條件概率是樸素貝葉斯模型的基礎(chǔ)���。
假設(shè)�����,你的xx公司正在面臨著用戶流失的壓力���。雖然�,你能計(jì)算用戶整體流失的概率(流失用戶數(shù)/用戶總數(shù))�����。但這個(gè)數(shù)字并沒有多大意義,因?yàn)橘Y源是有限的�,利用這個(gè)數(shù)字你只能撒胡椒面似的把錢撒在所有用戶上,顯然不經(jīng)濟(jì)�����。你非常想根據(jù)用戶的某種行為����,精確地估計(jì)一個(gè)用戶流失的概率,若這個(gè)概率超過某個(gè)閥值����,再觸發(fā)用戶挽留機(jī)制。這樣能把錢花到最需要花的地方�����。
你搜遍腦子里的數(shù)據(jù)分析方法�,終于,一個(gè)250年前的人名在腦中閃現(xiàn)�����。就是“貝葉斯Bayes”。你取得了近一個(gè)月的流失用戶數(shù)�����、流失用戶中未讀消息大于5條的人數(shù)�、近一個(gè)月的活躍用戶數(shù)及活躍用戶中未讀消息大于5條的人數(shù)。在此基礎(chǔ)上���,你獲得了一個(gè)“一旦用戶未讀消息大于5條��,他流失的概率高達(dá)%”的精確結(jié)論���。怎么實(shí)現(xiàn)這個(gè)計(jì)算呢?先別著急���,為了解釋清楚貝葉斯模型,我們先定義一些名詞�。
-
概率(Probability)——0和1之間的一個(gè)數(shù)字,表示一個(gè)特定結(jié)果發(fā)生的可能性���。比如投資硬幣���,“正面朝上”這個(gè)特定結(jié)果發(fā)生的可能性為0.5,這個(gè)0.5就是概率。換一種說法���,計(jì)算樣本數(shù)據(jù)中出現(xiàn)該結(jié)果次數(shù)的百分比�����。即你投一百次硬幣�����,正面朝上的次數(shù)基本上是50次��。
-
幾率(Odds)——某一特定結(jié)果發(fā)生與不發(fā)生的概率比���。如果你明天電梯上遇上你暗戀的女孩的概率是0.1,那么遇不上她的概率就是0.9�����,那么遇上暗戀女孩的幾率就是1/9����,幾率的取值范圍是0到無窮大。
-
似然(Likelihood)——兩個(gè)相關(guān)的條件概率之比�,即給定B發(fā)生的情況下�,某一特定結(jié)果A發(fā)生的概率和給定B不發(fā)生的情況下A發(fā)生的概率之比�����。另一種表達(dá)方式是����,給定B的情況下A發(fā)生的幾率和A的整體幾率之比。兩個(gè)計(jì)算方式是等價(jià)的��。
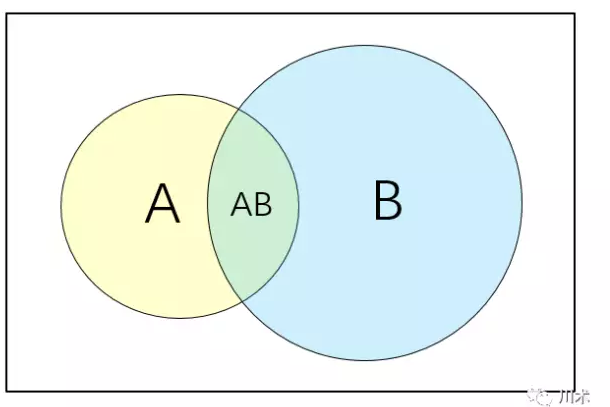
因?yàn)樯厦嬖谒迫划?dāng)中提到了條件概率����,那么我們有必要將什么是條件概率做更詳盡的闡述。
如上面的韋恩圖�����,我們用矩形表示一個(gè)樣本空間����,代表隨機(jī)事件發(fā)生的一切可能結(jié)果��。的在統(tǒng)計(jì)學(xué)中����,我們用符號P表示概率�����,A事件發(fā)生的概率表示為P(A)���。兩個(gè)事件間的概率表達(dá)實(shí)際上相當(dāng)繁瑣,我們只介紹本書中用得著的關(guān)系:
-
A事件與B事件同時(shí)發(fā)生的概率表示為P(A∩B)����,或簡寫為P(AB)即兩個(gè)圓圈重疊的部分。
-
A不發(fā)生的概率為1-P(A)�����,寫為P(~A)�����,即矩形中除了圓圈A以外的其他部分��。
-
A或者B至少有一個(gè)發(fā)生的概率表示為P(A∪B)����,即圓圈A與圓圈B共同覆蓋的區(qū)域�����。
-
