數(shù)據(jù)挖掘 | 數(shù)據(jù)理解和預(yù)處理
小編遇到過很多人(咳咳,請不要對號入座)�����,拿到數(shù)據(jù)后不管三七二十一����,先丟到模型中去跑�,管它具體什么樣呢,反正“大數(shù)據(jù)”嘛�����,總能整出點東西來�����。
但就像上次說過的�,“大數(shù)據(jù)”很有可能帶來“大錯誤”!所以在數(shù)據(jù)挖掘工作開始前�����,認(rèn)真的理解數(shù)據(jù)�、檢查數(shù)據(jù)���,對數(shù)據(jù)進(jìn)行預(yù)處理是至關(guān)重要的。
很多人說����,數(shù)據(jù)準(zhǔn)備工作真是個“體力活”,耗時耗力不說����,還異常的枯燥無味。這點小編承認(rèn)��,建模之前的數(shù)據(jù)處理確實是平淡的���,它往往不需要多高的智商�����,多牛的編程技巧����,多么高大上的統(tǒng)計模型��。
但是�����,它卻能時時觸發(fā)你的興奮點,因為它需要足夠的耐心和細(xì)心�,稍不留神就前功盡棄。
在這次的內(nèi)容里���,小編首先會從“數(shù)據(jù)理解”����、“變量類型”和“質(zhì)量檢查”三個方面進(jìn)行闡述�,然后會以一個自己做過的實際數(shù)據(jù)為例進(jìn)行展示。
一���、數(shù)據(jù)理解
拿到數(shù)據(jù)后要做的第一步就是理解數(shù)據(jù)�����。
什么是理解數(shù)據(jù)呢?不是簡單看下有多少Excel表����,有多少行����,多少列,而是要結(jié)合自己的分析目標(biāo)�����,帶著具體的業(yè)務(wù)需求去看����。
首先,我們需要明確數(shù)據(jù)記錄的詳細(xì)程度�,比方說某個網(wǎng)站的訪問量數(shù)據(jù)是以每小時為單位還是每天為單位;一份銷售數(shù)據(jù)記錄的是每家門店的銷售額還是每個地區(qū)的總銷售額。
其次��,我們需要確定研究群體�。研究群體的確定一定和業(yè)務(wù)目標(biāo)是密切相關(guān)的。
比方說����,如果我們想研究用戶對產(chǎn)品的滿意度與哪些因素有關(guān),就應(yīng)該把購買該產(chǎn)品的所有客戶作為研究群體;如果我們想研究用戶的購買行為受哪些因素影響���,就應(yīng)該同時考察購買人群和非購買人群��,在兩類人群的對比中尋找關(guān)鍵因素����。
研究群體的確定有時也和數(shù)據(jù)的詳細(xì)程度有關(guān)。
比如我們想研究“觀眾影評”對“電影票房”的影響�����,我們既可以把“每部電影”看成一個個體��,研究“影評總數(shù)”對“電影總票房”的影響���,也可以把“每部電影每天的票房”看成一個個體����,研究“每天的影評數(shù)”對“每天的電影票房”的影響����。
具體選擇哪一種取決于我們手上有什么樣的數(shù)據(jù),如果只有總票房和總影評數(shù)的數(shù)據(jù)�,那我們只能選擇第一種;如果有更詳細(xì)的數(shù)據(jù),那就可以考慮第二種方案�。
需要注意的是,這兩種方案還會影響我們對于模型的選擇����。
例如,如果研究“每天的影評數(shù)”對“每天電影票房”的影響�����,那每部電影又被細(xì)分為很多天��,同一部電影不同時間的票房會有較高的相似性����,這就形成了一種層次結(jié)構(gòu),可以考慮使用層次模型(hierarchical model)進(jìn)行分析�����。
最后���,當(dāng)我們確定了研究目標(biāo)和研究群體后�,我們需要逐一理解每個變量的含義�����。有些變量和業(yè)務(wù)目標(biāo)明顯無關(guān)�,可以直接從研究中剔除。
有些變量雖然有意義�,但是在全部樣本上取值都一樣,這樣的變量就是冗余變量,也需要從研究中剔除����。
還有一些變量具有重復(fù)的含義,如“省份名稱”和“省份簡稱”���,這時只需要保留一個就可以了����。
二�、變量類型
