分類算法之貝葉斯網(wǎng)絡(Bayesian networks)
在上一篇文章中我們討論了樸素貝葉斯分類�。樸素貝葉斯分類有一個限制條件�,就是特征屬性必須有條件獨立或基本獨立(實際上在現(xiàn)實應用中幾乎不可能做到完全獨立)。當這個條件成立時�,樸素貝葉斯分類法的準確率是最高的,但不幸的是����,現(xiàn)實中各個特征屬性間往往并不條件獨立,而是具有較強的相關性�����,這樣就限制了樸素貝葉斯分類的能力�����。這一篇文章中�,我們接著上一篇文章的例子,討論貝葉斯分類中更高級�、應用范圍更廣的一種算法——貝葉斯網(wǎng)絡(又稱貝葉斯信念網(wǎng)絡或信念網(wǎng)絡)。
2.2�����、重新考慮上一篇的例子
上一篇文章我們使用樸素貝葉斯分類實現(xiàn)了SNS社區(qū)中不真實賬號的檢測。在那個解決方案中��,我做了如下假設:
i�����、真實賬號比非真實賬號平均具有更大的日志密度���、各大的好友密度以及更多的使用真實頭像。
ii�����、日志密度����、好友密度和是否使用真實頭像在賬號真實性給定的條件下是獨立的。
但是�����,上述第二條假設很可能并不成立����。一般來說,好友密度除了與賬號是否真實有關,還與是否有真實頭像有關���,因為真實的頭像會吸引更多人加其為好友����。因此����,我們?yōu)榱双@取更準確的分類,可以將假設修改如下:
i����、真實賬號比非真實賬號平均具有更大的日志密度、各大的好友密度以及更多的使用真實頭像��。
ii��、日志密度與好友密度����、日志密度與是否使用真實頭像在賬號真實性給定的條件下是獨立的。
iii���、使用真實頭像的用戶比使用非真實頭像的用戶平均有更大的好友密度����。
上述假設更接近實際情況,但問題隨之也來了��,由于特征屬性間存在依賴關系�����,使得樸素貝葉斯分類不適用了��。既然這樣��,我去尋找另外的解決方案�。
下圖表示特征屬性之間的關聯(lián):
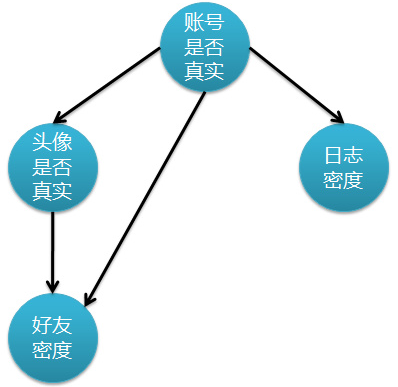
上圖是一個有向無環(huán)圖����,其中每個節(jié)點代表一個隨機變量,而弧則表示兩個隨機變量之間的聯(lián)系����,表示指向結點影響被指向結點。不過僅有這個圖的話�����,只能定性給出隨機變量間的關系,如果要定量�����,還需要一些數(shù)據(jù)���,這些數(shù)據(jù)就是每個節(jié)點對其直接前驅(qū)節(jié)點的條件概率�����,而沒有前驅(qū)節(jié)點的節(jié)點則使用先驗概率表示��。
例如����,通過對訓練數(shù)據(jù)集的統(tǒng)計���,得到下表(R表示賬號真實性�����,H表示頭像真實性):
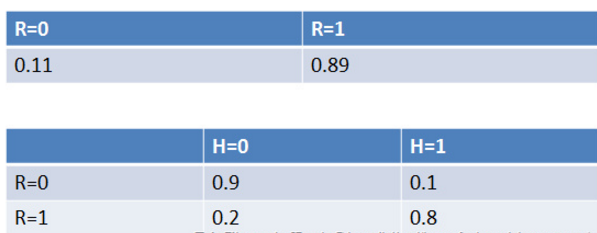
縱向表頭表示條件變量�����,橫向表頭表示隨機變量�����。上表為真實賬號和非真實賬號的概率���,而下表為頭像真實性對于賬號真實性的概率���。這兩張表分別為“賬號是否真實”和“頭像是否真實”的條件概率表����。有了這些數(shù)據(jù),不但能順向推斷���,還能通過貝葉斯定理進行逆向推斷����。例如���,現(xiàn)隨機抽取一個賬戶�����,已知其頭像為假�,求其賬號也為假的概率:
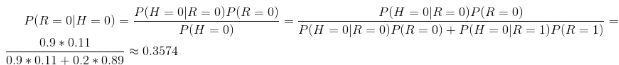
也就是說,在僅知道頭像為假的情況下�,有大約35.7%的概率此賬戶也為假。如果覺得閱讀上述推導有困難�,請復習概率論中的條件概率、貝葉斯定理及全概率公式���。如果給出所有節(jié)點的條件概率表����,則可以在觀察值不完備的情況下對任意隨機變量進行統(tǒng)計推斷���。上述方法就是使用了貝葉斯網(wǎng)絡�����。
2.3��、貝葉斯網(wǎng)絡的定義及性質(zhì)
有了上述鋪墊�����,我們就可以正式定義貝葉斯網(wǎng)絡了�����。
一個貝葉斯網(wǎng)絡定義包括一個有向無環(huán)圖(DAG)和一個條件概率表集合����。DAG中每一個節(jié)點表示一個隨機變量,可以是可直接觀測變量或隱藏變量�,而有向邊表示隨機變量間的條件依賴;條件概率表中的每一個元素對應DAG中唯一的節(jié)點����,存儲此節(jié)點對于其所有直接前驅(qū)節(jié)點的聯(lián)合條件概率。
貝葉斯網(wǎng)絡有一條極為重要的性質(zhì)����,就是我們斷言每一個節(jié)點在其直接前驅(qū)節(jié)點的值制定后�����,這個節(jié)點條件獨立于其所有非直接前驅(qū)前輩節(jié)點�。
這個性質(zhì)很類似Markov過程。其實��,貝葉斯網(wǎng)絡可以看做是Markov鏈的非線性擴展�。這條特性的重要意義在于明確了貝葉斯網(wǎng)絡可以方便計算聯(lián)合概率分布�。一般情況先���,多變量非獨立聯(lián)合條件概率分布有如下求取公式:
=P(x_1)P(x_2|x_1)P(x_3|x_1,x_2)...P(x_n|x_1,x_2,...,x_{n-1}) "P(x_1,x_2,...,x_n)=P(x_1)P(x_2|x_1)P(x_3|x_1,x_2)...P(x_n|x_1,x_2,...,x_{n-1})")
而在貝葉斯網(wǎng)絡中���,由于存在前述性質(zhì),任意隨機變量組合的聯(lián)合條件概率分布被化簡成
=\prod^n_{i=1}P(x_i|Parents(x_i)) "P(x_1,x_2,...,x_n)=\prod^n_{i=1}P(x_i|Parents(x_i))")
其中Parents表示xi的直接前驅(qū)節(jié)點的聯(lián)合�����,概率值可以從相應條件概率表中查到�����。
貝葉斯網(wǎng)絡比樸素貝葉斯更復雜��,而想構造和訓練出一個好的貝葉斯網(wǎng)絡更是異常艱難��。但是貝葉斯網(wǎng)絡是模擬人的認知思維推理模式����,用一組條件概率函數(shù)以及有向無環(huán)圖對不確定性的因果推理關系建模,因此其具有更高的實用價值�。
2.4、貝葉斯網(wǎng)絡的構造及學習
構造與訓練貝葉斯網(wǎng)絡分為以下兩步:
1��、確定隨機變量間的拓撲關系,形成DAG�。這一步通常需要領域?qū)<彝瓿桑胍⒁粋€好的拓撲結構�,通常需要不斷迭代和改進才可以。
2���、訓練貝葉斯網(wǎng)絡�����。這一步也就是要完成條件概率表的構造��,如果每個隨機變量的值都是可以直接觀察的��,像我們上面的例子�,那么這一步的訓練是直觀的�����,方法類似于樸素貝葉斯分類���。但是通常貝葉斯網(wǎng)絡的中存在隱藏變量節(jié)點,那么訓練方法就是比較復雜���,例如使用梯度下降法��。由于這些內(nèi)容過于晦澀以及牽扯到較深入的數(shù)學知識�,在此不再贅述,有興趣的朋友可以查閱相關文獻��。
2.5�、貝葉斯網(wǎng)絡的應用及示例
貝葉斯網(wǎng)絡作為一種不確定性的因果推理模型,其應用范圍非常廣�,在醫(yī)療診斷、信息檢索�、電子技術與工業(yè)工程等諸多方面發(fā)揮重要作用,而與其相關的一些問題也是近來的熱點研究課題��。例如���,Google就在諸多服務中使用了貝葉斯網(wǎng)絡��。
就使用方法來說����,貝葉斯網(wǎng)絡主要用于概率推理及決策�,具體來說,就是在信息不完備的情況下通過可以觀察隨機變量推斷不可觀察的隨機變量,并且不可觀察隨機變量可以多于以一個����,一般初期將不可觀察變量置為隨機值,然后進行概率推理�����。下面舉一個例子��。
還是SNS社區(qū)中不真實賬號檢測的例子�,我們的模型中存在四個隨機變量:賬號真實性R,頭像真實性H�,日志密度L,好友密度F����。其中H,L�����,F(xiàn)是可以觀察到的值�,而我們最關系的R是無法直接觀察的。這個問題就劃歸為通過H���,L�,F(xiàn)的觀察值對R進行概率推理�。推理過程可以如下表示:
1、使用觀察值實例化H,L和F����,把隨機值賦給R。
2����、計算=P(H|R)P(L|R)P(F|R,H) "P(R|H,L,F)=P(H|R)P(L|R)P(F|R,H)") 。其中相應概率值可以查條件概率表���。
。其中相應概率值可以查條件概率表���。
由于上述例子只有一個未知隨機變量�,所以不用迭代��。更一般得���,使用貝葉斯網(wǎng)絡進行推理的步驟可如下描述:
1���、對所有可觀察隨機變量節(jié)點用觀察值實例化;對不可觀察節(jié)點實例化為隨機值�����。
2、對DAG進行遍歷����,對每一個不可觀察節(jié)點y,計算=\alpha%20P(y|Parents(y))\prod%20_jP(s_j|Parents(s_j)) "P(y|w_i)=\alpha P(y|Parents(y))\prod _jP(s_j|Parents(s_j))") ��,其中wi表示除y以外的其它所有節(jié)點���,a為正規(guī)化因子��,sj表示y的第j個子節(jié)點�。
��,其中wi表示除y以外的其它所有節(jié)點���,a為正規(guī)化因子��,sj表示y的第j個子節(jié)點�。
3���、使用第三步計算出的各個y作為未知節(jié)點的新值進行實例化����,重復第二步��,直到結果充分收斂����。
4��、將收斂結果作為推斷值�����。
以上只是貝葉斯網(wǎng)絡推理的算法之一,另外還有其它算法��,這里不再詳述����。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330