作者:Python進(jìn)階者
來(lái)源:Python爬蟲(chóng)與數(shù)據(jù)挖掘
前言
前幾天有個(gè)叫【小明】的粉絲在問(wèn)了一道關(guān)于Python處理文本可視化+語(yǔ)義分析的問(wèn)題�。
他要構(gòu)建語(yǔ)料庫(kù),目前通過(guò)Python網(wǎng)絡(luò)爬蟲(chóng)抓到的數(shù)據(jù)存在一個(gè)csv文件里邊�,現(xiàn)在要把數(shù)據(jù)放進(jìn)txt里,表示不會(huì)�����,然后還有后面的詞云可視化��,分詞�����,語(yǔ)義分析等�,都不太會(huì)。
一�、思路
內(nèi)容稍微有點(diǎn)多,大體思路如下�,先將csv中的文本取出,之后使用停用詞做分詞處理�����,再做詞云圖�,之后做情感分析。
1����、將csv文件中的文本逐行取出,存新的txt文件��,這里運(yùn)行代碼《讀取csv文件中文本并存txt文檔.py》進(jìn)行實(shí)現(xiàn)�,得到文件《職位表述文本.txt》
2、運(yùn)行代碼《使用停用詞獲取最后的文本內(nèi)容.py》���,得到使用停用詞獲取最后的文本內(nèi)容����,生成文件《職位表述文本分詞后_outputs.txt》
3���、運(yùn)行代碼《指定txt詞云圖.py》��,可以得到詞云圖��;
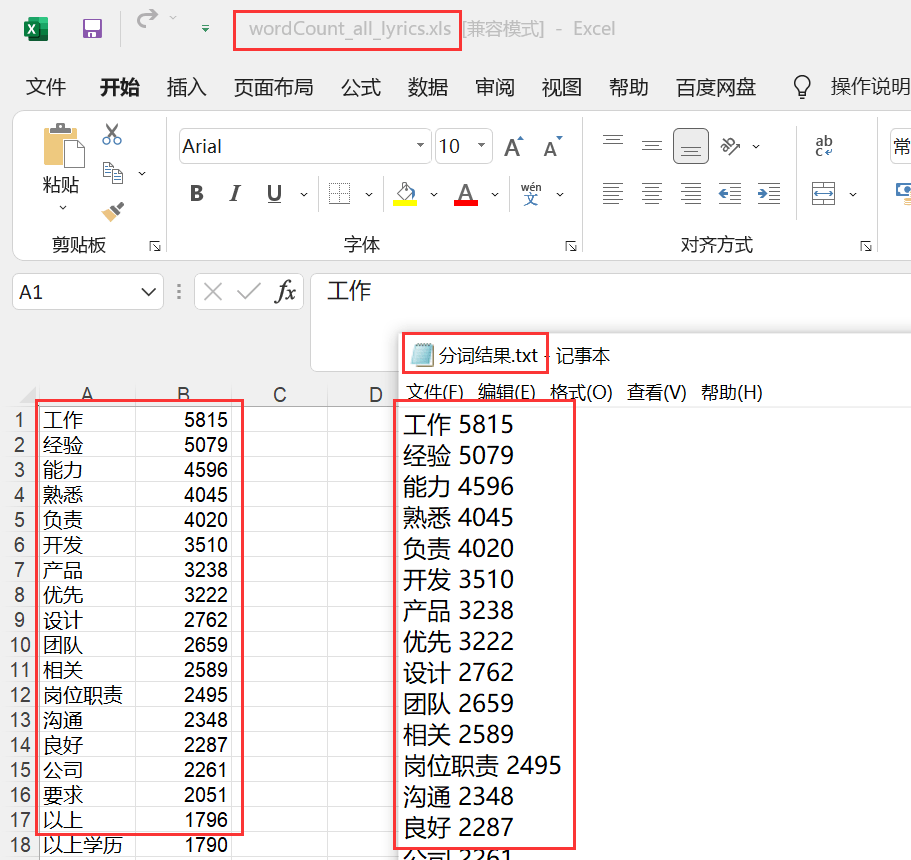
4���、運(yùn)行代碼《jieba分詞并統(tǒng)計(jì)詞頻后輸出結(jié)果到Excel和txt文檔.py》����,得到《wordCount_all_lyrics.xls》和《分詞結(jié)果.txt》文件�,將《分詞結(jié)果.txt》中的統(tǒng)計(jì)值可以去除,生成《情感分析用詞.txt》����,給第五步情感分析做準(zhǔn)備
5、運(yùn)行代碼《情感分析.py》�,得到情感分析的統(tǒng)計(jì)值,取平均值可以大致確認(rèn)情感是正還是負(fù)���。
二���、實(shí)現(xiàn)過(guò)程
1.將csv文件中的文本逐行取出,存新的txt文件
這里運(yùn)行代碼《讀取csv文件中文本并存txt文檔.py》進(jìn)行實(shí)現(xiàn)����,得到文件《職位表述文本.txt》,代碼如下�。
# coding: utf-8
import pandas as pd
df = pd.read_csv('./職位描述.csv', encoding='gbk')
# print(df.head())
for text in df['Job_Description']:
# print(text)
if text is not None:
with open('職位表述文本.txt', mode='a', encoding='utf-8') as file:
file.write(str(text))
print('寫(xiě)入完成')
2.使用停用詞獲取最后的文本內(nèi)容
運(yùn)行代碼《使用停用詞獲取最后的文本內(nèi)容.py》�,得到使用停用詞獲取最后的文本內(nèi)容����,生成文件《職位表述文本分詞后_outputs.txt》,代碼如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import jieba
# jieba.load_userdict('userdict.txt')
# 創(chuàng)建停用詞list
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
# 對(duì)句子進(jìn)行分詞
def seg_sentence(sentence):
sentence_seged = jieba.cut(sentence.strip())
stopwords = stopwordslist('stop_word.txt') # 這里加載停用詞的路徑
outstr = ''
for word in sentence_seged:
if word not in stopwords:
if word != 't':
outstr += word
outstr += " "
return outstr