所有變量按其測量尺度可以分成兩大類,一類是“分類變量”��,一類是“數(shù)值變量”��。不同類型的變量在處理方法和后期的模型選擇上會有顯著差別���。
【分類變量】
分類變量又稱屬性變量或離散變量�����,它的取值往往用有限的幾個類別名稱就可以表示了���,例如“性別”���,“教育程度”,“收入水平”�����,“星期幾”等����。細(xì)分的話���,分類變量又可分為兩類�����,一類是“名義變量”��,即各個類別間沒有順序和程度的差別�����,就像“手機(jī)系統(tǒng)”中ios和安卓并沒有明顯的好壞差別���,“電影類型”中“動作片”和“科幻片”也都是一樣的,說不上哪個更好或更差。
另外一類是定序變量�,即不同類別之間存在有意義的排序,如“空氣污染程度”可以用“差����、良、優(yōu)”來表示���、“教育程度”可以用“小學(xué)����、初中���、高中�����、大學(xué)”來表示����。
當(dāng)研究的因變量是分類變量時��,往往對應(yīng)特定的分析方法��,我們在后面的章節(jié)會陸續(xù)講到,這里暫且不談���。
當(dāng)研究中的自變量是分類變量時���,也會限制模型選擇的范圍。有些數(shù)據(jù)挖掘模型可以直接處理分類自變量�����,如決策樹模型;但很多數(shù)據(jù)挖掘模型不能直接處理分類自變量���,如線性回歸、神經(jīng)網(wǎng)絡(luò)等����,因此需要將分類變量轉(zhuǎn)換成數(shù)值變量。
對于定序自變量����,最常用的轉(zhuǎn)換方法就是按照類別程度將其直接轉(zhuǎn)換成數(shù)值自變量,例如將空氣污染程度 “差���、良����、優(yōu)”轉(zhuǎn)換為“1,2,3”。
對于名義自變量�����,最常用的轉(zhuǎn)換方法就是構(gòu)造0-1型啞變量�����。例如�,對于“性別”,可以定義“1=男����,0=女”。
當(dāng)某個名義變量有K個類別取值時�,則需要構(gòu)造K-1個啞變量。例如教育程度“小學(xué)�,初中,高中��,大學(xué)及以上”�,可以構(gòu)造三個啞變量分別為:x1:1=小學(xué),0=其它;x2:1=初中���,0=其它;x3:1=高中��,0=其它�����。當(dāng)x1�,x2,x3三個啞變量取值都為0時�����,則對應(yīng)著“大學(xué)及以上”�。
需要注意的是�,有時候名義變量的取值太多,會生成太多的啞變量����,這很容易造成模型的過度擬合。
這時可以考慮只把觀測比較多的幾個類別單獨拿出來�,而把剩下所有的類別都?xì)w為“其它”。
例如��,中國一共包含56個民族�,如果每個民族都生成一個啞變量就會有55個����,這時我們可以只考慮設(shè)置“是否為漢族”這一個0-1啞變量�����。
【數(shù)值變量】
我們再來看看數(shù)值變量�����。數(shù)值變量就是用數(shù)值描述�����,并且可以直接進(jìn)行代數(shù)運算的變量����,如“銷售收入”、“固定資本”����、“評論總數(shù)”、“訪問量”�、“學(xué)生成績”等等都是數(shù)值變量。
需要注意的是�����,用數(shù)值表示的變量不一定就是數(shù)值型變量,只有在代數(shù)運算下有意義的變量才是數(shù)值型變量��。
例如財務(wù)報表的年份����,上市時間等,雖然也是用數(shù)值表示的�,但我們通常不將它們按照數(shù)值型變量來處理。
上面我們講到����,分類變量通常要轉(zhuǎn)換成數(shù)值型變量,其實有些時候�����,數(shù)值型變量也需要轉(zhuǎn)換成分類變量��,這就用到了“數(shù)據(jù)分箱”的方法��。
為什么要進(jìn)行數(shù)據(jù)分箱呢?通常有以下幾個原因:
1. 數(shù)據(jù)的測量可能存在一定誤差���,沒有那么準(zhǔn)確���,因此按照取值范圍轉(zhuǎn)換成不同類別是一個有效的平滑方法;
