來源:數(shù)據(jù)STUDIO
作者:云朵君
一��、數(shù)據(jù)獲取
通過爬取全國城市在售預售新盤���,下面以獲取單個城市為例,介紹爬取數(shù)據(jù)部門主要代碼��。完整代碼見文末獲取方式����。
本次爬蟲使用到的模塊有requests_html、requests_cache�����、bs4.BeautifulSoup�、re等。若各位小伙伴們不太熟悉各個模塊,可以在文末推薦閱讀鏈接直達文章�����。
1����、定義函數(shù)
定義好獲取每個項目信息的函數(shù)。
def get_house_status(soup): """
獲取房屋狀態(tài)信息
""" house_status = []
status = soup.find_all(attrs={'class': 'fangyuan'})
for state in status:
_status = state.span.text
house_status.append(_status)
return house_status def get_house_price(soup): """
獲取房屋價格信息
""" house_price = []
regex = re.compile('s(S+)s')
prices = soup.find_all(attrs={'class': 'nhouse_price'})
for price in prices:
_prices = regex.findall(price.text)
_price = '' if _prices[0] == '價格待定':
pass else:
p = _prices[0].split('元')[0]
if '萬' in p:
_price = p + '元/套' else:
_price = p + '元/m2' house_price.append(_price)
return house_price def get_house_address(soup, c_city): """
獲取房屋地址信息
""" house_address = []
region = []
regex = re.compile('s(S+)s')
addresses = soup.find_all(attrs={'class': 'address'})
for address in addresses:
_address = regex.findall(address.text)
if len(_address) > 1:
region.append(_address[0].split('[')[1].split(']')[0])
else:
region.append(c_city)
house_address.append(address.a['title'])
return region, house_address def get_house_type(soup): """
獲取房屋類型信息
""" house_type = []
regex = re.compile('s(S+)s')
house_types = soup.find_all(attrs={'class': 'house_type clearfix'})
for _house_type in house_types:
type_list = regex.findall(_house_type.text)
type_str = '' for i in type_list:
type_str += i
house_type.append(type_str)
return house_type def get_house_name(soup): """
獲取項目名稱信息
""" house_name = []
regex = re.compile('s(S+)s')
nlcd_names = soup.find_all(attrs={'class': 'nlcd_name'})
for nlcd_name in nlcd_names:
name = '' names = regex.findall(nlcd_name.text)
if len(names) > 1:
for n in names:
name += n
house_name.append(name)
else:
house_name.extend(names)
return house_name
2�����、獲取數(shù)據(jù)的主函數(shù)
def get_data(c_city, city, start_page, cache): """
獲取數(shù)據(jù)
""" requests_cache.install_cache()
requests_cache.clear()
session = requests_cache.CachedSession() session.hooks = {'response': make_throttle_hook(np.random.randint(8, 12))} print(f'現(xiàn)在爬取{c_city}'.center(50, '*'))
last_page = get_last_page(city)
print(f'{c_city}共有{last_page}頁')
time.sleep(np.random.randint(15, 20))
df_city = pd.DataFrame()
user_agent = UserAgent().random
for page in range(start_page, last_page):
try:
cache['start_page'] = page
print(cache)
cache_json = json.dumps(cache, ensure_ascii=False)
with open('cache.txt', 'w', encoding='utf-8') as fout:
fout.write(cache_json)
print(f'現(xiàn)在爬取{c_city}的第{page + 1}頁.')
