Kaggle是一個(gè)數(shù)據(jù)分析建模的應(yīng)用競賽平臺(tái)��,有點(diǎn)類似KDD-CUP(國際知識(shí)發(fā)現(xiàn)和數(shù)據(jù)挖掘競賽)�,企業(yè)或者研究者可以將問題背景、數(shù)據(jù)���、期望指標(biāo)等發(fā)布到Kaggle上���,以競賽的形式向廣大的數(shù)據(jù)科學(xué)家征集解決方案。而熱愛數(shù)(dong)據(jù)(shou)挖(zhe)掘(teng)的小伙伴們可以下載/分析數(shù)據(jù)��,使用統(tǒng)計(jì)/機(jī)器學(xué)習(xí)/數(shù)據(jù)挖掘等知識(shí)�,建立算法模型,得出結(jié)果并提交���,排名top的可能會(huì)有獎(jiǎng)金����!
01 關(guān)于泰坦尼克號(hào)之災(zāi)
· 帶大家去該問題頁面溜達(dá)一圈吧
· 下面是問題背景頁
 · 泰坦尼克號(hào)問題之背景
· 就是那個(gè)大家都熟悉的『Jack and Rose』的故事�,豪華游艇倒了,大家都驚恐逃生�����,可是救生艇的數(shù)量有限����,無法人人都有,副船長發(fā)話了『lady and kid first��!』�����,所以是否獲救其實(shí)并非隨機(jī)��,而是基于一些背景有rank先后的�。
· 訓(xùn)練和測試數(shù)據(jù)是一些乘客的個(gè)人信息以及存活狀況,要嘗試根據(jù)它生成合適的模型并預(yù)測其他人的存活狀況���。
· 對(duì)�,這是一個(gè)二分類問題����,是我們之前討論的logistic regression所能處理的范疇。
02 說明
接觸過Kaggle的同學(xué)們可能知道這個(gè)問題�,也可能知道RandomForest和SVM等等算法,甚至還對(duì)多個(gè)模型做過融合,取得過非常好的結(jié)果�,那maybe這篇文章并不是針對(duì)你的,你可以自行略過�。
我們因?yàn)橹爸唤榻B了Logistic Regression這一種分類算法。所以本次的問題解決過程和優(yōu)化思路�����,都集中在這種算法上�����。
03 初探數(shù)據(jù)
先看看我們的數(shù)據(jù)����,長什么樣吧。在Data下我們train.csv和test.csv兩個(gè)文件�����,分別存著官方給的訓(xùn)練和測試數(shù)據(jù)�。
import pandas as pd #數(shù)據(jù)分析
import numpy as np #科學(xué)計(jì)算
from pandas import Series,DataFrame
data_train = pd.read_csv("/Users/Hanxiaoyang/Titanic_data/Train.csv")
data_train
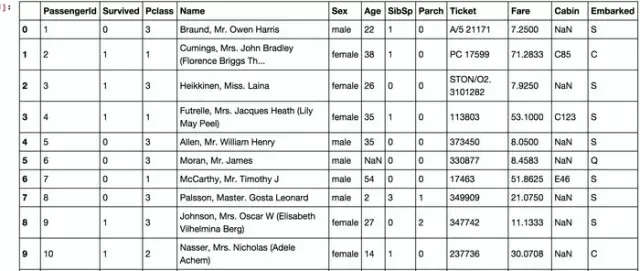
pandas是常用的python數(shù)據(jù)處理包,把csv文件讀入成dataframe各式�����,我們在ipython notebook中,看到data_train如下所示:
· 泰坦尼克號(hào)問題之背景
· 就是那個(gè)大家都熟悉的『Jack and Rose』的故事�,豪華游艇倒了,大家都驚恐逃生�����,可是救生艇的數(shù)量有限����,無法人人都有,副船長發(fā)話了『lady and kid first��!』�����,所以是否獲救其實(shí)并非隨機(jī)��,而是基于一些背景有rank先后的�。
· 訓(xùn)練和測試數(shù)據(jù)是一些乘客的個(gè)人信息以及存活狀況,要嘗試根據(jù)它生成合適的模型并預(yù)測其他人的存活狀況���。
· 對(duì)�,這是一個(gè)二分類問題����,是我們之前討論的logistic regression所能處理的范疇。
02 說明
接觸過Kaggle的同學(xué)們可能知道這個(gè)問題�,也可能知道RandomForest和SVM等等算法,甚至還對(duì)多個(gè)模型做過融合,取得過非常好的結(jié)果�,那maybe這篇文章并不是針對(duì)你的,你可以自行略過�。
我們因?yàn)橹爸唤榻B了Logistic Regression這一種分類算法。所以本次的問題解決過程和優(yōu)化思路�����,都集中在這種算法上�����。
03 初探數(shù)據(jù)
先看看我們的數(shù)據(jù)����,長什么樣吧。在Data下我們train.csv和test.csv兩個(gè)文件�����,分別存著官方給的訓(xùn)練和測試數(shù)據(jù)�。
import pandas as pd #數(shù)據(jù)分析
import numpy as np #科學(xué)計(jì)算
from pandas import Series,DataFrame
data_train = pd.read_csv("/Users/Hanxiaoyang/Titanic_data/Train.csv")
data_train
pandas是常用的python數(shù)據(jù)處理包,把csv文件讀入成dataframe各式�����,我們在ipython notebook中,看到data_train如下所示:
 這就是典型的dataframe格式���,如果你沒接觸過這種格式��,完全沒有關(guān)系,你就把它想象成Excel里面的列好了�����。
我們看到�����,總共有12列����,其中Survived字段表示的是該乘客是否獲救,其余都是乘客的個(gè)人信息����,包括:
· PassengerId => 乘客ID
· Pclass => 乘客等級(jí)(1/2/3等艙位)
· Name => 乘客姓名
· Sex => 性別
· Age => 年齡
· SibSp => 堂兄弟/妹個(gè)數(shù)
· Parch => 父母與小孩個(gè)數(shù)
· Ticket => 船票信息
· Fare => 票價(jià)
· Cabin => 客艙
· Embarked => 登船港口
逐條往下看,要看完這么多條����,眼睛都有一種要瞎的趕腳。好吧,我們讓dataframe自己告訴我們一些信息���,如下所示:
data_train.info()
看到了如下的信息:
這就是典型的dataframe格式���,如果你沒接觸過這種格式��,完全沒有關(guān)系,你就把它想象成Excel里面的列好了�����。
我們看到�����,總共有12列����,其中Survived字段表示的是該乘客是否獲救,其余都是乘客的個(gè)人信息����,包括:
· PassengerId => 乘客ID
· Pclass => 乘客等級(jí)(1/2/3等艙位)
· Name => 乘客姓名
· Sex => 性別
· Age => 年齡
· SibSp => 堂兄弟/妹個(gè)數(shù)
· Parch => 父母與小孩個(gè)數(shù)
· Ticket => 船票信息
· Fare => 票價(jià)
· Cabin => 客艙
· Embarked => 登船港口
逐條往下看,要看完這么多條����,眼睛都有一種要瞎的趕腳。好吧,我們讓dataframe自己告訴我們一些信息���,如下所示:
data_train.info()
看到了如下的信息:
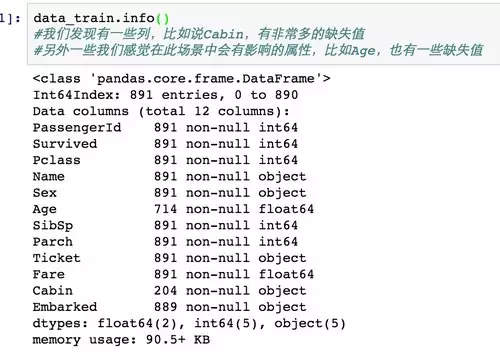 上面的數(shù)據(jù)說啥了��?它告訴我們����,訓(xùn)練數(shù)據(jù)中總共有891名乘客���,但是很不幸�����,我們有些屬性的數(shù)據(jù)不全�,比如說:
· Age(年齡)屬性只有714名乘客有記錄
· Cabin(客艙)更是只有204名乘客是已知的
似乎信息略少啊�,想再瞄一眼具體數(shù)據(jù)數(shù)值情況呢?恩����,我們用下列的方法,得到數(shù)值型數(shù)據(jù)的一些分布(因?yàn)橛行傩?��,比如姓名���,是文本型����;而另外一些屬性��,比如登船港口���,是類目型。這些我們用下面的函數(shù)是看不到的):
上面的數(shù)據(jù)說啥了��?它告訴我們����,訓(xùn)練數(shù)據(jù)中總共有891名乘客���,但是很不幸�����,我們有些屬性的數(shù)據(jù)不全�,比如說:
· Age(年齡)屬性只有714名乘客有記錄
· Cabin(客艙)更是只有204名乘客是已知的
似乎信息略少啊�,想再瞄一眼具體數(shù)據(jù)數(shù)值情況呢?恩����,我們用下列的方法,得到數(shù)值型數(shù)據(jù)的一些分布(因?yàn)橛行傩?��,比如姓名���,是文本型����;而另外一些屬性��,比如登船港口���,是類目型。這些我們用下面的函數(shù)是看不到的):
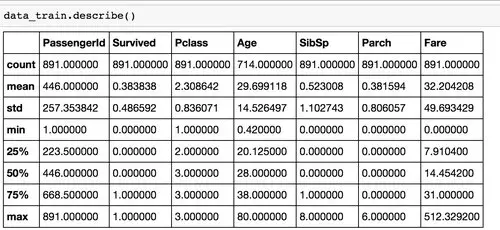 我們從上面看到更進(jìn)一步的什么信息呢�?
