PageRank算法R語言實現(xiàn)
Google搜索,早已成為我每天必用的工具�����,無數(shù)次驚嘆它搜索結(jié)果的準確性�����。同時����,我也在做Google的SEO,推廣自己的博客�����。經(jīng)過幾個月嘗試,我的博客PR到2了�,外鏈也有幾萬個了?����?偨Y(jié)下來���,還是感嘆PageRank的神奇!
改變世界的算法����,PageRank!
目錄
PageRank算法介紹
PageRank算法原理
PageRank算法的R語言實現(xiàn)
1. PageRank算法介紹
PageRank是Google專有的算法����,用于衡量特定網(wǎng)頁相對于搜索引擎索引中的其他網(wǎng)頁而言的重要程度。它由Larry Page 和 Sergey Brin在20世紀90年代后期發(fā)明��。PageRank實現(xiàn)了將鏈接價值概念作為排名因素�����。
PageRank讓鏈接來”投票”
一個頁面的“得票數(shù)”由所有鏈向它的頁面的重要性來決定�����,到一個頁面的超鏈接相當于對該頁投一票。一個頁面的PageRank是由所有鏈向它的頁面(“鏈入頁面”)的重要性經(jīng)過遞歸算法得到的��。一個有較多鏈入的頁面會有較高的等級�,相反如果一個頁面沒有任何鏈入頁面,那么它沒有等級�。
簡單一句話概括:從許多優(yōu)質(zhì)的網(wǎng)頁鏈接過來的網(wǎng)頁,必定還是優(yōu)質(zhì)網(wǎng)頁����。
PageRank的計算基于以下兩個基本假設(shè):
數(shù)量假設(shè):如果一個頁面節(jié)點接收到的其他網(wǎng)頁指向的入鏈數(shù)量越多,那么這個頁面越重要
質(zhì)量假設(shè):指向頁面A的入鏈質(zhì)量不同���,質(zhì)量高的頁面會通過鏈接向其他頁面?zhèn)鬟f更多的權(quán)重����。所以越是質(zhì)量高的頁面指向頁面A����,則頁面A越重要。
要提高PageRank有3個要點:
反向鏈接數(shù)
反向鏈接是否來自PageRank較高的頁面
反向鏈接源頁面的鏈接數(shù)
2. PageRank算法原理
在初始階段:網(wǎng)頁通過鏈接關(guān)系構(gòu)建起有向圖��,每個頁面設(shè)置相同的PageRank值����,通過若干輪的計算���,會得到每個頁面所獲得的最終PageRank值。隨著每一輪的計算進行��,網(wǎng)頁當前的PageRank值會不斷得到更新����。
在一輪更新頁面PageRank得分的計算中,每個頁面將其當前的PageRank值平均分配到本頁面包含的出鏈上��,這樣每個鏈接即獲得了相應(yīng)的權(quán)值�����。而每個頁面將所有指向本頁面的入鏈所傳入的權(quán)值求和�����,即可得到新的PageRank得分��。當每個頁面都獲得了更新后的PageRank值�,就完成了一輪PageRank計算��。
1). 算法原理
PageRank算法建立在隨機沖浪者模型上,其基本思想是:網(wǎng)頁的重要性排序是由網(wǎng)頁間的鏈接關(guān)系所決定的�,算法是依靠網(wǎng)頁間的鏈接結(jié)構(gòu)來評價每個頁面的等級和重要性,一個網(wǎng)頁的PR值不僅考慮指向它的鏈接網(wǎng)頁數(shù)�����,還有指向’指向它的網(wǎng)頁的其他網(wǎng)頁本身的重要性���。
PageRank具有兩大特性:
PR值的傳遞性:網(wǎng)頁A指向網(wǎng)頁B時�,A的PR值也部分傳遞給B
重要性的傳遞性:一個重要網(wǎng)頁比一個不重要網(wǎng)頁傳遞的權(quán)重要多
2). 計算公式:
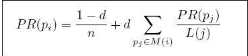
PR(pi): pi頁面的PageRank值
n: 所有頁面的數(shù)量
pi: 不同的網(wǎng)頁p1,p2,p3
M(i): pi鏈入網(wǎng)頁的集合
L(j): pj鏈出網(wǎng)頁的數(shù)量
d:阻尼系數(shù), 任意時刻����,用戶到達某頁面后并繼續(xù)向后瀏覽的概率�。 (1-d=0.15) :表示用戶停止點擊��,隨機跳到新URL的概率 取值范圍: 0 < d ≤ 1, Google設(shè)為0.85
3). 構(gòu)造實例:以4個頁面的數(shù)據(jù)為例