if page == 0:
df_city = pd.DataFrame()
else:
df_city = pd.read_csv(f'df_{c_city}.csv', encoding='utf-8')
url = html_url(city, page + 1)
if page % 2 == 0:
user_agent = UserAgent().random
header = {"User-Agent": user_agent}
res = session.post(url, headers=header)
if res.status_code == 200:
res.encoding = 'gb18030' soup = BeautifulSoup(res.text, features='lxml')
region, house_address = get_house_address(soup, c_city)
house_name = get_house_name(soup)
house_type = get_house_type(soup)
house_price = get_house_price(soup)
house_status = get_house_status(soup)
df_page = to_df(c_city,
region,
house_name,
house_address,
house_type,
house_price,
house_status)
df_city = pd.concat([df_city, df_page])
df_city.head(2)
time.sleep(np.random.randint(5, 10))
df_city.to_csv(f'df_{c_city}.csv',
encoding='utf-8',
index=False)
except:
df_city.to_csv(f'df_{c_city}.csv', encoding='utf-8', index=False)
cache_json = json.dumps(cache, ensure_ascii=False)
with open('cache.txt', 'w', encoding='utf-8') as fout:
fout.write(cache_json)
return df_city
爬取過程中�,將每個城市單獨保存為一個csv文件:
3、合并數(shù)據(jù)
import os import pandas as pd
df_total = pd.DataFrame() for root, dirs, files in os.path.walk('./全國房價數(shù)據(jù)集'):
for file in files:
split_file = os.path.splitext(file)
file_ext = split_file[1]
if file_ext == '.csv':
path = root + os.sep + file
df_city = pd.read_csv(path, encoding='utf-8')