mean字段告訴我們,大概0.383838的人最后獲救了��,2/3等艙的人數(shù)比1等艙要多�,平均乘客年齡大概是29.7歲(計(jì)算這個(gè)時(shí)候會(huì)略掉無記錄的)等等…
04 數(shù)據(jù)初步分析
每個(gè)乘客都這么多屬性,那我們咋知道哪些屬性更有用���,而又應(yīng)該怎么用它們?��。績H僅最上面的對(duì)數(shù)據(jù)了解�����,依舊無法給我們提供想法和思路。我們再深入一點(diǎn)來看看我們的數(shù)據(jù)����,看看每個(gè)/多個(gè) 屬性和最后的Survived之間有著什么樣的關(guān)系呢。
4.1 乘客各屬性分布
腦容量太有限了…數(shù)值看花眼了���。我們還是統(tǒng)計(jì)統(tǒng)計(jì)�,畫些圖來看看屬性和結(jié)果之間的關(guān)系好了�,代碼如下:
import matplotlib.pyplot as plt
fig = plt.figure()
fig.set(alpha=0.2) # 設(shè)定圖表顏色alpha參數(shù)plt.subplot2grid((2,3),(0,0)) # 在一張大圖里分列幾個(gè)小圖data_train.Survived.value_counts().plot(kind='bar')# 柱狀圖 plt.title(u"獲救情況 (1為獲救)") # 標(biāo)題plt.ylabel(u"人數(shù)")
plt.subplot2grid((2,3),(0,1))
data_train.Pclass.value_counts().plot(kind="bar")
plt.ylabel(u"人數(shù)")
plt.title(u"乘客等級(jí)分布")
plt.subplot2grid((2,3),(0,2))
plt.scatter(data_train.Survived, data_train.Age)
plt.ylabel(u"年齡") # 設(shè)定縱坐標(biāo)名稱plt.grid(b=True, which='major', axis='y')
plt.title(u"按年齡看獲救分布 (1為獲救)")
plt.subplot2grid((2,3),(1,0), colspan=2)
data_train.Age[data_train.Pclass == 1].plot(kind='kde')
data_train.Age[data_train.Pclass == 2].plot(kind='kde')
data_train.Age[data_train.Pclass == 3].plot(kind='kde')
plt.xlabel(u"年齡")# plots an axis lableplt.ylabel(u"密度")
plt.title(u"各等級(jí)的乘客年齡分布")
plt.legend((u'頭等艙', u'2等艙',u'3等艙'),loc='best') # sets our legend for our graph.plt.subplot2grid((2,3),(1,2))
data_train.Embarked.value_counts().plot(kind='bar')
plt.title(u"各登船口岸上船人數(shù)")
plt.ylabel(u"人數(shù)")
plt.show()
我們從上面看到更進(jìn)一步的什么信息呢�?
mean字段告訴我們,大概0.383838的人最后獲救了��,2/3等艙的人數(shù)比1等艙要多�,平均乘客年齡大概是29.7歲(計(jì)算這個(gè)時(shí)候會(huì)略掉無記錄的)等等…
04 數(shù)據(jù)初步分析
每個(gè)乘客都這么多屬性,那我們咋知道哪些屬性更有用���,而又應(yīng)該怎么用它們?��。績H僅最上面的對(duì)數(shù)據(jù)了解�����,依舊無法給我們提供想法和思路。我們再深入一點(diǎn)來看看我們的數(shù)據(jù)����,看看每個(gè)/多個(gè) 屬性和最后的Survived之間有著什么樣的關(guān)系呢。
4.1 乘客各屬性分布
腦容量太有限了…數(shù)值看花眼了���。我們還是統(tǒng)計(jì)統(tǒng)計(jì)�,畫些圖來看看屬性和結(jié)果之間的關(guān)系好了�,代碼如下:
import matplotlib.pyplot as plt
fig = plt.figure()
fig.set(alpha=0.2) # 設(shè)定圖表顏色alpha參數(shù)plt.subplot2grid((2,3),(0,0)) # 在一張大圖里分列幾個(gè)小圖data_train.Survived.value_counts().plot(kind='bar')# 柱狀圖 plt.title(u"獲救情況 (1為獲救)") # 標(biāo)題plt.ylabel(u"人數(shù)")
plt.subplot2grid((2,3),(0,1))
data_train.Pclass.value_counts().plot(kind="bar")
plt.ylabel(u"人數(shù)")
plt.title(u"乘客等級(jí)分布")
plt.subplot2grid((2,3),(0,2))
plt.scatter(data_train.Survived, data_train.Age)
plt.ylabel(u"年齡") # 設(shè)定縱坐標(biāo)名稱plt.grid(b=True, which='major', axis='y')
plt.title(u"按年齡看獲救分布 (1為獲救)")
plt.subplot2grid((2,3),(1,0), colspan=2)
data_train.Age[data_train.Pclass == 1].plot(kind='kde')
data_train.Age[data_train.Pclass == 2].plot(kind='kde')
data_train.Age[data_train.Pclass == 3].plot(kind='kde')
plt.xlabel(u"年齡")# plots an axis lableplt.ylabel(u"密度")
plt.title(u"各等級(jí)的乘客年齡分布")
plt.legend((u'頭等艙', u'2等艙',u'3等艙'),loc='best') # sets our legend for our graph.plt.subplot2grid((2,3),(1,2))
data_train.Embarked.value_counts().plot(kind='bar')
plt.title(u"各登船口岸上船人數(shù)")
plt.ylabel(u"人數(shù)")
plt.show()
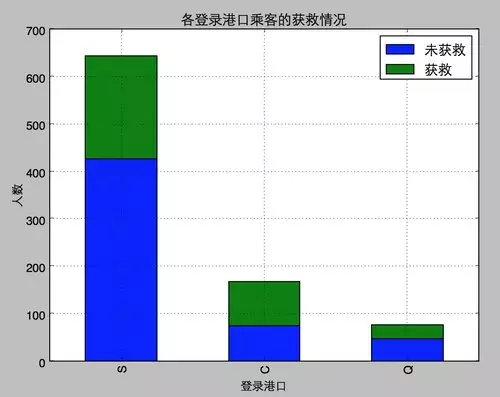
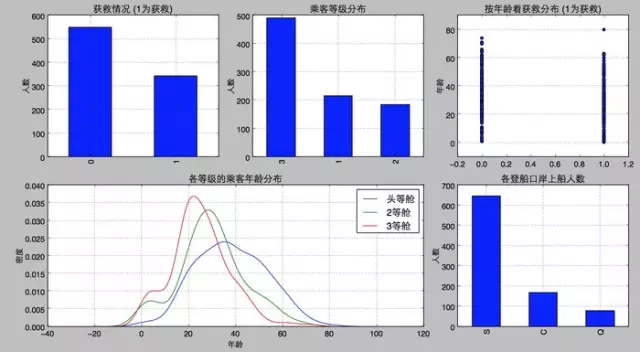 bingo,圖還是比數(shù)字好看多了���。所以我們在圖上可以看出來����,被救的人300多點(diǎn)��,不到半數(shù)���;3等艙乘客灰常多��;遇難和獲救的人年齡似乎跨度都很廣�����;3個(gè)不同的艙年齡總體趨勢似乎也一致��,2/3等艙乘客20歲多點(diǎn)的人最多��,1等艙40歲左右的最多(→_→似乎符合財(cái)富和年齡的分配哈���,咳咳��,別理我��,我瞎扯的)�����;登船港口人數(shù)按照S、C�����、Q遞減��,而且S遠(yuǎn)多于另外倆港口����。
這個(gè)時(shí)候我們可能會(huì)有一些想法了:
· 不同艙位/乘客等級(jí)可能和財(cái)富/地位有關(guān)系��,最后獲救概率可能會(huì)不一樣
bingo,圖還是比數(shù)字好看多了���。所以我們在圖上可以看出來����,被救的人300多點(diǎn)��,不到半數(shù)���;3等艙乘客灰常多��;遇難和獲救的人年齡似乎跨度都很廣�����;3個(gè)不同的艙年齡總體趨勢似乎也一致��,2/3等艙乘客20歲多點(diǎn)的人最多��,1等艙40歲左右的最多(→_→似乎符合財(cái)富和年齡的分配哈���,咳咳��,別理我��,我瞎扯的)�����;登船港口人數(shù)按照S、C�����、Q遞減��,而且S遠(yuǎn)多于另外倆港口����。
這個(gè)時(shí)候我們可能會(huì)有一些想法了:
· 不同艙位/乘客等級(jí)可能和財(cái)富/地位有關(guān)系��,最后獲救概率可能會(huì)不一樣
· 年齡對(duì)獲救概率也一定是有影響的�,畢竟前面說了���,副船長還說『小孩和女士先走』呢
· 和登船港口是不是有關(guān)系呢���?也許登船港口不同,人的出身地位不同����?
