LLM進入拖拽時代����!只靠Prompt幾秒定制大模型����,效率飆升12000倍
?
【新智元導(dǎo)讀】最近����,來自NUS�����、UT Austin等機構(gòu)的研究人員創(chuàng)新性地提出了一種「拖拽式大語言模型」(DnD)���,它可以基于提示詞快速生成模型參數(shù)����,無需微調(diào)就能適應(yīng)任務(wù)����。不僅效率最高提升12000倍,而且具備出色的零樣本泛化能力��。
現(xiàn)在的大模型基本都具備零樣本泛化能力�����,但要在真實場景中做特定的適配,還是得花好幾個小時來對模型進行微調(diào)�。
即便是像LoRA這樣的參數(shù)高效方法,也只能緩解而不能消除每個任務(wù)所需的微調(diào)成本�。
剛剛,包括尤洋教授在內(nèi)的來自新加坡國立大學(xué)����、得克薩斯大學(xué)奧斯汀分校等機構(gòu)的研究人員,提出了一種全新的「拖拽式大語言模型」——Drag-and-Drop LLMs�!

- 論文地址:
https://arxiv.org/abs/2506.16406
DnD是一種基于提示詞的參數(shù)生成器,能夠?qū)LM進行無需訓(xùn)練的自適應(yīng)微調(diào)�。
通過一個輕量級文本編碼器與一個級聯(lián)超卷積解碼器的組合,DnD能在數(shù)秒內(nèi)��,僅根據(jù)無標(biāo)簽的任務(wù)提示詞���,生成針對該任務(wù)的LoRA權(quán)重矩陣����。
顯然�,對于那些需要快速實現(xiàn)模型專業(yè)化的場景,DnD可以提供一種相較于傳統(tǒng)微調(diào)方法更強大�、靈活且高效的替代方案����。

