R語言學(xué)習(xí)筆記與感悟一
學(xué)習(xí)內(nèi)容:1.理解數(shù)據(jù)分析系統(tǒng)2.R與RStudio的關(guān)系、RStudio的基本使用3.注意事項(xiàng)��、幫助函數(shù)���、管理工作空間的函數(shù)�、文本與圖形的輸入與輸出4.數(shù)據(jù)結(jié)構(gòu)����、數(shù)據(jù)的輸入5.添加變量標(biāo)簽和值標(biāo)簽、處理數(shù)據(jù)對(duì)象的函數(shù)
主要學(xué)習(xí)材料:1.《R語言實(shí)戰(zhàn)》Chapter 1&22.猴子知乎Live第二講:

數(shù)據(jù)結(jié)構(gòu)入門
蓋房子 = 材料 + 整合材料程序 = 數(shù)據(jù)結(jié)構(gòu) + 算法
R與RStudio的區(qū)別:
R是運(yùn)行環(huán)境�;RStudio是開發(fā)工具,為了更方便地使用R語言�����,用于代碼的編輯��、調(diào)試���、圖形顯示。
在RStudio中導(dǎo)入數(shù)據(jù)后��,工作空間中會(huì)顯示內(nèi)存中保存的對(duì)象。
R Studio中的注釋部分與代碼部分有顏色的區(qū)分����,內(nèi)置函數(shù)與外來輸入的部分能通過顏色區(qū)分���。
RStudio的使用:
1. RStudio的組成:
控制臺(tái)Console:輸入命令及顯示輸出結(jié)果
代碼編輯器
工作空間
目錄���,同時(shí)也是圖形輸出設(shè)備所在處
2. 創(chuàng)建項(xiàng)目和腳本
File -> New Project -> New Directory -> Empty Project
File -> New File -> R Script在腳本中寫入R的代碼,腳本文件的后綴為.R
3. 運(yùn)行代碼
Step1: 在腳本中選中要運(yùn)行的代碼Step2: Code — Run Lines運(yùn)行結(jié)果會(huì)顯示在控制臺(tái)中
4. 更改RStudio背景色
Tools -> Global Options -> Appearance然后在Editor Theme中選擇背景
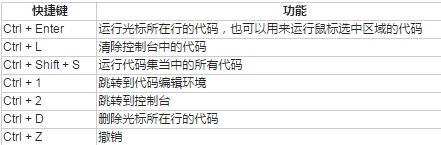
5. R Studio中的快捷鍵
第一章 R語言介紹
一����、注意事項(xiàng):
區(qū)分大小寫 邏輯值TRUE和FALSE全部大寫
在命令提示符(>)后每次輸入并執(zhí)行一條命令,或者一次性執(zhí)行寫在腳本文件中的一組命R使用<-�,而不是傳統(tǒng)的 = 作為賦值符
注釋由符號(hào) # 開頭,在 # 之后出現(xiàn)的任何文本都會(huì)被R解釋器忽略
路徑中使用一個(gè)正斜杠/或兩個(gè)反斜杠\\,使用引號(hào)閉合目錄名和文件名
輸入字符串時(shí)要加引號(hào)�,單引號(hào)和雙引號(hào)皆可
二、常用函數(shù):
(截圖來自《R語言實(shí)戰(zhàn)》)
注意:
導(dǎo)入數(shù)據(jù)前�����,必須先設(shè)置當(dāng)前工作目錄要導(dǎo)入存在另一個(gè)工作目錄下的數(shù)據(jù)��,必須先改變工作目錄再讀入數(shù)據(jù)
函數(shù)setwd()不會(huì)自動(dòng)創(chuàng)建一個(gè)不存在的目錄��。可以使用函數(shù)dir.create()來創(chuàng)建新目錄��,然后使用setwd()將工作目錄指向這個(gè)新目錄�。
啟動(dòng)一個(gè)R會(huì)話時(shí)使用setwd()命令指定到某一個(gè)項(xiàng)目的路徑,后接不加選項(xiàng)的load()命令���,這樣做可以從上一次會(huì)話結(jié)束的地方重新開始����。
實(shí)踐示例:setwd("C:/myprojects/project1") #當(dāng)前工作目錄被設(shè)置為C:/myprojects/project1
options() #當(dāng)前的選項(xiàng)設(shè)置情況將顯示出來
options(digits=3) #顯示為小數(shù)點(diǎn)后三位有效數(shù)字
x <- runif(20) #創(chuàng)建一個(gè)包含20個(gè)均勻分布隨機(jī)變量的向量