口說無憑,空想無益����。老老實(shí)實(shí)再來統(tǒng)計(jì)統(tǒng)計(jì),看看這些屬性值的統(tǒng)計(jì)分布吧��。
4.2 屬性與獲救結(jié)果的關(guān)聯(lián)統(tǒng)計(jì)
#看看各乘客等級(jí)的獲救情況fig = plt.figure()
fig.set(alpha=0.2) # 設(shè)定圖表顏色alpha參數(shù)Survived_0 = data_train.Pclass[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Pclass[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'獲救':Survived_1, u'未獲救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各乘客等級(jí)的獲救情況")
plt.xlabel(u"乘客等級(jí)")
plt.ylabel(u"人數(shù)")
plt.show()
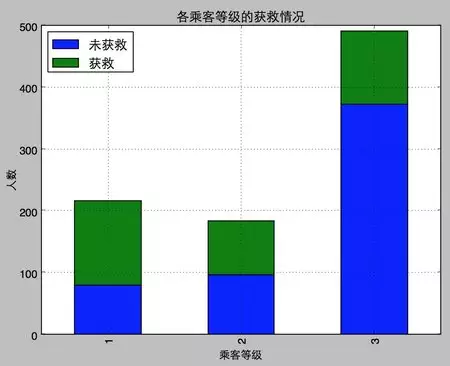 嘖嘖����,果然,錢和地位對(duì)艙位有影響���,進(jìn)而對(duì)獲救的可能性也有影響啊←_←
咳咳���,跑題了�,我想說的是�����,明顯等級(jí)為1的乘客��,獲救的概率高很多��。恩�,這個(gè)一定是影響最后獲救結(jié)果的一個(gè)特征。
#看看各性別的獲救情況fig = plt.figure()
fig.set(alpha=0.2) # 設(shè)定圖表顏色alpha參數(shù)Survived_m = data_train.Survived[data_train.Sex == 'male'].value_counts()
Survived_f = data_train.Survived[data_train.Sex == 'female'].value_counts()
df=pd.DataFrame({u'男性':Survived_m, u'女性':Survived_f})
df.plot(kind='bar', stacked=True)
plt.title(u"按性別看獲救情況")
plt.xlabel(u"性別")
plt.ylabel(u"人數(shù)")
plt.show()
嘖嘖����,果然,錢和地位對(duì)艙位有影響���,進(jìn)而對(duì)獲救的可能性也有影響啊←_←
咳咳���,跑題了�,我想說的是�����,明顯等級(jí)為1的乘客��,獲救的概率高很多��。恩�,這個(gè)一定是影響最后獲救結(jié)果的一個(gè)特征。
#看看各性別的獲救情況fig = plt.figure()
fig.set(alpha=0.2) # 設(shè)定圖表顏色alpha參數(shù)Survived_m = data_train.Survived[data_train.Sex == 'male'].value_counts()
Survived_f = data_train.Survived[data_train.Sex == 'female'].value_counts()
df=pd.DataFrame({u'男性':Survived_m, u'女性':Survived_f})
df.plot(kind='bar', stacked=True)
plt.title(u"按性別看獲救情況")
plt.xlabel(u"性別")
plt.ylabel(u"人數(shù)")
plt.show()
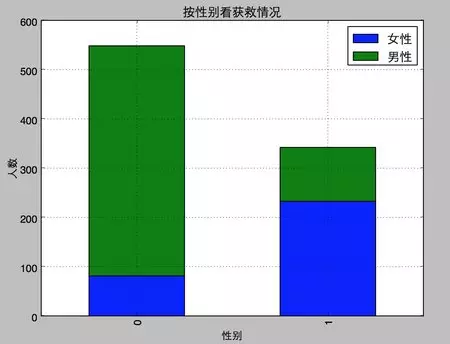 歪果盆友果然很尊重lady�����,lady first踐行得不錯(cuò)���。性別無疑也要作為重要特征加入最后的模型之中。
歪果盆友果然很尊重lady�����,lady first踐行得不錯(cuò)���。性別無疑也要作為重要特征加入最后的模型之中。
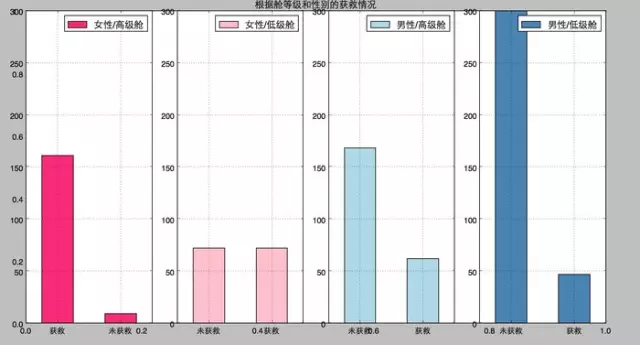 恩��,堅(jiān)定了之前的判斷����。
我們看看各登船港口的獲救情況�。
恩��,堅(jiān)定了之前的判斷����。
我們看看各登船港口的獲救情況�。
 下面我們來看看 堂兄弟/妹����,孩子/父母有幾人,對(duì)是否獲救的影響��。
下面我們來看看 堂兄弟/妹����,孩子/父母有幾人,對(duì)是否獲救的影響��。
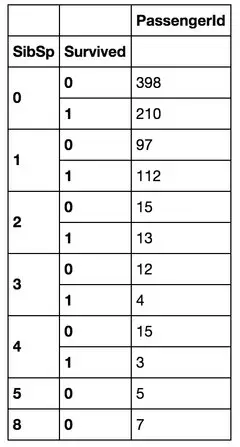
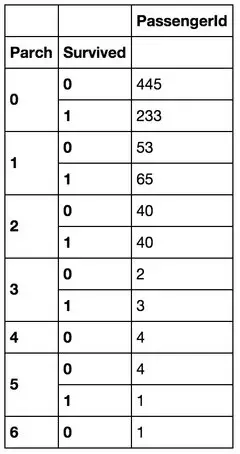
好吧�����,沒看出特別特別明顯的規(guī)律(為自己的智商感到捉急…)��,先作為備選特征����,放一放。
部分結(jié)果如下:
 這三三兩兩的…如此不集中…我們猜一下�,也許,前面的ABCDE是指的甲板位置���、然后編號(hào)是房間號(hào)����?…好吧,我瞎說的�,別當(dāng)真…
關(guān)鍵是Cabin這鬼屬性,應(yīng)該算作類目型的����,本來缺失值就多,還如此不集中��,注定是個(gè)棘手貨…第一感覺���,這玩意兒如果直接按照類目特征處理的話��,太散了���,估計(jì)每個(gè)因子化后的特征都拿不到什么權(quán)重。加上有那么多缺失值�,要不我們先把Cabin缺失與否作為條件(雖然這部分信息缺失可能并非未登記,maybe只是丟失了而已����,所以這樣做未必妥當(dāng)),先在有無Cabin信息這個(gè)粗粒度上看看Survived的情況好了�����。
這三三兩兩的…如此不集中…我們猜一下�,也許,前面的ABCDE是指的甲板位置���、然后編號(hào)是房間號(hào)����?…好吧,我瞎說的�,別當(dāng)真…
關(guān)鍵是Cabin這鬼屬性,應(yīng)該算作類目型的����,本來缺失值就多,還如此不集中��,注定是個(gè)棘手貨…第一感覺���,這玩意兒如果直接按照類目特征處理的話��,太散了���,估計(jì)每個(gè)因子化后的特征都拿不到什么權(quán)重。加上有那么多缺失值�,要不我們先把Cabin缺失與否作為條件(雖然這部分信息缺失可能并非未登記,maybe只是丟失了而已����,所以這樣做未必妥當(dāng)),先在有無Cabin信息這個(gè)粗粒度上看看Survived的情況好了�����。
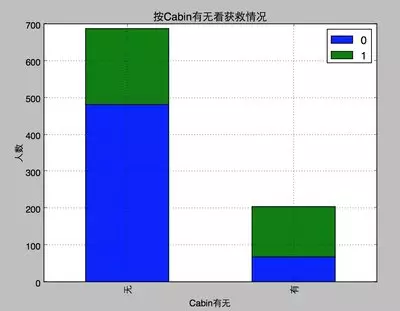 咳咳�,有Cabin記錄的似乎獲救概率稍高一些,先這么著放一放吧�。
05 簡單數(shù)據(jù)預(yù)處理
大體數(shù)據(jù)的情況看了一遍,對(duì)感興趣的屬性也有個(gè)大概的了解了���。
下一步干啥���?咱們該處理處理這些數(shù)據(jù),為機(jī)器學(xué)習(xí)建模做點(diǎn)準(zhǔn)備了��。
對(duì)了���,我這里說的數(shù)據(jù)預(yù)處理����,其實(shí)就包括了很多Kaggler津津樂道的feature engineering過程��,灰?�;页S斜匾?��!
先從最突出的數(shù)據(jù)屬性開始吧���,對(duì)���,Cabin和Age,有丟失數(shù)據(jù)實(shí)在是對(duì)下一步工作影響太大����。
先說Cabin,暫時(shí)我們就按照剛才說的��,按Cabin有無數(shù)據(jù)�����,將這個(gè)屬性處理成Yes和No兩種類型吧�����。
再說Age:
通常遇到缺值的情況���,我們會(huì)有幾種常見的處理方式
· 如果缺值的樣本占總數(shù)比例極高���,我們可能就直接舍棄了,作為特征加入的話����,可能反倒帶入noise,影響最后的結(jié)果了
· 如果缺值的樣本適中����,而該屬性非連續(xù)值特征屬性(比如說類目屬性),那就把NaN作為一個(gè)新類別����,加到類別特征中
· 如果缺值的樣本適中,而該屬性為連續(xù)值特征屬性��,有時(shí)候我們會(huì)考慮給定一個(gè)step(比如這里的age�,我們可以考慮每隔2/3歲為一個(gè)步長),然后把它離散化����,之后把NaN作為一個(gè)type加到屬性類目中。
· 有些情況下�,缺失的值個(gè)數(shù)并不是特別多,那我們也可以試著根據(jù)已有的值��,擬合一下數(shù)據(jù)�����,補(bǔ)充上。
本例中�����,后兩種處理方式應(yīng)該都是可行的��,我們先試試擬合補(bǔ)全吧(雖然說沒有特別多的背景可供我們擬合���,這不一定是一個(gè)多么好的選擇)
我們這里用scikit-learn中的RandomForest來擬合一下缺失的年齡數(shù)據(jù)(注:RandomForest是一個(gè)用在原始數(shù)據(jù)中做不同采樣���,建立多顆DecisionTree,再進(jìn)行average等等來降低過擬合現(xiàn)象��,提高結(jié)果的機(jī)器學(xué)習(xí)算法����,我們之后會(huì)介紹到)
咳咳�,有Cabin記錄的似乎獲救概率稍高一些,先這么著放一放吧�。
05 簡單數(shù)據(jù)預(yù)處理
大體數(shù)據(jù)的情況看了一遍,對(duì)感興趣的屬性也有個(gè)大概的了解了���。
下一步干啥���?咱們該處理處理這些數(shù)據(jù),為機(jī)器學(xué)習(xí)建模做點(diǎn)準(zhǔn)備了��。
對(duì)了���,我這里說的數(shù)據(jù)預(yù)處理����,其實(shí)就包括了很多Kaggler津津樂道的feature engineering過程��,灰?�;页S斜匾?��!