總結(jié)來說����,DnD的核心優(yōu)勢如下:
- 極致效率:其計算開銷比傳統(tǒng)的全量微調(diào)低12,000倍。
- 卓越性能:在零樣本學(xué)習(xí)的常識推理���、數(shù)學(xué)�����、編碼及多模態(tài)基準(zhǔn)測試中,其性能比最強大的��、需要訓(xùn)練的LoRA模型還要高出30%���。
- 強大泛化:僅需無標(biāo)簽的提示詞��,即可在不同領(lǐng)域間展現(xiàn)出強大的泛化能力����。
DnD實現(xiàn)方法
通過觀察���,研究人員發(fā)現(xiàn)����,LoRA適配器無非是其訓(xùn)練數(shù)據(jù)的一個函數(shù):梯度下降會將基礎(chǔ)權(quán)重「拖拽」至一個特定任務(wù)的最優(yōu)狀態(tài)。
如果能夠直接學(xué)習(xí)從提示到權(quán)重的映射����,那么就可以完全繞過梯度下降過程。
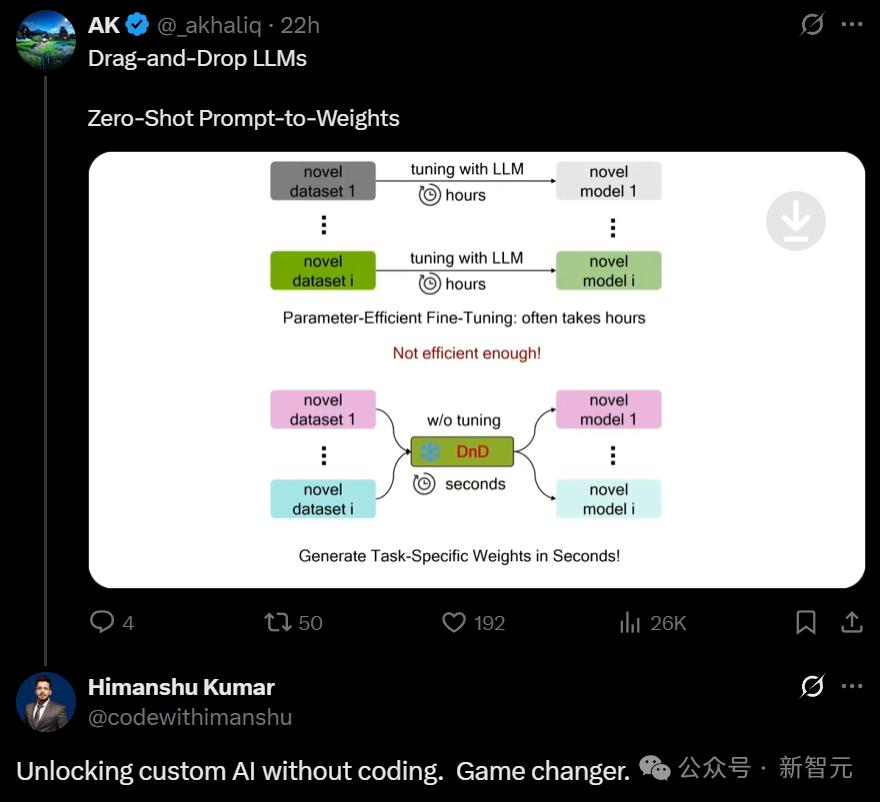
DnD通過兩個核心步驟獲得「拖拽」能力:準(zhǔn)備訓(xùn)練數(shù)據(jù)(左上)與訓(xùn)練參數(shù)生成器(右上)��。
在準(zhǔn)備數(shù)據(jù)時����,將模型參數(shù)(權(quán)重)與特定數(shù)據(jù)集的條件(提示詞)進行顯式配對。
在訓(xùn)練時�,DnD模型將條件作為輸入來生成參數(shù),并使用原始的LoRA參數(shù)作為監(jiān)督信號進行學(xué)習(xí)����。
基于這些洞見,團隊提出了「拖拽式大語言模型」��,它無需微調(diào)即可生成任務(wù)專屬的權(quán)重���。
