一、什么是數(shù)據(jù)分析����?
數(shù)據(jù)分析既是一門藝術(shù),所謂藝術(shù)就是結(jié)合技術(shù)�����、想象�����、經(jīng)驗(yàn)和意愿等綜合因素的平衡和融合��。數(shù)據(jù)分析的目的就是幫助我們把數(shù)據(jù)(Data)變成信息(Information)����,再從信息變成知識(shí)(Knowledge)�,最后從知識(shí)變成智慧(Wisdom)�����。
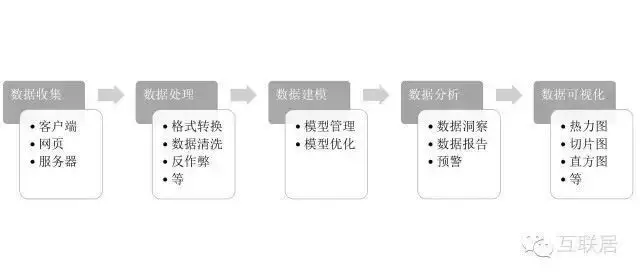 在數(shù)據(jù)分析的領(lǐng)域�����,商務(wù)智能(BI:Business Intelligence)���、數(shù)據(jù)挖掘(DM:Data Mining)、聯(lián)機(jī)分析處理(OLAP:On-Line Analytical Processing)等概念在名稱上和數(shù)據(jù)分析字面非常接近���,容易混淆���,如下做個(gè)簡單介紹。
· 商務(wù)智能(BI):商務(wù)智能是在商業(yè)數(shù)據(jù)上進(jìn)行價(jià)值挖掘的過程��,BI的歷史很長����,很多時(shí)候會(huì)特別指通過數(shù)據(jù)倉庫的技術(shù)進(jìn)行業(yè)務(wù)報(bào)表制作和分析的過程,分析方法上通常使用聚合(Aggregation)�、分片(Slice)等方式進(jìn)行數(shù)據(jù)處理。技術(shù)上�����,BI包括ETL(數(shù)據(jù)的抽取、轉(zhuǎn)換���、加載)��,數(shù)據(jù)倉庫(Data Warehouse)��,OLAP(聯(lián)機(jī)分析處理)����,數(shù)據(jù)挖掘(Data Mining)等技術(shù)�����。
· 數(shù)據(jù)挖掘:數(shù)據(jù)挖掘是指在大量數(shù)據(jù)中自動(dòng)搜索隱藏于其中的有著特殊關(guān)系性(屬于Association rule learning)的信息的過程����。相比商務(wù)智能,數(shù)據(jù)挖掘是一種更加學(xué)術(shù)的說法�����,范圍也廣��,深淺皆宜�,強(qiáng)調(diào)技術(shù)和方法。
· 聯(lián)機(jī)分析處理:聯(lián)機(jī)分析處理(OLAP)是一個(gè)建立數(shù)據(jù)系統(tǒng)的方法���,其核心思想即建立多維度的數(shù)據(jù)立方體�,以維度(Dimension)和度量(Measure)為基本概念�,輔以元數(shù)據(jù)實(shí)現(xiàn)可以鉆取(Drill-down/up)�����、切片(Slice)�����、切塊(Dice)等靈活��、系統(tǒng)和直觀的數(shù)據(jù)展現(xiàn)��。
在數(shù)據(jù)分析的領(lǐng)域�����,商務(wù)智能(BI:Business Intelligence)���、數(shù)據(jù)挖掘(DM:Data Mining)、聯(lián)機(jī)分析處理(OLAP:On-Line Analytical Processing)等概念在名稱上和數(shù)據(jù)分析字面非常接近���,容易混淆���,如下做個(gè)簡單介紹。