先從最突出的數(shù)據(jù)屬性開始吧���,對(duì)���,Cabin和Age,有丟失數(shù)據(jù)實(shí)在是對(duì)下一步工作影響太大����。
先說Cabin,暫時(shí)我們就按照剛才說的��,按Cabin有無數(shù)據(jù)�����,將這個(gè)屬性處理成Yes和No兩種類型吧�����。
再說Age:
通常遇到缺值的情況���,我們會(huì)有幾種常見的處理方式
· 如果缺值的樣本占總數(shù)比例極高���,我們可能就直接舍棄了,作為特征加入的話����,可能反倒帶入noise,影響最后的結(jié)果了
· 如果缺值的樣本適中����,而該屬性非連續(xù)值特征屬性(比如說類目屬性),那就把NaN作為一個(gè)新類別����,加到類別特征中
· 如果缺值的樣本適中,而該屬性為連續(xù)值特征屬性��,有時(shí)候我們會(huì)考慮給定一個(gè)step(比如這里的age�,我們可以考慮每隔2/3歲為一個(gè)步長),然后把它離散化����,之后把NaN作為一個(gè)type加到屬性類目中。
· 有些情況下�,缺失的值個(gè)數(shù)并不是特別多,那我們也可以試著根據(jù)已有的值��,擬合一下數(shù)據(jù)�����,補(bǔ)充上。
本例中�����,后兩種處理方式應(yīng)該都是可行的��,我們先試試擬合補(bǔ)全吧(雖然說沒有特別多的背景可供我們擬合���,這不一定是一個(gè)多么好的選擇)
我們這里用scikit-learn中的RandomForest來擬合一下缺失的年齡數(shù)據(jù)(注:RandomForest是一個(gè)用在原始數(shù)據(jù)中做不同采樣���,建立多顆DecisionTree,再進(jìn)行average等等來降低過擬合現(xiàn)象��,提高結(jié)果的機(jī)器學(xué)習(xí)算法����,我們之后會(huì)介紹到)
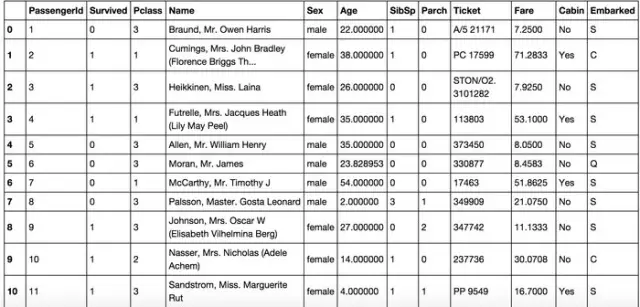 恩。目的達(dá)到�,OK了。
因?yàn)?a href='/map/luojihuigui/' style='color:#000;font-size:inherit;'>邏輯回歸建模時(shí)���,需要輸入的特征都是數(shù)值型特征����,我們通常會(huì)先對(duì)類目型的特征因子化。
什么叫做因子化呢�����?舉個(gè)例子:
以Cabin為例���,原本一個(gè)屬性維度,因?yàn)槠淙≈悼梢允荹‘yes’,’no’]�,而將其平展開為’Cabin_yes’,’Cabin_no’兩個(gè)屬性
原本Cabin取值為yes的,在此處的”Cabin_yes”下取值為1����,在”Cabin_no”下取值為0
原本Cabin取值為no的,在此處的”Cabin_yes”下取值為0��,在”Cabin_no”下取值為1
我們使用pandas的”get_dummies”來完成這個(gè)工作��,并拼接在原來的”data_train”之上��,如下所示�。
恩。目的達(dá)到�,OK了。
因?yàn)?a href='/map/luojihuigui/' style='color:#000;font-size:inherit;'>邏輯回歸建模時(shí)���,需要輸入的特征都是數(shù)值型特征����,我們通常會(huì)先對(duì)類目型的特征因子化。
什么叫做因子化呢�����?舉個(gè)例子:
以Cabin為例���,原本一個(gè)屬性維度,因?yàn)槠淙≈悼梢允荹‘yes’,’no’]�,而將其平展開為’Cabin_yes’,’Cabin_no’兩個(gè)屬性
原本Cabin取值為yes的,在此處的”Cabin_yes”下取值為1����,在”Cabin_no”下取值為0
原本Cabin取值為no的,在此處的”Cabin_yes”下取值為0��,在”Cabin_no”下取值為1
我們使用pandas的”get_dummies”來完成這個(gè)工作��,并拼接在原來的”data_train”之上��,如下所示�。
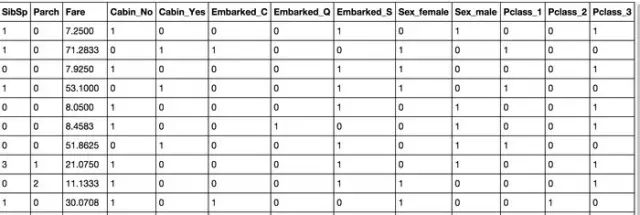 bingo,我們很成功地把這些類目屬性全都轉(zhuǎn)成0�,1的數(shù)值屬性了。
這樣���,看起來���,是不是我們需要的屬性值都有了��,且它們都是數(shù)值型屬性呢�����。
有一種臨近結(jié)果的寵寵欲動(dòng)感吧��,莫急莫急����,我們還得做一些處理����,仔細(xì)看看Age和Fare兩個(gè)屬性�,乘客的數(shù)值幅度變化,也忒大了吧?���?!如果大家了解邏輯回歸與梯度下降的話,會(huì)知道�����,各屬性值之間scale差距太大�,將對(duì)收斂速度造成幾萬點(diǎn)傷害值!甚至不收斂����! (╬▔皿▔)…所以我們先用scikit-learn里面的preprocessing模塊對(duì)這倆貨做一個(gè)scaling,所謂scaling�����,其實(shí)就是將一些變化幅度較大的特征化到[-1,1]之內(nèi)�����。
bingo,我們很成功地把這些類目屬性全都轉(zhuǎn)成0�,1的數(shù)值屬性了。
這樣���,看起來���,是不是我們需要的屬性值都有了��,且它們都是數(shù)值型屬性呢�����。
有一種臨近結(jié)果的寵寵欲動(dòng)感吧��,莫急莫急����,我們還得做一些處理����,仔細(xì)看看Age和Fare兩個(gè)屬性�,乘客的數(shù)值幅度變化,也忒大了吧?���?!如果大家了解邏輯回歸與梯度下降的話,會(huì)知道�����,各屬性值之間scale差距太大�,將對(duì)收斂速度造成幾萬點(diǎn)傷害值!甚至不收斂����! (╬▔皿▔)…所以我們先用scikit-learn里面的preprocessing模塊對(duì)這倆貨做一個(gè)scaling,所謂scaling�����,其實(shí)就是將一些變化幅度較大的特征化到[-1,1]之內(nèi)�����。
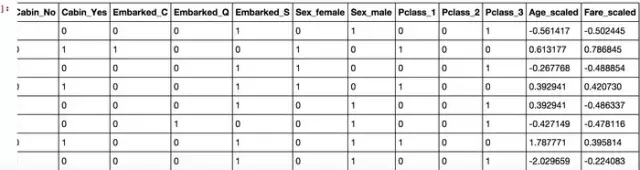 恩���,好看多了,萬事俱備���,只欠建模����。馬上就要看到成效了,哈哈���。我們把需要的屬性值抽出來�����,轉(zhuǎn)成scikit-learn里面LogisticRegression可以處理的格式���。
06 邏輯回歸建模
我們把需要的feature字段取出來,轉(zhuǎn)成numpy格式��,使用scikit-learn中的LogisticRegression建模����。
good,很順利���,我們得到了一個(gè)model��,如下:
恩���,好看多了,萬事俱備���,只欠建模����。馬上就要看到成效了,哈哈���。我們把需要的屬性值抽出來�����,轉(zhuǎn)成scikit-learn里面LogisticRegression可以處理的格式���。
06 邏輯回歸建模
我們把需要的feature字段取出來,轉(zhuǎn)成numpy格式��,使用scikit-learn中的LogisticRegression建模����。
good,很順利���,我們得到了一個(gè)model��,如下:
 先淡定����!淡定!你以為把test.csv直接丟進(jìn)model里就能拿到結(jié)果啊…騷年���,圖樣圖森破?�?!我們的”test_data”也要做和”train_data”一樣的預(yù)處理?����。�����?��!
