簡單易學(xué)的機(jī)器學(xué)習(xí)算法—K-Means算法
一、聚類算法的簡介
聚類算法是一種典型的無監(jiān)督學(xué)習(xí)算法,主要用于將相似的樣本自動歸到一個類別中����。聚類算法與分類算法最大的區(qū)別是:聚類算法是無監(jiān)督的學(xué)習(xí)算法�����,而分類算法屬于監(jiān)督的學(xué)習(xí)算法��。
在聚類算法中根據(jù)樣本之間的相似性��,將樣本劃分到不同的類別中��,對于不同的相似度計算方法��,會得到不同的聚類結(jié)果�,常用的相似度計算方法有歐式距離法。
二����、K-Means算法的概述
基本K-Means算法的思想很簡單,事先確定常數(shù)K�����,常數(shù)K意味著最終的聚類類別數(shù),首先隨機(jī)選定初始點為質(zhì)心��,并通過計算每一個樣本與質(zhì)心之間的相似度(這里為歐式距離)��,將樣本點歸到最相似的類中���,接著��,重新計算每個類的質(zhì)心(即為類中心)�����,重復(fù)這樣的過程��,知道質(zhì)心不再改變�,最終就確定了每個樣本所屬的類別以及每個類的質(zhì)心�。由于每次都要計算所有的樣本與每一個質(zhì)心之間的相似度,故在大規(guī)模的數(shù)據(jù)集上���,K-Means算法的收斂速度比較慢��。
三�����、K-Means算法的流程
初始化常數(shù)K�����,隨機(jī)選取初始點為質(zhì)心
重復(fù)計算一下過程���,直到質(zhì)心不再改變
計算樣本與每個質(zhì)心之間的相似度,將樣本歸類到最相似的類中
重新計算質(zhì)心
輸出最終的質(zhì)心以及每個類
四�、K-Means算法的實現(xiàn)
對數(shù)據(jù)集進(jìn)行測試
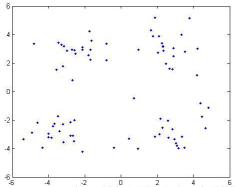
原始數(shù)據(jù)集
MATLAB代碼
主程序
[plain] view plain copy 在CODE上查看代碼片派生到我的代碼片
%% input the data
A = load('testSet.txt');
%% 計算質(zhì)心
centroids = kMeans(A, 4);
隨機(jī)選取質(zhì)心
[plain] view plain copy 在CODE上查看代碼片派生到我的代碼片
%% 取得隨機(jī)中心
function [ centroids ] = randCent( dataSet, k )
[m,n] = size(dataSet);%取得列數(shù)
centroids = zeros(k, n);
for j = 1:n
minJ = min(dataSet(:,j));
rangeJ = max(dataSet(:,j))-min(dataSet(:,j));
centroids(:,j) = minJ+rand(k,1)*rangeJ;%產(chǎn)生區(qū)間上的隨機(jī)數(shù)
end
end
計算相似性
[plain] view plain copy 在CODE上查看代碼片派生到我的代碼片
function [ dist ] = distence( vecA, vecB )
dist = (vecA-vecB)*(vecA-vecB)';%這里取歐式距離的平方
end
kMeans的主程序
[plain] view plain copy 在CODE上查看代碼片派生到我的代碼片
%% kMeans的核心程序,不斷迭代求解聚類中心
function [ centroids ] = kMeans( dataSet, k )
[m,n] = size(dataSet);
%初始化聚類中心
centroids = randCent(dataSet, k);
subCenter = zeros(m,2);%做一個m*2的矩陣�����,第一列存儲類別�,第二列存儲距離
change = 1;%判斷是否改變
while change == 1
change = 0;
%對每一組數(shù)據(jù)計算距離
for i = 1:m
minDist = inf;
minIndex = 0;
for j = 1:k
dist= distence(dataSet(i,:), centroids(j,:));
if dist < minDist
minDist = dist;
minIndex = j;
end
end
if subCenter(i,1) ~= minIndex
change = 1;
subCenter(i,:)=[minIndex, minDist];
end
end
%對k類重新就算聚類中心
for j = 1:k
sum = zeros(1,n);
r = 0;%數(shù)量
for i = 1:m
if subCenter(i,1) == j
sum = sum + dataSet(i,:);
r = r+1;
end
end
centroids(j,:) = sum./r;
end
end
%% 完成作圖
hold on
for i = 1:m
switch subCenter(i,1)
case 1
plot(dataSet(i,1), dataSet(i,2), '.b');
case 2
plot(dataSet(i,1), dataSet(i,2), '.g');
case 3
plot(dataSet(i,1), dataSet(i,2), '.r');
otherwise
plot(dataSet(i,1), dataSet(i,2), '.c');
end
end
plot(centroids(:,1),centroids(:,2),'+k');
end
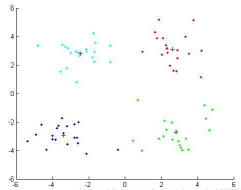
最終的聚類結(jié)果
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330