df_total = pd.concat([df_total, df_city])
df_total.to_csv(root+os.sep+'全國新房202102.csv', encoding='utf-8', index=False)
1����、導入需要用的模塊
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import missingno as msno
2��、讀取數(shù)據(jù)
raw_data = pd.read_csv('全國新房202102.csv', encoding='utf-8')
raw_data.sample(5)
3���、查看下數(shù)據(jù)基本情況
>>> raw_data.shape
(54733, 7) >>> len(raw_data.city.drop_duplicates()) 581
爬取了全國581個城市,共計54733個在售�、預售房產(chǎn)項目�。
由于獲取到的數(shù)據(jù)存在缺失值、異常值以及不能直接使用的數(shù)據(jù)���,因此在分析前需要先處理缺失值����、異常值等���,以便后續(xù)分析����。
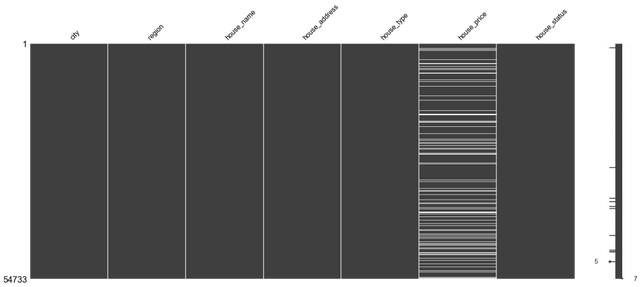
4���、缺失值分析
msno.matrix(raw_data)
整體來看�����,處理house_price存在缺失值�,這是因為這部分樓盤是預售狀態(tài),暫未公布售價����。
5、house_type
再仔細分析����,house_price有兩種形式
除了預售缺失值外,有單價和總價兩種��,為方便統(tǒng)計����,需將總價除以面積,將價格統(tǒng)一為單均價���。因此需要對戶型house_type進行處理���,如下:
def deal_house_type(data):
res = []
if data is np.nan:
return [np.nan, np.nan, np.nan]
else:
if '-'in data:
types = data.split('-')[0]
areas = data.split('-')[1]
area = areas.split('~')
if len(area) == 1:
min_area = areas.split('~')[0][0:-2]
max_area = areas.split('~')[0][0:-2]
else:
min_area = areas.split('~')[0]
max_area = areas.split('~')[1][0:-2]
res = [types, int(min_area), int(max_area)]
return res
else:
return [np.nan, np.nan, np.nan]
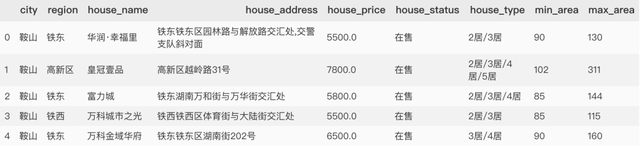
series_type = raw_data.house_type.map(lambda x: deal_house_type(x))