先淡定����!淡定!你以為把test.csv直接丟進(jìn)model里就能拿到結(jié)果啊…騷年���,圖樣圖森破?�?!我們的”test_data”也要做和”train_data”一樣的預(yù)處理?����。�����?��!
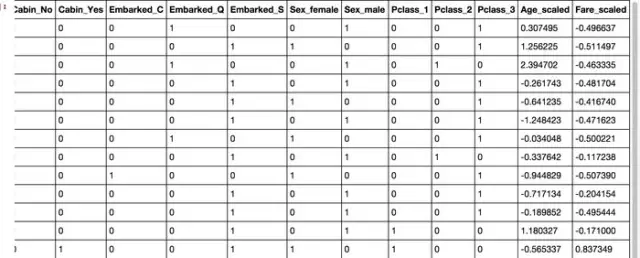 不錯(cuò)不錯(cuò),數(shù)據(jù)很OK���,差最后一步了��。
下面就做預(yù)測取結(jié)果吧??�!
不錯(cuò)不錯(cuò),數(shù)據(jù)很OK���,差最后一步了��。
下面就做預(yù)測取結(jié)果吧??�!
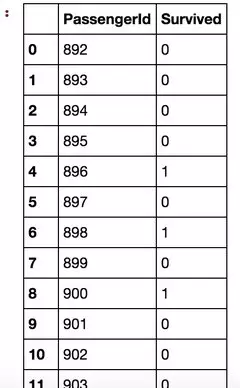 嘖嘖,挺好��,格式正確�,去make a submission啦啦啦!
在Kaggle的Make a submission頁面�,提交上結(jié)果。如下:
嘖嘖,挺好��,格式正確�,去make a submission啦啦啦!
在Kaggle的Make a submission頁面�,提交上結(jié)果。如下:
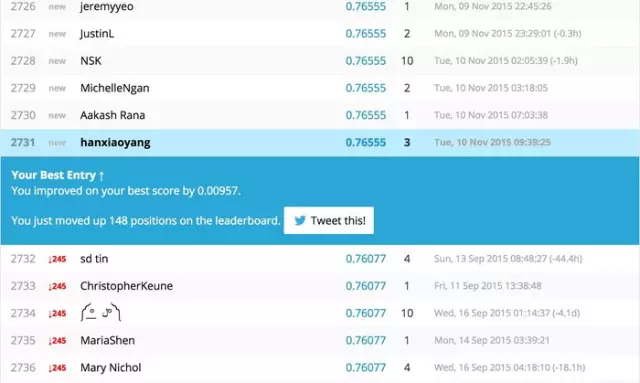 0.76555�����,恩�,結(jié)果還不錯(cuò)。畢竟��,這只是我們簡單分析處理過后出的一個(gè)baseline模型嘛��。
07 邏輯回歸系統(tǒng)優(yōu)化
7.1 模型系數(shù)關(guān)聯(lián)分析
親�����,你以為結(jié)果提交上了����,就完事了?
我不會(huì)告訴你���,這只是萬里長征第一步啊(淚牛滿面)?���。?���!這才剛擼完baseline model啊?����。����。∵€得優(yōu)化?����。��。���?!
看過Andrew Ng老師的machine Learning課程的同學(xué)們���,知道�,我們應(yīng)該分析分析模型現(xiàn)在的狀態(tài)了��,是過/欠擬合��?�,以確定我們需要更多的特征還是更多數(shù)據(jù),或者其他操作��。我們有一條很著名的learning curves對(duì)吧��。
不過在現(xiàn)在的場景下���,先不著急做這個(gè)事情���,我們這個(gè)baseline系統(tǒng)還有些粗糙,先再挖掘挖掘�����。
首先�����,Name和Ticket兩個(gè)屬性被我們完整舍棄了(好吧,其實(shí)是因?yàn)檫@倆屬性�,幾乎每一條記錄都是一個(gè)完全不同的值,我們并沒有找到很直接的處理方式)��。
然后����,我們想想,年齡的擬合本身也未必是一件非?���?孔V的事情,我們依據(jù)其余屬性����,其實(shí)并不能很好地?cái)M合預(yù)測出未知的年齡。再一個(gè)����,以我們的日常經(jīng)驗(yàn),小盆友和老人可能得到的照顧會(huì)多一些��,這樣看的話�,年齡作為一個(gè)連續(xù)值�,給一個(gè)固定的系數(shù),應(yīng)該和年齡是一個(gè)正相關(guān)或者負(fù)相關(guān)��,似乎體現(xiàn)不出兩頭受照顧的實(shí)際情況�,所以,說不定我們把年齡離散化�,按區(qū)段分作類別屬性會(huì)更合適一些。
上面只是我瞎想的����,who knows是不是這么回事呢,老老實(shí)實(shí)先把得到的model系數(shù)和feature關(guān)聯(lián)起來看看�。
pd.DataFrame({"columns":list(train_df.columns)[1:], "coef":list(clf.coef_.T)})
1
0.76555�����,恩�,結(jié)果還不錯(cuò)。畢竟��,這只是我們簡單分析處理過后出的一個(gè)baseline模型嘛��。
07 邏輯回歸系統(tǒng)優(yōu)化
7.1 模型系數(shù)關(guān)聯(lián)分析
親�����,你以為結(jié)果提交上了����,就完事了?
我不會(huì)告訴你���,這只是萬里長征第一步啊(淚牛滿面)?���。?���!這才剛擼完baseline model啊?����。����。∵€得優(yōu)化?����。��。���?!
看過Andrew Ng老師的machine Learning課程的同學(xué)們���,知道�,我們應(yīng)該分析分析模型現(xiàn)在的狀態(tài)了��,是過/欠擬合��?�,以確定我們需要更多的特征還是更多數(shù)據(jù),或者其他操作��。我們有一條很著名的learning curves對(duì)吧��。
不過在現(xiàn)在的場景下���,先不著急做這個(gè)事情���,我們這個(gè)baseline系統(tǒng)還有些粗糙,先再挖掘挖掘�����。
首先�����,Name和Ticket兩個(gè)屬性被我們完整舍棄了(好吧,其實(shí)是因?yàn)檫@倆屬性�,幾乎每一條記錄都是一個(gè)完全不同的值,我們并沒有找到很直接的處理方式)��。
然后����,我們想想,年齡的擬合本身也未必是一件非?���?孔V的事情,我們依據(jù)其余屬性����,其實(shí)并不能很好地?cái)M合預(yù)測出未知的年齡。再一個(gè)����,以我們的日常經(jīng)驗(yàn),小盆友和老人可能得到的照顧會(huì)多一些��,這樣看的話�,年齡作為一個(gè)連續(xù)值�,給一個(gè)固定的系數(shù),應(yīng)該和年齡是一個(gè)正相關(guān)或者負(fù)相關(guān)��,似乎體現(xiàn)不出兩頭受照顧的實(shí)際情況�,所以,說不定我們把年齡離散化�,按區(qū)段分作類別屬性會(huì)更合適一些。
上面只是我瞎想的����,who knows是不是這么回事呢,老老實(shí)實(shí)先把得到的model系數(shù)和feature關(guān)聯(lián)起來看看�。
pd.DataFrame({"columns":list(train_df.columns)[1:], "coef":list(clf.coef_.T)})
1
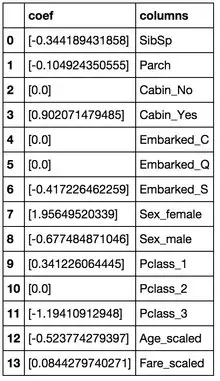 首先,大家回去前兩篇文章里瞄一眼公式就知道�,這些系數(shù)為正的特征,和最后結(jié)果是一個(gè)正相關(guān)��,反之為負(fù)相關(guān)��。
我們先看看那些權(quán)重絕對(duì)值非常大的feature��,在我們的模型上:
· Sex屬性���,如果是female會(huì)極大提高最后獲救的概率�����,而male會(huì)很大程度拉低這個(gè)概率��。
· Pclass屬性���,1等艙乘客最后獲救的概率會(huì)上升�,而乘客等級(jí)為3會(huì)極大地拉低這個(gè)概率�����。
· 有Cabin值會(huì)很大程度拉升最后獲救概率(這里似乎能看到了一點(diǎn)端倪���,事實(shí)上從最上面的有無Cabin記錄的Survived分布圖上看出��,即使有Cabin記錄的乘客也有一部分遇難了��,估計(jì)這個(gè)屬性上我們挖掘還不夠)
· Age是一個(gè)負(fù)相關(guān)��,意味著在我們的模型里���,年齡越小,越有獲救的優(yōu)先權(quán)(還得回原數(shù)據(jù)看看這個(gè)是否合理)
· 有一個(gè)登船港口S會(huì)很大程度拉低獲救的概率,另外倆港口壓根就沒啥作用(這個(gè)實(shí)際上非常奇怪�,因?yàn)槲覀儚闹暗慕y(tǒng)計(jì)圖上并沒有看到S港口的獲救率非常低,所以也許可以考慮把登船港口這個(gè)feature去掉試試)��。
· 船票Fare有小幅度的正相關(guān)(并不意味著這個(gè)feature作用不大����,有可能是我們細(xì)化的程度還不夠�����,舉個(gè)例子��,說不定我們得對(duì)它離散化�,再分至各個(gè)乘客等級(jí)上?)
噢啦���,觀察完了����,我們現(xiàn)在有一些想法了�����,但是怎么樣才知道,哪些優(yōu)化的方法是promising的呢���?
