機器學習實戰(zhàn)之Apriori
1. 關(guān)聯(lián)分析
1.1 定義
關(guān)聯(lián)分析是一種在大規(guī)模數(shù)據(jù)上尋找物品間隱含關(guān)系的一種任務(wù).這種關(guān)系有2種形式:頻繁項集和關(guān)聯(lián)規(guī)則.
(1) 頻繁項集(frequent item sets): 經(jīng)常出現(xiàn)在一起的物品的集合;
(2) 關(guān)聯(lián)規(guī)則(association rules): 暗示兩種物品之間可能存在很強的關(guān)系.
1.2 量化關(guān)聯(lián)分析是否成功的算法
支持度和可信度是用來量化關(guān)聯(lián)分析是否成功的方法.
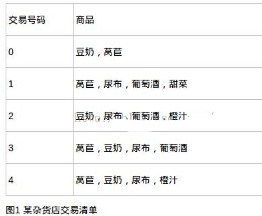
(1)支持度(support) : 一個項集的支持度被定義為數(shù)據(jù)集中包含該項集的記錄所占的比例. 支持度針對項集而言,可以設(shè)置最小支持度,只保留滿足最小支持度的項集.以下圖中的清 單為例, {豆奶}的支持度為4/5;{豆奶,尿布}的支持度為3/5.
(2) 可信度或置信度(confidence) : 針對關(guān)聯(lián)規(guī)則定義的. 例如: 規(guī)則{尿布}->{葡萄酒}的可信度被定義為 "支持度{尿布,葡萄酒}/支持度{尿布}" . 支持度{尿布,葡萄酒}為3/5 , 支持度{尿布} 為4/5, 即這條規(guī)則可信度為3/4. 這意味著對于包含"尿布"的所有記錄,我們的規(guī)則對其中75%的記錄都適用.
2. Apriori
2.1 問題: 假設(shè)一家商店里只有4種商品:0,1,2,3. 下圖顯示了所有可能被購買的商品組合:
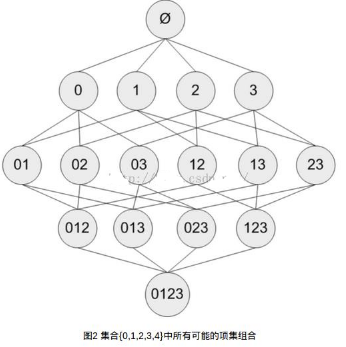
對于單個項集的支持度, 通過遍歷每條記錄并檢查該記錄是否包含該項集來計算.但是對于包含N種物品的數(shù)據(jù)集共有中項集組合,重復計算上述過程是不現(xiàn)實的.
2.2 Apriori原理
Apriori原理能夠減少計算量.
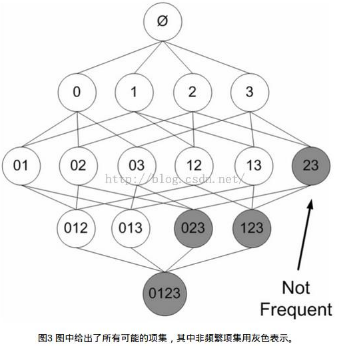
其內(nèi)容是: 若某個項集是頻繁的, 那么它的子集也是頻繁的; 則其逆否命題也是正確的,即 若一個項集是非頻繁的, 則它的所有超集也是非頻繁的.
舉例說明: 已知陰影項集{2,3}是非頻繁的����。利用這個知識,我們就知道項集{0,2,3}�����,{1,2,3}以及{0,1,2,3}也是非頻繁的���。也就是說���,一旦計算出了{2,3}的支持度���,知道它是非頻繁的后���,就可以緊接著排除{0,2,3}、{1,2,3}和{0,1,2,3}�����。使用該原理可以避免項集數(shù)目的指數(shù)增長,從而在合理時間內(nèi)計算出頻繁項集.
2.3 實現(xiàn)Apriori算法來發(fā)現(xiàn)頻繁項集
(1) Apriori算法是發(fā)現(xiàn)頻繁項集的一種方法. 其兩個輸入?yún)?shù)分別是數(shù)據(jù)集和最小支持度.
(2) Apriori算法流程:
首先生成所有單個物品的項集列表; 然后掃描交易記錄查看哪些項集滿足最小支持度要求,去掉不滿足最小支持度的項集.
對剩下來的集合進行組合以生成包含兩個元素的項集; 然后掃描交易記錄查看哪些項集滿足最小支持度要求,去掉不滿足最小支持度的項集.
上述過程重復直到所有項集都被去掉
(3) Apriori算法生成頻繁項集的偽代碼
對數(shù)據(jù)集中的每條交易記錄tran:
對每個候選項集can:
檢查交易記錄tran是否包含候選項集can:
若包含,則增加can的計數(shù);
對每個候選項集:
若該候選項集的支持度不低于最小支持度, 則保留; 反之, 則去掉.
