機(jī)器學(xué)習(xí)實戰(zhàn)之SVD
1. 奇異值分解 SVD(singular value decomposition)
1.1 SVD評價
優(yōu)點: 簡化數(shù)據(jù), 去除噪聲和冗余信息, 提高算法的結(jié)果
缺點: 數(shù)據(jù)的轉(zhuǎn)換可能難以理解
1.2 SVD應(yīng)用
(1) 隱性語義索引(latent semantic indexing, LSI)/隱性語義分析(latent semantic analysis, LSA)
在LSI中, 一個矩陣由文檔和詞語組成的.在該矩陣上應(yīng)用SVD可以構(gòu)建多個奇異值, 這些奇異值代表文檔中的概念或主題, 可以用于更高效的文檔搜索.
(2) 推薦系統(tǒng)
先利用SVD從數(shù)據(jù)中構(gòu)建一個主題空間, 然后在該主題空間下計算相似度.
1.3 SVD分解
SVD是一種矩陣分解技術(shù),其將原始的數(shù)據(jù)集矩陣A(m*n)分解為三個矩陣,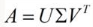 分解得到的三個矩陣的維度分別為m*m,m*n,n*n.其中
分解得到的三個矩陣的維度分別為m*m,m*n,n*n.其中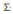 除了對角元素不為0,其它元素均為0,其對角元素稱為奇異值,且按從大到小的順序排列, 這些奇異值對應(yīng)原始數(shù)據(jù)集矩陣A的奇異值,即A*A(T)的特征值的平方根.
除了對角元素不為0,其它元素均為0,其對角元素稱為奇異值,且按從大到小的順序排列, 這些奇異值對應(yīng)原始數(shù)據(jù)集矩陣A的奇異值,即A*A(T)的特征值的平方根.
在某個奇異值(r個)之后, 其它的奇異值由于值太小,被忽略置為0, 這就意味著數(shù)據(jù)集中僅有r個重要特征,而其余特征都是噪聲或冗余特征.如下圖所示:

問題: 如何選擇數(shù)值r?
解答: 確定要保留的奇異值數(shù)目有很多啟發(fā)式的策略,其中一個典型的做法就是保留矩陣中90%的能量信息.為了計算能量信息,將所有的奇異值求其平方和,從大到小疊加奇異值,直到奇異值之和達(dá)到總值的90%為止;另一種方法是,當(dāng)矩陣有上萬個奇異值時, 直接保留前2000或3000個.,但是后一種方法不能保證前3000個奇異值能夠包含錢90%的能量信息,但是操作簡單.
****SVD分解很耗時,通過離線方式計算SVD分解和相似度計算,是一種減少冗余計算和推薦所需時間的辦法.
2. 基于協(xié)同過濾的推薦引擎
2.1 定義
協(xié)同過濾是通過將用戶和其他用戶的數(shù)據(jù)進(jìn)行對比來實現(xiàn)推薦的.
例如: 試圖對某個用戶喜歡的電影進(jìn)行預(yù)測,搜索引擎會發(fā)現(xiàn)有一部電影該用戶還沒看過,然后它會計算該電影和用戶看過的電影之間的相似度, 如果相似度很高, 推薦算法就會認(rèn)為用戶喜歡這部電影.
缺點: 在協(xié)同過濾情況下, 由于新物品到來時由于缺乏所有用戶對其的喜好信息,因此無法判斷每個用戶對其的喜好.而無法判斷某個用戶對其的喜好,也就無法利用該商品.
2.2 相似度計算
協(xié)同過濾利用用戶對食物的意見來計算相似度,下圖給出了一些用戶對菜的評級信息所組成的矩陣:
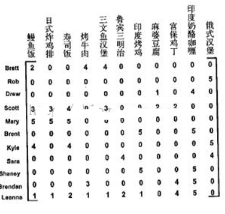
定義相似度在0-1之間變化,且物品對越相似,其相似度值越大,可以使用公式 相似度 = 1/(1 + 距離) 來計算相似度.
計算距離的方法如下:
(1) 歐氏距離
(2)皮爾遜相關(guān)系數(shù)(pearson correlation)
度量兩個向量間的相似度,該方法優(yōu)于歐氏在于其對用戶評級的量級不敏感,例如某個人對所有物品的評分都是5分,另一個人對所有物品評分都是1分,皮爾遜相關(guān)系數(shù)認(rèn)為這兩個評分向量是相等的. 不過皮爾遜相關(guān)系數(shù)的取值范圍是(-1,1),通過0.5 + 0.5 * corrcoef()將其歸一化到0-1之間.
(3) 余弦相似度( cosine similarity)
計算的是兩個向量夾角的余弦值.其取值范圍是(-1,1),因此也要將其歸一化到(0,1)區(qū)間.
以下是這三種相似度計算方法的代碼實現(xiàn):
<span style="font-size:18px;">def eulidSim(in1,in2):
return 1.0/(1.0+la.norm(in1-in2))
def pearsonSim(in1,in2):
if len(in1) < 3: #檢查是否存在3個或更多的點,小于的話,這兩個向量完全相關(guān)
return 1.0
return 0.5 + 0.5 * corrcoef(in1,in2,rowvar = 0)[0][1]
</span><span style="font-size:18px;"> def cosSim(in1,in2):
num = float(in1.T * in2)
denom = la.norm(in1) * la.norm(in2)
return 0.5 + 0.5 * (num/denom)
</span>
2.3 餐館菜推薦引擎
(1) 用處: 推薦餐館食物. 給定一個用戶, 系統(tǒng)會為此用戶推薦N個最好的推薦菜.為了實現(xiàn)這一目的,要做到:
尋找用戶沒有評級的菜, 即在用戶-物品矩陣中的0值;
在用戶沒有評級的所有物品中,對每個物品預(yù)計一個可能的評級分?jǐn)?shù).