· 商務(wù)智能(BI):商務(wù)智能是在商業(yè)數(shù)據(jù)上進(jìn)行價(jià)值挖掘的過程��,BI的歷史很長����,很多時(shí)候會(huì)特別指通過數(shù)據(jù)倉庫的技術(shù)進(jìn)行業(yè)務(wù)報(bào)表制作和分析的過程,分析方法上通常使用聚合(Aggregation)�、分片(Slice)等方式進(jìn)行數(shù)據(jù)處理。技術(shù)上�����,BI包括ETL(數(shù)據(jù)的抽取、轉(zhuǎn)換���、加載)��,數(shù)據(jù)倉庫(Data Warehouse)��,OLAP(聯(lián)機(jī)分析處理)����,數(shù)據(jù)挖掘(Data Mining)等技術(shù)�����。
· 數(shù)據(jù)挖掘:數(shù)據(jù)挖掘是指在大量數(shù)據(jù)中自動(dòng)搜索隱藏于其中的有著特殊關(guān)系性(屬于Association rule learning)的信息的過程����。相比商務(wù)智能,數(shù)據(jù)挖掘是一種更加學(xué)術(shù)的說法�����,范圍也廣��,深淺皆宜�,強(qiáng)調(diào)技術(shù)和方法。
· 聯(lián)機(jī)分析處理:聯(lián)機(jī)分析處理(OLAP)是一個(gè)建立數(shù)據(jù)系統(tǒng)的方法���,其核心思想即建立多維度的數(shù)據(jù)立方體�,以維度(Dimension)和度量(Measure)為基本概念�,輔以元數(shù)據(jù)實(shí)現(xiàn)可以鉆取(Drill-down/up)�����、切片(Slice)�����、切塊(Dice)等靈活��、系統(tǒng)和直觀的數(shù)據(jù)展現(xiàn)��。
數(shù)據(jù)分析就是以業(yè)務(wù)為導(dǎo)向�,從數(shù)據(jù)中發(fā)掘提升業(yè)務(wù)能力的洞察。
二����、數(shù)據(jù)分析軟件的發(fā)展
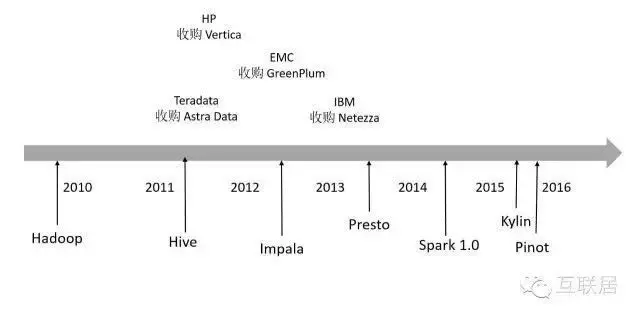
數(shù)據(jù)分析軟件市場(chǎng)從來都是活躍的市場(chǎng)��,從兩個(gè)視角來看����,一個(gè)是商業(yè)軟件市場(chǎng)�,充滿了大魚吃小魚的故事;另一個(gè)是開源數(shù)據(jù)存儲(chǔ)處理軟件�����,在互聯(lián)網(wǎng)精神和開源情懷的引導(dǎo)下�,各種專業(yè)領(lǐng)域的開源軟件日益壯大,通用數(shù)據(jù)存儲(chǔ)系統(tǒng)也不斷升級(jí)����。