df_type = pd.DataFrame(series_type.to_dict(), index=['house_type', 'min_area', 'max_area']).T
data_type = pd.concat([data_copy.drop(labels='house_type',axis=1), df_type], axis=1)
data_type.head()
得到下表
6、house_price
得到戶型面積后��,接下來處理房屋價格��。
def deal_house_price(data):
try:
if data.house_price is np.nan:
return np.nan
else:
if "價格待定" in data.house_price:
return np.nan
elif "萬" not in data.house_price:
price = int(data.house_price.split('元')[0])
else:
price_total = int(float(data.house_price.split('萬')[0])* 10000)
if data.min_area is np.nan and data.max_area is np.nan:
return np.nan
elif data.min_area is np.nan:
price = price_total/ data.max_area
elif data.max_area is np.nan:
price = price_total / data.min_area
else:
price = price_total / (data.min_area + data.max_area)
return int(price)
except:
return np.nan
series_price = data_type.apply(lambda x:deal_house_price(x), axis=1 )
data_type['house_price'] = series_price
data_type.head()
得到結(jié)果
7、缺失值處理
data = data_type.copy()
# 房價缺失值用0填充 data['house_price'] = data_type.house_price.fillna(0) data['house_type'] = data_type.house_type.fillna('未知')
8��、異常值分析
data.describe([.1, .25, .5, .75, .99]).T
很明顯有個缺失值���,查看原網(wǎng)頁��,此數(shù)值因較特殊���,清洗過程中多乘100000����,因此直接將此值更改過來即可。
還可以通過可視化(箱圖)的方式查看異常值���。
from pyecharts import options as opts
from pyecharts.charts import Boxplot