返回所有頻繁項集列表
其具體實現(xiàn)代碼如下:
<span style="font-size:18px;">#c1是所有單個物品的集合
def createC1(dataSet):
c1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in c1:
c1.append([item])
c1.sort()
return map(frozenset,c1) #frozenset是不能改變的集合,用戶不能修改
#由ck得到lk的過程,即從ck選出支持度不小于指定值的項構(gòu)成lk
def scanD(data,ck,minSupport):
#統(tǒng)計每個候選項集及其對應的出現(xiàn)次數(shù)
ssCnt = {}
for transaction in data:
for can in ck:
if can.issubset(transaction):
if not ssCnt.has_key(can):
ssCnt[can] = 1
else:
ssCnt[can] += 1
#去掉不滿足最小支持度的候選項集
numItems = float(len(data))
retList = [] #存儲滿足支持度不低于最小值的項集
supportData = {} #存儲所有項集及其支持度
for key in ssCnt:
support = ssCnt[key]/numItems
if support >= minSupport:
retList.insert(0,key)
supportData[key] = support
return retList,supportData #返回的retlist是ck中滿足最小支持度項集的集合</span>
(4) Apriori完整的實現(xiàn)
整個Apriori算法的偽代碼如下:
當集合中項的個數(shù)大于0時:
構(gòu)建一個k個項組成的候選項集的列表(k從1開始)
遍歷數(shù)據(jù)集來篩選并保留候選項集列表中滿足最小支持度的項集
構(gòu)建由k+1個項組成的候選項集的列表
以下是實現(xiàn)代碼:
<span style="font-size:18px;">#由頻繁集lk和項集個數(shù)生成候選集ck,其中l(wèi)k中每一項中含有元素k-1個,生成的ck中每一項中含有元素k個
def aprioriGen(lk,k):
retList = []
lenlk = len(lk)
#retList可能會為空
for i in range(lenlk):
for j in range(i+1,lenlk):
#只有在兩項中前k-2個元素一樣時,將這兩個集合合并(這樣合并得到的大小就為k)
l1 = list(lk[i])[:k-2]
l2 = list(lk[j])[:k-2]
l1.sort(); l2.sort()
if l1 == l2:
retList.append(lk[i] | lk[j])
return retList</span>
*** 在候選項集生成過程中, 只有在前k-2個項相同時才合并, 原始頻繁項集中每一項含有k-1個元素, 為了合成得到每一項大小是k的候選項集列表,只有在前k-2項相同時,最后一項不同時,才有可能得到頻繁項集.注意這里不是兩兩合并, 因為限制了候選項集的大小.
<span style="font-size:18px;">def apriori(dataSet,minSupport = 0.5):
#單獨產(chǎn)生c1,l1
c1 = createC1(dataSet)
data = map(set,dataSet)
l1,supportData = scanD(data,c1,minSupport) #得到l1,大小為1的頻繁項集集合
#由l1得到c2,c2得到l2,依次循環(huán)
l = [l1]
k = 2
#當lk為空時,退出循環(huán)
while (len(l[k-2]) > 0):
ck = aprioriGen(l[k-2],k)
lk,supportK = scanD(data,ck,minSupport)
supportData.update(supportK)
l.append(lk)
k += 1
return l,supportData #所有的頻繁集及其支持度</span>
3. 從頻繁項集中挖掘相關(guān)規(guī)則
3.1 關(guān)聯(lián)規(guī)則的量化指標是可信度.
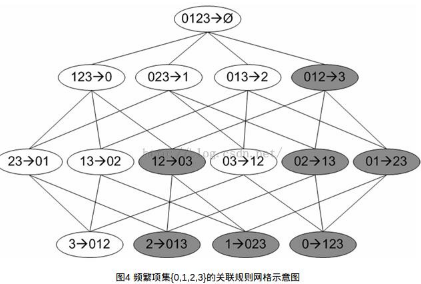
一條規(guī)則P?H的可信度定義為support(P | H)/support(P)���,其中“|”表示P和H的并集�。可見可信度的計算是基于項集的支持度的����。
下圖給出一個頻繁項集{0,1,2,3}產(chǎn)生的關(guān)聯(lián)規(guī)則, 其中陰影區(qū)域給出的是低可信度的規(guī)則.可以發(fā)現(xiàn)如果{0,1,2}?{3}是一條低可信度規(guī)則,那么所有其他以3作為后件(箭頭右部包含3)的規(guī)則均為低可信度的.因為{3}的支持度肯定比包含3的項集的支持度要高, 即分子沒變,但是分母增加, 則得到的可信度就降低了.
結(jié)論:若某條規(guī)則不滿足最小可信度要求, 則其規(guī)則的所有子集也不會滿足最小可信度要求. 以圖4為例���,假設(shè)規(guī)則{0,1,2} ? {3}并不滿足最小可信度要求�,那么就知道任何左部為{0,1,2}子集的規(guī)則也不會滿足最小可信度要求��。
利用此結(jié)論可以大大減少需要測試的規(guī)則數(shù)目.