舉例來說,2011年��,Teradata收購了Aster Data 公司�����, 同年惠普收購實(shí)時(shí)分析平臺(tái)Vertica等���;2012年����,EMC收購數(shù)據(jù)倉庫軟件廠商Greenplum�;2013年,IBM宣布以17億美元收購數(shù)據(jù)分析公司Netezza��;這些收購事件指向的是同一個(gè)目標(biāo)市場(chǎng)———大數(shù)據(jù)分析���。傳統(tǒng)的數(shù)據(jù)庫軟件�,處理TB級(jí)數(shù)據(jù)非常費(fèi)勁��,而這些新興的數(shù)據(jù)庫正式瞄準(zhǔn)TB級(jí)別���,乃至PB級(jí)別的數(shù)據(jù)分析���。
在開源世界,Hadoop將人們引入了大數(shù)據(jù)時(shí)代�,處理TB級(jí)別大數(shù)據(jù)成為一種可能,但實(shí)時(shí)性能一直是Hadoop的一個(gè)傷痛��。2014年��,Spark橫空出世,通過最大利用內(nèi)存處理數(shù)據(jù)的方式��,大大改進(jìn)了數(shù)據(jù)處理的響應(yīng)時(shí)間�����,快速發(fā)展出一個(gè)較為完備的生態(tài)系統(tǒng)���。另外�,大量日志數(shù)據(jù)都存放在HDFS中���,如何提高數(shù)據(jù)處理性能����,支持實(shí)時(shí)查詢功能則成為了不少開源數(shù)據(jù)軟件的核心目標(biāo)����。例如Hive利用MapReduce作為計(jì)算引擎,Presto自己開發(fā)計(jì)算引擎���,Druid使用自己開發(fā)索引和計(jì)算引擎等�,都是為了一個(gè)目標(biāo):處理更多數(shù)據(jù)����,獲取更高性能�����。
 三、數(shù)據(jù)分析軟件的分類
為了全面了解分類數(shù)據(jù)分析軟件�,我們按照以下幾個(gè)分類來介紹。
· 商業(yè)數(shù)據(jù)庫 開源時(shí)序數(shù)據(jù)庫
· 開源計(jì)算框架
· 開源數(shù)據(jù)分析軟件
· 開源SQL on Hadoop
三、數(shù)據(jù)分析軟件的分類
為了全面了解分類數(shù)據(jù)分析軟件�,我們按照以下幾個(gè)分類來介紹。
· 商業(yè)數(shù)據(jù)庫 開源時(shí)序數(shù)據(jù)庫
· 開源計(jì)算框架
· 開源數(shù)據(jù)分析軟件
· 開源SQL on Hadoop
· 云端數(shù)據(jù)分析SaaS
四�����、商業(yè)軟件
商用數(shù)據(jù)庫軟件種類繁多�����,但是真正能夠支持TB級(jí)別以上的數(shù)據(jù)存儲(chǔ)和分析并不太多�����,這里介紹幾個(gè)有特點(diǎn)的支持大數(shù)據(jù)的商用數(shù)據(jù)庫軟件�。
1.HP Vertica