2.有些算法,如決策樹模型�,雖然可以處理數(shù)值型變量,但是當(dāng)該變量有大量不重復(fù)的取值時��,使用大于����、小于、等于這些運算符時會考慮很多的情況�,因此效率會很低,數(shù)據(jù)分箱的方法能很好的提高算法效率;
3.有些模型算法只能處理分類型自變量(如關(guān)聯(lián)規(guī)則)�����,因此也需要將數(shù)值變量進(jìn)行分箱處理���。
數(shù)據(jù)分箱后���,可以使用每個分箱內(nèi)的均值、中位數(shù)���、臨界值等作為這個類別的代表值�,也可以直接將不同取值范圍定義成不同的類別,如:將污染程度劃分后定義為“低�����、中��、高”等���。
那如何進(jìn)行數(shù)據(jù)分箱呢?常用的數(shù)據(jù)分箱的方法有:等寬分箱(將變量的取值范圍劃分成等寬的幾個區(qū)間)����、等頻分箱(按照變量取值的分位數(shù)進(jìn)行劃分)�����、基于k均值聚類的分箱(將所有數(shù)據(jù)進(jìn)行k均值聚類�����,所得的不同類別即為不同的分箱)�,還有一些有監(jiān)督分箱方法���,如:使分箱后的結(jié)果達(dá)到最小熵或最小描述長度等�。這里不詳細(xì)介紹了,有興趣的童鞋可以自行百度���。
三���、質(zhì)量檢查
對數(shù)據(jù)中的各個變量有了初步了解后,我們還需要對數(shù)據(jù)進(jìn)行嚴(yán)格的質(zhì)量檢查�,如果數(shù)據(jù)質(zhì)量不過關(guān),還需要進(jìn)行數(shù)據(jù)的清洗或修補(bǔ)工作�。
一般來說,質(zhì)量檢查包括檢查每個變量的缺失程度以及取值范圍的合理性�。
【缺失檢查】
原始數(shù)據(jù)中經(jīng)常會存在各種各樣的缺失現(xiàn)象。
有些指標(biāo)的缺失是合理的���,例如顧客只有使用過某個產(chǎn)品才能對這個產(chǎn)品的滿意度進(jìn)行評價����,一筆貸款的抵押物中只有存在房地產(chǎn)�,才會記錄相應(yīng)的房地產(chǎn)的價值情況等。
像這種允許缺失的變量是最難搞的��,因為我們很難判斷它的缺失是合理的���,還是由于漏報造成的����。
但無論哪種情況,如果變量的缺失率過高���,都會影響數(shù)據(jù)的整體質(zhì)量�,因為數(shù)據(jù)所反映的信息實在太少����,很難從中挖掘到有用的東西。
對于不允許缺失的變量來說�����,如果存在缺失情況���,就必須進(jìn)行相應(yīng)的處理��。如果一個變量的缺失程度非常大���,比方說達(dá)到了70%,那就考慮直接踢掉吧�����,估計沒救了����。
如果缺失比例還可以接受的話,可以嘗試用缺失值插補(bǔ)的方法進(jìn)行補(bǔ)救����。
插補(bǔ)的目的是使插補(bǔ)值能最大可能的接近其真實的取值,所以如果可以從其他途徑得到變量的真實值�,那一定優(yōu)先選擇這種方法。
比如某個公司的財務(wù)信息中缺失了“最終控制人類型”和“是否國家控股”這兩個取值���,這些可以通過網(wǎng)上的公開信息得到真實值;再比如缺失了“凈利潤率”這個指標(biāo)的取值���,但是卻有“凈利潤”和“總收入”的取值,那就可以通過變量間的關(guān)系得到相應(yīng)的缺失值��,即凈利潤率=凈利潤/總收入�。
當(dāng)然,更多的時候���,我們無法得到缺失值的真實信息����,這時就只能借用已有的數(shù)據(jù)來進(jìn)行插補(bǔ)了。
對數(shù)值變量來說����,可以用已觀測值的均值、中位數(shù)來插補(bǔ)缺失值;對分類型變量來說���,可以用已觀測數(shù)據(jù)中出現(xiàn)比例最高的類別取值來進(jìn)行插補(bǔ)����。
這些方法操作起來非常簡單����,但它們都是對所有缺失值賦予了相同的取值,所以當(dāng)缺失比例較大時��,可能會扭曲被插補(bǔ)變量與其余變量的關(guān)系���。
更復(fù)雜一點的�,我們可以選擇模型插補(bǔ)方法�,即針對被插補(bǔ)變量和其它自變量之間的關(guān)系建立統(tǒng)計模型(如回歸、決策樹等)���,將模型預(yù)測值作為插補(bǔ)值�。