summary(x) #生成摘要統(tǒng)計(jì)量
hist(x) #生成直方圖
savehistory() #命令的歷史記錄保存到文件.Rhistory中
save.image() #工作空間(包含向量x)保存到文件.RData中
q() #會(huì)話結(jié)束
三���、輸入與輸出
輸入:
函數(shù)source("filename")可在當(dāng)前會(huì)話中執(zhí)行一個(gè)腳本�����。如果文件名中不包含路徑�����,R將假設(shè)此腳本在當(dāng)前工作目錄中�����。
文本輸出:
函數(shù)sink("filename")將輸出重定向到文件filename中���。使用參數(shù)append=TRUE可以將文本追加到文件后�,而不是覆蓋它�����。參數(shù)split=TRUE可將輸出同時(shí)發(fā)送到屏幕和輸出文件中�。不加參數(shù)調(diào)用命令sink()將僅向屏幕返回輸出結(jié)果����。
圖形輸出:
要重定向圖形輸出,使用表1-4中列出的函數(shù)即可����。最后使用dev.off()將輸出返回到終端。

實(shí)踐示例1:
sink("myoutput", append=TRUE, split=TRUE)
pdf("mygraphs.pdf")
source("script2.R")
文件script2.R中的R代碼將執(zhí)行�,結(jié)果也將顯示在屏幕上。此外����,文本輸出將被追加到文件myoutput中,圖形輸出將保存到文件mygraphs.pdf中���。
實(shí)踐示例2:
sink()
dev.off()
source("script3.R")
文件script3.R中的R代碼將執(zhí)行�����,結(jié)果將顯示在屏幕上�,沒有文本和圖形輸出保存到文件中。
待解決疑問1:
在上述兩個(gè)示例中���,為什么不是先使用輸入函數(shù)source(),而是先使用輸出函數(shù)�����?
四�����、R包
install.packages("package_name")安裝包
library("package_name")載入包���,包安裝后必須先載入才能使用
update.packages("package_name")更新已經(jīng)安裝的包
search()可以告訴你哪些包已加載并可使用
installed.packages()查看已安裝的包的描述,將列出安裝的包
library()顯示庫(kù)(存儲(chǔ)包的目錄)中有哪些包
.libPaths()顯示庫(kù)所在的位置
help(package="package_name")可以輸出某個(gè)包的簡(jiǎn)短描述以及包中的函數(shù)名稱和數(shù)據(jù)集名稱的列表
實(shí)踐示例:
install.packages("vcd") #安裝vcd包
help(package="vcd") #列出此包中可用的函數(shù)和數(shù)據(jù)集
library(vcd) #載入這個(gè)包
help(Arthritis) #查看數(shù)據(jù)集Arthritis的描述
Arthritis #顯示數(shù)據(jù)集Arthritis的內(nèi)容
example(Arthritis) #運(yùn)行數(shù)據(jù)集Arthritis的自帶的示例
q() #退出
第二章 創(chuàng)建數(shù)據(jù)集(數(shù)據(jù)分析的第一步)
包括兩個(gè)步驟:1.選擇一種數(shù)據(jù)結(jié)構(gòu)來存儲(chǔ)數(shù)據(jù)���;2.將數(shù)據(jù)輸入或?qū)氲竭@個(gè)數(shù)據(jù)結(jié)構(gòu)中��。
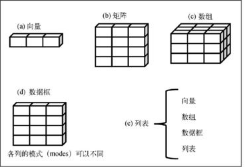
一��、數(shù)據(jù)結(jié)構(gòu)
向量�、矩陣、數(shù)組中的數(shù)據(jù)必須是同種類型�����;數(shù)據(jù)框和列表中的數(shù)據(jù)可以是不同類型
1. 向量
向量是用于存儲(chǔ)數(shù)值型���、字符型或邏輯型數(shù)據(jù)的一維數(shù)組���。用函數(shù)c()來創(chuàng)建向量。
a <- c(1,2,5,3,6,-2,4)