inputs = open('職位表述文本.txt', 'r', encoding='utf-8')
outputs = open('職位表述文本分詞后_outputs.txt', 'w', encoding='utf-8')
for line in inputs:
line_seg = seg_sentence(line) # 這里的返回值是字符串
outputs.write(line_seg + 'n')
outputs.close()
inputs.close()
關(guān)鍵節(jié)點(diǎn)�,都有相應(yīng)的注釋?zhuān)阒恍枰鎿Q對(duì)應(yīng)的txt文件即可����,如果有遇到編碼問(wèn)題,將utf-8改為gbk即可解決。
3.制作詞云圖
運(yùn)行代碼《指定txt詞云圖.py》����,可以得到詞云圖�,代碼如下:
from wordcloud import WordCloud
import jieba
import numpy
import PIL.Image as Image
def cut(text):
wordlist_jieba=jieba.cut(text)
space_wordlist=" ".join(wordlist_jieba)
return space_wordlist
with open(r"C:UserspdcfiDesktopxiaoming職位表述文本.txt" ,encoding="utf-8")as file:
text=file.read()
text=cut(text)
mask_pic=numpy.array(Image.open(r"C:UserspdcfiDesktopxiaomingpython.png"))
wordcloud = WordCloud(font_path=r"C:/Windows/Fonts/simfang.ttf",
collocations=False,
max_words= 100,
min_font_size=10,
max_font_size=500,
mask=mask_pic).generate(text)
image=wordcloud.to_image()
# image.show()
wordcloud.to_file('詞云圖.png') # 把詞云保存下來(lái)
如果想用你自己的圖片�,只需要替換原始圖片即可���。這里使用Python底圖做演示,得到的效果如下:

4.分詞統(tǒng)計(jì)
運(yùn)行代碼《jieba分詞并統(tǒng)計(jì)詞頻后輸出結(jié)果到Excel和txt文檔.py》�,得到《wordCount_all_lyrics.xls》和《分詞結(jié)果.txt》文件,將《分詞結(jié)果.txt》中的統(tǒng)計(jì)值可以去除���,生成《情感分析用詞.txt》�����,給第五步情感分析做準(zhǔn)備���,代碼如下:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import sys
import jieba
import jieba.analyse
import xlwt # 寫(xiě)入Excel表的庫(kù)
# reload(sys)
# sys.setdefaultencoding('utf-8')
if __name__ == "__main__":
wbk = xlwt.Workbook(encoding='ascii')
sheet = wbk.add_sheet("wordCount") # Excel單元格名字
word_lst = []
key_list = []
for line in open('職位表述文本.txt', encoding='utf-8'): # 需要分詞統(tǒng)計(jì)的原始目標(biāo)文檔
item = line.strip('nr').split('t') # 制表格切分
# print item
tags = jieba.analyse.extract_tags(item[0]) # jieba分詞
for t in tags:
word_lst.append(t)
word_dict = {}
with open("分詞結(jié)果.txt", 'w') as wf2: # 指定生成文件的名稱(chēng)