v = [int(i) for i in data.house_price] c = Boxplot() c.add_xaxis(["house_price"]) c.add_yaxis("house_price", v) c.set_global_opts(title_opts=opts.TitleOpts(title="house_price")) c.render_notebook()
三��、可視化分析
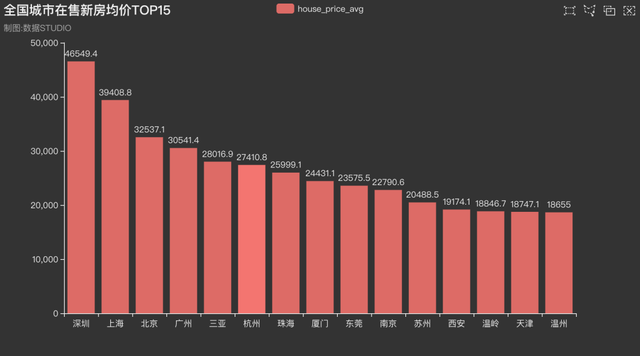
1����、全國城市在售新房均價TOP15
全國城市新房均價分析�����,房價是我們最關(guān)心的一個特征之一,因此看下全國均價最高的是哪幾個城市���。
data1 = data.query('house_price != 0')
data_pivot = data1.pivot_table(values='house_price',
index='city').sort_values(by='house_price',
ascending=False)
data_pivot
2�、全國城市在售新房均價條形圖
from pyecharts.charts import Bar
from pyecharts.globals import ThemeType
x_axis = [i for i in data_pivot.index[0:15]]
y_axis = [round(float(i), 1) for i in data_pivot.house_price.values[0:15]] c = (
Bar({"theme": ThemeType.DARK})
.add_xaxis(x_axis)
.add_yaxis("house_price_avg", y_axis)
.set_global_opts(
title_opts=opts.TitleOpts(title="全國城市在售新房均價TOP15", subtitle="數(shù)據(jù): STUDIO"),
brush_opts=opts.BrushOpts(),
)
) c.render_notebook()
結(jié)果如下�,排名前面的一直都是深圳、北京��、上海等一線城市��。
3���、全國房價地理位置圖
import pandas as pd from pyecharts.globals import ThemeType, CurrentConfig, GeoType from pyecharts import options as opts from pyecharts.charts import Geo datas = [(i, int(j)) for i, j in zip(data_pivot.index, data_pivot.values)] geo = (Geo(init_opts=opts.InitOpts(width='1000px',
height='600px',
theme=ThemeType.PURPLE_PASSION),
is_ignore_nonexistent_coord = True)
.add_schema(maptype='china',
label_opts=opts.LabelOpts(is_show=True)) .add('均價',
data_pair=datas,