對這些物品的評分從高到低進(jìn)行排序,返回前n個物品
下面是實現(xiàn)代碼:
<span style="font-size:18px;">#計算在給定相似度計算方法的條件下,用戶user對物品item的估計評分值
def standEst(dataMat,user,simMea,item):
n = shape(dataMat)[1]
simTotal = 0.0
ratSimTotal = 0.0
for j in range(n):
userRate = dataMat[user,j]
if userRate == 0 :
continue
#得到對菜item和j都評過分的用戶id,用來計算物品item和j之間的相似度
overlap = nonzero(logical_and(dataMat[:,item].A>0,dataMat[:,j].A>0))[0]
if len(overlap) == 0:
similarity = 0
else:
#計算物品item和j之間的相似度(必須選取用戶對這兩個物品都評分的用戶分?jǐn)?shù)構(gòu)成物品分?jǐn)?shù)向量)
similarity = simMea(dataMat[overlap,item],dataMat[overlap,j])
simTotal += similarity
ratSimTotal += similarity * userRate
if simTotal ==0:
return 0
else:
return ratSimTotal/simTotal #歸一化處理
#輸入依次是數(shù)據(jù)矩陣,用戶編號,返回的菜的個數(shù),距離計算方法,獲得物品評分的函數(shù)
def recommend(dataMat,user,n=3,simMea=cosSim,estMethod=standEst):
#返回user用戶未評分的菜的下標(biāo)
unratedItem = nonzero(dataMat[user,:].A == 0)[1]
if(len(unratedItem) == 0):
return 'you rated every one'
itemScore = []
#對每個沒評分的菜都估計該用戶可能賦予的分?jǐn)?shù)
for item in unratedItem:
score = estMethod(dataMat,user,simMea,item)
itemScore.append((item,score))
#返回評分最高的前n個菜下標(biāo)以及分?jǐn)?shù)
return sorted(itemScore, key = lambda jj:jj[1],reverse = True)[:n]</span>
2.4 利用SVD提高推薦效果
實際的數(shù)據(jù)集得到的矩陣相當(dāng)稀疏,因此可以先利用SVD將原始矩陣映射到低維空間中,; 然后再在低維空間中, 計算物品間的相似度,大大減少計算量.
其代碼實現(xiàn)如下:
<span style="font-size:18px;">#通過SVD對原始數(shù)據(jù)矩陣降維,便于計算物品間的相似度
def scdEst(dataMat,user,simMea,item):
n = shape(dataMat)[1]
simTotal = 0.0
ratSimTotal = 0.0
u,sigma,vt = la.svd(dataMat) #sigma是行向量
sig4 = mat(eye(4) * sigma[:4]) #只利用最大的4個奇異值,將其轉(zhuǎn)換為4*4矩陣,非對角元素為0
xformedItems = dataMat.T * u[:,:4] * sig4.I #得到n*4
for j in range(n):
userRate = dataMat[user,j]
if userRate == 0 or j == item:
continue
#得到對菜item和j都評過分的用戶id,用來計算物品item和j之間的相似度
#overlap = nonzero(logical_and(dataMat[:,item].A>0,dataMat[:,j].A>0))[0]
#if len(overlap) == 0:
# similarity = 0
#else:
#計算物品item和j之間的相似度
# similarity = simMea(dataMat[overlap,item],dataMat[overlap,j])
similarity = simMea(xformedItems[item,:].T,xformedItems[j,:].T)
simTotal += similarity
ratSimTotal += similarity * userRate
if simTotal ==0:
return 0
else:
return ratSimTotal/simTotal #歸一化處理</span>
3. 基于SVD的圖像壓縮
<span style="font-size:18px;">#打印矩陣
def printMat(in1,thresh=0.8):
for i in range(32):
for k in range(32):
if(float(in1[i,k]) > thresh):
print 1,
else:
print 0,
print ''
#利用SVD實現(xiàn)圖像壓縮,允許基于任意給定的奇異值來重構(gòu)圖像,默認(rèn)去前3個奇異值
def imgCompress(numSV=3,thresh=0.8):
#32*32 matrix
my1 = []
for line in open('0_5.txt').readlines():
newrow = []
for i in range(32):
newrow.append(int(line[i]))
my1.append(newrow)
myMat = mat(my1)
print '***original matrix***'
printMat(myMat)
u,sigma,vt = la.svd(myMat)
#將sigma矩陣化,即sigrecon的對角元素是sigma的元素
sigrecon = mat(zeros((numSV,numSV)))
for k in range(numSV):
sigrecon[k,k] = sigma[k]
#重構(gòu)矩陣
reconMat = u[:,:numSV] * sigrecon * vt[:numSV,:]
print '***reconstruct matrix***'
printMat(reconMat)</span>
以數(shù)字為例:數(shù)字0存儲為32*32的矩陣,需要存儲1024個數(shù)據(jù); 通過實驗發(fā)現(xiàn)只需要2個奇異值就能夠很精確地對圖像進(jìn)行重構(gòu),u,vt的大小都是32*2的矩陣,再加上2個奇異值,則需要32*2*2+2=130個0-1值來存儲0;通過對比發(fā)現(xiàn),實現(xiàn)了幾乎10倍的壓縮比.
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330