Vertica公司成立于2005年,創(chuàng)立者為數(shù)據(jù)庫巨擘Michael Stonebraker(2014年圖靈獎(jiǎng)獲得者���,INGRES����,PostgreSQL,VoltDB等數(shù)據(jù)庫發(fā)明人)����。2011年Vertica被惠普收購。Vertica軟件是能提供高效數(shù)據(jù)存儲(chǔ)和快速查詢的列存儲(chǔ)數(shù)據(jù)庫實(shí)時(shí)分析平臺(tái)�����,還支持大規(guī)模并行處理(MPP)����。產(chǎn)品廣泛應(yīng)用于高端數(shù)字營銷、互聯(lián)網(wǎng)客戶(比如Facebook����、AOL、Twitter���、 Groupon)分析處理����,數(shù)據(jù)達(dá)到PB級(jí)���。Facebook利用Vertica進(jìn)行快速的用戶數(shù)據(jù)分析���,據(jù)稱Facebook超過300節(jié)點(diǎn)(Node)和處理超過6PB數(shù)據(jù)����。
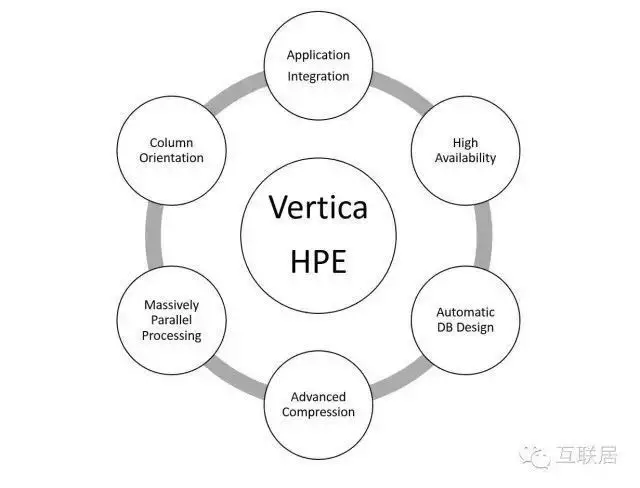
Vertica有以下幾個(gè)特點(diǎn):
· 面向列的存儲(chǔ)
· 靈活的壓縮算法��,根據(jù)數(shù)據(jù)的排序性和基數(shù)決定壓縮算法
· 高可用數(shù)據(jù)庫和查詢
· MPP架構(gòu)���,分布式存儲(chǔ)和任務(wù)負(fù)載,Share Nothing架構(gòu)
· 支持標(biāo)準(zhǔn)的SQL查詢�����,ODBC/JDBC等
· 支持Projection(數(shù)據(jù)投射)功能
 Vertica的Projection技術(shù)�,原理是將數(shù)據(jù)的某些列提取出來進(jìn)行專門的存儲(chǔ),以加快后期的訪問數(shù)據(jù)�����,同一個(gè)列可以在不同的Projection中���。
Vertica的Projection技術(shù)�,原理是將數(shù)據(jù)的某些列提取出來進(jìn)行專門的存儲(chǔ),以加快后期的訪問數(shù)據(jù)�����,同一個(gè)列可以在不同的Projection中���。

2.Oracle Exadata
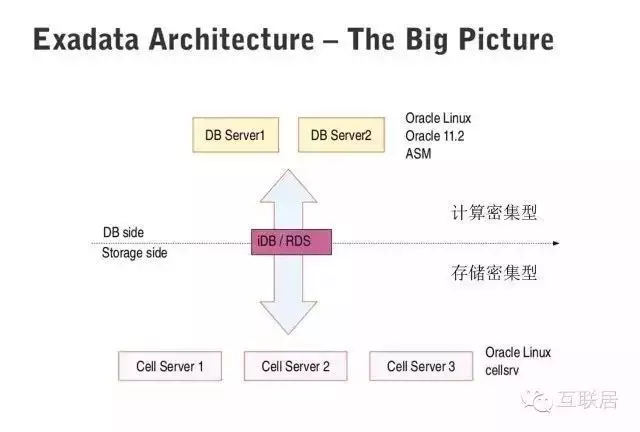
Oracle Exadata是數(shù)據(jù)庫發(fā)展史上一個(gè)傳奇����,它是數(shù)據(jù)庫軟件和最新硬件的完美結(jié)合。其提供最快最可靠的數(shù)據(jù)庫平臺(tái)����,不僅支持常規(guī)的數(shù)據(jù)庫應(yīng)用,也支持聯(lián)機(jī)分析處理(OLAP)和數(shù)據(jù)倉庫(DW)的場(chǎng)景����。
Exadata采用了多種最新的硬件技術(shù),例如40Gb/秒的InfiniBand網(wǎng)絡(luò)( InfiniBand 是超高速的專用數(shù)據(jù)網(wǎng)絡(luò)協(xié)議���,主要專用硬件支持)����,3.2TB PCI閃存卡(每個(gè)閃存卡都配有Exadata智能緩存�����,X6型號(hào))�。Oracle Exadata 數(shù)據(jù)庫云服務(wù)器允許將新一代服務(wù)器和存儲(chǔ)無縫部署到現(xiàn)有Oracle Exadata 數(shù)據(jù)庫云服務(wù)器中。它包含兩套子系統(tǒng)�,一套處理計(jì)算密集型的查詢,一套處理存儲(chǔ)密集型的查詢�,Exadata能夠做到智能查詢分配�����。