在B事件發(fā)生的基礎(chǔ)上發(fā)生A的概率表示為P(A|B)�����,這便是我們前文所提到的條件概率��,圖形上它有AB重合的面積比上B的面積�����。
回到我們的例子�。以P(A)代表用戶流失的概率�,P(B)代表用戶有5條以上未讀信息的概率,P(B|A)代表用戶流失的前提下未讀信息大于5條的概率���。我們要求未讀信息大于5條的用戶流失的概率�,即P(A|B)��,貝葉斯公式告訴我們:
P(A|B)=P(AB)/P(B)
=P(B|A)*P(A)/P(B)
從公式中可知���,如果要計(jì)算B條件下A發(fā)生的概率�����,只需要計(jì)算出后面等式的三個(gè)部分�����,B事件的概率(P(B))�,是B的先驗(yàn)概率����、A屬于某類的概率(P(A)),是A的先驗(yàn)概率�����、以及已知A的某個(gè)分類下����,事件B的概率(P(B|A)),是后驗(yàn)概率���。
如果要確定某個(gè)樣本歸屬于哪一類��,則需要計(jì)算出歸屬不同類的概率���,再從中挑選出最大的概率
我們把上面的貝葉斯公式寫出這樣����,也許你能更好的理解:
MAX(P(Ai|B))=MAX(P(B|Ai)*P(Ai)/P(B))
而這個(gè)公式告訴我們��,需要計(jì)算最大的后驗(yàn)概率�����,只需要計(jì)算出分子的最大值即可���,而不同水平的概率P(C)非常容易獲得�����,故難點(diǎn)就在于P(X|C)的概率計(jì)算�。而問題的解決���,正是聰明之處����,即貝葉斯假設(shè)變量X間是條件獨(dú)立的,故而P(X|C)的概率就可以計(jì)算為:
P(B|Ai) =P(B1/Ai)*P(B2/Ai)*P(B3/Ai)*…..*P(Bn/Ai)
如下圖����,由這個(gè)公式我們就能輕松計(jì)算出����,在觀察到某用戶的未讀信息大于5條時(shí),他流失的概率為80%�����。80%的數(shù)值比原來的30%真是靠譜太多了�����。
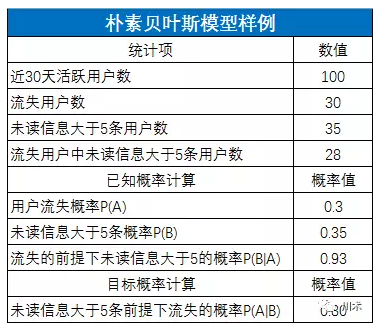
當(dāng)然���,現(xiàn)實(shí)情況并不會(huì)像這個(gè)例子這么理想化����。大家會(huì)問����,憑什么你就會(huì)想到用“未讀消息大于5條”來作為條件概率?我只能說,現(xiàn)實(shí)情況中�����,你可能要找上一堆覺得能夠凸顯用戶流失的行為���,然后一一做貝葉斯規(guī)則�,來測算他們是否能顯著識別用戶流失�����。尋找這個(gè)字段的效率�����,取決于你對業(yè)務(wù)的理解程度和直覺的敏銳性��。另外��,你還需要定義“流失”和“活躍”�,還需要定義貝葉斯規(guī)則計(jì)算的基礎(chǔ)樣本,這決定了結(jié)果的精度��。
樸素貝葉斯的應(yīng)用不止于此���,我們再例舉一個(gè)更復(fù)雜���,但現(xiàn)實(shí)場景也更實(shí)際的案例�。假設(shè)你為了肅清電商平臺上的惡性商戶(刷單����、非法交易����、惡性競爭等),委托算法團(tuán)隊(duì)開發(fā)了一個(gè)識別商家是否是惡性商戶的模型M1���。為什么要開發(fā)模型呢����?因?yàn)橹白R別惡性商家����,你只能通過用戶舉報(bào)和人肉識別異常數(shù)據(jù)的方式,人力成本高且速率很慢����。你指望有智能的算法來提高效率。
