從實戰(zhàn)角度解讀數(shù)據(jù)科學
在過去幾年里���,數(shù)據(jù)科學已經(jīng)被各行各業(yè)廣泛接納。數(shù)據(jù)科學起初在更大程度上來說是一個研究課題�����,源于科學家們?yōu)榱死斫馊祟愔悄?��、打造人工智能而做出的努力���。后來,事實證明它能帶來真正的商業(yè)價值����。
舉個例子��。Zalando公司是歐洲最大的時裝零售商之一�,就在大量地利用數(shù)據(jù)科學來提供數(shù)據(jù)驅(qū)動的推薦和其他功能��。在很多地方���,包括產(chǎn)品頁面�����、目錄頁面�����、廣告郵件和重定向頁面上��,都會為用戶提供“推薦”這樣的后端服務���。
生成推薦
有很多種方法可以生成數(shù)據(jù)驅(qū)動的推薦。協(xié)同過濾程序會收集整個用戶群在產(chǎn)品瀏覽�、愿望清單和購買等方面的用戶行為���,然后處理這些信息�,確定哪些商品擁有類似的用戶模式。這種方法的優(yōu)點在于計算機不必了解商品本身的任何信息����,缺點是必須要有龐大的流量,不然無法獲得關(guān)于商品的充足信息���。另一種方法只著眼于商品的各種屬性�,比如推薦同一品牌或者顏色相近的其他商品���。當然����,有很多途徑可以延伸使用這些方法或者把它們綜合運用起來���。

還有更簡單的一些方法���,基本只通過計數(shù)來生成推薦,但在實際操作上�,這類方法的復雜度幾乎沒有上限。例如���,就個性化推薦而言��,我們一直在研究對從各種角度對商品進行排序的機器學習排名方法��。上圖顯示的是用于優(yōu)化這一方法的成本函數(shù)�,主要是為了說明數(shù)據(jù)科學有時具有的復雜程度。該函數(shù)采用包含正則項的對偶加權(quán)排名指標��。雖然在數(shù)學上非常精確���,但也非常抽象��。這種方法不僅能用于電子商務領(lǐng)域的推薦���,還能用于解決各種各樣的排名問題,前提是排名對象具備適合的特征���。
把數(shù)學方法引入產(chǎn)業(yè)界
那么�����,如何將上面提到的這類非常正規(guī)的數(shù)學方法引入產(chǎn)品開發(fā)����?數(shù)據(jù)科學和工程之間又是怎樣對接的?哪種組織和團隊架構(gòu)最適合采用這種方法����?這些是非常重要且合理的問題�,因為它們決定了對一名數(shù)據(jù)科學家或者一整支數(shù)據(jù)科學家團隊的投資到最后是否真能取得回報。
在后文中�,我將根據(jù)我個人從事機器學習研究工作和在Zalando公司領(lǐng)導數(shù)支數(shù)據(jù)科學家和工程師團隊的實戰(zhàn)經(jīng)驗,對這些問題進行探討��。
了解數(shù)據(jù)科學和軟件開發(fā)的區(qū)別
讓我們先著眼于數(shù)據(jù)科學系統(tǒng)和后端開發(fā)系統(tǒng)����,看看如何才能把這兩個系統(tǒng)結(jié)合起來。
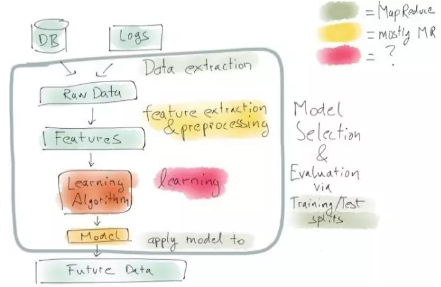
典型的數(shù)據(jù)科學工作流程如下:第一步永遠是找出問題�,然后收集相關(guān)數(shù)據(jù),可能來自于數(shù)據(jù)庫或者開發(fā)記錄�����。視你所在機構(gòu)的數(shù)據(jù)可用性而定�����,這可能就已經(jīng)非常困難了�����,你必須先弄清楚誰能讓你有權(quán)訪問那些數(shù)據(jù),然后弄清楚誰能確保你順利拿到那些數(shù)據(jù)���。得到數(shù)據(jù)后����,接著對其進行預處理��,提取數(shù)據(jù)特征���,以期獲取有用信息���,幫助解決問題。將這些特征輸入機器學習算法�����,再將得出的模型用測試數(shù)據(jù)進行評估�,以預測模型用于未來數(shù)據(jù)的效果。
這一管道通常會一次性建設完畢��,往往由數(shù)據(jù)科學家使用Python等編程語言����,手動完成各個步驟�。Python有很多的數(shù)據(jù)分析庫和數(shù)據(jù)可視化庫����。根據(jù)數(shù)據(jù)量的大小��,也可能使用Spark或Hadoop這樣的分布式計算系統(tǒng)�,但數(shù)據(jù)科學家往往先從數(shù)據(jù)的一個子集著手。
為什么先從小處著手���?