b <- c("one", "two", "three")
c <- c(TRUE, TRUE, TRUE, FALSE, TRUE, FALSE)
使用:
單個(gè)向量中的數(shù)據(jù)必須擁有相同的數(shù)據(jù)類型(數(shù)值型����、字符型或邏輯型)����。
獲取向量的長(zhǎng)度 length(vector_name)
要訪問向量中的某個(gè)元素,在方括號(hào)中給定元素所處位置的數(shù)值���,例如:a[c(2, 4)]用于訪問向量a中的第二個(gè)和第四個(gè)元素�。
由于R中內(nèi)置了同名函數(shù)c()�,最好不要在編碼時(shí)使用c作為對(duì)象名。
R中沒有標(biāo)量����。標(biāo)量是只含一個(gè)元素的向量����,例如f <- 3���、g <- "US"和h <- TRUE ,它們用于保存常量��。
冒號(hào)用于生成一個(gè)數(shù)值序列�����。例如�����,a <- c(2:6)等價(jià)于a <- c(2,3, 4, 5, 6)�。
2. 矩陣
矩陣是一個(gè)二維數(shù)組����,每個(gè)元素都擁有相同的類型(數(shù)值型�����、字符型或邏輯型)。
可通過函數(shù)matrix創(chuàng)建矩陣。
mymatrix <- matrix(vector,
nrow=number_of_rows, ncol=number_of_columns,
byrow=logical_value,
dimnames=list(char_vector_rownames, char_vector_colnames))
vector包含了矩陣的元素����,是一個(gè)向量
nrow和ncol用以指定行和列的維數(shù)
byrow則表明矩陣應(yīng)當(dāng)按行填充(byrow=TRUE)還是按列填充(byrow=FALSE)�,默認(rèn)情況下按列填充
dimnames包含了可選的、以字符型向量表示的行名和列名實(shí)踐示例:cells <- c(1,26,24,68)
rnames <- c("R1", "R2")
cnames <- c("C1", "C2")
mymatrix <- matrix(cells, nrow=2, ncol=2, byrow=TRUE, dimnames=list(rnames, cnames)使用:
訪問矩陣中的行、列或元素X[i,]指矩陣X中的第i 行�,X[,j]指第j 列��,X[i, j]指第i 行第j 個(gè)元素�,如:x[2,] #選取矩陣x中第二行的元素x[,2] #選取矩陣x中第二列的元素x[1,4] #選取矩陣x中位于第一行第四列的元素選擇多行或多列時(shí),下標(biāo)i 和j 可為數(shù)值型向量��,如:x[1, c(4,5)] #選取矩陣x第一行中位于第四列和第五列的元素
矩陣的作用: 繪制圖形
3. 數(shù)組
數(shù)組(array)維度可以大于2����,數(shù)據(jù)只能擁有一種類型�����。行表示觀測(cè),列表示變量。
數(shù)組可通過array函數(shù)創(chuàng)建。myarray <- array(vector, dimensions, dimnames)
vector包含了數(shù)組中的數(shù)據(jù) ���,是一個(gè)向量
dimensions是數(shù)值型向量����,給出了各個(gè)維度下標(biāo)的最大值
dimnames是各維度名稱的列表實(shí)踐示例:data <- 1:24
dim1 <- c("A1", "A2")
dim2 <- c("B1", "B2", "B3")
dim3 <- c("C1", "C2", "C3", "C4")
z <- array(data, c(2, 3, 4), dimnames=list(dim1, dim2, dim3))
4.數(shù)據(jù)框
數(shù)據(jù)框是數(shù)據(jù)分析中最常用的數(shù)據(jù)結(jié)構(gòu)不同的列可以包含不同類型(數(shù)值型�、字符型等)的數(shù)據(jù),但是每一列的數(shù)據(jù)類型必須唯一����。
數(shù)據(jù)框可通過函數(shù)data.frame()創(chuàng)建����。mydata <- data.frame(col1, col2, col3, ...)