團隊首先在多個不同數(shù)據(jù)集上分別訓(xùn)練并保存相應(yīng)的LoRA適配器��。
為了賦予模型「拖拽」的能力�,團隊將這些數(shù)據(jù)集的提示詞與收集到的LoRA權(quán)重進行隨機配對,構(gòu)成DnD模型的訓(xùn)練數(shù)據(jù)——即「提示詞-參數(shù)」對��。
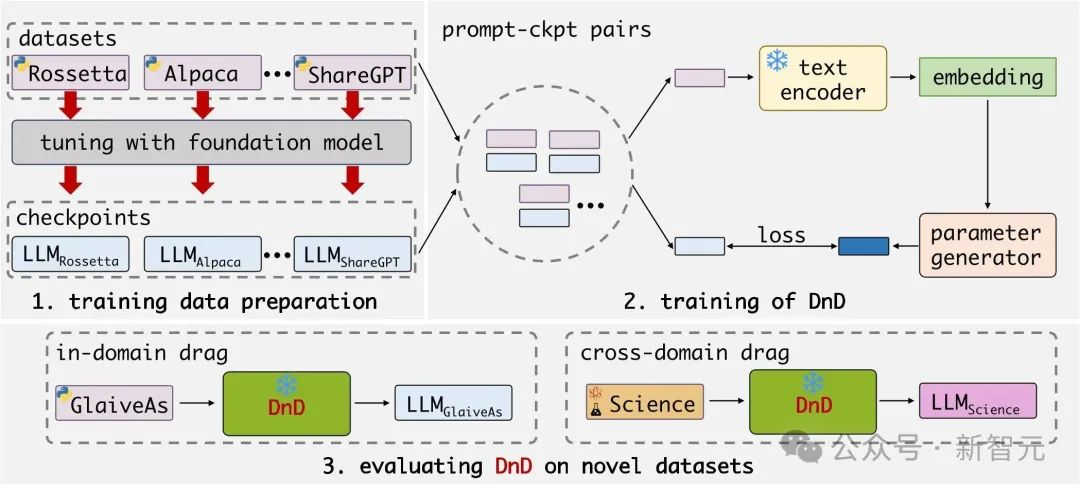
參數(shù)生成器是一個由級聯(lián)卷積塊構(gòu)成的解碼器���。
參數(shù)生成器的模塊細節(jié)如下:每個超卷積塊包含三個超卷積模塊,用于在不同維度上提取并融合特征信息����。

訓(xùn)練時,團隊采用一個現(xiàn)成的文本編碼器提取提示詞的嵌入向量��,并將其輸入生成器����。
生成器會預(yù)測出模型權(quán)重�����,團隊利用其與真實LoRA權(quán)重之間的均方誤差(MSE)損失來對其進行優(yōu)化���。
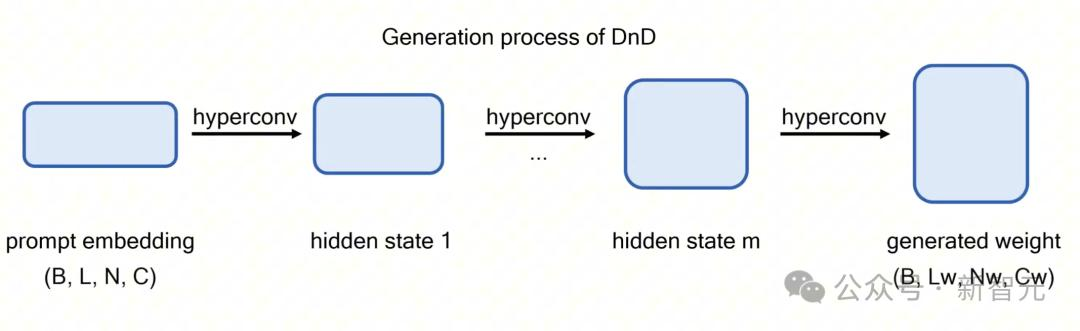
在推理階段�����,團隊只需將來自全新數(shù)據(jù)集(訓(xùn)練中未見過)的提示詞輸入DnD�,僅需一次前向傳播,即可獲得為該任務(wù)量身定制的參數(shù)��。
效果評估

零樣本學(xué)習(xí)效果
在新的(測試)數(shù)據(jù)集上的泛化能力。
在所有未曾見過的數(shù)據(jù)集上����,DnD在準(zhǔn)確率上都顯著超越了那些用于訓(xùn)練的LoRA模型���。

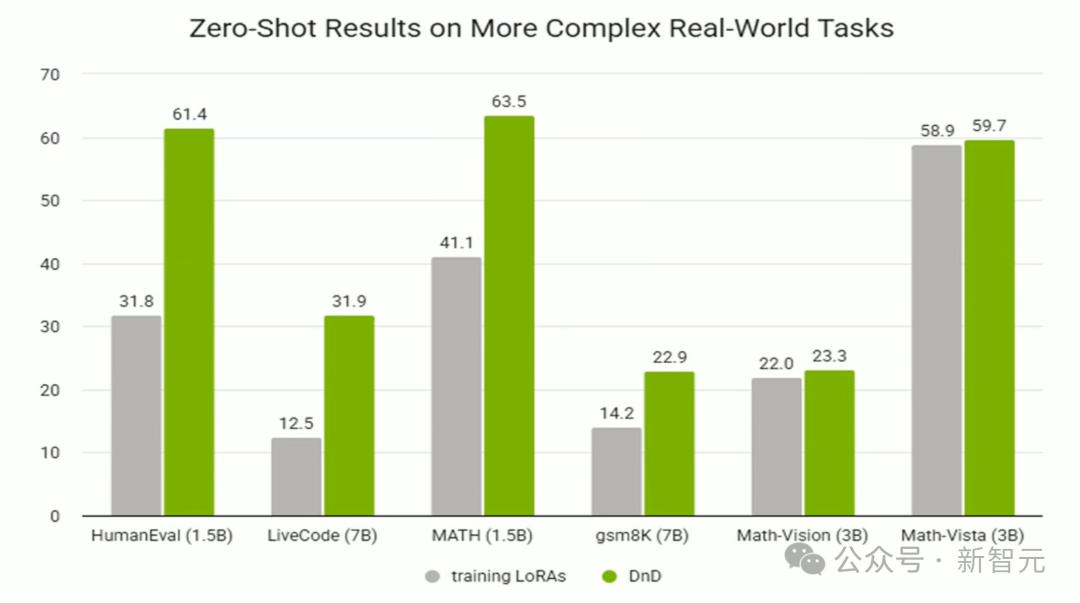