之前監(jiān)察團(tuán)隊(duì)的成果告訴我們,目前平臺上的惡性商戶比率為0.2%��,記為P(E)����,那么P(~E)就是99.8%。利用模型M1進(jìn)行檢測����,你發(fā)現(xiàn)在監(jiān)察團(tuán)隊(duì)已判定的惡性商戶中,由模型M1所判定為陽性(惡性商戶)的人數(shù)占比為90%��,這是一個(gè)條件概率����,表示為P(P|E)=90%;在監(jiān)察團(tuán)隊(duì)判定為健康商戶群體中����,由模型M1判定為陽性的人數(shù)占比為8%,表示為P(P|~E)=8%�����。乍看之下�,你是不是覺得這個(gè)模型的準(zhǔn)確度不夠呢��?感覺對商戶有8%的誤殺�,還有10%的漏判����。其實(shí)不然,這個(gè)模型的結(jié)果不是你想當(dāng)然的這么使用的
這里�����,我們需要使用一個(gè)稱為“全概率公式”的計(jì)算模型�����,來計(jì)算出在M1判別某個(gè)商戶為惡性商戶時(shí)�,這個(gè)結(jié)果的可信度有多高����。這正是貝葉斯模型的核心。當(dāng)M1判別某個(gè)商戶為惡性商戶時(shí)�����,這個(gè)商戶的確是惡性商戶的概率由P(E|P)表示:
P(E|P)
=P(P|E)*P(E) / (P(E)*P(P|E)+P(~E)*P(P|~E))
上面就是全概率公式�。要知道判別為惡性商戶的前提下�����,該商戶實(shí)際為惡性商戶的概率�����,需要由先前的惡性商戶比率P(E)��,以判別的惡性商戶中的結(jié)果為陽性的商戶比率P(P|E)����,以判別為健康商戶中的結(jié)果為陽性的比率P(P|~E)�����,以判別商戶中健康商戶的比率P(~E)來共同決定����。
P(E) 0.2%
P(P|E) 90%
P(~E) 99.8%
P(P|~E) 8%
P(E|P)= P(P|E)*P(E) / (P(E)*P(P|E)+P(~E)*P(P|~E)) 2.2%
由上面的數(shù)字,帶入全概率公式后�����,我們獲得的結(jié)果為2.2%�����。也就是說,根據(jù)M1的判別為陽性的結(jié)果�,某個(gè)商戶實(shí)際為惡性商戶的概率為2.2%,是不進(jìn)行判別的0.2%的11倍�����。
你可能認(rèn)為2.2%的概率并不算高���。但實(shí)際情況下你應(yīng)該這么思考:被M1模型判別為惡性商戶�����,說明這家商戶做出惡性行為的概率是一般商戶的11倍�,那么��,就非常有必要用進(jìn)一步的手段進(jìn)行檢查了����。
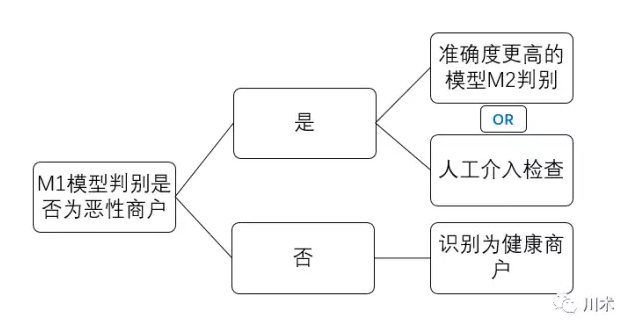
惡性商戶判別模型真正的使用邏輯應(yīng)該是如下圖所示���。我們先用M1進(jìn)行一輪判別���,結(jié)果是陽性的商戶����,說明出現(xiàn)惡性行為的概率是一般商戶的11倍���,那么有必要用精度更高的方式進(jìn)行判別���,或者人工介入進(jìn)行檢查。精度更高的檢查和人工介入���,成本都是非常高的�。因此M1模型的使用能夠使我們的成本得到大幅節(jié)約��。
貝葉斯模型在很多方面都有應(yīng)用��,我們熟知的領(lǐng)域就有垃圾郵件識別��、文本的模糊匹配�����、欺詐判別��、商品推薦等等。通過貝葉斯模型的闡述�����,大家應(yīng)該有這樣的一種體會(huì):分析模型并不取決于多么復(fù)雜的數(shù)學(xué)公式���,多么高級的軟件工具�����,多么高深的算法組合����;它們的原理往往是通俗易懂的�,實(shí)現(xiàn)起來也沒有多高的門檻。比如貝葉斯模型�����,用Excel的單元格和加減乘除的符號就能實(shí)現(xiàn)��。所以����,不要覺得數(shù)據(jù)分析建模有多遙遠(yuǎn),其實(shí)就在你手邊�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330