使用:
選取數(shù)據(jù)框中元素1.使用下標(biāo)記號(hào)patientdata[1:2] #選取名為patientdata數(shù)據(jù)框中的第一列至第二列元素2.直接指定列名patientdata[c("diabetes", "status")] #選取patientdata數(shù)據(jù)框中列名分別為diabetes和status所在列的元素3.用$和列名選取一個(gè)給定數(shù)據(jù)框中的某一列patientdata$age #選取patientdata數(shù)據(jù)框中列名為age所在列的元素
求數(shù)據(jù)框的行數(shù)例如:求患者總數(shù)patientNumber <- nrow(patientdata)
求滿足某一特征的數(shù)據(jù)個(gè)數(shù)例如:求患有“1型糖尿病”的患者人數(shù)Step1: 使用==找到符合條件的數(shù)據(jù)�����,并賦值給新的數(shù)據(jù)框type1 <- patientdata[patientdata$diabetes == "1型糖尿病"]type1也是一個(gè)數(shù)據(jù)框,僅包含符合糖尿病類型為“1型糖尿病”的患者Step2: 求type1數(shù)據(jù)框的行數(shù)type1.number <- nrow(type1)對(duì)象名稱中的句點(diǎn)(.)沒有特殊意義。
在數(shù)據(jù)框中按行添加新數(shù)據(jù)用rbind函數(shù)Step1:將要添加的數(shù)據(jù)放入新的數(shù)據(jù)框中
patientID <- c(5)
age <- c(30)
diabetes <- c("1型糖尿病")
status <- c("較差")
newPatient <- data.frame(patientID, age, diabetes, status, stringsAsFactors=FALSE)
Step2:將新數(shù)據(jù)框用rbind函數(shù)加入原數(shù)據(jù)框patientdata <- rbind(patientdata, newPatient)
在數(shù)據(jù)框中按列添加新數(shù)據(jù)用cbind函數(shù)Step1:由于列在數(shù)據(jù)框中相當(dāng)于向量�����,所以將新數(shù)據(jù)首先放入新的向量中inTime <- c("2015-3-1", "2014-12-31", "2015-10-1", "2015-5-1", "2016-12-31")Step2:將新定義的向量用cbind函數(shù)加入原數(shù)據(jù)框patientdata <- cbind(patientdata, inTime)
5.列表
列表允許將若干(可能無關(guān)的)對(duì)象整合到單個(gè)對(duì)象名下���。例如�����,某個(gè)列表中可能是若干向量��、矩陣�、數(shù)據(jù)框,甚至其他列表的組合�����。
使用函數(shù)list()創(chuàng)建列表mylist <- list(object1, object2, ...)還可以為列表中的對(duì)象命名mylist <- list(name1=object1, name2=object2, ...)其中的對(duì)象可以是目前為止講到的任何結(jié)構(gòu)�����。
使用:
常用于存儲(chǔ)各種類型函數(shù)的返回結(jié)果
計(jì)算業(yè)務(wù)指標(biāo)KPI例如:存儲(chǔ)業(yè)務(wù)指標(biāo)一“患有‘1型糖尿病’的患者信息”和業(yè)務(wù)指標(biāo)二“病人的數(shù)量”為KPI結(jié)果kpi <- list(diabetesType=type1, number=number) #列表中的業(yè)務(wù)指標(biāo)一diabetesType是一個(gè)數(shù)據(jù)框��,業(yè)務(wù)指標(biāo)二number是一個(gè)數(shù)值�,起名字是為了方便后期查找
訪問列表中的元素在雙重方括號(hào)中指明代表某個(gè)成分的數(shù)字或名稱例如:獲取列表中的業(yè)務(wù)指標(biāo)二“病人數(shù)量”��,并賦值給向量numbernumber <- kpi[["number"]]或number <- kpi[[2]] #獲取列表kpi中的第二個(gè)成分���,并賦值給numbe
6.因子
變量可歸結(jié)為名義型�����、有序型或連續(xù)型變量�����。
