數(shù)據(jù)分析技術:相關關系分析;說“你好我也好”,這不足夠
基礎準備
數(shù)據(jù)的相關性分析是生活中運用十分廣泛的一種數(shù)據(jù)分析方法�。例如���,在某個婦科產(chǎn)品的廣告里�,用“你好我也好”來表達用了產(chǎn)品就能健康的相關關系����;在朋友交往中,患難見真情幫助人們知道哪個才是真正親密的朋友��;過年走親戚��,用代際血緣的遠近來描述不同親戚之間的親密程度�。在數(shù)據(jù)分析領域��,對于不同變量之間相關關系的衡量指標也是不同的�����。
實際的生產(chǎn)生活中�,很多事物之間有著千絲萬縷的聯(lián)系���,這些聯(lián)系有的緊密,有的稀松����。表達互相聯(lián)系事物的依存情況有兩種方式:相關關系和回歸關系(函數(shù)關系)?��;貧w關系是一種確定關系��,通過一個或幾個事物的取值能夠得到另一個事物的取值���,這是通過回歸方程(函數(shù)方程)實現(xiàn)的。相關關系不是確定關系����,當一個或幾個事物的取值發(fā)生變化時,與它(它們)有聯(lián)系的事物的取值也會發(fā)生變化���,但變化值不是確定的數(shù)值����?�;谶@些區(qū)別,在數(shù)據(jù)分析中�,一般先做相關關系的分析,待相關關系清楚以后����,再進一步確定不同變量之間的函數(shù)關系(回歸關系)。
相關關系分類
相關關系從不同的角度有不同的分類方式�。首先是按照相關關系強度劃分:完全相關,弱相關和不相關���。也能按照相關關系的方向分類:正相關和負相關�。以上兩種是最常用的分類方式��。除此之外����,還有兩種分類方式���,需要重點介紹�。
按照相關關系形態(tài)劃分��,可以分為線性相關和非線性相關�����。當一個變量的值發(fā)生變化時,另外一個變量也發(fā)生大致相同的變化����。在直角坐標系里,兩個變量的觀測值的分布大致在一條直線上����,那么這兩個變量之間的相關關系是線性關系;如果在直角指標系內(nèi)�,兩個變量的觀測值分布是一條曲線,那么它們之間的相關關系是非線性相關���。
還有一種相關關系的劃分原則是按照變量的個數(shù)劃分���,可以分為單相關,復相關和偏相關�����。單相關是兩個變量之間的關系��,這兩個變量一個是因變量,一個是自變量�����。兩個變量的相關關系分析也被稱為二元變量相關分析�。復相關是指三個或三個以上的變量之間的關系,即一個因變量對兩個或兩個以上自變量的相關關系����。偏相關綜合了單相關和復相關的特點,當一個變量與多個變量相關�����,但是只關心其中一個因變量與自變量的關系�����,需要屏蔽其他因變量對自變量的影響��,這樣的相關關系就叫做偏相關。
相關分析
相關分析是將變量之間相關關系進行量化處理的過程,通過計算變量間的相關系數(shù)���,對兩個或兩個以上變量之間兩兩相關的強度進行量化描述��。量化描述的結果就是各種不同的相關系數(shù)����。
二元變量相關系數(shù)
二元變量的相關分析計算得到的是兩個變量之間的相關系數(shù)。具體而言����,兩個定距和定比變量間的相關性用Pearson(皮爾遜)相關系數(shù)來判定,這是參數(shù)檢驗的方法�����;兩個定序或定類變量間的相關性用Spearman等級相關系數(shù)和Kendall’s tau-b等級相關系數(shù)來判定����,這兩種方法屬于非參數(shù)檢驗。
Pearson簡單相關系數(shù)
皮爾遜簡單相關�����,也稱積差相關���。是以英國統(tǒng)計學家皮爾遜的名字命名的計算線性相關的方法�,用于對定距或定比變量的相關性探索���。皮爾遜相關系數(shù)的計算公式:
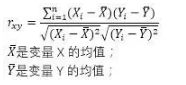
使用條件:
兩個變量都是由測量獲得的連續(xù)型數(shù)據(jù)�,即等距或等比數(shù)據(jù)。
兩個變量的總體都呈正態(tài)分布或接近正態(tài)分布����,,至少是單峰對稱分布���,當然樣本并不一定要正態(tài)���。
必須是成對的數(shù)據(jù),并且每對數(shù)據(jù)之間是相互獨立的��。
兩個變量之間呈線性關系����,一般用描繪散點圖的方式來觀察。
Spearman等級相關系數(shù)
Spearman相關系數(shù)是由英國統(tǒng)計學家Spearman在Pearson相關的基礎上剔除的等級相關系數(shù)的計算方法����,用于對定類或定序變量的相關性檢驗,可以看作是Pearson相關系數(shù)的非參數(shù)檢驗�����,因為它依據(jù)的是數(shù)據(jù)的秩而非數(shù)據(jù)的實際值。Spearman相關系數(shù)的取值范圍也是在-1到+1之間�,絕對值越大相關性越強�,正負號表示相關的方向。Spearman相關系數(shù)計算公式:

Spearman等級相關系數(shù)的特點:
如果兩變量正相關較強����,則它們秩變化同步,D值較小���,等級相關系數(shù)趨于1��;
如果兩變量負相關較強��,則它們秩變化相反�,D值較大���,等級相關系數(shù)趨于-1�����;
如果兩變量相關性弱�,它們秩變化互不影響�,D值趨于中間值����,等級相關系數(shù)趨于0���;
Kendall’s tau-b等級相關系數(shù)
和Spearman相關系數(shù)一樣��,Kendall’stau-b等級相關系數(shù)也是用于對定序變量的相關程度的度量����,也屬于非參數(shù)檢驗的范疇��。它利用變量秩數(shù)據(jù)來計算一致對數(shù)目U和非一致對數(shù)目V�����。當兩個變量具有較強的正相關關系時��,一致對數(shù)目U較大����,非一致對數(shù)目V較小��;當兩個變量具有較強的負相關關系時���,一致對數(shù)目U較小��,非一致對數(shù)目V較大�;當兩個變量相關性較弱時,一致對數(shù)目U和非一致對數(shù)目V大致相等��。Kendalltau-b相關系數(shù)定義為:

Kendall tau-b相關系數(shù)具有如下特點:
如果兩變量正相關性強����,秩變化同步�,則U應該較大,V應該較小�����,趨于1����;
如果兩變量負相關性強,秩變化相反�,則U應該較小,V應該較大����,趨于-1����;
如果相關關系弱���,則U����,V大致相等���,趨于0����;
偏相關分析系數(shù)
在實際生活中�����,一個事物的變化往往會受到多個事物的影響�,而非完全的二元相關關系,因此這就使得二元變量相關系數(shù)不能真真反映兩個變量間的線性相關程度�����。那么當兩個變量的取值受到其它變量影響時���,可以利用偏相關分析對其它變量進行控制�,以輸出控制其它變量影響后的相關系數(shù),這就是偏相關分析過程�����。
偏相關分析就是在分析兩個變量之間的線性相關關系時控制可能對其產(chǎn)生影響的變量����,以便于使分析結果更準確可靠���。偏相關分析也稱為凈相關分析��,分析依據(jù)是偏相關系數(shù)����。當有1個控制變量時�,偏相關系數(shù)稱為一階偏相關;當有兩個控制變量時����,偏相關系數(shù)稱為二階偏相關;當控制變量為0個時�,偏相關系數(shù)稱為零階偏相關�,也就是Pearson簡單相關系數(shù)��。
偏相關分析的零假設為:兩事物的偏相關系數(shù)與零無顯著差異����。假設分析中有3個變量x,y���,z����,在分析x與y的相關性時需要控制變量z��,那么x����,y之間的一階偏相關系數(shù)計算公式為:

其中,r是相應的偏相關系數(shù)����,n是樣本數(shù),k是控制變量的數(shù)目��,n-k-2是自由度。
距離相關分析
顯示生活中�,事物之間的關系往往錯綜復雜,設計的變量很多���,且它們代表的信息也非常繁雜���,我們通過觀察無法厘清這些變量及其觀測值之間的內(nèi)在關系,為了判別錯綜復雜的變量及其觀測值之間是否具有相似性�,是否屬于同一類別,通常采用更為復雜的分析手段���,距離相關分析��。
距離相關分析用于對不同個案間或同一變量的不同觀測值之間進行相似性或不相似性的測量��。距離相關分析的結果可為進一步的因子分析,聚類分析和多維尺度分析等提供信息�,以幫助了解復雜數(shù)據(jù)的內(nèi)在結構,為進一步分析打下基礎�,因此距離相關分析通常不單獨使用,所以其分析結果不會給出顯著性值����,而只是給出各個案或各觀測值之間的距離大小,再由研究者自行判斷其相似或不相似程度。
距離相關分析根據(jù)統(tǒng)計量的不同���,可分為兩種情況:
非相似性測量:計算個案或變量值之間的距離�。其數(shù)值越大����,表示相似性程度越弱。
相似性測量:計算個案或變量值之間的Pearson相關系數(shù)或Cosine相關�,取值范圍為-1~+1,其數(shù)值越大�����,表示相似程度越高�����。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330