因?yàn)閠est.csv里面并沒有Survived這個(gè)字段(好吧���,這是廢話,這明明就是我們要預(yù)測的結(jié)果)��,我們無法在這份數(shù)據(jù)上評(píng)定我們算法在該場景下的效果…
而『每做一次調(diào)整就make a submission��,然后根據(jù)結(jié)果來判定這次調(diào)整的好壞』其實(shí)是行不通的…
7.2 交叉驗(yàn)證
我們通常情況下��,這么做cross validation:把train.csv分成兩部分��,一部分用于訓(xùn)練我們需要的模型�����,另外一部分?jǐn)?shù)據(jù)上看我們預(yù)測算法的效果����。
我們用scikit-learn的cross_validation來幫我們完成小數(shù)據(jù)集上的這個(gè)工作。
先簡單看看cross validation情況下的打分
結(jié)果是下面醬紫的:
[0.81564246 0.81005587 0.78651685 0.78651685 0.81355932]
似乎比Kaggle上的結(jié)果略高哈����,畢竟用的是不是同一份數(shù)據(jù)集評(píng)估的。
等等,既然我們要做交叉驗(yàn)證�,那我們干脆先把交叉驗(yàn)證里面的bad case拿出來看看,看看人眼審核���,是否能發(fā)現(xiàn)什么蛛絲馬跡��,是我們忽略了哪些信息��,使得這些乘客被判定錯(cuò)了。再把bad case上得到的想法和前頭系數(shù)分析的合在一起����,然后逐個(gè)試試。
下面我們做數(shù)據(jù)分割����,并且在原始數(shù)據(jù)集上瞄一眼bad case:
我們判定錯(cuò)誤的 bad case 中部分?jǐn)?shù)據(jù)如下:
首先,大家回去前兩篇文章里瞄一眼公式就知道�,這些系數(shù)為正的特征,和最后結(jié)果是一個(gè)正相關(guān)��,反之為負(fù)相關(guān)��。
我們先看看那些權(quán)重絕對(duì)值非常大的feature��,在我們的模型上:
· Sex屬性���,如果是female會(huì)極大提高最后獲救的概率�����,而male會(huì)很大程度拉低這個(gè)概率��。
· Pclass屬性���,1等艙乘客最后獲救的概率會(huì)上升�,而乘客等級(jí)為3會(huì)極大地拉低這個(gè)概率�����。
· 有Cabin值會(huì)很大程度拉升最后獲救概率(這里似乎能看到了一點(diǎn)端倪���,事實(shí)上從最上面的有無Cabin記錄的Survived分布圖上看出��,即使有Cabin記錄的乘客也有一部分遇難了��,估計(jì)這個(gè)屬性上我們挖掘還不夠)
· Age是一個(gè)負(fù)相關(guān)��,意味著在我們的模型里���,年齡越小,越有獲救的優(yōu)先權(quán)(還得回原數(shù)據(jù)看看這個(gè)是否合理)
· 有一個(gè)登船港口S會(huì)很大程度拉低獲救的概率,另外倆港口壓根就沒啥作用(這個(gè)實(shí)際上非常奇怪�,因?yàn)槲覀儚闹暗慕y(tǒng)計(jì)圖上并沒有看到S港口的獲救率非常低,所以也許可以考慮把登船港口這個(gè)feature去掉試試)��。
· 船票Fare有小幅度的正相關(guān)(并不意味著這個(gè)feature作用不大����,有可能是我們細(xì)化的程度還不夠�����,舉個(gè)例子��,說不定我們得對(duì)它離散化�,再分至各個(gè)乘客等級(jí)上?)
噢啦���,觀察完了����,我們現(xiàn)在有一些想法了�����,但是怎么樣才知道,哪些優(yōu)化的方法是promising的呢���?
因?yàn)閠est.csv里面并沒有Survived這個(gè)字段(好吧���,這是廢話,這明明就是我們要預(yù)測的結(jié)果)��,我們無法在這份數(shù)據(jù)上評(píng)定我們算法在該場景下的效果…
而『每做一次調(diào)整就make a submission��,然后根據(jù)結(jié)果來判定這次調(diào)整的好壞』其實(shí)是行不通的…
7.2 交叉驗(yàn)證
我們通常情況下��,這么做cross validation:把train.csv分成兩部分��,一部分用于訓(xùn)練我們需要的模型�����,另外一部分?jǐn)?shù)據(jù)上看我們預(yù)測算法的效果����。
我們用scikit-learn的cross_validation來幫我們完成小數(shù)據(jù)集上的這個(gè)工作。
先簡單看看cross validation情況下的打分
結(jié)果是下面醬紫的:
[0.81564246 0.81005587 0.78651685 0.78651685 0.81355932]
似乎比Kaggle上的結(jié)果略高哈����,畢竟用的是不是同一份數(shù)據(jù)集評(píng)估的。
等等,既然我們要做交叉驗(yàn)證�,那我們干脆先把交叉驗(yàn)證里面的bad case拿出來看看,看看人眼審核���,是否能發(fā)現(xiàn)什么蛛絲馬跡��,是我們忽略了哪些信息��,使得這些乘客被判定錯(cuò)了。再把bad case上得到的想法和前頭系數(shù)分析的合在一起����,然后逐個(gè)試試。
下面我們做數(shù)據(jù)分割����,并且在原始數(shù)據(jù)集上瞄一眼bad case:
我們判定錯(cuò)誤的 bad case 中部分?jǐn)?shù)據(jù)如下:
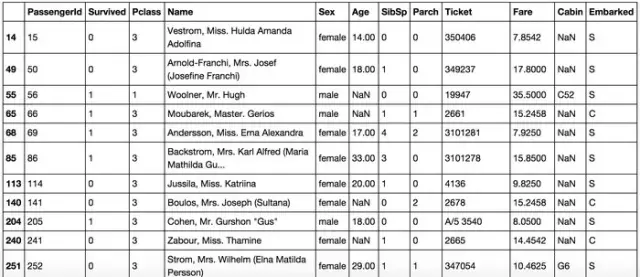 大家可以自己跑一遍試試,拿到bad cases之后�����,仔細(xì)看看���。也會(huì)有一些猜測和想法���。其中會(huì)有一部分可能會(huì)印證在系數(shù)分析部分的猜測��,那這些優(yōu)化的想法優(yōu)先級(jí)可以放高一些���。
現(xiàn)在有了”train_df” 和 “vc_df” 兩個(gè)數(shù)據(jù)部分,前者用于訓(xùn)練model�����,后者用于評(píng)定和選擇模型�����??梢蚤_始可勁折騰了。
我們隨便列一些可能可以做的優(yōu)化操作:
· Age屬性不使用現(xiàn)在的擬合方式���,而是根據(jù)名稱中的『Mr』『Mrs』『Miss』等的平均值進(jìn)行填充�。
· Age不做成一個(gè)連續(xù)值屬性����,而是使用一個(gè)步長進(jìn)行離散化,變成離散的類目feature��。
· Cabin再細(xì)化一些,對(duì)于有記錄的Cabin屬性����,我們將其分為前面的字母部分(我猜是位置和船層之類的信息) 和 后面的數(shù)字部分(應(yīng)該是房間號(hào),有意思的事情是���,如果你仔細(xì)看看原始數(shù)據(jù)���,你會(huì)發(fā)現(xiàn),這個(gè)值大的情況下��,似乎獲救的可能性高一些)��。
· Pclass和Sex倆太重要了��,我們試著用它們?nèi)ソM出一個(gè)組合屬性來試試�����,這也是另外一種程度的細(xì)化��。
· 單加一個(gè)Child字段�����,Age<=12的��,設(shè)為1����,其余為0(你去看看數(shù)據(jù),確實(shí)小盆友優(yōu)先程度很高啊)
· 如果名字里面有『Mrs』�,而Parch>1的,我們猜測她可能是一個(gè)母親����,應(yīng)該獲救的概率也會(huì)提高,因此可以多加一個(gè)Mother字段����,此種情況下設(shè)為1,其余情況下設(shè)為0
· 登船港口可以考慮先去掉試試(Q和C本來就沒權(quán)重����,S有點(diǎn)詭異)
· 把堂兄弟/兄妹 和 Parch 還有自己 個(gè)數(shù)加在一起組一個(gè)Family_size字段(考慮到大家族可能對(duì)最后的結(jié)果有影響)
· Name是一個(gè)我們一直沒有觸碰的屬性,我們可以做一些簡單的處理���,比如說男性中帶某些字眼的(‘Capt’, ‘Don’, ‘Major’, ‘Sir’)可以統(tǒng)一到一個(gè)Title��,女性也一樣�。
大家接著往下挖掘,可能還可以想到更多可以細(xì)挖的部分����。我這里先列這些了,然后我們可以使用手頭上的”train_df”和”cv_df”開始試驗(yàn)這些feature engineering的tricks是否有效了�。
試驗(yàn)的過程比較漫長,也需要有耐心�,而且我們經(jīng)常會(huì)面臨很尷尬的狀況,就是我們靈光一閃����,想到一個(gè)feature,然后堅(jiān)信它一定有效��,結(jié)果試驗(yàn)下來���,效果還不如試驗(yàn)之前的結(jié)果。恩�,需要堅(jiān)持和耐心,以及不斷的挖掘�。
