R語言相關(guān)分布函數(shù)�����、統(tǒng)計函數(shù)的使用
R語言相關(guān)分布函數(shù)、統(tǒng)計函數(shù)的使用
分布函數(shù)家族: *func()
r : 隨機(jī)分布函數(shù)
d : 概率密度函數(shù)
p : 累積分布函數(shù)
q : 分位數(shù)函數(shù)
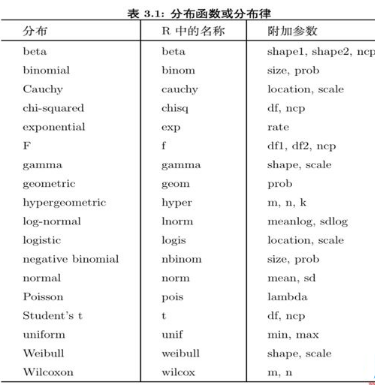
func()表示具體的名稱如下表:
例子
#r : 隨機(jī)分布函數(shù)
#d : 概率密度函數(shù)
#p : 累積分布函數(shù)
#q : 分位數(shù)函數(shù)
#生成符合二項分布的數(shù)據(jù)
# 二項分布
# X~(N,P)
str(rbinom)
x<-rbinom(5,1,0.5) #做1次試驗����,假設(shè)正面概率為0.5,進(jìn)行5次觀察����,每1次試驗中正面出現(xiàn)的次數(shù)為別為 0 0 1 1 0
x<-rbinom(5,10,0.5) #做10次試驗,假設(shè)正面概率為0.5�����,進(jìn)行5次觀察���,每10次試驗中正面出現(xiàn)的次數(shù)分別為 4 4 7 6 6
x
plot(x)
#概率密度函數(shù)
y<-dbinom(40,100,0.5) #做100次試驗���,假設(shè)正面概率為0.5,正面出現(xiàn)的次數(shù)為50次的概率是 0.01084387
y<-dbinom(40:50,100,0.5) ##做100次試驗����,假設(shè)正面概率為0.5,正面出現(xiàn)的次數(shù)分別為40到50的概率分別為: 0.01084387...
sum(y) #累計概率
y<-dbinom(0:100,100,0.5)
plot(y) #概率密度曲線
plot(0:100,y,pch=16) #概率密度曲線
#累計概率
z<-pbinom(50,100,0.5) #累計概率 小于等于50的概率為0.5397946
z<-dbinom(0:50,100,0.5)
sum(z)
plot(pbinom(0:100,100,0.5))
#分為點
q = qbinom(0.5,100,0.5) #在0.5分為點的數(shù)值為
q
單變量統(tǒng)計函數(shù)
均值:mean
中位數(shù):median
分位數(shù):quantile
方差:var
標(biāo)準(zhǔn)差:sd
頻數(shù)表:table
偏度: Sk=sum((x[!is.na(x)]-Av)^3/Sd^3)/N #偏度
<0 左偏 >0 右偏
峰度: Ku=sum((x[!is.na(x)]-Av)^4/Sd^4)/N-3 #峰度
<3 坡度緩 >3 坡度陡
#單變量的描述統(tǒng)計
str(airquality) #R自帶的空氣質(zhì)量數(shù)據(jù)集 str 結(jié)構(gòu)structure的縮寫
summary(airquality) #匯總數(shù)據(jù)包括 最小值�����、分位數(shù)、平均數(shù)��、中位數(shù)��、最大值���、缺失值(NA's)
#平均值
mean(airquality$Ozone, na.rm = T) #na.rm=T 對缺失值進(jìn)行刪除�����,存在缺失值�,結(jié)果為NA
mean(airquality$Temp, na.rm = T, trim = .01) #trim=.01 按百分比去掉頭尾的數(shù)�,刪除極值
#中位數(shù)
median(airquality$Ozone, na.rm = T)
#加權(quán)平均數(shù)
temp100 <- rnorm(100,30,1) #通過正態(tài)分布生成100個隨機(jī)數(shù),平均值為30
w <- 1:100 #生成每個值的權(quán)重值
wmt = weighted.mean(temp100,w,na.rm = T) #進(jìn)行加權(quán)平均計算
mt = mean(temp100,na.rm = T)
#幾何平均數(shù)
x<- c(.045, .021, .255, .019)
xm = mean(x)
xg = exp(mean(log(x)))#exp指數(shù) log對數(shù)
#中位數(shù)
median(temp100,na.rm = T)
#分位數(shù)
quantile(airquality$Temp, na.rm = T)
# 0% 25% 50% 75% 100% 50%中位數(shù) 0%最小值 25%上四分位數(shù)
# 56 72 79 85 97
quantile(airquality$Temp, na.rm = T, probs = c(0,0.1,0.9,1)) #通過probs自定義分位點
#方差
var(temp100)
#標(biāo)準(zhǔn)差
ts <- sd(temp100)
ts^2 #標(biāo)準(zhǔn)差的平方等于方差
#峰度和偏度
mysummary = function(x,...){
Av=mean(x,na.rm = T)
Sd=sd(x,na.rm = T)
N=length(x[!is.na(x)])
Sk=sum((x[!is.na(x)]-Av)^3/Sd^3)/N #偏度
Ku=sum((x[!is.na(x)]-Av)^4/Sd^4)/N-3 #峰度
result=c(argv=Av, sd=Sd, skew=Sk, kurt=Ku)
return (result)
}
mysummary(temp100)
# argv sd skew kurt
#30.109613023 1.033804058 -0.008489863 -0.597720454
#通過apply進(jìn)行提交
apply(airquality[,c(-5,-6)],2,FUN=mysummary)
#Ozone Solar.R Wind Temp
#argv 42.129310 185.9315068 9.95751634 77.8823529
#sd 32.987885 90.0584222 3.52300135 9.4652697
#skew 1.209866 -0.4192893 0.34102753 -0.3705073
#kurt 1.112243 -1.0040581 0.02886468 -0.4628929
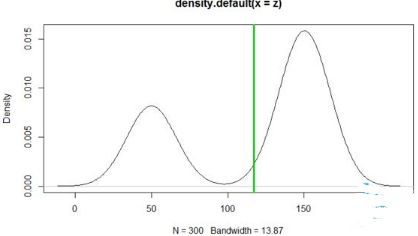
非單封分布:
#非單峰分布不能簡單計算均值
x=rnorm(100,50,9)
y=rnorm(200,150,9)
z=c(x,y)
plot(density(z)) #使用密度曲線畫圖
abline(v=mean(z),col=3,lw=3)
雙變量函數(shù)
協(xié)方差:cov
相關(guān)系數(shù):cor 通過相關(guān)系數(shù)計算相關(guān)性
缺失值處理:行刪除�����、配對刪除等
#協(xié)方差
cov(airquality[,-5:-6],use = 'complete.obs') #行刪除,處理缺失值
cov(airquality[,-5:-6],use = 'pairwise.complete.obs') #配對刪除,處理缺失值
#相關(guān)系數(shù)
cor(airquality[,-5:-6],use = 'complete.obs') #行刪除
cor(airquality[,-5:-6],use = 'pairwise.complete.obs') #配對刪除
#結(jié)果為對稱矩陣
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330