DnD能為數(shù)學(xué)�、代碼和多模態(tài)問答等更復(fù)雜的任務(wù)生成參數(shù)����。
在這些任務(wù)上依然展現(xiàn)出強大的零樣本學(xué)習(xí)能力。
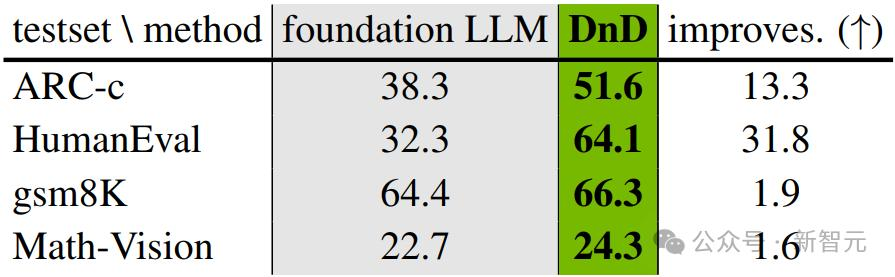
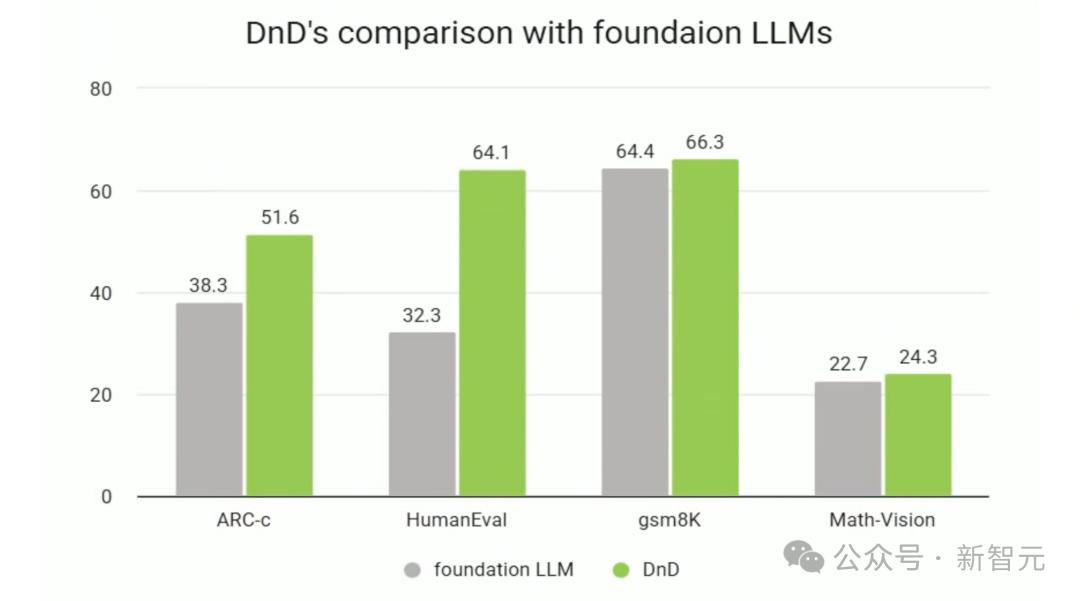
DnD在多種任務(wù)上超越了基座LLM�,展現(xiàn)出顯著的「拖拽」增強效果。

DnD能夠很好地擴展至更大的7B基座模型���,并在更復(fù)雜的LiveCodeBench基準(zhǔn)測試中保持強勁性能�����。
通過利用已微調(diào)的LoRA作為訓(xùn)練數(shù)據(jù)��,DnD成功地在輸入提示詞與模型參數(shù)之間建立了聯(lián)系����。
團隊向DnD輸入其訓(xùn)練階段從未見過的數(shù)據(jù)集提示詞����,讓它為這些新任務(wù)直接生成參數(shù),以此來檢驗其零樣本學(xué)習(xí)能力���。
DnD在權(quán)重空間中生成的參數(shù)與原始參數(shù)分布接近�,并且在性能上表現(xiàn)良好�。
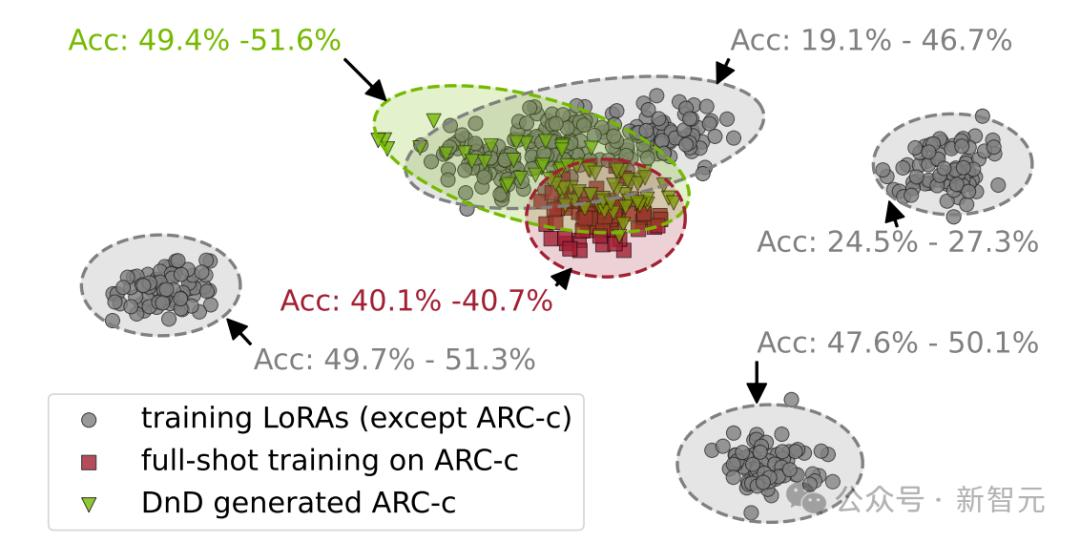
實驗結(jié)果表明���,在零樣本測試集上���,團隊的方法相較于訓(xùn)練所用的LoRA模型的平均性能����,取得了驚人的提升��,并且能夠很好地泛化到多種真實世界任務(wù)和不同尺寸的LLM��。
對比其他微調(diào)方法