名義型變量是沒有順序之分的類別變量�。糖尿病類型Diabetes(Type1、Type2)是名義型變量�,即使在數(shù)據(jù)中Type1編碼為1而Type2編碼為2,也不意味著二者是有序的���。
有序型變量表示一種順序關(guān)系��,而非數(shù)量關(guān)系�。病情Status(poor, improved, excellent)是順序型變量���,病情為poor(較差)病人的狀態(tài)不如improved(病情好轉(zhuǎn))的病人�,但并不知道相差多少����。
連續(xù)型變量可以呈現(xiàn)為某個(gè)范圍內(nèi)的任意值,并同時(shí)表示了順序和數(shù)量��。年齡Age就是一個(gè)連續(xù)型變量,它能夠表示像14.5或22.8這樣的值以及其間的其他任意值����。15歲的人比14歲的人年長(zhǎng)一歲
因子:類別(名義型)變量和有序類別(有序型)變量在R中稱為因子(factor)。因子在R中非常重要����,因?yàn)樗鼪Q定了數(shù)據(jù)的分析方式以及如何進(jìn)行視覺呈現(xiàn)。
函數(shù)factor()以一個(gè)整數(shù)向量的形式存儲(chǔ)類別值�,整數(shù)的取值范圍是[1... k ](其中k 是名義型變量中唯一值的個(gè)數(shù)),同時(shí)一個(gè)由字符串(原始值)組成的內(nèi)部向量將映射到這些整數(shù)上����。舉例來說,假設(shè)有向量:diabetes <- c("Type1", "Type2", "Type1", "Type1")語句diabetes <- factor(diabetes)將此向量存儲(chǔ)為(1, 2, 1, 1)�,并在內(nèi)部將其關(guān)聯(lián)為1=Type1和2=Type2(具體賦值根據(jù)字母順序而定)�����。針對(duì)向量diabetes進(jìn)行的任何分析都會(huì)將其作為名義型變量對(duì)待��,并自動(dòng)選擇適合這一測(cè)量尺度的統(tǒng)計(jì)方法���。(這里的測(cè)量尺度是指定類尺度�、定序尺度、定距尺度���、定比尺度中的定類尺度�����。)
要表示有序型變量�����,需要為函數(shù)factor()指定參數(shù)ordered=TRUE給定向量:status <- c("Poor", "Improved", "Excellent", "Poor")語句status <- factor(status, ordered=TRUE)會(huì)將向量編碼為(3, 2, 1, 3)�,并在內(nèi)部將這些值關(guān)聯(lián)為1=Excellent���、2=Improved以及3=Poor�����。針對(duì)此向量進(jìn)行的任何分析都會(huì)將其作為有序型變量對(duì)待�����,并自動(dòng)選擇合適的統(tǒng)計(jì)方法����。對(duì)于字符型向量,因子的水平默認(rèn)依字母順序創(chuàng)建�����?���?梢酝ㄟ^指定levels選項(xiàng)來覆蓋默認(rèn)排序。例如:
status <- factor(status, ordered=TRUE�,
levels=c("Poor", "Improved", "Excellent"))
各水平的賦值將為1=Poor、2=Improved�����、3=Excellent����。
關(guān)于$使用的補(bǔ)充:當(dāng)需要多次重復(fù)引用同一個(gè)數(shù)據(jù)框名稱時(shí),為了避免在每個(gè)變量名前都鍵入一次“數(shù)據(jù)框名稱+$”�,可以通過以下替代方法:
使用attach()和detach()函數(shù)attach()可將數(shù)據(jù)框添加到R的搜索路徑中���。函數(shù)detach()將數(shù)據(jù)框從搜索路徑中移除�。R在遇到一個(gè)變量名以后�,將檢查搜索路徑中的數(shù)據(jù)框,以定位到這個(gè)變量。例如:從mtcars數(shù)據(jù)框中獲取每加侖行駛英里數(shù)(mpg)變量的描述性統(tǒng)計(jì)量��,并分別繪制此變量與發(fā)動(dòng)機(jī)排量(disp)和車身重量(wt)的散點(diǎn)圖:
attach(mtcars)
summary(mpg)
plot(mpg, disp)
plot(mpg, wt)
detach(mtcars)
此方法主要適用于名稱相同的對(duì)象只有一個(gè)的情況���。若數(shù)據(jù)框被綁定之前已經(jīng)用與數(shù)據(jù)框中某對(duì)象相同的名稱定義了新的對(duì)象���,則該新對(duì)象取得優(yōu)先權(quán),可能會(huì)由于兩個(gè)對(duì)象的元素個(gè)數(shù)不同而出錯(cuò)����。

