數(shù)據(jù)分析中常見的七種回歸分析以及R語言實現(xiàn)(三)---嶺回歸
我們在回歸分析的時候�,古典模型中有一個基本的假定就是自變量之間是不相關的��,但是如果我們在擬合出來的回歸模型出現(xiàn)了自變量之間高度相關的話���,可能對結果又產(chǎn)生影響,我們稱這個問題為多重共線性�����,多重共線性又分為兩種,一種是完全多重共線性�����,還有一種是不完全多重共線性����;
產(chǎn)生的原因有幾個方面
1、變量之間存在內部的聯(lián)系
2����、變量之間存在共同的趨勢等
造成的后果分兩部分
完全多重共線性造成的后果
1、當自變量線性相關的時候���,參數(shù)將無法唯一確定����,參數(shù)的方差將趨近于無窮大��,這時候無法使用最小二乘法
不完全多重共線性造成的后果
1��、參數(shù)估計量的方差隨著多重共線性的嚴重程度的增加而增加��,但是參數(shù)是可以估計的
2、進行統(tǒng)計檢驗時容易刪除掉重要解釋變量
因為當多重共線性的時候容易造成自變量對因變量不顯著�����,從模型中錯誤的剔除����,這樣容易刪除重要解釋變量的設定���;
3、參數(shù)的置信區(qū)間明顯擴大
因為由于存在多重共線性��。我們的參數(shù)估計都有較大的標準差,因此參數(shù)真值的置信區(qū)間也將增大
那么我們怎么去判斷一個模型上存在多重共線性呢����?
根據(jù)經(jīng)驗表明,多重共線性存在的一個標志就是就模型存在較大的標準差,和較小的T統(tǒng)計量��,如果一個模型的可決系數(shù)R^2很大�,F(xiàn)檢驗高度限制,但偏回歸系數(shù)的T檢驗幾乎都不顯著,那么模型很可能是存在多重共線性了���。因為通過檢驗,雖然各個解釋變量對因變量的共同影響高度顯著���,但每個解釋變量的單獨影響都不顯著����,我們無法判斷哪個解釋變量對被解釋變量的影響更大
1、可以利用自變量之間的簡單相關系數(shù)檢驗
這個方法是一個簡便的方法�����,一般而言���,如果每兩個解釋變量的簡單相關系數(shù)一般較高,則可以認為是存在著嚴重的多重共線性
2��、方差膨脹因子
在回歸中我們用VIF表示方差膨脹因子
表達式 VIF=1/(1-R^2)
隨著多重共線性的嚴重程度增強��,方差膨脹因子會逐漸的變大,一般的當VIF>=10的時候,我們就可以認為存在嚴重多重共線性;
在R語言中car包中的vif()函數(shù)可以幫我們算出這個方差膨脹一找你
這就介紹這兩個了,其實還有好多方法�����,大家可以可以私底下查,或者和我一起交流;
多重共線性的解決辦法
因為存在多重共線性����,我們還是擬合模型的;當然會有解決辦法����,這里我就介紹一下常用的方法嶺回歸��;其他的方法也有�,這里就不說了�����;
這里就說說大概的思想�����,具體推導的步驟這里就不寫����,有興趣的可以網(wǎng)上查查�;在多重共線性十分嚴重下����,兩個共線變量的系數(shù)之間的二維聯(lián)合分布是一個山嶺曲面,曲面上的每一個點對應一種殘差平方和����,點的位置越高���,相應的殘差平方和越小���。因此山嶺最高點和殘差平方和的最小值相對應,相應的參數(shù)值便是參數(shù)的最小二乘法估計值����,但由于多重共線性的存在最小二乘法估計量已經(jīng)不適用�����,一個自然的想法就是應尋找其他的更適合的估計量���,這種估計量既要具有較小的方差,又不能使殘差平方和過分偏離其極小值����。在參數(shù)的聯(lián)合分布曲面上,能滿足這種要求的點只能沿著山嶺尋找�,這就是嶺回歸法���;
