模式識(shí)別�����、機(jī)器學(xué)習(xí)����、數(shù)據(jù)挖掘當(dāng)中的各種距離總結(jié)
在做分類時(shí)常常需要估算不同樣本之間的相似性度量(SimilarityMeasurement),這時(shí)通常采用的方法就是計(jì)算樣本間的“距離”(Distance)�。采用什么樣的方法計(jì)算距離是很講究����,甚至關(guān)系到分類的正確與否�。
本文目錄:
1.歐氏距離
2.曼哈頓距離
3. 切比雪夫距離
4. 閔可夫斯基距離
5.標(biāo)準(zhǔn)化歐氏距離
6.馬氏距離
7.夾角余弦
8.漢明距離
9.杰卡德距離& 杰卡德相似系數(shù)
10.相關(guān)系數(shù)& 相關(guān)距離
11.信息熵
1. 歐氏距離(EuclideanDistance)
歐氏距離是最易于理解的一種距離計(jì)算方法,源自歐氏空間中兩點(diǎn)間的距離公式����。
(1)二維平面上兩點(diǎn)a(x1,y1)與b(x2,y2)間的歐氏距離:
(2)三維空間兩點(diǎn)a(x1,y1,z1)與b(x2,y2,z2)間的歐氏距離:
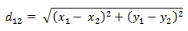
(3)兩個(gè)n維向量a(x11,x12,…,x1n)與 b(x21,x22,…,x2n)間的歐氏距離:
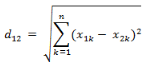
也可以用表示成向量運(yùn)算的形式:
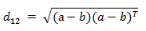
(4)Matlab計(jì)算歐氏距離
Matlab計(jì)算距離主要使用pdist函數(shù)。若X是一個(gè)M×N的矩陣����,則pdist(X)將X矩陣M行的每一行作為一個(gè)N維向量,然后計(jì)算這M個(gè)向量兩兩間的距離���。
例子:計(jì)算向量(0,0)、(1,0)�����、(0,2)兩兩間的歐式距離
X= [0 0 ; 1 0 ; 0 2]
D= pdist(X,'euclidean')
結(jié)果:
D=
1.0000 2.0000 2.2361
2. 曼哈頓距離(ManhattanDistance)
從名字就可以猜出這種距離的計(jì)算方法了��。想象你在曼哈頓要從一個(gè)十字路口開車到另外一個(gè)十字路口����,駕駛距離是兩點(diǎn)間的直線距離嗎���?顯然不是,除非你能穿越大樓����。實(shí)際駕駛距離就是這個(gè)“曼哈頓距離”。而這也是曼哈頓距離名稱的來源��, 曼哈頓距離也稱為城市街區(qū)距離(CityBlock distance)���。
(1)二維平面兩點(diǎn)a(x1,y1)與b(x2,y2)間的曼哈頓距離
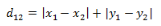
(2)兩個(gè)n維向量a(x11,x12,…,x1n)與b(x21,x22,…,x2n)間的曼哈頓距離
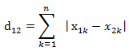
(3)Matlab計(jì)算曼哈頓距離
例子:計(jì)算向量(0,0)��、(1,0)��、(0,2)兩兩間的曼哈頓距離
X= [0 0 ; 1 0 ; 0 2]
D= pdist(X, 'cityblock')
結(jié)果:
D=
1 2 3
3. 切比雪夫距離 ( Chebyshev Distance )
國際象棋玩過么����?國王走一步能夠移動(dòng)到相鄰的8個(gè)方格中的任意一個(gè)����。那么國王從格子(x1,y1)走到格子(x2,y2)最少需要多少步?自己走走試試�。你會(huì)發(fā)現(xiàn)最少步數(shù)總是max(| x2-x1 | , | y2-y1 | ) 步。有一種類似的一種距離度量方法叫切比雪夫距離���。
(1)二維平面兩點(diǎn)a(x1,y1)與b(x2,y2)間的切比雪夫距離
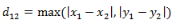
(2)兩個(gè)n維向量a(x11,x12,…,x1n)與b(x21,x22,…,x2n)間的切比雪夫距離
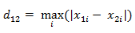
這個(gè)公式的另一種等價(jià)形式是
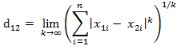
看不出兩個(gè)公式是等價(jià)的��?提示一下:試試用放縮法和夾逼法則來證明����。
(3)Matlab計(jì)算切比雪夫距離