從小處著手的主要原因在于���,這個過程不是只進行一次,而是會迭代很多次�����。從本質(zhì)上來說�,數(shù)據(jù)科學項目本身是探究性的,所得結(jié)果在某種程度上是開放性的��。目標可能很明確�����,但在剛開始的時候,常常不知道哪些數(shù)據(jù)可用���,或者可用數(shù)據(jù)是否適合����。畢竟�����,選擇采用機器學習這種方法��,已經(jīng)意味著你不能妄想只靠編寫一套程序就能解決問題����。你必須采用一種數(shù)據(jù)驅(qū)動的方法。
這意味著該管道將會迭代和改進很多次���,嘗試不同的數(shù)據(jù)特征����、不同的預處理方式���、不同的機器學習算法���,甚至可能回到原點����,添加更多的數(shù)據(jù)源��。
整個過程本質(zhì)上是迭代的��,常常具有高度的探究性����。在模型表現(xiàn)看起來比較像樣后���,就該準備用現(xiàn)實數(shù)據(jù)來測試了�����。這時便輪到開發(fā)系統(tǒng)出場���。
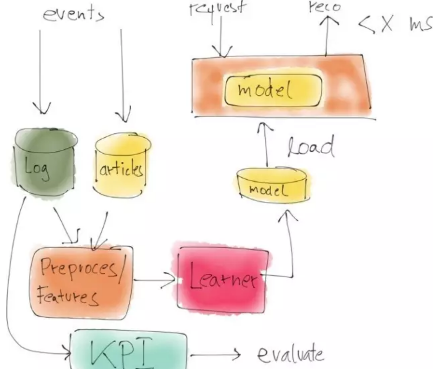
區(qū)分開發(fā)系統(tǒng)和數(shù)據(jù)科學
開發(fā)系統(tǒng)和數(shù)據(jù)科學系統(tǒng)之間的最主要區(qū)別可能在于,開發(fā)系統(tǒng)是持續(xù)運行的實時系統(tǒng)�。數(shù)據(jù)必須得到處理�,模型必須不斷更新�����。輸入事件也常常被用來計算點擊率等關(guān)鍵績效指標���。模型經(jīng)常每隔幾小時就使用可用數(shù)據(jù)重新訓練一次��,然后加載入開發(fā)系統(tǒng)中����,通過采用REST架構(gòu)的接口提供數(shù)據(jù)
出于性能和穩(wěn)定性的考慮����,那些系統(tǒng)常常用Java之類的編程語言編寫。
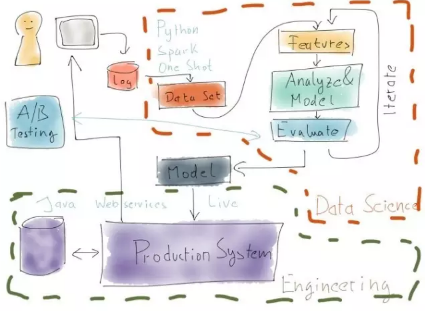
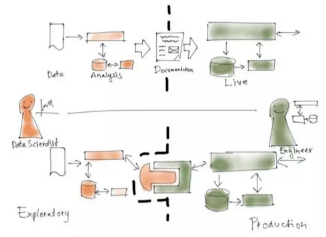
如果把開發(fā)系統(tǒng)和數(shù)據(jù)科學系統(tǒng)放在一起比較���,就會得出以上這張圖����。右上方是數(shù)據(jù)科學系統(tǒng)����,使用Python這樣的編程語言或者Spark這樣的分布式計算系統(tǒng)����,但通常包含手動觸發(fā)的一次性計算和為了優(yōu)化系統(tǒng)而進行的迭代�����。其結(jié)果是一個模型�,它本質(zhì)上就是一堆描述學習模型的數(shù)字。然后�����,開發(fā)系統(tǒng)會加載該模型����。開發(fā)系統(tǒng)會是一套更為傳統(tǒng)的的企業(yè)系統(tǒng)�,用Java這樣的語言編寫,并且保持持續(xù)運行���。