這個方法實質是犧牲了無偏性來尋求參數(shù)估計的最小方差性�����;
缺點:通常嶺回歸方程的R平方值會稍低于普通回歸分析��,但回歸系數(shù)的顯著性往往明顯高于普通回歸���,在存在共線性問題和病態(tài)數(shù)據(jù)偏多的研究中有較大的實用價值
R語言建模
這里使用可能要使用到car和MASS,由于謝老師已經(jīng)寫了詳細的過程����,這里我就全程照搬了����,偷了個懶���,寫個代碼過程其實也有些累的��;
1 分別使用嶺回歸和Lasso解決薛毅書第279頁例6.10的回歸問題
cement <- data.frame(X1 = c(7, 1, 11, 11, 7, 11, 3, 1, 2, 21, 1, 11, 10), X2 = c(26,
29, 56, 31, 52, 55, 71, 31, 54, 47, 40, 66, 68), X3 = c(6, 15, 8, 8, 6,
9, 17, 22, 18, 4, 23, 9, 8), X4 = c(60, 52, 20, 47, 33, 22, 6, 44, 22, 26,
34, 12, 12), Y = c(78.5, 74.3, 104.3, 87.6, 95.9, 109.2, 102.7, 72.5, 93.1,
115.9, 83.8, 113.3, 109.4))
cement
## X1 X2 X3 X4 Y
## 1 7 26 6 60 78.5
## 2 1 29 15 52 74.3
## 3 11 56 8 20 104.3
## 4 11 31 8 47 87.6
## 5 7 52 6 33 95.9
## 6 11 55 9 22 109.2
## 7 3 71 17 6 102.7
## 8 1 31 22 44 72.5
## 9 2 54 18 22 93.1
## 10 21 47 4 26 115.9
## 11 1 40 23 34 83.8
## 12 11 66 9 12 113.3
## 13 10 68 8 12 109.4
lm.sol <- lm(Y ~ ., data = cement)
summary(lm.sol)
##
## Call:
## lm(formula = Y ~ ., data = cement)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.175 -1.671 0.251 1.378 3.925
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 62.405 70.071 0.89 0.399
## X1 1.551 0.745 2.08 0.071 .
## X2 0.510 0.724 0.70 0.501
## X3 0.102 0.755 0.14 0.896
## X4 -0.144 0.709 -0.20 0.844
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.45 on 8 degrees of freedom
## Multiple R-squared: 0.982, Adjusted R-squared: 0.974
## F-statistic: 111 on 4 and 8 DF, p-value: 4.76e-07
# 從結果看�,截距和自變量的相關系數(shù)均不顯著�。
# 利用car包中的vif()函數(shù)查看各自變量間的共線情況
library(car)
vif(lm.sol)