例子:計(jì)算向量(0,0)、(1,0)��、(0,2)兩兩間的切比雪夫距離
X= [0 0 ; 1 0 ; 0 2]
D= pdist(X, 'chebychev')
結(jié)果:
D=
1 2 2
4. 閔可夫斯基距離(MinkowskiDistance)
閔氏距離不是一種距離��,而是一組距離的定義�����。
(1)閔氏距離的定義
兩個(gè)n維變量a(x11,x12,…,x1n)與b(x21,x22,…,x2n)間的閔可夫斯基距離定義為:
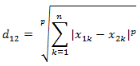
其中p是一個(gè)變參數(shù)���。
當(dāng)p=1時(shí)����,就是曼哈頓距離
當(dāng)p=2時(shí)���,就是歐氏距離
當(dāng)p→∞時(shí),就是切比雪夫距離
根據(jù)變參數(shù)的不同����,閔氏距離可以表示一類的距離��。
(2)閔氏距離的缺點(diǎn)
閔氏距離���,包括曼哈頓距離、歐氏距離和切比雪夫距離都存在明顯的缺點(diǎn)����。
舉個(gè)例子:二維樣本(身高,體重),其中身高范圍是150~190����,體重范圍是50~60,有三個(gè)樣本:a(180,50)����,b(190,50),c(180,60)����。那么a與b之間的閔氏距離(無論是曼哈頓距離、歐氏距離或切比雪夫距離)等于a與c之間的閔氏距離�����,但是身高的10cm真的等價(jià)于體重的10kg么?因此用閔氏距離來衡量這些樣本間的相似度很有問題�。
簡單說來,閔氏距離的缺點(diǎn)主要有兩個(gè):(1)將各個(gè)分量的量綱(scale)�����,也就是“單位”當(dāng)作相同的看待了�����。(2)沒有考慮各個(gè)分量的分布(期望�����,方差等)可能是不同的����。
(3)Matlab計(jì)算閔氏距離
例子:計(jì)算向量(0,0)、(1,0)�����、(0,2)兩兩間的閔氏距離(以變參數(shù)為2的歐氏距離為例)
X= [0 0 ; 1 0 ; 0 2]
D= pdist(X,'minkowski',2)
結(jié)果:
D=
1.0000 2.0000 2.2361
5. 標(biāo)準(zhǔn)化歐氏距離(Standardized Euclidean distance )
(1)標(biāo)準(zhǔn)歐氏距離的定義
標(biāo)準(zhǔn)化歐氏距離是針對(duì)簡單歐氏距離的缺點(diǎn)而作的一種改進(jìn)方案����。標(biāo)準(zhǔn)歐氏距離的思路:既然數(shù)據(jù)各維分量的分布不一樣,好吧�����!那我先將各個(gè)分量都“標(biāo)準(zhǔn)化”到均值����、方差相等吧。均值和方差標(biāo)準(zhǔn)化到多少呢���?這里先復(fù)習(xí)點(diǎn)統(tǒng)計(jì)學(xué)知識(shí)吧���,假設(shè)樣本集X的均值(mean)為m,標(biāo)準(zhǔn)差(standarddeviation)為s�,那么X的“標(biāo)準(zhǔn)化變量”表示為:
而且標(biāo)準(zhǔn)化變量的數(shù)學(xué)期望為0,方差為1�����。因此樣本集的標(biāo)準(zhǔn)化過程(standardization)用公式描述就是:
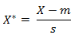
標(biāo)準(zhǔn)化后的值 = ( 標(biāo)準(zhǔn)化前的值 - 分量的均值 ) /分量的標(biāo)準(zhǔn)差
經(jīng)過簡單的推導(dǎo)就可以得到兩個(gè)n維向量a(x11,x12,…,x1n)與b(x21,x22,…,x2n)間的標(biāo)準(zhǔn)化歐氏距離的公式:
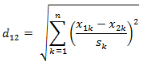
如果將方差的倒數(shù)看成是一個(gè)權(quán)重����,這個(gè)公式可以看成是一種加權(quán)歐氏距離(WeightedEuclidean distance)。
(2)Matlab計(jì)算標(biāo)準(zhǔn)化歐氏距離
例子:計(jì)算向量(0,0)、(1,0)���、(0,2)兩兩間的標(biāo)準(zhǔn)化歐氏距離 (假設(shè)兩個(gè)分量的標(biāo)準(zhǔn)差分別為0.5和1)
X= [0 0 ; 1 0 ; 0 2]
D= pdist(X, 'seuclidean',[0.5,1])
結(jié)果:
D=
2.0000 2.0000 2.8284