 Oracle Exadata有如下幾個(gè)技術(shù)特點(diǎn):
· 采用InfiniBand高速網(wǎng)絡(luò) 采用極速閃存方案�。+ 全面的Oracle數(shù)據(jù)庫兼容性�。
· 針對(duì)所有數(shù)據(jù)庫負(fù)載進(jìn)行了優(yōu)化,包括智能掃描�����。
· Oracle Exadata支持混合列壓縮���。
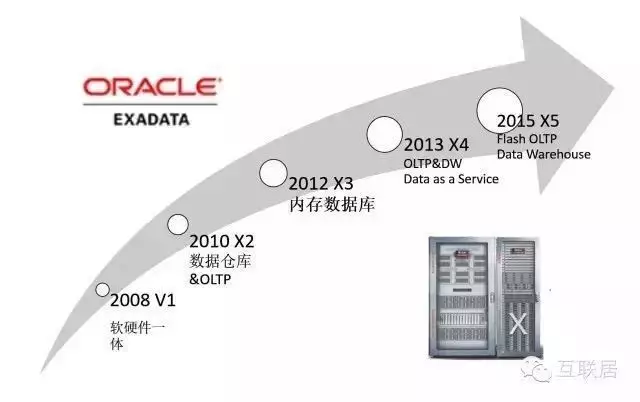
Oracle Exadata2008年推出,軟硬件一體�����,不斷發(fā)展壯大���,漸漸形成高性能數(shù)據(jù)庫的代名詞�����。
Oracle Exadata有如下幾個(gè)技術(shù)特點(diǎn):
· 采用InfiniBand高速網(wǎng)絡(luò) 采用極速閃存方案�。+ 全面的Oracle數(shù)據(jù)庫兼容性�。
· 針對(duì)所有數(shù)據(jù)庫負(fù)載進(jìn)行了優(yōu)化,包括智能掃描�����。
· Oracle Exadata支持混合列壓縮���。
Oracle Exadata2008年推出,軟硬件一體�����,不斷發(fā)展壯大���,漸漸形成高性能數(shù)據(jù)庫的代名詞�����。
 Oracle Exadata混合列存儲(chǔ)是介于行存儲(chǔ)和列存儲(chǔ)之間的一個(gè)方案�����,主要思想是對(duì)列進(jìn)行分段處理��,每一段都使用列式存儲(chǔ)放在Block中���,而后按照不同的壓縮策略處理�����。
3.Teredata
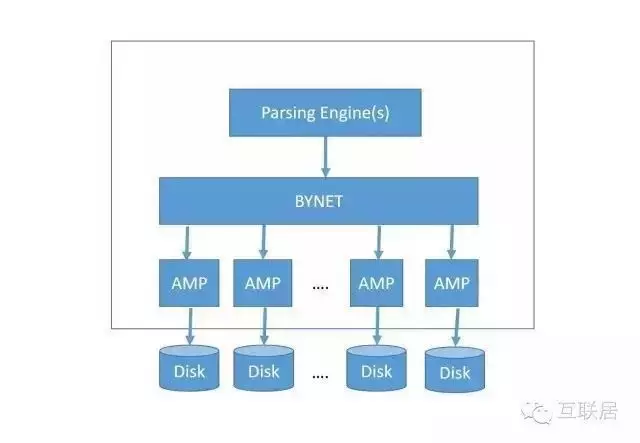
Teradata(天睿)公司專注于大數(shù)據(jù)分析�、數(shù)據(jù)倉庫和整合營銷管理解決方案的供應(yīng)商�。Teredata采用純粹的Share Nothing架構(gòu),支持MPP�。對(duì)于多維度的查詢更加靈活,專注與數(shù)據(jù)倉庫的應(yīng)用領(lǐng)域���。下面是TereData的架構(gòu)��,其中PE用于查詢的分析引擎����,分析SQL查詢�����,制定查詢計(jì)劃,聚合查詢結(jié)果等��;BYNET是一個(gè)高速的互聯(lián)層�,是一個(gè)軟件和硬件結(jié)合的解決方案����。
AMP(Access Module Processor)是存儲(chǔ)和查詢數(shù)據(jù)的節(jié)點(diǎn)����,支持排序和聚合等操作��。
Oracle Exadata混合列存儲(chǔ)是介于行存儲(chǔ)和列存儲(chǔ)之間的一個(gè)方案�����,主要思想是對(duì)列進(jìn)行分段處理��,每一段都使用列式存儲(chǔ)放在Block中���,而后按照不同的壓縮策略處理�����。
3.Teredata