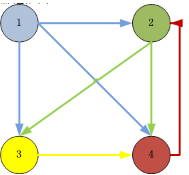
圖片說明:
ID=1的頁面鏈向2,3,4頁面,所以一個用戶從ID=1的頁面跳轉(zhuǎn)到2,3,4的概率各為1/3
ID=2的頁面鏈向3,4頁面����,所以一個用戶從ID=2的頁面跳轉(zhuǎn)到3,4的概率各為1/2
ID=3的頁面鏈向4頁面����,所以一個用戶從ID=3的頁面跳轉(zhuǎn)到4的概率各為1
ID=4的頁面鏈向2頁面���,所以一個用戶從ID=4的頁面跳轉(zhuǎn)到2的概率各為1
構(gòu)造鄰接表:
鏈接源頁面 鏈接目標頁面
1 2,3,4
2 3,4
3 4
4 2
構(gòu)造鄰接矩陣(方陣):
列:源頁面
行:目標頁面
[,1] [,2] [,3] [,4]
[1,] 0 0 0 0
[2,] 1 0 0 1
[3,] 1 1 0 0
[4,] 1 1 1 0
轉(zhuǎn)換為概率矩陣(轉(zhuǎn)移矩陣)
[,1] [,2] [,3] [,4]
[1,] 0 0 0 0
[2,] 1/3 0 0 1
[3,] 1/3 1/2 0 0
[4,] 1/3 1/2 1 0
通過鏈接關(guān)系�����,我們就構(gòu)造出了“轉(zhuǎn)移矩陣”�����。
3. R語言單機算法實現(xiàn)
創(chuàng)建數(shù)據(jù)文件:page.csv
1,2
1,3
1,4
2,3
2,4
3,4
4,2
分別用下面3種方式實現(xiàn)PageRank:
未考慮阻尼系統(tǒng)的情況
包括考慮阻尼系統(tǒng)的情況
直接用R的特征值計算函數(shù)
1). 未考慮阻尼系統(tǒng)的情況
R語言實現(xiàn)
#構(gòu)建鄰接矩陣
adjacencyMatrix<-function(pages){
n<-max(apply(pages,2,max))
A <- matrix(0,n,n)
for(i in 1:nrow(pages)) A[pages[i,]$dist,pages[i,]$src]<-1
A
}
#變換概率矩陣
probabilityMatrix<-function(G){
cs <- colSums(G)
cs[cs==0] <- 1
n <- nrow(G)
A <- matrix(0,nrow(G),ncol(G))
for (i in 1:n) A[i,] <- A[i,] + G[i,]/cs
A
}
#遞歸計算矩陣特征值
eigenMatrix<-function(G,iter=100){
iter<-10
n<-nrow(G)
x <- rep(1,n)
for (i in 1:iter) x <- G %*% x
x/sum(x)
}
> pages<-read.table(file="page.csv",header=FALSE,sep=",")
> names(pages)<-c("src","dist");pages
src dist
1 1 2
2 1 3
3 1 4
4 2 3
5 2 4
6 3 4
7 4 2
> A<-adjacencyMatrix(pages);A
[,1] [,2] [,3] [,4]
[1,] 0 0 0 0
[2,] 1 0 0 1
[3,] 1 1 0 0
[4,] 1 1 1 0
> G<-probabilityMatrix(A);G
[,1] [,2] [,3] [,4]
[1,] 0.0000000 0.0 0 0
[2,] 0.3333333 0.0 0 1
[3,] 0.3333333 0.5 0 0
[4,] 0.3333333 0.5 1 0
> q<-eigenMatrix(G,100);q
[,1]
[1,] 0.0000000
[2,] 0.4036458
[3,] 0.1979167
[4,] 0.3984375
結(jié)果解讀:
ID=1的頁面���,PR值是0,因為沒有指向ID=1的頁面
ID=2的頁面���,PR值是0.4,權(quán)重最高�,因為1和4都指向2,4權(quán)重較高�,并且4只有一個鏈接指向到2,權(quán)重傳遞沒有損失
ID=3的頁面�����,PR值是0.19,雖有1和2的指向了3���,但是1和2還指向的其他頁面���,權(quán)重被分散了,所以ID=3的頁面PR并不高