6. 馬氏距離(MahalanobisDistance)
(1)馬氏距離定義
有M個(gè)樣本向量X1~Xm���,協(xié)方差矩陣記為S,均值記為向量μ�����,則其中樣本向量X到u的馬氏距離表示為:
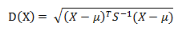
而其中向量Xi與Xj之間的馬氏距離定義為:
若協(xié)方差矩陣是單位矩陣(各個(gè)樣本向量之間獨(dú)立同分布),則公式就成了:
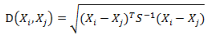
也就是歐氏距離了����。
若協(xié)方差矩陣是對(duì)角矩陣,公式變成了標(biāo)準(zhǔn)化歐氏距離�����。
(2)馬氏距離的優(yōu)缺點(diǎn):量綱無關(guān)���,排除變量之間的相關(guān)性的干擾�����。
(3)Matlab計(jì)算(1 2)����,( 1 3),( 2 2)����,( 3 1)兩兩之間的馬氏距離
X = [1 2; 1 3; 2 2; 3 1]
Y = pdist(X,'mahalanobis')
結(jié)果:
Y=
2.3452 2.0000 2.3452 1.2247 2.4495 1.2247
7. 夾角余弦(Cosine)
有沒有搞錯(cuò)����,又不是學(xué)幾何,怎么扯到夾角余弦了���?各位看官稍安勿躁�����。幾何中夾角余弦可用來衡量兩個(gè)向量方向的差異���,機(jī)器學(xué)習(xí)中借用這一概念來衡量樣本向量之間的差異。
(1)在二維空間中向量A(x1,y1)與向量B(x2,y2)的夾角余弦公式:
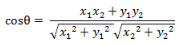
(2)兩個(gè)n維樣本點(diǎn)a(x11,x12,…,x1n)和b(x21,x22,…,x2n)的夾角余弦
類似的���,對(duì)于兩個(gè)n維樣本點(diǎn)a(x11,x12,…,x1n)和b(x21,x22,…,x2n)��,可以使用類似于夾角余弦的概念來衡量它們間的相似程度��。
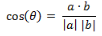
即: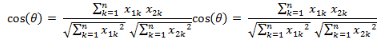
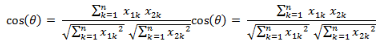
夾角余弦取值范圍為[-1,1]�����。夾角余弦越大表示兩個(gè)向量的夾角越小��,夾角余弦越小表示兩向量的夾角越大�����。當(dāng)兩個(gè)向量的方向重合時(shí)夾角余弦取最大值1���,當(dāng)兩個(gè)向量的方向完全相反夾角余弦取最小值-1�����。
夾角余弦的具體應(yīng)用可以參閱參考文獻(xiàn)[1]��。
(3)Matlab計(jì)算夾角余弦
例子:計(jì)算(1,0)����、( 1,1.732)���、(-1,0)兩兩間的夾角余弦
X= [1 0 ; 1 1.732 ; -1 0]
D= 1- pdist(X, 'cosine') % Matlab中的pdist(X,'cosine')得到的是1減夾角余弦的值
結(jié)果:
D=
0.5000 -1.0000 -0.5000
8. 漢明距離(Hammingdistance)
(1)漢明距離的定義
兩個(gè)等長字符串s1與s2之間的漢明距離定義為將其中一個(gè)變?yōu)榱硗庖粋€(gè)所需要作的最小替換次數(shù)���。例如字符串“1111”與“1001”之間的漢明距離為2�����。
應(yīng)用:信息編碼(為了增強(qiáng)容錯(cuò)性���,應(yīng)使得編碼間的最小漢明距離盡可能大)���。
(2)Matlab計(jì)算漢明距離
Matlab中2個(gè)向量之間的漢明距離的定義為2個(gè)向量不同的分量所占的百分比��。
例子:計(jì)算向量(0,0)�����、(1,0)���、(0,2)兩兩間的漢明距離
X = [0 0 ; 1 0 ; 0 2];
D = PDIST(X, 'hamming')
結(jié)果:
D=
0.5000 0.5000 1.0000
9. 杰卡德相似系數(shù)(Jaccardsimilarity coefficient)
(1) 杰卡德相似系數(shù)
兩個(gè)集合A和B的交集元素在A,B的并集中所占的比例�,稱為兩個(gè)集合的杰卡德相似系數(shù),用符號(hào)J(A,B)表示����。
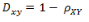
杰卡德相似系數(shù)是衡量兩個(gè)集合的相似度一種指標(biāo)�����。