Teradata(天睿)公司專注于大數(shù)據(jù)分析�、數(shù)據(jù)倉庫和整合營銷管理解決方案的供應(yīng)商�。Teredata采用純粹的Share Nothing架構(gòu),支持MPP�。對(duì)于多維度的查詢更加靈活,專注與數(shù)據(jù)倉庫的應(yīng)用領(lǐng)域���。下面是TereData的架構(gòu)��,其中PE用于查詢的分析引擎����,分析SQL查詢�����,制定查詢計(jì)劃,聚合查詢結(jié)果等��;BYNET是一個(gè)高速的互聯(lián)層�,是一個(gè)軟件和硬件結(jié)合的解決方案����。
AMP(Access Module Processor)是存儲(chǔ)和查詢數(shù)據(jù)的節(jié)點(diǎn)����,支持排序和聚合等操作��。
 另外Teredata還提出了一個(gè)統(tǒng)一的數(shù)據(jù)數(shù)據(jù)分析框架��,其中包括兩個(gè)核心產(chǎn)品�����,一個(gè)是Teredata數(shù)據(jù)倉庫�����,另外是一個(gè)Teredata Aster數(shù)據(jù)分析產(chǎn)品�����。這兩個(gè)產(chǎn)品分別走不同的路線:Teredata是傳統(tǒng)數(shù)據(jù)倉庫,滿足通用的數(shù)據(jù)需求�����,Aster實(shí)際上是一種基于MapReduce的數(shù)據(jù)分析解決方案,可以支持更加靈活的數(shù)據(jù)結(jié)構(gòu)的處理����,例如非結(jié)構(gòu)化數(shù)據(jù)的處理����。
另外Teredata還提出了一個(gè)統(tǒng)一的數(shù)據(jù)數(shù)據(jù)分析框架��,其中包括兩個(gè)核心產(chǎn)品�����,一個(gè)是Teredata數(shù)據(jù)倉庫�����,另外是一個(gè)Teredata Aster數(shù)據(jù)分析產(chǎn)品�����。這兩個(gè)產(chǎn)品分別走不同的路線:Teredata是傳統(tǒng)數(shù)據(jù)倉庫,滿足通用的數(shù)據(jù)需求�����,Aster實(shí)際上是一種基于MapReduce的數(shù)據(jù)分析解決方案,可以支持更加靈活的數(shù)據(jù)結(jié)構(gòu)的處理����,例如非結(jié)構(gòu)化數(shù)據(jù)的處理����。
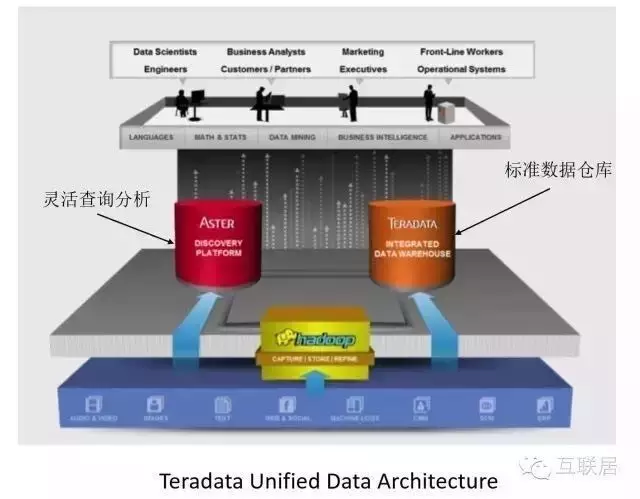 Teredata提供了一個(gè)完整的數(shù)據(jù)解決方案��,包括數(shù)據(jù)倉庫和MapReduce���。
五�����、時(shí)序數(shù)據(jù)庫
時(shí)序數(shù)據(jù)庫用于記錄在過去時(shí)間的各個(gè)數(shù)據(jù)點(diǎn)的信息�,典型的應(yīng)用是服務(wù)器的各種性能指標(biāo)����,例如CPU,內(nèi)存使用情況等等。目前也廣泛應(yīng)用于各種傳感器的數(shù)據(jù)收集分析工作,這些數(shù)據(jù)的收集都有一個(gè)特點(diǎn),對(duì)時(shí)間的依賴非常大,每天產(chǎn)生的數(shù)據(jù)量都非常大��,因此寫入的量非常大,一般的關(guān)系數(shù)據(jù)庫無法滿足這些場(chǎng)景�。因此時(shí)序數(shù)據(jù)庫����,在設(shè)計(jì)上需要支持高吞吐�,高效數(shù)據(jù)壓縮���,支持歷史查詢���,分布式部署等特點(diǎn)。