ID=4的頁面��,PR值是0.39��,權(quán)重很高����,因為被1,2,3都指向了
從上面的結(jié)果,我們發(fā)現(xiàn)ID=1的頁面���,PR值是0�,那么ID=1的頁��,就不能向其他頁面輸出權(quán)重了�,計算就會不合理!所以���,增加d阻尼系數(shù)���,修正沒有鏈接指向的頁面��,保證頁面的最小PR值>0�,�。數(shù)據(jù)分析師培訓
2). 包括考慮阻尼系統(tǒng)的情況
增加函數(shù):dProbabilityMatrix
#變換概率矩陣,考慮d的情況
dProbabilityMatrix<-function(G,d=0.85){
cs <- colSums(G)
cs[cs==0] <- 1
n <- nrow(G)
delta <- (1-d)/n
A <- matrix(delta,nrow(G),ncol(G))
for (i in 1:n) A[i,] <- A[i,] + d*G[i,]/cs
A
}
> pages<-read.table(file="page.csv",header=FALSE,sep=",")
> names(pages)<-c("src","dist");pages
src dist
1 1 2
2 1 3
3 1 4
4 2 3
5 2 4
6 3 4
7 4 2
> A<-adjacencyMatrix(pages);A
[,1] [,2] [,3] [,4]
[1,] 0 0 0 0
[2,] 1 0 0 1
[3,] 1 1 0 0
[4,] 1 1 1 0
> G<-dProbabilityMatrix(A);G
[,1] [,2] [,3] [,4]
[1,] 0.0375000 0.0375 0.0375 0.0375
[2,] 0.3208333 0.0375 0.0375 0.8875
[3,] 0.3208333 0.4625 0.0375 0.0375
[4,] 0.3208333 0.4625 0.8875 0.0375
> q<-eigenMatrix(G,100);q
[,1]
[1,] 0.0375000
[2,] 0.3738930
[3,] 0.2063759
[4,] 0.3822311
增加阻尼系數(shù)后,ID=1的頁面�����,就有值了PR(1)=(1-d)/n=(1-0.85)/4=0.0375�����,即無外鏈頁面的最小值�����。
3). 直接用R的特征值計算函數(shù)
增加函數(shù):calcEigenMatrix
#直接計算矩陣特征值
calcEigenMatrix<-function(G){
x <- Re(eigen(G)$vectors[,1])
x/sum(x)
}
> pages<-read.table(file="page.csv",header=FALSE,sep=",")
> names(pages)<-c("src","dist");pages
src dist
1 1 2
2 1 3
3 1 4
4 2 3
5 2 4
6 3 4
7 4 2
> A<-adjacencyMatrix(pages);A
[,1] [,2] [,3] [,4]
[1,] 0 0 0 0
[2,] 1 0 0 1
[3,] 1 1 0 0
[4,] 1 1 1 0
> G<-dProbabilityMatrix(A);G
[,1] [,2] [,3] [,4]
[1,] 0.0375000 0.0375 0.0375 0.0375
[2,] 0.3208333 0.0375 0.0375 0.8875
[3,] 0.3208333 0.4625 0.0375 0.0375
[4,] 0.3208333 0.4625 0.8875 0.0375
> q<-calcEigenMatrix(G);q
[1] 0.0375000 0.3732476 0.2067552 0.3824972
直接計算矩陣特征值���,可以有效地減少的循環(huán)的操作,提高程序運行效率����。
在了解PageRank的原理后����,使用R語言構(gòu)建PageRank模型�����,是非常容易的�。實際應(yīng)用中,我們也愿意用比較簡單的方式建模����,驗證后,再用其他語言語言去企業(yè)應(yīng)用�����!
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330