R語(yǔ)言中的離群值檢測(cè)和處理
數(shù)據(jù)中的離群值往往會(huì)扭曲預(yù)測(cè)結(jié)果并影響模型精度����,回歸模型中離群值的影響尤其大���,因此我們需要對(duì)其進(jìn)行檢測(cè)和處理����。
離群值檢測(cè)的重要性
處理離群值或者極端值并不是數(shù)據(jù)建模的必要流程�,然而,了解它們對(duì)預(yù)測(cè)模型的影響也是大有裨益的��。數(shù)據(jù)分析師們需要自己判斷處理離群值的必要性���,并結(jié)合實(shí)際問(wèn)題選取處理方法���。那么�����,檢測(cè)離群值的重要性體現(xiàn)在哪兒呢�?其實(shí)�,由于離群值的存在,模型的估計(jì)和預(yù)測(cè)可能會(huì)有很大的偏差或者變化���。我們用汽車(chē)數(shù)據(jù)來(lái)說(shuō)明這個(gè)現(xiàn)象���。
我將用包含和不含離群值的汽車(chē)數(shù)據(jù)來(lái)建立一個(gè)簡(jiǎn)單的線性回歸模型,以此闡述離群值的影響���。為了更好的區(qū)分它的效應(yīng)��,我在原始數(shù)據(jù)集中人為地加入了極端值��,然后利用線性歸回做預(yù)測(cè)�����。
# 給數(shù)據(jù)集插入離群值
cars1 <- cars[1:30, ] # 原始數(shù)據(jù)
cars_outliers <- data.frame(speed = c(19, 19, 20, 20, 20),
dist = c(190, 186, 210, 220, 218)) # 引入離群值
cars2 <- rbind(cars1, cars_outliers) # 包含李全職的數(shù)據(jù)
# 繪制包含離群值的數(shù)據(jù)建模結(jié)果
par(mfrow = c(1, 2))
plot(cars2$speed, cars2$dist, xlim = c(0, 28), ylim=c(0, 230),
main = "With Outliers", xlab = "speed", ylab = "dist",
pch = "*", col = "red", cex = 2)
abline(lm(dist ~ speed, data = cars2), col = "blue", lwd = 3, lty = 2)
# 繪制原始數(shù)據(jù)建模加過(guò),留意回歸線斜率的變化
plot(cars1$speed, cars1$dist, xlim = c(0, 28), ylim = c(0, 230),
main = "Outliers removed \n A much better fit!",
xlab = "speed", ylab = "dist", pch = "*", col = "red", cex = 2)
abline(lm(dist ~ speed, data = cars1), col = "blue", lwd = 3, lty = 2)
結(jié)果如下
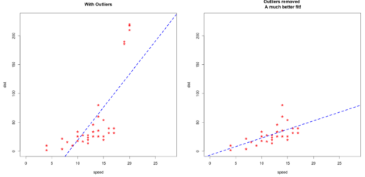
留意一下移除離群值后擬合線的斜率變化����。如左圖所示����,如果用包含離群值的數(shù)據(jù)訓(xùn)練模型���,我們預(yù)測(cè)結(jié)果在速度很快的數(shù)據(jù)上會(huì)有很大的誤差��,因?yàn)榛貧w線非常陡峭��。
檢測(cè)離群值
1. 單變量檢測(cè)法
給定一個(gè)連續(xù)變量后�����,離群值可以認(rèn)為是哪些超出1.5倍四分位距的觀測(cè)點(diǎn)�。四分位距(Inter Quartile Range, a.k.a IQR)是0.25分位數(shù)和0.75分位數(shù)的差�,我們可以通過(guò)箱線圖來(lái)檢測(cè)離群點(diǎn),在須軸以外的點(diǎn)就是�����。
url <- "http://rstatistics.net/wp-content/uploads/2015/09/ozone.csv"
# 備用數(shù)據(jù)源: https://raw.githubusercontent.com/selva86/datasets/master/ozone.csv
inputData <- read.csv(url) # 導(dǎo)入數(shù)據(jù)
outlier_values <- boxplot.stats(inputData$pressure_height)$out # outlier values.
boxplot(inputData$pressure_height, main="Pressure Height", boxwex=0.1)
mtext(paste("Outliers: ", paste(outlier_values, collapse=", ")), cex=0.6)
2. 雙變量檢測(cè)法
如果有兩個(gè)變量X和Y����,X是分類(lèi)變量而Y是連續(xù)變量����,可以繪制在X的不同類(lèi)別上Y的箱線圖來(lái)檢測(cè)離群值����。
url <- "http://rstatistics.net/wp-content/uploads/2015/09/ozone.csv"
ozone <- read.csv(url)
# Month和Day_of_Week是分類(lèi)變量
boxplot(ozone_reading ~ Month, data=ozone, main="Ozone reading across months") # 有明確的模式
boxplot(ozone_reading ~ Day_of_week, data=ozone, main="Ozone reading for days of week") # this may not be significant, as day of week variable is a subset of the month var.