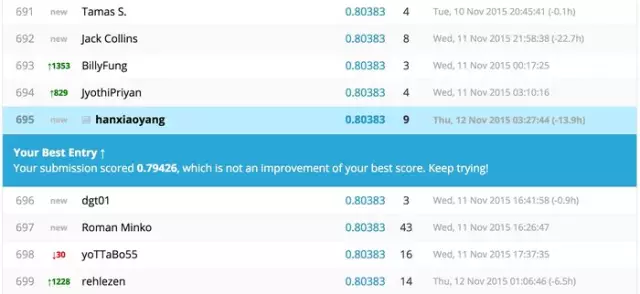
我最好的結(jié)果是在
『Survived~C(Pclass)+C(Title)+C(Sex)+C(Age_bucket)+C(Cabin_num_bucket)Mother+Fare+Family_Size』下取得的,結(jié)果如下(抱歉����,之前commit的時(shí)候沒有截圖���,于是重新make commission了,截了個(gè)圖���,不是目前我的最高分哈):
大家可以自己跑一遍試試,拿到bad cases之后�����,仔細(xì)看看���。也會(huì)有一些猜測和想法���。其中會(huì)有一部分可能會(huì)印證在系數(shù)分析部分的猜測��,那這些優(yōu)化的想法優(yōu)先級(jí)可以放高一些���。
現(xiàn)在有了”train_df” 和 “vc_df” 兩個(gè)數(shù)據(jù)部分,前者用于訓(xùn)練model�����,后者用于評(píng)定和選擇模型�����??梢蚤_始可勁折騰了。
我們隨便列一些可能可以做的優(yōu)化操作:
· Age屬性不使用現(xiàn)在的擬合方式���,而是根據(jù)名稱中的『Mr』『Mrs』『Miss』等的平均值進(jìn)行填充�。
· Age不做成一個(gè)連續(xù)值屬性����,而是使用一個(gè)步長進(jìn)行離散化,變成離散的類目feature��。
· Cabin再細(xì)化一些,對(duì)于有記錄的Cabin屬性����,我們將其分為前面的字母部分(我猜是位置和船層之類的信息) 和 后面的數(shù)字部分(應(yīng)該是房間號(hào),有意思的事情是���,如果你仔細(xì)看看原始數(shù)據(jù)���,你會(huì)發(fā)現(xiàn),這個(gè)值大的情況下��,似乎獲救的可能性高一些)��。
· Pclass和Sex倆太重要了��,我們試著用它們?nèi)ソM出一個(gè)組合屬性來試試�����,這也是另外一種程度的細(xì)化��。
· 單加一個(gè)Child字段�����,Age<=12的��,設(shè)為1����,其余為0(你去看看數(shù)據(jù),確實(shí)小盆友優(yōu)先程度很高啊)
· 如果名字里面有『Mrs』�,而Parch>1的,我們猜測她可能是一個(gè)母親����,應(yīng)該獲救的概率也會(huì)提高,因此可以多加一個(gè)Mother字段����,此種情況下設(shè)為1,其余情況下設(shè)為0
· 登船港口可以考慮先去掉試試(Q和C本來就沒權(quán)重����,S有點(diǎn)詭異)
· 把堂兄弟/兄妹 和 Parch 還有自己 個(gè)數(shù)加在一起組一個(gè)Family_size字段(考慮到大家族可能對(duì)最后的結(jié)果有影響)
· Name是一個(gè)我們一直沒有觸碰的屬性,我們可以做一些簡單的處理���,比如說男性中帶某些字眼的(‘Capt’, ‘Don’, ‘Major’, ‘Sir’)可以統(tǒng)一到一個(gè)Title��,女性也一樣�。
大家接著往下挖掘,可能還可以想到更多可以細(xì)挖的部分����。我這里先列這些了,然后我們可以使用手頭上的”train_df”和”cv_df”開始試驗(yàn)這些feature engineering的tricks是否有效了�。
試驗(yàn)的過程比較漫長,也需要有耐心�,而且我們經(jīng)常會(huì)面臨很尷尬的狀況,就是我們靈光一閃����,想到一個(gè)feature,然后堅(jiān)信它一定有效��,結(jié)果試驗(yàn)下來���,效果還不如試驗(yàn)之前的結(jié)果。恩�,需要堅(jiān)持和耐心,以及不斷的挖掘�。
我最好的結(jié)果是在
『Survived~C(Pclass)+C(Title)+C(Sex)+C(Age_bucket)+C(Cabin_num_bucket)Mother+Fare+Family_Size』下取得的,結(jié)果如下(抱歉����,之前commit的時(shí)候沒有截圖���,于是重新make commission了,截了個(gè)圖���,不是目前我的最高分哈):
 7.3 learning curves
有一個(gè)很可能發(fā)生的問題是�,我們不斷地做feature engineering���,產(chǎn)生的特征越來越多�����,用這些特征去訓(xùn)練模型��,會(huì)對(duì)我們的訓(xùn)練集擬合得越來越好�����,同時(shí)也可能在逐步喪失泛化能力����,從而在待預(yù)測的數(shù)據(jù)上����,表現(xiàn)不佳�,也就是發(fā)生過擬合問題�����。
從另一個(gè)角度上說����,如果模型在待預(yù)測的數(shù)據(jù)上表現(xiàn)不佳,除掉上面說的過擬合問題���,也有可能是欠擬合問題�,也就是說在訓(xùn)練集上�,其實(shí)擬合的也不是那么好。
額�����,這個(gè)欠擬合和過擬合怎么解釋呢��。這么說吧:
· 過擬合就像是你班那個(gè)學(xué)數(shù)學(xué)比較刻板的同學(xué)�����,老師講過的題目��,一字不漏全記下來了�,于是老師再出一樣的題目,分分鐘精確出結(jié)果��。but數(shù)學(xué)考試���,因?yàn)榭偸桥龅叫骂}目��,所以成績不咋地����。
· 欠擬合就像是�,咳咳,和博主level差不多的差生��。連老師講的練習(xí)題也記不住���,于是連老師出一樣題目復(fù)習(xí)的周測都做不好��,考試更是可想而知了��。
而在機(jī)器學(xué)習(xí)的問題上��,對(duì)于過擬合和欠擬合兩種情形�����。我們優(yōu)化的方式是不同的�����。
對(duì)過擬合而言�����,通常以下策略對(duì)結(jié)果優(yōu)化是有用的:
· 做一下feature selection�,挑出較好的feature的subset來做training
· 提供更多的數(shù)據(jù),從而彌補(bǔ)原始數(shù)據(jù)的bias問題�����,學(xué)習(xí)到的model也會(huì)更準(zhǔn)確
而對(duì)于欠擬合而言�����,我們通常需要更多的feature��,更復(fù)雜的模型來提高準(zhǔn)確度���。
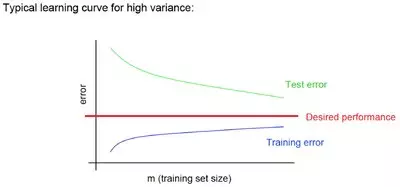
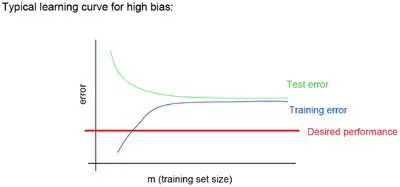
著名的learning curve可以幫我們判定我們的模型現(xiàn)在所處的狀態(tài)�����。我們以樣本數(shù)為橫坐標(biāo)�,訓(xùn)練和交叉驗(yàn)證集上的錯(cuò)誤率作為縱坐標(biāo)�,兩種狀態(tài)分別如下兩張圖所示:過擬合(overfitting/high variace),欠擬合(underfitting/high bias)
7.3 learning curves
有一個(gè)很可能發(fā)生的問題是�,我們不斷地做feature engineering���,產(chǎn)生的特征越來越多�����,用這些特征去訓(xùn)練模型��,會(huì)對(duì)我們的訓(xùn)練集擬合得越來越好�����,同時(shí)也可能在逐步喪失泛化能力����,從而在待預(yù)測的數(shù)據(jù)上����,表現(xiàn)不佳�,也就是發(fā)生過擬合問題�����。
從另一個(gè)角度上說����,如果模型在待預(yù)測的數(shù)據(jù)上表現(xiàn)不佳,除掉上面說的過擬合問題���,也有可能是欠擬合問題�,也就是說在訓(xùn)練集上�,其實(shí)擬合的也不是那么好。
額�����,這個(gè)欠擬合和過擬合怎么解釋呢��。這么說吧:
· 過擬合就像是你班那個(gè)學(xué)數(shù)學(xué)比較刻板的同學(xué)�����,老師講過的題目��,一字不漏全記下來了�,于是老師再出一樣的題目,分分鐘精確出結(jié)果��。but數(shù)學(xué)考試���,因?yàn)榭偸桥龅叫骂}目��,所以成績不咋地����。
· 欠擬合就像是�,咳咳,和博主level差不多的差生��。連老師講的練習(xí)題也記不住���,于是連老師出一樣題目復(fù)習(xí)的周測都做不好��,考試更是可想而知了��。
而在機(jī)器學(xué)習(xí)的問題上��,對(duì)于過擬合和欠擬合兩種情形�����。我們優(yōu)化的方式是不同的�����。