當然���,上圖有點簡化。實際上�����,模型必須反復訓練,因此還必須將某個版本的數(shù)據(jù)處理管道嵌入開發(fā)系統(tǒng)����,以便時不時地更新模型。
請注意圖中的A/B測試�,它會在實時系統(tǒng)中執(zhí)行,對應的是數(shù)據(jù)科學系統(tǒng)中的評估步驟����。通常來說,A/B測試和模型評估不完全具有可比性�����,因為在沒有真正把推薦商品顯示給用戶看的情況下�����,A/B測試很難模擬出線下推薦的效果�����,但A/B測試應該有助于模型性能的提升����。
最后要注意的是����,這整個系統(tǒng)不是建立后就“完事”����。如同必須先迭代和精調(diào)數(shù)據(jù)科學系統(tǒng)的數(shù)據(jù)分析管道一樣,整個實時系統(tǒng)也需要隨著數(shù)據(jù)分布情況的變化進行迭代��,并且為數(shù)據(jù)分析打開新的可能性��。我認為���,這種“外部迭代”既是最大的挑戰(zhàn)�,也是最重要的挑戰(zhàn)��,因為它將決定你能否持續(xù)改善系統(tǒng)�����,保證你最初對數(shù)據(jù)科學的投資不會付諸東流����。
數(shù)據(jù)科學家和開發(fā)人員:合作模式
到目前為止,我們主要討論了各系統(tǒng)在軟件開發(fā)中的典型情況�����。人們對開發(fā)系統(tǒng)真正能夠達成的穩(wěn)健度和高效性的期望高低不一���。有時�����,直接部署一套用Python編寫的模型就足夠了���,但探究部分和開發(fā)部分通常就此分道揚鑣。
如何協(xié)調(diào)數(shù)據(jù)科學家和開發(fā)人員之間的合作�����?這是一個重大的挑戰(zhàn)���。從某種程度上來說�����,“數(shù)據(jù)科學家”還是一個新職業(yè)���,但他們所做的工作明顯有別于開發(fā)人員所做的工作�����。這兩者很容易在溝通上存在誤解和障礙�。
數(shù)據(jù)科學家的工作通常具有高度的探究性�����。數(shù)據(jù)科學項目常常始于一個模糊的目標�,或者有關(guān)哪種數(shù)據(jù)和方法可用的設想。你往往只能試驗你的想法��,洞悉你的數(shù)據(jù)���。數(shù)據(jù)科學家會編寫大量代碼���,但其中很大一部分代碼都是為了測試想法,并不會直接用在最終的解決方案中���。
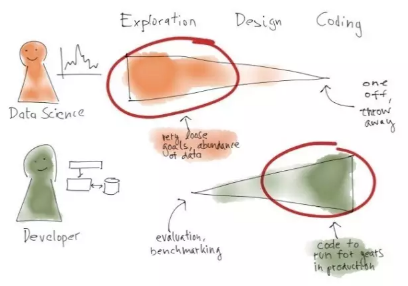
而開發(fā)人員把更多的精力用于編寫代碼。他們的目標就是編寫系統(tǒng),打造具有所需功能性的程序��。開發(fā)人員有時也從事探究性的工作��,比如原型建造��、概念驗證或者基準測試����,但他們的主要工作就是寫代碼。