使用with()函數(shù)對(duì)于上例:
with(mtcars, {
summary(mpg, disp, wt)
plot(mpg, disp)
plot(mpg, wt)
})
大括號(hào){}之間的語句都針對(duì)數(shù)據(jù)框mtcars執(zhí)行,這樣就無須擔(dān)心名稱沖突了�。如果僅有一條語句(例如summary(mpg)),那么大括號(hào){}可以省略�。函數(shù)with()的局限性: 賦值僅在此函數(shù)的括號(hào)內(nèi)生效。要?jiǎng)?chuàng)建在with()結(jié)構(gòu)以外存在的對(duì)象�,使用特殊賦值符<<-替代標(biāo)準(zhǔn)賦值符(<-)。

實(shí)例標(biāo)識(shí)符在R中�����,實(shí)例標(biāo)識(shí)符(case identifier)可通過數(shù)據(jù)框操作函數(shù)中的rowname選項(xiàng)指定�����。例如,在病例數(shù)據(jù)中����,病人編號(hào)(patientID)用于區(qū)分?jǐn)?shù)據(jù)集中不同的個(gè)體:
patientdata <- data.frame(patientID, age, diabetes, status,
row.names=patientID)
二、數(shù)據(jù)的輸入(最常用的幾種)
1. 使用鍵盤輸入數(shù)據(jù)
對(duì)于小數(shù)據(jù)集很有效函數(shù)edit()會(huì)自動(dòng)調(diào)用一個(gè)允許手動(dòng)輸入數(shù)據(jù)的文本編輯器��。
Step1: 創(chuàng)建一個(gè)空數(shù)據(jù)框(或矩陣)����,其中變量名和變量的模式需與理想中的最終數(shù)據(jù)集一致;
Step2: 針對(duì)這個(gè)數(shù)據(jù)對(duì)象調(diào)用文本編輯器��,輸入數(shù)據(jù)�����,并將結(jié)果保存回此數(shù)據(jù)對(duì)象中�����。
例如:創(chuàng)建一個(gè)名為mydata的數(shù)據(jù)框��,含有三個(gè)變量:age(數(shù)值型)���、gender(字符型)和weight(數(shù)值型)����,然后調(diào)用文本編輯器����,鍵入數(shù)據(jù),最后保存結(jié)果��。
mydata <- data.frame(age=numeric(0), gender=character(0), weight=numeric(0))
mydata <- edit(mydata)
類似于age=numeric(0)的賦值語句將創(chuàng)建一個(gè)指定數(shù)據(jù)類型但不含實(shí)際數(shù)據(jù)的變量��。
編輯的結(jié)果需要賦值回對(duì)象本身!!!!!!語句mydata <- edit(mydata)的一種簡(jiǎn)捷的等價(jià)寫法是fix(mydata)�。
調(diào)用出文本編輯器后,單擊列的標(biāo)題��,可以用編輯器修改變量名和變量類型(數(shù)值型����、字符型)。還可以通過單擊未使用列的標(biāo)題來添加新的變量����。
2. 從帶分隔符的文本文件導(dǎo)入數(shù)據(jù)
使用read.table()函數(shù),可讀入一個(gè)表格格式的文件并將其保存為一個(gè)數(shù)據(jù)框���。mydataframe <- read.table(file, header=logical_value, sep="delimiter", row.names="name"
file是一個(gè)帶分隔符的ASCII文本文件
header是一個(gè)表明首行是否包含了變量名的邏輯值(TRUE或FALSE)
sep用來指定分隔數(shù)據(jù)的分隔符
row.names是一個(gè)可選參數(shù)���,用以指定一個(gè)或多個(gè)表示行標(biāo)識(shí)符的變量
例如:從當(dāng)前工作目錄中讀入了一個(gè)名為studentgrades.csv的逗號(hào)分隔文件��,從文件的第一行取得了各變量名稱�,將變量STUDENTID指定為行標(biāo)識(shí)符����,最后將結(jié)果保存到了名為grades的數(shù)據(jù)框中。grades <- read.table("studentgrades.csv", header=TRUE, sep=",", row.names="STUDENTID")
