前面提到�����,其primal problem是以下形式:
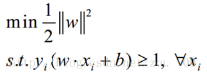
同樣的方法引入拉格朗日乘子�,我們就可以得到以下拉格朗日函數(shù):
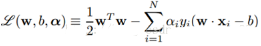
然后對(duì)L(w, b, α)分別求w和b的極值。也就是L(w, b,α)對(duì)w和b的梯度為0:?L/?w=0和?L/?b=0�,還需要滿足α>=0。求解這里導(dǎo)數(shù)為0的式子可以得到:
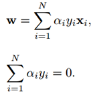
然后再代入拉格朗日函數(shù)后�����,就變成:
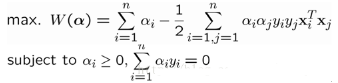
這個(gè)就是dual problem(如果我們知道α�,我們就知道了w。反過來�����,如果我們知道w��,也可以知道α)���。這時(shí)候我們就變成了求對(duì)α的極大��,即是關(guān)于對(duì)偶變量α的優(yōu)化問題(沒有了變量w�,b�,只有α)。當(dāng)求解得到最優(yōu)的α*后��,就可以同樣代入到上面的公式�����,導(dǎo)出w*和b*了����,最終得出分離超平面和分類決策函數(shù)。也就是訓(xùn)練好了SVM��。那來一個(gè)新的樣本x后��,就可以這樣分類了:
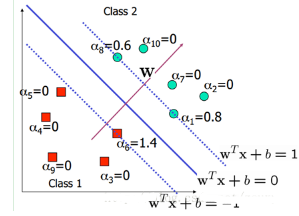
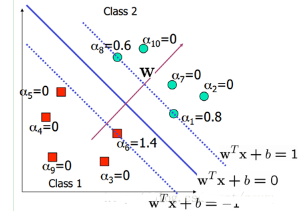
在這里�����,其實(shí)很多的αi都是0�����,也就是說w只是一些少量樣本的線性加權(quán)值�����。這種“稀疏”的表示實(shí)際上看成是KNN的數(shù)據(jù)壓縮的版本���。也就是說����,以后新來的要分類的樣本首先根據(jù)w和b做一次線性運(yùn)算��,然后看求的結(jié)果是大于0還是小于0來判斷正例還是負(fù)例。現(xiàn)在有了αi��,我們不需要求出w�����,只需將新來的樣本和訓(xùn)練數(shù)據(jù)中的所有樣本做內(nèi)積和即可���。那有人會(huì)說�����,與前面所有的樣本都做運(yùn)算是不是太耗時(shí)了��?其實(shí)不然��,我們從KKT條件中得到�����,只有支持向量的αi不為0��,其他情況αi都是0���。因此,我們只需求新來的樣本和支持向量的內(nèi)積���,然后運(yùn)算即可��。這種寫法為下面要提到的核函數(shù)(kernel)做了很好的鋪墊���。如下圖所示:
四、松弛向量與軟間隔最大化
我們之前討論的情況都是建立在樣本的分布比較優(yōu)雅和線性可分的假設(shè)上����,在這種情況下可以找到近乎完美的超平面對(duì)兩類樣本進(jìn)行分離。但如果遇到下面這兩種情況呢�����?左圖���,負(fù)類的一個(gè)樣本點(diǎn)A不太合群����,跑到正類這邊了��,這時(shí)候如果按上面的確定分類面的方法��,那么就會(huì)得到左圖中紅色這條分類邊界,嗯���,看起來不太爽����,好像全世界都在將就A一樣����。還有就是遇到右圖的這種情況。正類的一個(gè)點(diǎn)和負(fù)類的一個(gè)點(diǎn)都跑到了別人家門口���,這時(shí)候就找不到一條直線來將他們分開了���,那這時(shí)候怎么辦呢?我們真的要對(duì)這些零丁的不太聽話的離群點(diǎn)屈服和將就嗎�?就因?yàn)樗麄兊牟煌昝栏淖兾覀冊(cè)瓉硗昝赖姆纸缑鏁?huì)不會(huì)得不償失呢?但又不得不考慮他們���,那怎樣才能折中呢�?