這些不同之處也在代碼日漸開發(fā)出來的方式上表現(xiàn)得非常明顯���。開發(fā)人員常常盡量遵循一個明確定義的過程���,其中涉及為獨立的工作流創(chuàng)建分支程序,接著對各個分支進行檢查���,然后再并入主干�。開發(fā)人員可以并行工作�,但需要把已核準的分支集成到主干程序中,然后再從主干上建立新的分支��,如此往復�����。這一切是為了確保主干能以有序的方式完成開發(fā)。
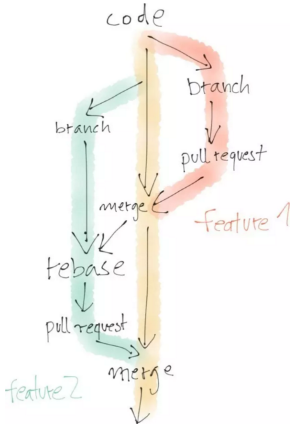
正如我上文所說��,數(shù)據(jù)科學家也會編寫大量代碼��,但這些代碼常常是為了探索和嘗試新的想法����。所以,你可能會先開發(fā)出一個1.0版��,但并不太符合你的預期����,接著便有了2.0版,進而產(chǎn)生2.1和2.2版�����。然后你放棄了這個方向�����,又做出了3.0和3.1版��。這時你意識到,如果把2.1版和3.1版的一些想法結(jié)合起來��,就能得到更好的解決方案����,因此有了3.3和3.4版�����,這便是最終的解決方案����。
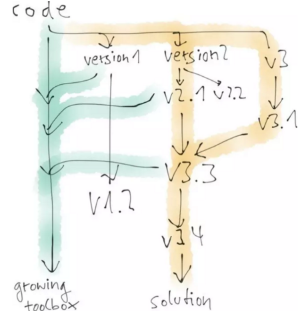
有意思的是,你會很想保留那些走進死胡同的版本���,因為以后你可能還會再用到它們���。你也可能會把其中一些令你滿意的成果加入一個日漸壯大的工具箱,它就像是你個人的機器學習庫��。開發(fā)人員喜歡刪除“死亡代碼”(也是因為他們知道以后隨時都能重新恢復那些代碼�,而且他們知道如何快速地做到這一點),而數(shù)據(jù)科學家則喜歡保留代碼����,以防萬一�。
在實踐中���,這兩個不同之處意味著開發(fā)人員和數(shù)據(jù)科學家在一起工作時常常會出問題����。標準的軟件工程實踐并不適合數(shù)據(jù)科學家的探究性工作模式�����,因為兩者致力于的目標不同�。代碼檢查和分支—檢查—整合這套有序的工作流程,在數(shù)據(jù)科學家這邊完全行不通�����,只會拖慢他們的進度�����。同理��,把探究性模式應用于開發(fā)系統(tǒng)也行不通�。
那么��,我們?nèi)绾巫寯?shù)據(jù)科學家和開發(fā)人員之間的合作對雙方都最有利�?第一反應可能是把二者分開�。例如,徹底分開代碼庫��,讓數(shù)據(jù)科學家獨立工作�,制定規(guī)范文檔�,然后由開發(fā)人員加以實現(xiàn)。這種方法可行��,但效率很低�����,而且容易出錯��,因為重新實現(xiàn)可能引入錯誤��,尤其是在開發(fā)人員不熟悉數(shù)據(jù)分析算法的情況下��。另外���,進行外部迭代以改善整個系統(tǒng)�,也取決于開發(fā)人員是否有足夠的能力來實現(xiàn)數(shù)據(jù)科學家的規(guī)范文檔。
幸好���,很多數(shù)據(jù)科學家也想成為更好的軟件工程師�����,很多軟件工程師也有心成為更好的數(shù)據(jù)科學家�。因此��,我們已經(jīng)開始嘗試更加直接一點�、有助于加快整個過程的合作模式。