默認(rèn)情況下��,字符型變量將轉(zhuǎn)換為因子����。禁止這種轉(zhuǎn)換的方法:
法一:設(shè)置stringsAsFactors=FALSE
法二:使用選項(xiàng)colClasses為每一列指定一個(gè)類,例如logical(邏輯型)��、numeric(數(shù)值型)��、character(字符型)�、factor(因子)。
3. 導(dǎo)入Excel數(shù)據(jù)
讀取一個(gè)Excel文件的最好方式�,就是在Excel中將其導(dǎo)出為一個(gè)逗號(hào)分隔文件(csv),并使用前文描述的方式將其導(dǎo)入R中���。
在Windows系統(tǒng)中���,也可以使用RODBC包來訪問Excel文件。

實(shí)踐示例:
install.packages("RODBC")
library(RODBC)
channel <- odbcConnectExcel("myfile.xls")
mydataframe <- sqlFetch(channel, "mysheet")
odbcClose(channel)
myfile.xls是一個(gè)Excel文件mysheet是要從這個(gè)工作簿中讀取工作表的名稱channel是一個(gè)由odbcConnectExcel()返回的RODBC連接對(duì)象mydataframe是返回的數(shù)據(jù)框
XLSX格式的電子表格��,可以用xlsx包來讀取�����。xlsx包不僅僅可以導(dǎo)入數(shù)據(jù)表���,它還能夠創(chuàng)建和操作XLSX文件�。包中的函數(shù)read.xlsx()可將XLSX文件中的工作表導(dǎo)入為一個(gè)數(shù)據(jù)框���。其最簡(jiǎn)單的調(diào)用格式是read.xlsx(file, n)���,其中file是Excel工作簿的所在路徑,n則為要導(dǎo)入的工作表序號(hào)�。
library(xlsx)
workbook <- "C:/myworkbook.xlsx"
mydataframe <- read.xlsx(workbook,1)
從位于C盤根目錄的工作簿myworkbook.xlsx中導(dǎo)入了第一個(gè)工作表,并將其保存為一個(gè)數(shù)據(jù)框mydataframe��。
4.從網(wǎng)頁(yè)抓取數(shù)據(jù)
使用函數(shù)readLines()下載網(wǎng)頁(yè)��,然后使用如grep()和gsub()一類的函數(shù)處理它���。對(duì)于結(jié)構(gòu)復(fù)雜的網(wǎng)頁(yè)��,可以使用RCurl包和XML包來提取其中想要的信息�。
其他還包括導(dǎo)入XML數(shù)據(jù)、導(dǎo)入SPSS數(shù)據(jù)�����、導(dǎo)入SAS數(shù)據(jù)���、導(dǎo)入Stata數(shù)據(jù)����、導(dǎo)入netCDF數(shù)據(jù)����、導(dǎo)入HDF5 數(shù)據(jù)、訪問數(shù)據(jù)庫(kù)管理系統(tǒng)��、通過Stat/Transfer導(dǎo)入數(shù)據(jù)���,等用到時(shí)再詳細(xì)補(bǔ)充��,現(xiàn)在理解起來有些抽象��。
三�����、數(shù)據(jù)集的標(biāo)注
1. 變量標(biāo)簽
為變量名添加描述性的標(biāo)簽方法:將變量標(biāo)簽作為變量名���,然后通過位置下標(biāo)來訪問這個(gè)變量。
例如���,對(duì)于數(shù)據(jù)框patientdata中的第二列包含著個(gè)體首次入院時(shí)年齡的變量age�����,附加一個(gè)描述更詳細(xì)的標(biāo)簽“Age at hospitalization (in years)”(入院年齡)names(patientdata)[2] <- "Age at hospitalization(in years)"將age重命名為"Age at hospitalization (in years)"���。新的變量名太長(zhǎng),不適合重復(fù)輸入����,作為替代,可以使用patientdata[2]來引用這個(gè)變量�����,而在本應(yīng)輸出age的地方輸出字符串"Age at hospitalization (in years)"。
待解決疑問2:為變量名添加描述性標(biāo)簽是否等同于更改變量名����?