type_=GeoType.EFFECT_SCATTER,
symbol_size=8,
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title='全國城市在售新房均價', subtitle="制圖: 數(shù)據(jù)STUDIO"),
visualmap_opts=opts.VisualMapOpts(max_=550,
is_piecewise=True,
pieces=[
{"max": 5000, "min": 1000, "label": "1000-5000", "color": "#708090"},
{"max": 10000, "min": 5001, "label": "5001-10000", "color": "#00FFFF"},
{"max": 20000, "min": 10001, "label": "10001-20000", "color": "#FF69B4"},
{"max": 30000, "min": 20001, "label": "20001-30000", "color": "#FFD700"},
{"max": 40000, "min": 30001, "label": "30001-40000", "color": "#FF0000"},
{"max": 100000, "min": 40001, "label": "40000-100000", "color": "#228B22"},])
)
)
geo.render('全國城市在售新房均價.html')
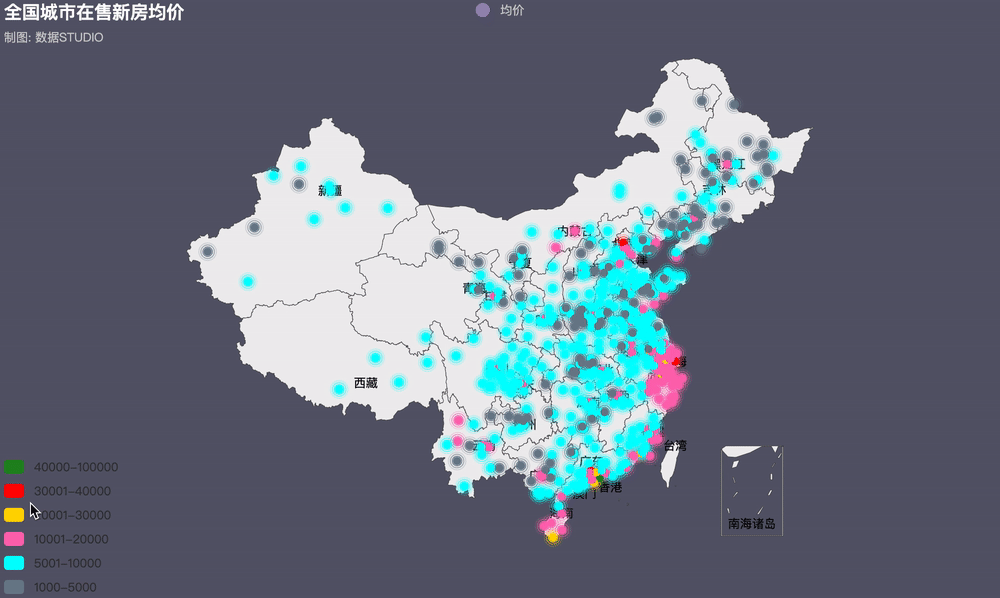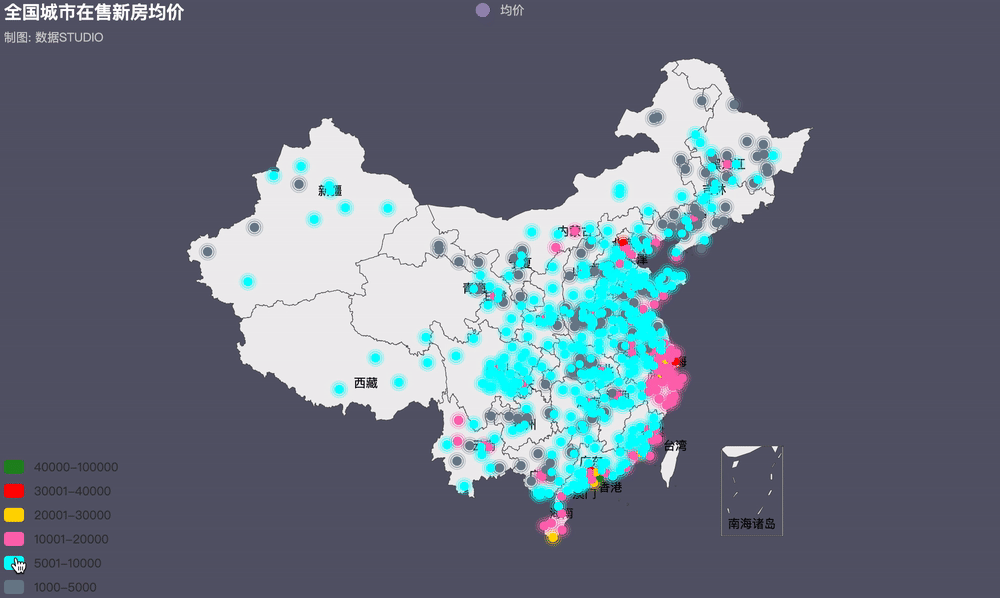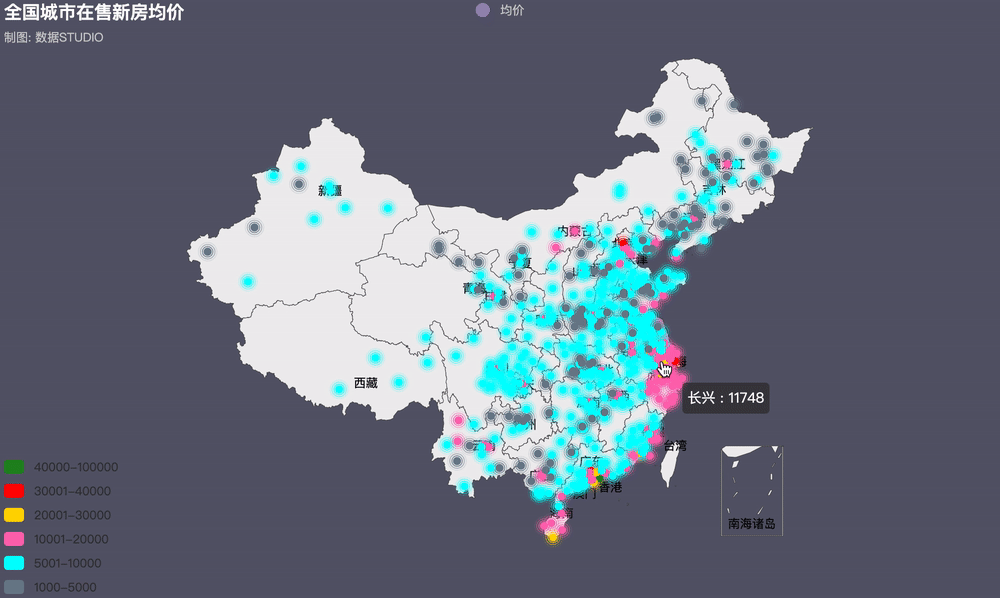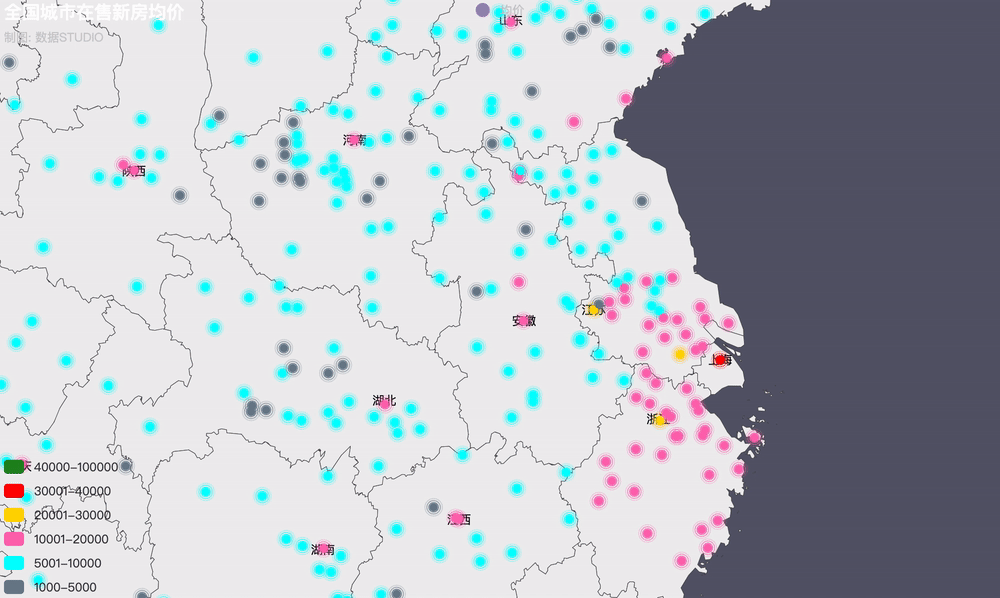
近年來��,火熱的樓市價格一路飆升���,為了穩(wěn)定房價,各地政府相繼出臺各項調(diào)控政策�。據(jù)統(tǒng)計,今年內(nèi)全國各地累計出臺樓市調(diào)控政策次數(shù)已高達97次(近100次)�,其中,1月份單月全國各地樓市調(diào)控政策次數(shù)高達42次����,2月份比1月份多3次�,共計45次�����。
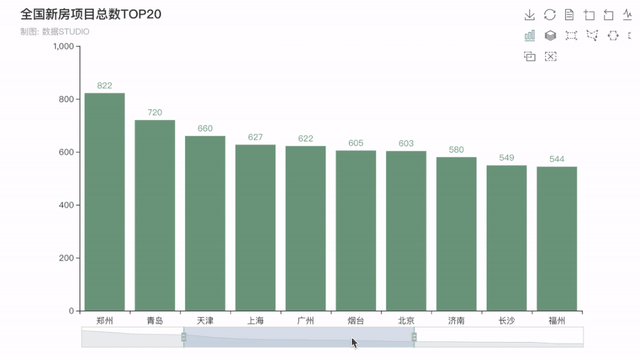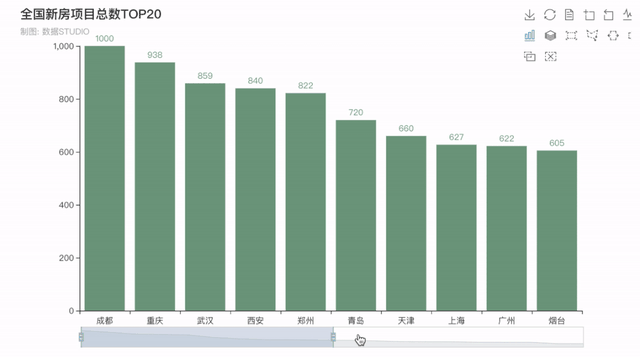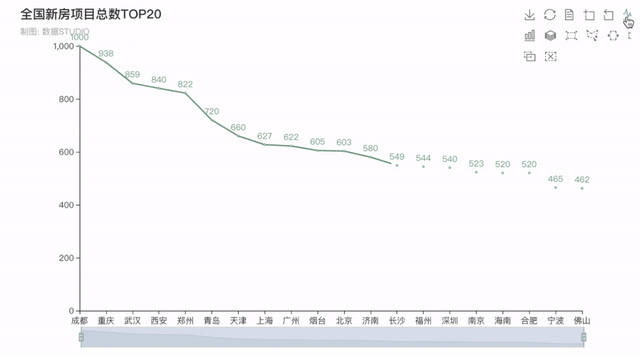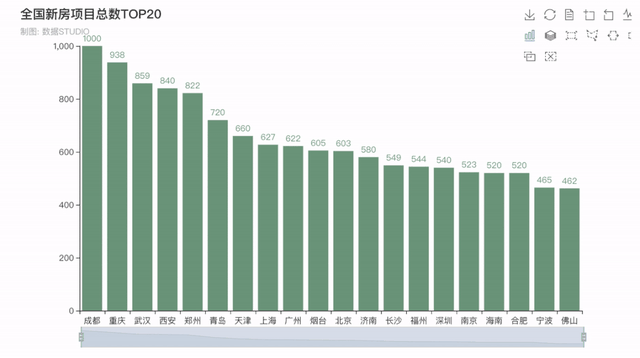
4�����、全國新房項目總數(shù)排行榜
接下來看看全國在售預售新房項目總數(shù)排行TOP20���,排在前五的分別是四川成都--1000個���,重慶--938個�,湖北武漢--859個,陜西西安--840個�����,河南鄭州--822個�����,均是新一線城市(成都��、杭州、重慶����、武漢、蘇州�、西安、天津�、南京、鄭州����、長沙、沈陽����、青島、寧波�、東莞和無錫)。