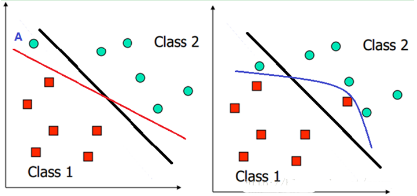
對(duì)于上面說的這種偏離正常位置很遠(yuǎn)的數(shù)據(jù)點(diǎn)����,我們稱之為 outlier����,它有可能是采集訓(xùn)練樣本的時(shí)候的噪聲����,也有可能是某個(gè)標(biāo)數(shù)據(jù)的大叔打瞌睡標(biāo)錯(cuò)了�����,把正樣本標(biāo)成負(fù)樣本了���。那一般來說,如果我們直接忽略它�����,原來的分隔超平面還是挺好的����,但是由于這個(gè) outlier 的出現(xiàn),導(dǎo)致分隔超平面不得不被擠歪了�,同時(shí) margin 也相應(yīng)變小了。當(dāng)然��,更嚴(yán)重的情況是,如果出現(xiàn)右圖的這種outlier����,我們將無(wú)法構(gòu)造出能將數(shù)據(jù)線性分開的超平面來�。
為了處理這種情況���,我們?cè)试S數(shù)據(jù)點(diǎn)在一定程度上偏離超平面�����。也就是允許一些點(diǎn)跑到H1和H2之間��,也就是他們到分類面的間隔會(huì)小于1���。如下圖:
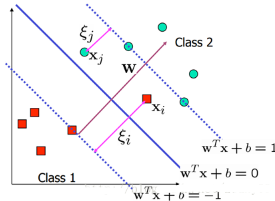
具體來說,原來的約束條件就變?yōu)椋?
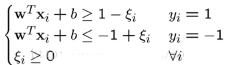
這時(shí)候���,我們?cè)谀繕?biāo)函數(shù)里面增加一個(gè)懲罰項(xiàng)���,新的模型就變成(也稱軟間隔):
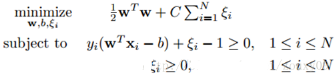
引入非負(fù)參數(shù)ξi后(稱為松弛變量)��,就允許某些樣本點(diǎn)的函數(shù)間隔小于1���,即在最大間隔區(qū)間里面,或者函數(shù)間隔是負(fù)數(shù)����,即樣本點(diǎn)在對(duì)方的區(qū)域中���。而放松限制條件后,我們需要重新調(diào)整目標(biāo)函數(shù)�,以對(duì)離群點(diǎn)進(jìn)行處罰,目標(biāo)函數(shù)后面加上的第二項(xiàng)就表示離群點(diǎn)越多���,目標(biāo)函數(shù)值越大����,而我們要求的是盡可能小的目標(biāo)函數(shù)值����。這里的C是離群點(diǎn)的權(quán)重,C越大表明離群點(diǎn)對(duì)目標(biāo)函數(shù)影響越大,也就是越不希望看到離群點(diǎn)���。這時(shí)候����,間隔也會(huì)很小����。我們看到,目標(biāo)函數(shù)控制了離群點(diǎn)的數(shù)目和程度�����,使大部分樣本點(diǎn)仍然遵守限制條件��。數(shù)據(jù)分析師培訓(xùn)
這時(shí)候��,經(jīng)過同樣的推導(dǎo)過程�����,我們的對(duì)偶優(yōu)化問題變成:
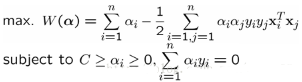
此時(shí)����,我們發(fā)現(xiàn)沒有了參數(shù)ξi�,與之前模型唯一不同在于αi又多了αi<=C的限制條件�����。需要提醒的是���,b的求值公式也發(fā)生了改變��,改變結(jié)果在SMO算法里面介紹��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫(kù)���,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330