對(duì)過擬合而言�����,通常以下策略對(duì)結(jié)果優(yōu)化是有用的:
· 做一下feature selection�,挑出較好的feature的subset來做training
· 提供更多的數(shù)據(jù),從而彌補(bǔ)原始數(shù)據(jù)的bias問題�����,學(xué)習(xí)到的model也會(huì)更準(zhǔn)確
而對(duì)于欠擬合而言�����,我們通常需要更多的feature��,更復(fù)雜的模型來提高準(zhǔn)確度���。
著名的learning curve可以幫我們判定我們的模型現(xiàn)在所處的狀態(tài)�����。我們以樣本數(shù)為橫坐標(biāo)�,訓(xùn)練和交叉驗(yàn)證集上的錯(cuò)誤率作為縱坐標(biāo)�,兩種狀態(tài)分別如下兩張圖所示:過擬合(overfitting/high variace),欠擬合(underfitting/high bias)
我們也可以把錯(cuò)誤率替換成準(zhǔn)確率(得分)���,得到另一種形式的learning curve(sklearn 里面是這么做的)���。
回到我們的問題,我們用scikit-learn里面的learning_curve來幫我們分辨我們模型的狀態(tài)�。舉個(gè)例子,這里我們一起畫一下我們最先得到的baseline model的learning curve�����。
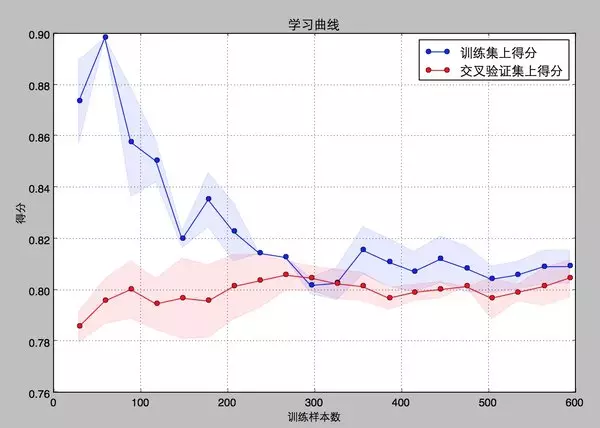 在實(shí)際數(shù)據(jù)上看��,我們得到的learning curve沒有理論推導(dǎo)的那么光滑哈�,但是可以大致看出來,訓(xùn)練集和交叉驗(yàn)證集上的得分曲線走勢還是符合預(yù)期的����。
在實(shí)際數(shù)據(jù)上看��,我們得到的learning curve沒有理論推導(dǎo)的那么光滑哈�,但是可以大致看出來,訓(xùn)練集和交叉驗(yàn)證集上的得分曲線走勢還是符合預(yù)期的����。
目前的曲線看來��,我們的model并不處于overfitting的狀態(tài)(overfitting的表現(xiàn)一般是訓(xùn)練集上得分高����,而交叉驗(yàn)證集上要低很多���,中間的gap比較大)��。因此我們可以再做些feature engineering的工作�,添加一些新產(chǎn)出的特征或者組合特征到模型中��。
08 模型融合(model ensemble)
啥叫模型融合呢����,我們還是舉幾個(gè)例子直觀理解一下好了。
大家都看過知識(shí)問答的綜藝節(jié)目中��,求助現(xiàn)場觀眾時(shí)候�,讓觀眾投票���,最高的答案作為自己的答案的形式吧,每個(gè)人都有一個(gè)判定結(jié)果��,最后我們相信答案在大多數(shù)人手里。
再通俗一點(diǎn)舉個(gè)例子��。你和你班某數(shù)學(xué)大神關(guān)系好,每次作業(yè)都『模仿』他的���,于是絕大多數(shù)情況下�,他做對(duì)了�����,你也對(duì)了。突然某一天大神腦子犯糊涂����,手一抖��,寫錯(cuò)了一個(gè)數(shù)����,于是…恩�����,你也只能跟著錯(cuò)了�。
我們再來看看另外一個(gè)場景��,你和你班5個(gè)數(shù)學(xué)大神關(guān)系都很好,每次都把他們作業(yè)拿過來��,對(duì)比一下���,再『自己做』����,那你想想���,如果哪天某大神犯糊涂了��,寫錯(cuò)了���,but另外四個(gè)寫對(duì)了啊����,那你肯定相信另外4人的是正確答案吧?
最簡單的模型融合大概就是這么個(gè)意思��,比如分類問題,當(dāng)我們手頭上有一堆在同一份數(shù)據(jù)集上訓(xùn)練得到的分類器(比如logistic regression���,SVM����,KNN����,random forest,神經(jīng)網(wǎng)絡(luò))��,那我們讓他們都分別去做判定�����,然后對(duì)結(jié)果做投票統(tǒng)計(jì)����,取票數(shù)最多的結(jié)果為最后結(jié)果����。
bingo�,問題就這么完美的解決了�。
模型融合可以比較好地緩解�����,訓(xùn)練過程中產(chǎn)生的過擬合問題�����,從而對(duì)于結(jié)果的準(zhǔn)確度提升有一定的幫助����。
話說回來���,回到我們現(xiàn)在的問題��。你看����,我們現(xiàn)在只講了logistic regression����,如果我們還想用這個(gè)融合思想去提高我們的結(jié)果���,我們該怎么做呢��?
既然這個(gè)時(shí)候模型沒得選�����,那咱們就在數(shù)據(jù)上動(dòng)動(dòng)手腳咯���。大家想想,如果模型出現(xiàn)過擬合現(xiàn)在�,一定是在我們的訓(xùn)練上出現(xiàn)擬合過度造成的對(duì)吧����。
那我們干脆就不要用全部的訓(xùn)練集,每次取訓(xùn)練集的一個(gè)subset�,做訓(xùn)練,這樣��,我們雖然用的是同一個(gè)機(jī)器學(xué)習(xí)算法��,但是得到的模型卻是不一樣的��;同時(shí)�,因?yàn)槲覀儧]有任何一份子數(shù)據(jù)集是全的�,因此即使出現(xiàn)過擬合��,也是在子訓(xùn)練集上出現(xiàn)過擬合�����,而不是全體數(shù)據(jù)上,這樣做一個(gè)融合�,可能對(duì)最后的結(jié)果有一定的幫助�。對(duì),這就是常用的Bagging��。
我們用scikit-learn里面的Bagging來完成上面的思路�,過程非常簡單。代碼如下:
然后你再M(fèi)ake a submission,恩�,發(fā)現(xiàn)對(duì)結(jié)果還是有幫助的����。
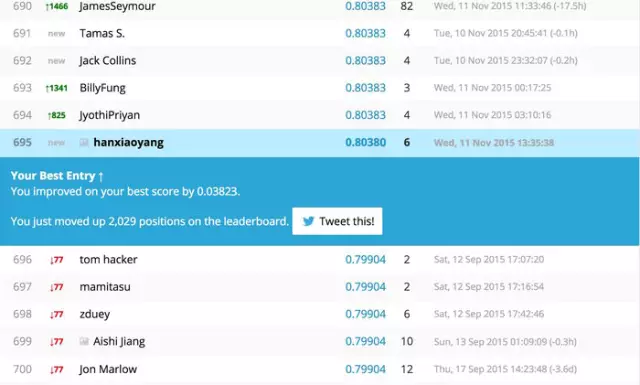 09 總結(jié)
文章稍微有點(diǎn)長��,非常感謝各位耐心看到這里。
總結(jié)的部分���,我就簡短寫幾段,出現(xiàn)的話�����,很多在文中有對(duì)應(yīng)的場景�����,大家有興趣再回頭看看。
對(duì)于任何的機(jī)器學(xué)習(xí)問題��,不要一上來就追求盡善盡美,先用自己會(huì)的算法擼一個(gè)baseline的model出來�,再進(jìn)行后續(xù)的分析步驟�,一步步提高。
在問題的結(jié)果過程中:
* 『對(duì)數(shù)據(jù)的認(rèn)識(shí)太重要了!』
* 『數(shù)據(jù)中的特殊點(diǎn)/離群點(diǎn)的分析和處理太重要了!』
* 『特征工程(feature engineering)太重要了�����!』
* 『模型融合(model ensemble)太重要了��!』
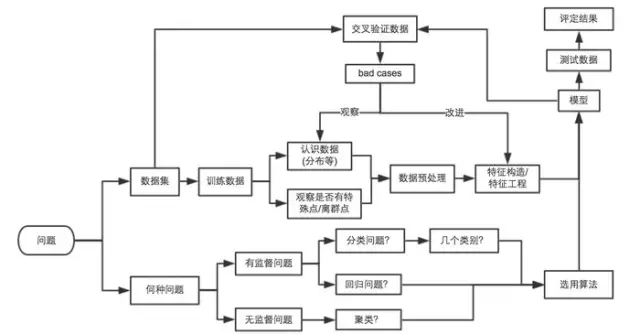
本文中用機(jī)器學(xué)習(xí)解決問題的過程大概如下圖所示:
09 總結(jié)
文章稍微有點(diǎn)長��,非常感謝各位耐心看到這里。
總結(jié)的部分���,我就簡短寫幾段,出現(xiàn)的話�����,很多在文中有對(duì)應(yīng)的場景�����,大家有興趣再回頭看看。
對(duì)于任何的機(jī)器學(xué)習(xí)問題��,不要一上來就追求盡善盡美,先用自己會(huì)的算法擼一個(gè)baseline的model出來�,再進(jìn)行后續(xù)的分析步驟�,一步步提高。
在問題的結(jié)果過程中:
* 『對(duì)數(shù)據(jù)的認(rèn)識(shí)太重要了!』
* 『數(shù)據(jù)中的特殊點(diǎn)/離群點(diǎn)的分析和處理太重要了!』
* 『特征工程(feature engineering)太重要了�����!』
* 『模型融合(model ensemble)太重要了��!』
本文中用機(jī)器學(xué)習(xí)解決問題的過程大概如下圖所示:
 順便說一句��,CDA數(shù)據(jù)分析競賽正在籌備中���,想要參加比賽或者和我們合作的可以后臺(tái)回復(fù)“CDA數(shù)據(jù)分析競賽”加入我們�。
順便說一句��,CDA數(shù)據(jù)分析競賽正在籌備中���,想要參加比賽或者和我們合作的可以后臺(tái)回復(fù)“CDA數(shù)據(jù)分析競賽”加入我們�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330