現(xiàn)在的新一線城市經(jīng)濟發(fā)展速度較快��,未來發(fā)展前景廣闊�����,可以說是僅次于北上廣深��。人口都在持續(xù)流入,人口流入將會增加對于房產(chǎn)的需求��,房產(chǎn)需求增長將會讓房產(chǎn)價格穩(wěn)步攀升�。也是很值得投資的。
from pyecharts import options as opts from pyecharts.charts import Bar
city_counts = data.city.value_counts()[0:20]
x_values = city_counts.index.to_list()
y_values = [int(i) for i in city_counts.values]
bar = (
Bar()
.add_xaxis(x_values)
.add_yaxis("",y_values,itemstyle_opts=opts.ItemStyleOpts(color="#749f83"))
.set_global_opts(title_opts=opts.TitleOpts(title="全國新房項目總數(shù)TOP20"),
toolbox_opts=opts.ToolboxOpts(),
legend_opts=opts.LegendOpts(is_show=False),
datazoom_opts=opts.DataZoomOpts(),)
)
bar.render_notebook()
結(jié)果
5��、城市各行政區(qū)在售新房均價
以在售/預售房產(chǎn)項目最多的成都為例����,看城市各行政區(qū)在售新房均價。
在"住房不炒"的大環(huán)境下���,各大城市限購政策越來越嚴格����。近日成都更是實行購房資格預審�����,熱點樓盤優(yōu)先向無房居民家庭銷售�,是我們這些剛需的一大福音��。接下來一起看看吧�。
成都各行政區(qū)在售新房均價
data2 = data.query('house_price != 0 and city=="成都"')
data_pivot_cd = data2.pivot_table(values='house_price',
index='region').sort_values(by='house_price')
x_axis2 = [i for i in data_pivot_cd.index[10:]]
y_axis2 = [round(float(i), 1) for i in data_pivot_cd.house_price.values[10:]]
c = (
Bar({"theme": ThemeType.DARK})
.add_xaxis(x_axis2)
.add_yaxis(
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情���;

















 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330