2. 值標(biāo)簽
函數(shù)factor()為類別型變量中的編碼添加值標(biāo)簽
例如,假設(shè)有一個(gè)名為gender的變量�,其中1表示男性,2表示女性��,將其關(guān)聯(lián)到標(biāo)簽“male”和“female”上
patientdata$gender <- factor(patientdata$gender,
levels=c(1,2),
labels=c("male", "female"))
注意:這里levels標(biāo)簽中的數(shù)字代表實(shí)際值而不是順序���!
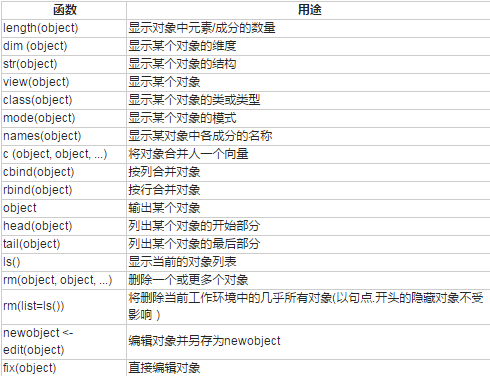
四�����、處理數(shù)據(jù)對(duì)象的實(shí)用函數(shù)
學(xué)習(xí)感悟:
正在努力培養(yǎng)自己將知識(shí)形成體系的能力���,剛剛選定OneNote作為主要工具,各種功能還在進(jìn)一步的探索當(dāng)中��。R語言的這部分內(nèi)容在第一遍學(xué)習(xí)時(shí)����,就邊學(xué)邊進(jìn)行了整理��,算是把書讀薄的過程���,這次是第二遍,在腦中形成了知識(shí)架構(gòu)����,同時(shí)把零散的知識(shí)點(diǎn)插入到架構(gòu)中合適的位置。知識(shí)結(jié)構(gòu)清晰后����,很多原有的疑惑會(huì)迎刃而解���,同時(shí)也會(huì)發(fā)現(xiàn)新的問題����,接下來還會(huì)不斷在實(shí)踐中鞏固容易遺忘的知識(shí)點(diǎn)并解決老問題��。
最近一直在摸索適合自己的學(xué)習(xí)方式�。我在吸收新知識(shí)方面比較慢,所以第一遍都會(huì)踏踏實(shí)實(shí)地學(xué)習(xí)���,標(biāo)記出不明白的地方����,但是不會(huì)硬磕,過一段時(shí)間再看看可能就自然而然地想通了�����,很多時(shí)候后續(xù)知識(shí)的學(xué)習(xí)會(huì)促進(jìn)前期知識(shí)的理解�����。因?yàn)橛洃浟σ话?�,所以學(xué)習(xí)新知識(shí)時(shí)更適合拿出整塊的時(shí)間來學(xué)習(xí)同一科目��,這樣可以有效降低每次學(xué)習(xí)前都要先回顧之前的知識(shí)點(diǎn)而花費(fèi)的時(shí)間�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;












 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330