## X1 X2 X3 X4
## 38.50 254.42 46.87 282.51
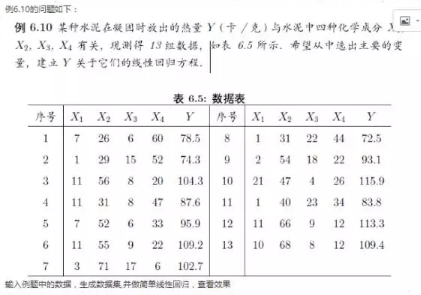
# 從結果看,各自變量的VIF值都超過10�����,存在多重共線性�����,其中��,X2與X4的VIF值均超過200.
plot(X2 ~ X4, col = "red", data = cement)
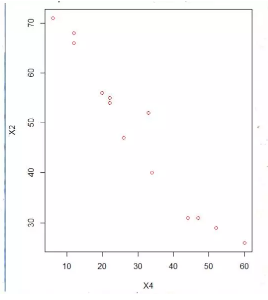
接下來���,利用MASS包中的函數(shù)lm.ridge()來實現(xiàn)嶺回歸���。下面的計算試了151個lambda值����,最后選取了使得廣義交叉驗證GCV最小的那個����。
library(MASS)
##
## Attaching package: 'MASS'
##
## The following object is masked _by_ '.GlobalEnv':
##
## cement
ridge.sol <- lm.ridge(Y ~ ., lambda = seq(0, 150, length = 151), data = cement,
model = TRUE)
names(ridge.sol) # 變量名字
## [1] "coef" "scales" "Inter" "lambda" "ym" "xm" "GCV" "kHKB"
## [9] "kLW"
ridge.sol$lambda[which.min(ridge.sol$GCV)] ##找到GCV最小時的lambdaGCV
## [1] 1
ridge.sol$coef[which.min(ridge.sol$GCV)] ##找到GCV最小時對應的系數(shù)
## [1] 7.627
par(mfrow = c(1, 2))
# 畫出圖形,并作出lambdaGCV取最小值時的那條豎直線
matplot(ridge.sol$lambda, t(ridge.sol$coef), xlab = expression(lamdba), ylab = "Cofficients",
type = "l", lty = 1:20)
abline(v = ridge.sol$lambda[which.min(ridge.sol$GCV)])
# 下面的語句繪出lambda同GCV之間關系的圖形
plot(ridge.sol$lambda, ridge.sol$GCV, type = "l", xlab = expression(lambda),
ylab = expression(beta))
abline(v = ridge.sol$lambda[which.min(ridge.sol$GCV)])
par(mfrow = c(1, 1))
# 從上圖看�����,lambda的選擇并不是那么重要�����,只要不離lambda=0太近就沒有多大差別�。
# 下面利用ridge包中的linearRidge()函數(shù)進行自動選擇嶺回歸參數(shù)
library(ridge)
mod <- linearRidge(Y ~ ., data = cement)
summary(mod)
##
## Call:
## linearRidge(formula = Y ~ ., data = cement)
##
##
## Coefficients:
## Estimate Scaled estimate Std. Error (scaled) t value (scaled)
## (Intercept) 83.704 NA NA NA
## X1 1.292 26.332 3.672 7.17
## X2 0.298 16.046 3.988 4.02
## X3 -0.148 -3.279 3.598 0.91
## X4 -0.351 -20.329 3.996 5.09
## Pr(>|t|)
## (Intercept) NA
## X1 7.5e-13 ***
## X2 5.7e-05 ***
## X3 0.36
## X4 3.6e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Ridge parameter: 0.01473, chosen automatically, computed using 2 PCs
##
## Degrees of freedom: model 3.01 , variance 2.84 , residual 3.18
# 從模型運行結果看����,測嶺回歸參數(shù)值為0.0147,各自變量的系數(shù)顯著想明顯提高(除了X3仍不顯著)
最后��,利用Lasso回歸解決共線性問題
library(lars)
## Loaded lars 1.2
x = as.matrix(cement[, 1:4])
y = as.matrix(cement[, 5])
(laa = lars(x, y, type = "lar")) #lars函數(shù)值用于矩陣型數(shù)據(jù)
##
## Call:
## lars(x = x, y = y, type = "lar")
## R-squared: 0.982
## Sequence of LAR moves:
## X4 X1 X2 X3
## Var 4 1 2 3
## Step 1 2 3 4
# 由此可見�,LASSO的變量選擇依次是X4���,X1,X2�����,X3
plot(laa) #繪出圖數(shù)據(jù)分析培訓
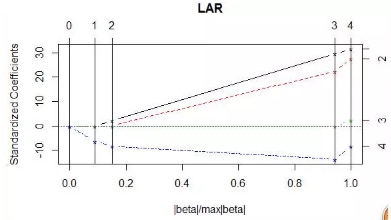
summary(laa) #給出Cp值
## LARS/LAR
## Call: lars(x = x, y = y, type = "lar")
## Df Rss Cp
## 0 1 2716 442.92
## 1 2 2219 361.95
## 2 3 1918 313.50
## 3 4 48 3.02
## 4 5 48 5.00
# 根據(jù)課上對Cp含義的解釋(衡量多重共線性���,其值越小越好)��,我們取到第3步�,使得Cp值最小����,也就是選擇X4,X1���,X2這三個變量
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330