3.2 關(guān)聯(lián)規(guī)則生成函數(shù)
函數(shù)generateRules()是主函數(shù),調(diào)用另2個函數(shù).其他兩個函數(shù)是rulesFromConseq()和calcConf()�,分別用于生成候選規(guī)則集合以及對規(guī)則進行評估(計算可信度)。
(1) 函數(shù)generateRules()有3個參數(shù):頻繁項集列表L�����、包含那些頻繁項集支持數(shù)據(jù)的字典supportData���、最小可信度閾值minConf�����。函數(shù)最后要生成一個包含可信度的規(guī)則列表bigRuleList�����,后面可以基于可信度對它們進行排序�。L和supportData正好為函數(shù)apriori()的輸出。該函數(shù)遍歷L中的每一個頻繁項集����,并對每個頻繁項集構(gòu)建只包含單個元素集合的列表H1。代碼中的i指示當前遍歷的頻繁項集包含的元素個數(shù)����,freqSet為當前遍歷的頻繁項集(回憶L的組織結(jié)構(gòu)是先把具有相同元素個數(shù)的頻繁項集組織成列表,再將各個列表組成一個大列表����,所以為遍歷L中的頻繁項集,需要使用兩層for循環(huán))����。
<span style="font-size:18px;">#關(guān)聯(lián)規(guī)則生成函數(shù)
def generateRules(L,supportData,minConf=0.7):
#存儲所有關(guān)聯(lián)規(guī)則
bigRuleList = []
for i in range(1,len(L)): #一條關(guān)聯(lián)規(guī)則至少需要2個元素,故下標從1開始
for freqSet in L[i]: #frequent為大小為i的項集
H1 = [] #對每個頻繁項集構(gòu)了,建只包含單個元素的集合,即可以出現(xiàn)在規(guī)則右邊
for item in freqSet:
H1.append(frozenset([item]))
if (i > 1):
H1 = calcConf(freqSet,H1,supportData,bigRuleList,minConf)
#包含三個及以上元素的頻繁集
rulesFromConseq(freqSet,H1,supportData,bigRuleList,minConf)
else:
#包含兩個元素的頻繁集
calcConf(freqSet,H1,supportData,bigRuleList,minConf)
return bigRuleList</span>
(2)calcConf函數(shù): 計算規(guī)則的可信度���,并過濾出滿足最小可信度要求的規(guī)則. 返回值prunedH保存規(guī)則列表的右部�,這個值將在下一個函數(shù)rulesFromConseq()中用到���。
函數(shù)實現(xiàn)代碼如下:
<span style="font-size:18px;">#處理包含兩個元素的頻繁集,計算規(guī)則的可信度��,并過濾出滿足最小可信度要求的規(guī)則
def calcConf(freqSet,H,supportData,brl,minConf=0.7):
#保存關(guān)聯(lián)規(guī)則的列表
prunedH = []
for conseq in H:
#對一個頻繁集合,其分母都是一樣的,supprot{1,2}/support{1},supprot{1,2}/support{2}
conf = supportData[freqSet]/supportData[freqSet-conseq]
if conf >= minConf:
print freqSet - conseq, '---->',conseq,' conf:',conf
brl.append((freqSet-conseq,conseq,conf))
prunedH.append(conseq)
return prunedH
</span>
(2) rulesFromConseq()函數(shù); 根據(jù)當前候選規(guī)則集H生成下一層候選規(guī)則集 ;
H為規(guī)則右邊可能出現(xiàn)的頻繁項集, H中元素的長度逐漸增大; 比如 原頻繁集包含3個元素,則出現(xiàn)在規(guī)則右邊的元素可能有1個,2個; 假設(shè)規(guī)則{0,1,2} ? {3}并不滿足最小可信度要求�����,那么就知道任何左部為{0,1,2}子集的規(guī)則也不會滿足最小可信度要求,即不考慮{0,1} ? {2,3}����。因此我們先從右邊只有一個元素時開始,只有存在可以出現(xiàn)在規(guī)則右邊的元素,右邊才有可能出現(xiàn)元素個數(shù)為2的情況.數(shù)據(jù)分析師培訓
代碼如下:
<span style="font-size:18px;">#根據(jù)當前候選規(guī)則集H生成下一層候選規(guī)則集,H是可以出現(xiàn)在規(guī)則右邊的元素列表
def rulesFromConseq(freqSet,H,supportData,brl,minConf=0.7):
#可以出現(xiàn)在規(guī)則右邊的元素個數(shù)[1]=1,[1,2]=2,從1個元素增加直到小于freqSet的總個數(shù)都行
m = len(H[0])
if (len(freqSet) > (m+1)):
hmp1 = aprioriGen(H,m+1) #產(chǎn)生大小為m+1的頻繁集列表,(1,2->3)->(1->2,3),生成下一層H
hmp1 = calcConf(freqSet,hmp1,supportData,brl,minConf)
if (len(hmp1) > 1):#規(guī)則右邊的元素個數(shù)還可以增加
rulesFromConseq(freqSet,hmp1,supportData,brl,minConf)</span>
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330