數(shù)值型數(shù)據(jù)的探索分析
數(shù)據(jù)分析過程中�,往往需要對(duì)數(shù)據(jù)作基本的探索性分析��,查看數(shù)據(jù)是否存在問題�,如缺失值數(shù)量、是否存在明顯的異常值����、數(shù)據(jù)是如何分布的、數(shù)據(jù)的集中趨勢(shì)和離散趨勢(shì)等�����。
探索性分析一般包括三大部分����,即數(shù)據(jù)的分布情況、數(shù)據(jù)的集中與離散趨勢(shì)和數(shù)據(jù)的分布形態(tài):
首先來看看關(guān)于數(shù)據(jù)分布情況的探索性分析�。一般統(tǒng)計(jì)中通過5數(shù)就可以大致了解數(shù)據(jù)的分布,他們是最小值���、下四分位數(shù)����、中位數(shù)、上四分位數(shù)和最大值��。
其次看看數(shù)據(jù)的集中趨勢(shì)和離散趨勢(shì)��,通過集中趨勢(shì)可以了解數(shù)據(jù)的中心值或代表值���,通過離散趨勢(shì)可以了解數(shù)據(jù)遠(yuǎn)離中心的程度����。關(guān)于集中趨勢(shì)���,一般可使用均值、眾數(shù)��、中位數(shù)來衡量�,離散趨勢(shì)一般通過標(biāo)準(zhǔn)差、極差和四分位差來體現(xiàn)��。
最后看看數(shù)據(jù)的分布形態(tài)���,數(shù)據(jù)的分布形態(tài)無非是相比于正態(tài)分布而言�����,即偏度和峰度��。偏度是數(shù)據(jù)分布形態(tài)呈現(xiàn)左偏或右偏��;峰度是數(shù)據(jù)分布形態(tài)呈現(xiàn)尖瘦或矮胖�����。對(duì)于偏度和峰度需要說明的是:若偏度=0�����,則無偏�;若偏度>0,則有偏�;若偏度<0,則左偏�;若峰度=0,則陡峭程度與正態(tài)分布一致���;如峰度>0�����,則分布陡峭����;若峰度<0,則分布平緩����。
下面從定量和定性的角度看觀察數(shù)據(jù)的探索性分析過程:
自定義函數(shù)describe_statistics,函數(shù)返回變量的觀測(cè)數(shù)目�、缺失值數(shù)目、最小值�、下四分位數(shù)、中位數(shù)����、上四分位數(shù)、最大值�、均值��、眾數(shù)��、標(biāo)準(zhǔn)差、極差�、四分位差、偏度和峰度�。這里的自定義函數(shù)返回結(jié)果類似于SAS的輸出結(jié)果形態(tài):
```{r}
describe_statistics <- function(x){
options(digits = 3)
require(timeDate);
N = length(x);
Nmiss = sum(is.na(x));
Min = min(x, na.rm = TRUE);
Q1 = quantile(x, probs = 0.25, na.rm = TRUE);
Median = median(x, na.rm = TRUE);
Q3 = quantile(x, probs = 0.75, na.rm = TRUE);
Max = max(x, na.rm = TRUE);
Mean = mean(x, na.rm = TRUE);
Mode = as.numeric(names(table(x)))[which.max(table(x))];
Sd = sd(x, na.rm = TRUE);
Range = abs(diff(range(x)));
QRange = IQR(x, na.rm = TRUE);
Skewness = skewness(x, na.rm = TRUE);
Kurtosis = kurtosis(x, na.rm = TRUE);
#返回函數(shù)結(jié)果
return(data.frame(N = N, Nmiss = Nmiss, Min = Min, Q1 = Q1, Median = Median, Q3 = Q3, Max = Max, Mean = Mean, Mode = Mode, Sd = Sd, Range = Range, QRange = QRange, Skewness = Skewness, Kurtosis = Kurtosis))
}
```
下面我們就用這個(gè)自定義函數(shù)來測(cè)試一下,通過上面的這些統(tǒng)計(jì)量值來探索數(shù)據(jù)分布�����、集中趨勢(shì)�����、離散趨勢(shì)和分布形態(tài)����。由于本文講解的是數(shù)值型數(shù)據(jù)的探索分析,故需要將數(shù)據(jù)框中的數(shù)值型數(shù)據(jù)挑選出來�����,仍然自定義函數(shù)�����,返回?cái)?shù)據(jù)框中所有數(shù)值型數(shù)據(jù)的字段:
```{r}
Value_Variables <- function(df){
Vars <- names(df)[sapply(df,class) == 'integer' | sapply(df,class) == 'numeric']
return(Vars)
}
```
以R中自帶的iris數(shù)據(jù)集測(cè)試:
```{r}
vars <- Value_Variables(iris)
res <- sapply(iris[,vars], describe_statistics)
res
```
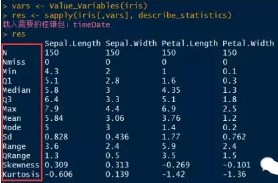
上面的結(jié)果呈現(xiàn)了鳶尾花四個(gè)數(shù)值型變量的探索性分析�。
以C50包中的churnTrain數(shù)據(jù)集測(cè)試:
```{r}
library(C50)
data(churn)
vars <- Value_Variables(churnTrain)
res <- sapply(churnTrain[,vars], describe_statistics)
res
```
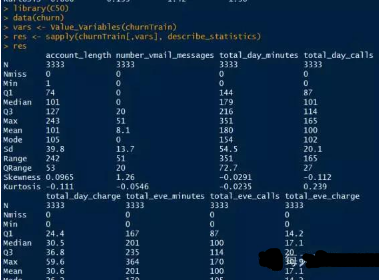
很顯然,當(dāng)變量很多時(shí),這樣的返回結(jié)果讓人看的很難受���,如要使輸出結(jié)果便讀的話����,可以將返回結(jié)果轉(zhuǎn)置:
```{r}
t(res)
```
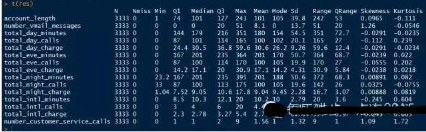
這會(huì)結(jié)果要比較整齊����,好看。
以上是從定量的角度來探索數(shù)據(jù)的分布��、集中趨勢(shì)����、離散趨勢(shì)和分布形態(tài),下面我們簡(jiǎn)單介紹一下定性的方法�����。
從定性角度��,即通過可視化來進(jìn)行數(shù)據(jù)的探索性分析���,強(qiáng)烈推薦使用GGally包中的ggpairs()函數(shù)�����,該函數(shù)將繪制兩兩變量的相關(guān)系數(shù)�����、散點(diǎn)圖�����,同時(shí)也繪制出單變量的密度分布圖:
```{r}
library(GGally)
vars <- Value_Variables(iris)
ggpairs(iris[,vars])
```
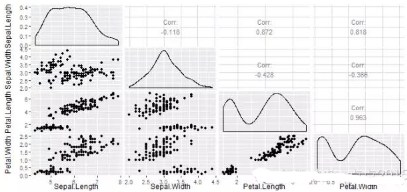
上圖不僅僅反映了數(shù)據(jù)的分布情況���、還得出兩兩變量間的散點(diǎn)圖和相關(guān)系數(shù),可為下一步分析做鋪墊�。
數(shù)據(jù)的探索性分析過程中,通過定量和定性方法的搭配�,可使分析者快速的了解數(shù)據(jù)的結(jié)構(gòu)、分布及內(nèi)在關(guān)系��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330