為了進一步展示DnD的強大能力�����,團隊將其與全量樣本微調(diào)(full-shot tuning)��、少樣本學(xué)習(xí)(few-shot)以及上下文學(xué)習(xí)(in-context learning)進行了對比�。
令人驚訝的是�,DnD的性能超越了LoRA全量微調(diào)的效果,同時速度快了2500倍��。
雖然經(jīng)過更多輪次的迭代����,全量微調(diào)的性能會超過DnD,但其代價是高達12000倍的推理延遲��。
此外,在樣本數(shù)少于256個時�����,DnD的性能穩(wěn)定地優(yōu)于少樣本學(xué)習(xí)和上下文學(xué)習(xí)���。
尤其值得注意的是,少樣本學(xué)習(xí)和上下文學(xué)習(xí)都需要依賴帶標(biāo)簽的答案�,而DnD僅僅需要無標(biāo)簽的提示詞�����。
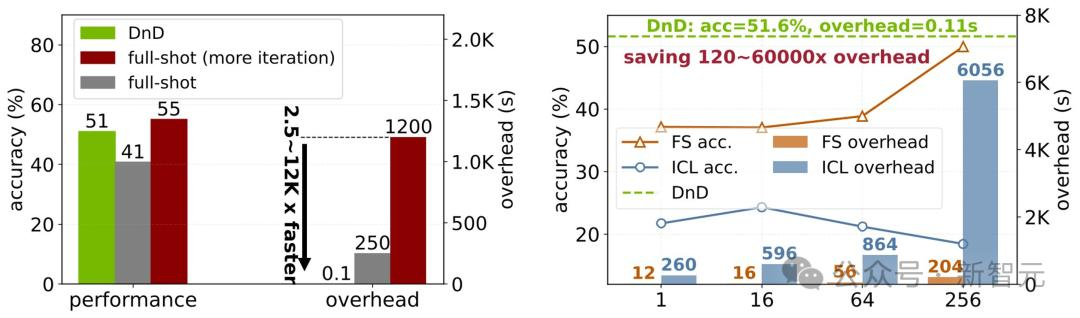
DnD能夠達到與全量樣本相當(dāng)甚至更優(yōu)的性能��,同時速度提高了2500-12000倍
- 參考資料:
https://jerryliang24.github.io/DnD
By 新智元 On 2025年6月24日 In 綜合
推薦學(xué)習(xí)書籍 《CDA一級教材》適合CDA一級考生備考�,也適合業(yè)務(wù)及數(shù)據(jù)分析崗位的從業(yè)者提升自我�。完整電子版已上線CDA網(wǎng)校,累計已有10萬+在讀~  免費加入閱讀:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0
免費加入閱讀:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330