箱線圖如下:
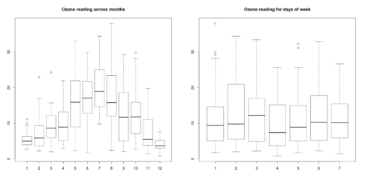
上圖我們發(fā)現(xiàn)每個(gè)月的ozone_reading數(shù)據(jù)有明顯變化,但在周內(nèi)每天的區(qū)別并不明顯����。每一個(gè)類(lèi)別中,在箱線圖須軸以外的店就是離群值��。
如果X和Y都是連續(xù)變量�����,我們可以將X離散化
boxplot(ozone_reading ~ pressure_height, data=ozone,
main="Boxplot for Pressure height (continuos var) vs Ozone")
boxplot(ozone_reading ~ cut(pressure_height, pretty(inputData$pressure_height)),
data=ozone, main="Boxplot for Pressure height (categorial) vs Ozone", cex.axis=0.5)
結(jié)果如下
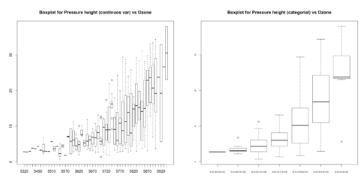
離散化處理后�����,你會(huì)發(fā)現(xiàn)被判定為離群值的點(diǎn)更少���,并且ozone_reading隨著pressure_height的增加而變化的趨勢(shì)愈發(fā)明確了���。
3. 多元模型檢測(cè)法
僅憑一個(gè)特征就判定一個(gè)觀測(cè)值是離群點(diǎn)可能并不科學(xué)。利用多個(gè)特征的信息來(lái)判斷個(gè)體是否是離群值會(huì)更好��,這就需要使用Cook距離���。
Cook距離可以衡量一個(gè)給定的回歸模型是否只受單個(gè)變量X的影響�����。Cook距離會(huì)極端每一個(gè)數(shù)據(jù)點(diǎn)對(duì)預(yù)測(cè)結(jié)果的影響�����。對(duì)于每個(gè)觀測(cè)i��,Cook距離會(huì)衡量包含i與不包含i時(shí)����,Y的擬合值的變化��,這樣我們就知道了i對(duì)擬合結(jié)果的影響了�。
觀測(cè)i的Cook距離 計(jì)算公式如下:
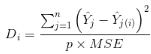
其中:
是使用所有觀測(cè)計(jì)算的第j個(gè)y的擬合值
是使用除觀測(cè)i外所有觀測(cè)計(jì)算的第j個(gè)y的擬合值
是均方誤差
是回歸模型的系數(shù)個(gè)數(shù)
mod <- lm(ozone_reading ~ ., data=ozone)
cooksd <- cooks.distance(mod)
影響評(píng)估
一般來(lái)說(shuō),如果某個(gè)觀測(cè)的Cook距離比平均距離大4倍�,我們就可以認(rèn)為這個(gè)點(diǎn)是離群點(diǎn),當(dāng)然這不是一個(gè)非常死板的判定條件。
plot(cooksd, pch="*", cex=2, main="Influential Obs by Cooks distance") # 繪制Cook距離
abline(h = 4*mean(cooksd, na.rm=T), col="red") # 添加決策線
text(x=1:length(cooksd)+1, y=cooksd, labels=ifelse(cooksd>4*mean(cooksd, na.rm=T),names(cooksd),""), col="red") # 添加標(biāo)簽
結(jié)果如下:
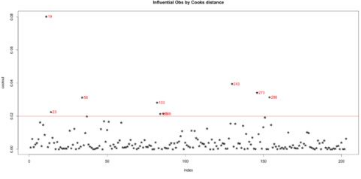
現(xiàn)在讓我們從原始數(shù)據(jù)集中找出那些影響力特別大的觀測(cè)點(diǎn)吧���。如果你把它們逐一挑出來(lái)了�����,你就能發(fā)現(xiàn)為何它們會(huì)有這么大的影響力了——這些觀測(cè)的在某些變量上的取值過(guò)于極端了����。
influential 4*mean(cooksd, na.rm=T))]) # 有影響力的觀測(cè)值行標(biāo)
head(ozone[influential, ]) # 列出這些觀測(cè)
#> Month Day_of_month Day_of_week ozone_reading pressure_height Wind_speed Humidity
#> 19 1 19 1 4.07 5680 5 73
#> 23 1 23 5 4.90 5700 5 59
#> 58 2 27 5 22.89 5740 3 47
#> 133 5 12 3 33.04 5880 3 80
#> 135 5 14 5 31.15 5850 4 76
#> 149 5 28 5 4.82 5750 3 76
#> Temperature_Sandburg Temperature_ElMonte Inversion_base_height Pressure_gradient
#> 19 52 56.48 393 -68
#> 23 69 51.08 3044 18
#> 58 53 58.82 885 -4
#> 133 80 73.04 436 0
#> 135 78 71.24 1181 50
#> 149 65 51.08 3644 86