例如����,數(shù)據(jù)科學家和開發(fā)人員的代碼庫仍然可以分開,但數(shù)據(jù)科學家可通過一個明確定義的接口�����,把他們的算法和一部分的開發(fā)系統(tǒng)鉤連起來��。顯然����,與開發(fā)系統(tǒng)進行通信的代碼必須遵守更嚴格的軟件開發(fā)實踐�����,但仍然由數(shù)據(jù)科學家負責�����。這樣一來���,他們不僅能在內(nèi)部迅速迭代��,還能在開發(fā)系統(tǒng)中迭代���。
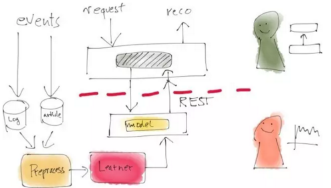
這種架構(gòu)模式的具體實現(xiàn)方式的一種�,便是采用微服務架構(gòu)��,并讓開發(fā)系統(tǒng)能夠查詢數(shù)據(jù)科學家的微服務以獲得建議����。這樣一來,原本被數(shù)據(jù)科學家用于離線分析的整個管道也能同時用于執(zhí)行A/B測試�����,甚至可在無需開發(fā)人員重新實現(xiàn)所有代碼的狀態(tài)下直接添加進開發(fā)系統(tǒng)。這也更強調(diào)數(shù)據(jù)科學家的軟件工程技能����,但我們發(fā)現(xiàn)擁有那套技能的數(shù)據(jù)科學家越來越多。為了反映這一事實�����,Zalando公司已經(jīng)把數(shù)據(jù)科學家的頭銜改為了“研究工程師(數(shù)據(jù)科學方向)”�。
依靠像這樣的方法,數(shù)據(jù)科學家能夠迅速行動��,用離線數(shù)據(jù)迭代���,遵從軟件開發(fā)的具體要求迭代��,整個團隊能把穩(wěn)定的數(shù)據(jù)分析解決方案逐漸移植到開發(fā)系統(tǒng)中���。
不斷適應和改進
到此為止,我已經(jīng)大致剖析了把數(shù)據(jù)科學引入軟件開發(fā)的典型架構(gòu)��。大家必須弄明白一個關(guān)鍵的概念�,那就是這類架構(gòu)需要不斷適應和改進(就像使用實時數(shù)據(jù)的所有數(shù)據(jù)驅(qū)動項目一樣)。能夠迅速迭代、嘗試新方法和在A/B測試中用實時數(shù)據(jù)測試結(jié)果�,這些是最重要的。
根據(jù)我的經(jīng)驗來看���,讓數(shù)據(jù)科學家和開發(fā)人員各自為政是無法做到這一點的�����。但同時�,必須承認他們的工作模式不同�,因為他們的目標不同:數(shù)據(jù)科學家的工作更具探究性,而開發(fā)人員更關(guān)注于打造軟件和系統(tǒng)���。如果讓雙方以一種最適合這些目標的方式工作����,并在他們之間定義一個明確的接口,就有可能把雙方結(jié)合在一起�,迅速地嘗試新方法。這要求數(shù)據(jù)科學家具備更多的軟件工程技能���,或者至少要有能夠架通兩個世界的工程師提供支持����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330