(2) 杰卡德距離
與杰卡德相似系數(shù)相反的概念是杰卡德距離(Jaccarddistance)����。杰卡德距離可用如下公式表示:
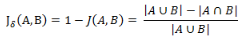
杰卡德距離用兩個(gè)集合中不同元素占所有元素的比例來衡量兩個(gè)集合的區(qū)分度�����。
(3)杰卡德相似系數(shù)與杰卡德距離的應(yīng)用
可將杰卡德相似系數(shù)用在衡量樣本的相似度上�����。
樣本A與樣本B是兩個(gè)n維向量�����,而且所有維度的取值都是0或1���。例如:A(0111)和B(1011)�。我們將樣本看成是一個(gè)集合����,1表示集合包含該元素���,0表示集合不包含該元素。
p:樣本A與B都是1的維度的個(gè)數(shù)
q:樣本A是1�,樣本B是0的維度的個(gè)數(shù)
r:樣本A是0,樣本B是1的維度的個(gè)數(shù)
s:樣本A與B都是0的維度的個(gè)數(shù)
那么樣本A與B的杰卡德相似系數(shù)可以表示為:
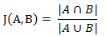
這里p+q+r可理解為A與B的并集的元素個(gè)數(shù)���,而p是A與B的交集的元素個(gè)數(shù)�����。
而樣本A與B的杰卡德距離表示為:
(4)Matlab計(jì)算杰卡德距離
Matlab的pdist函數(shù)定義的杰卡德距離跟我這里的定義有一些差別��,Matlab中將其定義為不同的維度的個(gè)數(shù)占“非全零維度”的比例。
例子:計(jì)算(1,1,0)���、(1,-1,0)��、(-1,1,0)兩兩之間的杰卡德距離
X= [1 1 0; 1 -1 0; -1 1 0]
D= pdist( X , 'jaccard')
結(jié)果
D=
0.5000 0.5000 1.0000
10. 相關(guān)系數(shù)( Correlation coefficient )與相關(guān)距離(Correlation distance)
(1)相關(guān)系數(shù)的定義
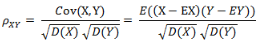
相關(guān)系數(shù)是衡量隨機(jī)變量X與Y相關(guān)程度的一種方法���,相關(guān)系數(shù)的取值范圍是[-1,1]。相關(guān)系數(shù)的絕對(duì)值越大���,則表明X與Y相關(guān)度越高����。當(dāng)X與Y線性相關(guān)時(shí),相關(guān)系數(shù)取值為1(正線性相關(guān))或-1(負(fù)線性相關(guān))��。
(2)相關(guān)距離的定義
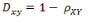
(3)Matlab計(jì)算(1, 2 ,3 ,4 )與( 3 ,8 ,7 ,6 )之間的相關(guān)系數(shù)與相關(guān)距離
X = [1 2 3 4 ; 3 8 7 6]
C = corrcoef( X' ) %將返回相關(guān)系數(shù)矩陣
D = pdist( X , 'correlation')
結(jié)果:
C=
1.0000 0.4781
0.4781 1.0000
D=
0.5219
其中0.4781就是相關(guān)系數(shù)����,0.5219是相關(guān)距離。
11. 信息熵(Information Entropy)
信息熵并不屬于一種相似性度量�����。那為什么放在這篇文章中?�?��?這個(gè)�����。�。���。我也不知道���。 (╯▽╰)
信息熵是衡量分布的混亂程度或分散程度的一種度量���。分布越分散(或者說分布越平均),信息熵就越大�。分布越有序(或者說分布越集中),信息熵就越小�����。
計(jì)算給定的樣本集X的信息熵的公式:
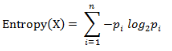
參數(shù)的含義:
n:樣本集X的分類數(shù)
pi:X中第i類元素出現(xiàn)的概率
信息熵越大表明樣本集S分類越分散���,信息熵越小則表明樣本集X分類越集中����。���。當(dāng)S中n個(gè)分類出現(xiàn)的概率一樣大時(shí)(都是1/n),信息熵取最大值log2(n)��。當(dāng)X只有一個(gè)分類時(shí)��,信息熵取最小值0數(shù)據(jù)分析師培訓(xùn)
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330