#> Inversion_temperature Visibility
#> 19 69.80 10
#> 23 52.88 150
#> 58 67.10 80
#> 133 86.36 40
#> 135 79.88 17
#> 149 59.36 70
讓我們看看前6個(gè)觀測(cè)來(lái)看看為什么這些觀測(cè)富有影響力吧�。
第58, 133�, 135行的ozone_reading值非常大
第23, 135���, 149行的Inversion_bzase_height值非常大
第19行有非常低的Pressure_gradient
離群值檢驗(yàn)
car包中的outlierTest函數(shù)可以返回指定模型中影響力最大的觀測(cè)值���。
car::outlierTest(mod)
#> No Studentized residuals with Bonferonni p Largest |rstudent|:
#> rstudent unadjusted p-value Bonferonni p
#> 243 3.045756 0.0026525 0.53845
0utliners包
outliers包提供了幾個(gè)有用的函數(shù)來(lái)系統(tǒng)地檢測(cè)出離群值。其中一些函數(shù)既便利又好上手���,特別是outliers()函數(shù)和scores()函數(shù)�。
outliers()會(huì)返回和平均值相比較后最極端的觀測(cè)��,如果你給定參數(shù)opposite=TRUE,它會(huì)返回位于另一端的觀測(cè)�����。
set.seed(1234)
y=rnorm(100)
outlier(y)
#> [1] 2.548991
outlier(y,opposite=TRUE)
#> [1] -2.345698
dim(y) <- c(20,5) # convert it to a matrix
outlier(y)
#> [1] 2.415835 1.102298 1.647817 2.548991 2.121117
outlier(y,opposite=TRUE)
#> [1] -2.345698 -2.180040 -1.806031 -1.390701 -1.372302
scores()函數(shù)有兩大功能�。一是計(jì)算規(guī)范化得分�,諸如z得分,t得分����,chisq得分等。它還可以基于上述的得分值�����,返回那些得分在相應(yīng)分布百分位數(shù)之外的觀測(cè)值���。
set.seed(1234)
x = rnorm(10)
scores(x) # z得分 => (x-mean)/sd
scores(x, type="chisq") # chisq得分 => (x - mean(x))^2/var(x)
#> [1] 0.68458034 0.44007451 2.17210689 3.88421971 0.66539631 . . .
scores(x, type="t") # t得分
scores(x, type="chisq", prob=0.9) # 是否超過(guò)chisq分布的0.9分位數(shù)
#> [1] FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
scores(x, type="chisq", prob=0.95) # 0.95分位數(shù)
scores(x, type="z", prob=0.95) # 基于z得分判定
scores(x, type="t", prob=0.95) # 大家都懂����,我懶得翻譯了
離群值處理
在尋找到離群值之后���,你需要根據(jù)處理的實(shí)際問(wèn)題來(lái)對(duì)它們進(jìn)行處理�,常用方法如下:
1. 插值
使用均值/中位數(shù)/眾數(shù)插值,這個(gè)方法在 缺失值的處理 鄰領(lǐng)域已被廣泛應(yīng)用����。另一種穩(wěn)健的做法是使用 鏈?zhǔn)椒匠?nbsp;進(jìn)行多元插值。
2. 封頂
對(duì)于那些取值超過(guò)1.5倍四分位距的數(shù)值�����,可以分別用該變量5%和95%的分位數(shù)替代原數(shù)據(jù)�����,下方代碼可以實(shí)現(xiàn)該過(guò)程:
x <- ozone$pressure_height
qnt <- quantile(x, probs=c(.25, .75), na.rm = T)
caps <- quantile(x, probs=c(.05, .95), na.rm = T)
H <- 1.5 * IQR(x, na.rm = T)
x[x < (qnt[1] - H)] (qnt[2] + H)] <- caps[2]
注:該方法和數(shù)據(jù)預(yù)處理中的縮尾(winsorize)處理基本一致��,和數(shù)理統(tǒng)計(jì)中的m統(tǒng)計(jì)量思想也類(lèi)似�����。
3. 預(yù)測(cè)
這是另一種思路�����,將離群值先替換做缺失值��,再將其視作被解釋變量進(jìn)行預(yù)測(cè)����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫(kù)�,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330