如何處理缺失值是一個很大的研究課題,我們這里只是介紹了最簡單可行的方法��,有興趣的讀者可以參閱Little和Rubin 2002年的專著“Statistical Analysis with Missing Data”�。
【變量取值合理性檢查】
除了缺失外��,我們還要考察每個變量的取值合理性��。每個變量都會有自己的取值范圍�,比如“用戶訪問量”、“下載次數(shù)”一定是非負(fù)的���,“投資收益率”一定在0~1之間�。通過判斷變量的取值是否超出它應(yīng)有的取值范圍�,可以簡單的對異常值進(jìn)行甄別。
除了根據(jù)變量的取值范圍來檢查變量質(zhì)量外���,還可以根據(jù)變量之間的相互關(guān)系進(jìn)行判斷���。例如一家公司的“凈利潤率”不應(yīng)該大于“總利潤率”等。
只有通過了各個方面檢測的數(shù)據(jù)才是一份高質(zhì)量的數(shù)據(jù)���,才有可能帶來有價值的模型結(jié)果��。
四�、實例分析——電影票房分析
最后,我們給出一個實例分析�。在這個例子中,我們的目標(biāo)是研究電影哪些方面的特征對電影票房有影響��。
我們有兩方面的數(shù)據(jù)����,一是描述電影特征的數(shù)據(jù),二是描述電影票房的數(shù)據(jù)���。
由于我們關(guān)注的是北美的票房市場�,所以描述電影特征的數(shù)據(jù)可以從IMDB網(wǎng)站得到���,它是一個關(guān)于演員���、電影、電視節(jié)目�、電視明星和電影制作的在線數(shù)據(jù)庫,里面可以找到每部上映電影的眾多信息;電影每天的票房數(shù)據(jù)可以從美國權(quán)威的票房網(wǎng)站Box Office Mojo得到,上面記錄了每部電影上映期間內(nèi)每天的票房數(shù)據(jù)����。
我們將從IMDB得到的數(shù)據(jù)放到“movieinfor.csv”文件中,將從Box Office Mojo中得到的數(shù)據(jù)放到“boxoffice.csv”文件中��。
這里�����,我們以2012年北美票房市場最高的前100部電影為例進(jìn)行講解���。下表給出了這兩個數(shù)據(jù)集中包含的所有變量以及相應(yīng)的解釋。
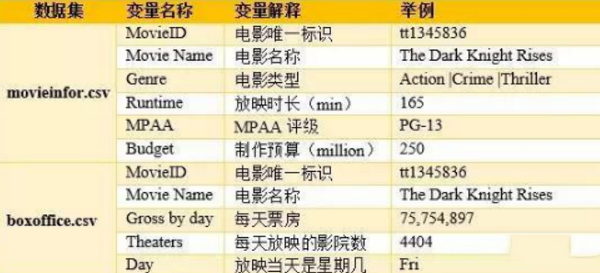
在這兩個數(shù)據(jù)中��,movieinfor.csv數(shù)據(jù)的記錄是精確到每部電影的����,而boxoffice.csv數(shù)據(jù)精確到了每部電影中每天的票房數(shù)據(jù),是精確到天的���。上表中給出的變量中����,除了電影名稱和ID外,“電影類型”“MPAA評級”(美國電影協(xié)會對電影的評級)和“星期幾”是分類型變量;“放映時長”��、“制作預(yù)算”�����、“電影每天的票房”和“每天放映的影院數(shù)”是數(shù)值型變量�。兩份數(shù)據(jù)都不存在缺失值。
我們首先對兩個數(shù)據(jù)集分別進(jìn)行變量預(yù)處理�,然后再根據(jù)電影ID將兩個數(shù)據(jù)整合到一起。下面給出了每個變量的處理方法:
【電影類型】
電影類型是一個分類變量��。在這個變量中我們發(fā)現(xiàn)每部電影都不止一個類型�,例如“The Dark Knight Rises”這部電影就有“Action”、“Crime”和“Thriller”三個類型��,并且它們以“|”為分隔符寫在了一起��。
同時���,不同電影之間可能有相同的類型����,也可能有不同的類型�����,例如票房排名第二的電影“Skyfall”,它的類型是“Action |Adventure |Thriller”�。
因此,我們首先需要做的是把每部電影所屬的類型逐一取出來���,然后將所有出現(xiàn)過的類型分別形成一個0-1啞變量�����,如果這部電影在某個類型上出現(xiàn)了�,則相應(yīng)變量的取值就是1�����,否則是0.