for item in word_lst:
if item not in word_dict: # 統(tǒng)計(jì)數(shù)量
word_dict[item] = 1
else:
word_dict[item] += 1
orderList = list(word_dict.values())
orderList.sort(reverse=True)
# print orderList
for i in range(len(orderList)):
for key in word_dict:
if word_dict[key] == orderList[i]:
wf2.write(key + ' ' + str(word_dict[key]) + 'n') # 寫(xiě)入txt文檔
key_list.append(key)
word_dict[key] = 0
for i in range(len(key_list)):
sheet.write(i, 1, label=orderList[i])
sheet.write(i, 0, label=key_list[i])
wbk.save('wordCount_all_lyrics.xls') # 保存為 wordCount.xls文件
得到的txt和excel文件如下所示:
5.情感分析的統(tǒng)計(jì)值
運(yùn)行代碼《情感分析.py》,得到情感分析的統(tǒng)計(jì)值�,取平均值可以大致確認(rèn)情感是正還是負(fù)��,代碼如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from snownlp import SnowNLP
# 積極/消極
# print(s.sentiments) # 0.9769551298267365 positive的概率
def get_word():
with open("情感分析用詞.txt", encoding='utf-8') as f:
line = f.readline()
word_list = []
while line:
line = f.readline()
word_list.append(line.strip('rn'))
f.close()
return word_list
def get_sentiment(word):
text = u'{}'.format(word)
s = SnowNLP(text)
print(s.sentiments)
if __name__ == '__main__':
words = get_word()
for word in words:
get_sentiment(word)
# text = u'''
# 也許
# '''
# s = SnowNLP(text)
# print(s.sentiments)
# with open('lyric_sentiments.txt', 'a', encoding='utf-8') as fp:
# fp.write(str(s.sentiments)+'n')
# print('happy end')
基于NLP語(yǔ)義分析���,程序運(yùn)行之后�����,得到的情感得分值如下圖所示:
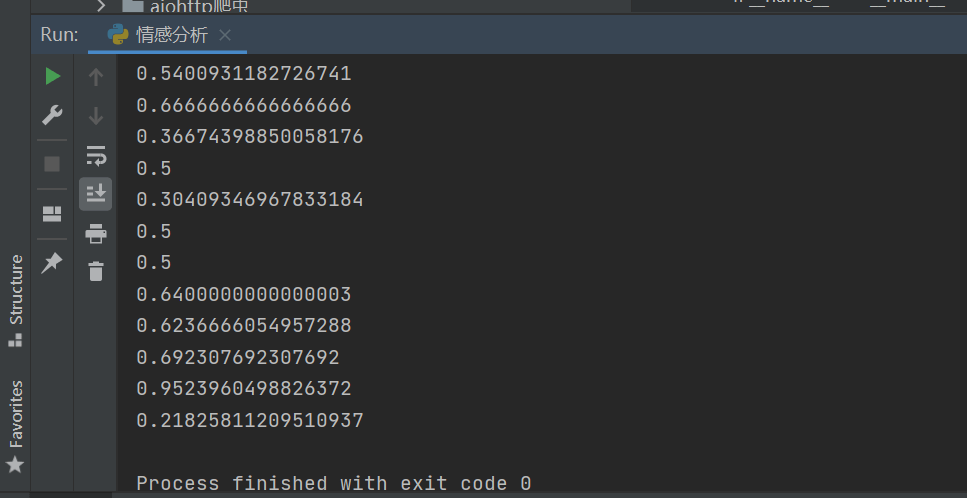
將得數(shù)取平均值�,一般滿(mǎn)足0.5分以上,說(shuō)明情感是積極的���,這里經(jīng)過(guò)統(tǒng)計(jì)之后��,發(fā)現(xiàn)整體是積極的�。
四��、總結(jié)
我是Python進(jìn)階者��。本文基于粉絲提問(wèn)�,針對(duì)一次文本處理,手把手教你對(duì)抓取的文本進(jìn)行分詞����、詞頻統(tǒng)計(jì)�����、詞云可視化和情感分析����,算是完成了一個(gè)小項(xiàng)目了��。下次再遇到類(lèi)似這種問(wèn)題或者小的課堂作業(yè)�����,不妨拿本項(xiàng)目練練手,說(shuō)不定有妙用噢����,拿個(gè)高分不在話(huà)下��!
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)��,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330