通過上面一步����,我們知道這個數(shù)據(jù)集中出現(xiàn)過的所有電影類型一共有11個�����。
那是不是按照之前所講的�,應(yīng)該把它轉(zhuǎn)換為10個啞變量呢?這里需要注意的是,所有的電影類型之間并不是互斥的(即有了action,就不能有其他的類型)�,所以我們無需因為共線性的原因去掉其中一個。
也就是說�,如果把每一個電影類型單獨作為一個獨立的變量,可以衍生出11個新的0-1變量�,這完全沒有問題。但11個變量未免有點過多�����,所以我們根據(jù)不同電影類型的頻數(shù)分布情況����,只把出現(xiàn)次數(shù)明顯較多的類型單獨拿出來,最終生成了6個0-1型變量�,分別為Adventure,F(xiàn)antasy��,Comedy��,Action�,Animation,Others���。
【MPAA評級】
對于這個分類型變量�����,我們首先可以看一下數(shù)據(jù)中它所包含的全部取值�����,發(fā)現(xiàn)一共有“PG”���,“PG-13”和“R”三個����。
和上面的電影類型(Genre)不同���,對于一部電影而言���,它只能有一個MPAA取值。因此����,在MPAA變量中����,我們需要選擇一個作為基準(zhǔn)���,將另外兩個構(gòu)造成啞變量。
例如���,我們以“PG”為基準(zhǔn)�����,構(gòu)造的兩個啞變量分別為PG13和R�,如果這兩個啞變量的取值同時為0����,那就相當(dāng)于電影的MPAA評級是PG。
【放映當(dāng)天是星期幾】
這個變量同MPAA評級一樣��,每部電影只能有一個取值��。
如果它在星期一到星期日上都有取值的話�,我們可以衍生出6個0-1型啞變量。
因為這里我們更關(guān)注周末和非周末對電影票房的影響��,而并不關(guān)注具體是哪一天��,所以我們將其進(jìn)一步概括成一個變量��,即“是否是周末”。
【放映時長和制作預(yù)算】
放映時長和制作預(yù)算這兩個變量都是取值大于0的數(shù)值型變量�,我們可以分別檢查它們的取值是否在合理的范圍內(nèi),然后直接保留它們的數(shù)值信息�����。
同時�����,對“制作預(yù)算”而言�����,假設(shè)我們這里關(guān)心的不是制作預(yù)算的具體數(shù)值��,而是“小成本電影”和“大成本電影”的票房差異�����,那我們就可以將這個數(shù)值型變量進(jìn)行分箱處理�,轉(zhuǎn)換為一個0-1型的分類變量,即 “是否為小成本電影”���。
在決定按照什么標(biāo)準(zhǔn)來劃分是否為小成本電影時�,我們根據(jù)之前文獻(xiàn)里的研究結(jié)果��,將制作預(yù)算在100 million以下的電影看成是小成本電影����。
上述所有變量的處理過程都可以使用R中最基本的語句(table,rep�,which等)完成,由于篇幅限制�����,小編這里就不列出詳細(xì)的code了��,大家感興趣的話���,可以閱讀狗熊會的“R語千尋”系列(戳這里)�����,相信會在R語言的學(xué)習(xí)上受到更多啟發(fā)���。
最后,我們將所有新生成的變量按照電影ID整合到一起��,就大功告成啦。
五�、總結(jié)
最后總結(jié)一下,小編在這次內(nèi)容中向大家介紹了拿到數(shù)據(jù)后的數(shù)據(jù)理解和預(yù)處理工作��,內(nèi)容雖然不難���,但同樣需要我們認(rèn)真對待���。就好像生活一樣,只有踏踏實實走好前面的路����,才有可能迎接后面的高潮迭起!
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330