1.OpenTSDB
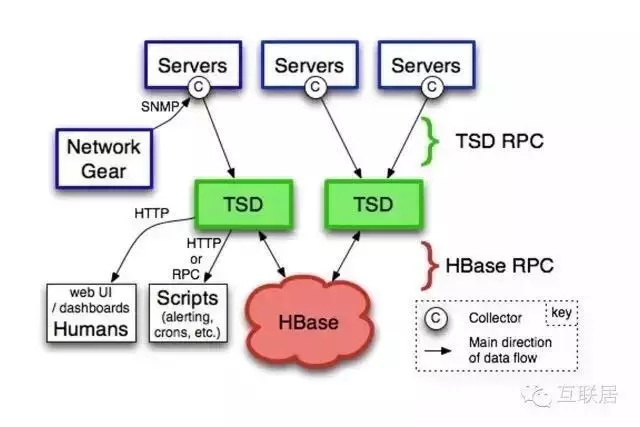
OpenTSDB是一個(gè)開源的時(shí)序數(shù)據(jù)庫����,支持存儲(chǔ)數(shù)千億的數(shù)據(jù)點(diǎn),并提供精確查詢功能��。它采用Java語言編寫���,通過基于HBase的存儲(chǔ)實(shí)現(xiàn)橫向擴(kuò)展��。它廣泛用于服務(wù)器性能的監(jiān)控和度量����,包括網(wǎng)絡(luò)和服務(wù)器����,傳感器�,IoT�����,金融數(shù)據(jù)的實(shí)時(shí)監(jiān)控領(lǐng)域�。OpenTSDB應(yīng)用于很多互聯(lián)網(wǎng)公司的運(yùn)維系統(tǒng),例如Pinterest公司有超過100個(gè)節(jié)點(diǎn)的部署��,Yahoo��!公司也有超過50節(jié)點(diǎn)的部署��。它的設(shè)計(jì)思路是利用HBase的Key存儲(chǔ)一些tag信息��,將同一個(gè)小時(shí)數(shù)據(jù)放在一行存儲(chǔ)����,方便查詢的速度。
Teredata提供了一個(gè)完整的數(shù)據(jù)解決方案��,包括數(shù)據(jù)倉庫和MapReduce���。
五�����、時(shí)序數(shù)據(jù)庫
時(shí)序數(shù)據(jù)庫用于記錄在過去時(shí)間的各個(gè)數(shù)據(jù)點(diǎn)的信息�,典型的應(yīng)用是服務(wù)器的各種性能指標(biāo)����,例如CPU,內(nèi)存使用情況等等。目前也廣泛應(yīng)用于各種傳感器的數(shù)據(jù)收集分析工作,這些數(shù)據(jù)的收集都有一個(gè)特點(diǎn),對(duì)時(shí)間的依賴非常大,每天產(chǎn)生的數(shù)據(jù)量都非常大��,因此寫入的量非常大,一般的關(guān)系數(shù)據(jù)庫無法滿足這些場(chǎng)景�。因此時(shí)序數(shù)據(jù)庫����,在設(shè)計(jì)上需要支持高吞吐�,高效數(shù)據(jù)壓縮���,支持歷史查詢���,分布式部署等特點(diǎn)。
1.OpenTSDB
OpenTSDB是一個(gè)開源的時(shí)序數(shù)據(jù)庫����,支持存儲(chǔ)數(shù)千億的數(shù)據(jù)點(diǎn),并提供精確查詢功能��。它采用Java語言編寫���,通過基于HBase的存儲(chǔ)實(shí)現(xiàn)橫向擴(kuò)展��。它廣泛用于服務(wù)器性能的監(jiān)控和度量����,包括網(wǎng)絡(luò)和服務(wù)器����,傳感器�,IoT�����,金融數(shù)據(jù)的實(shí)時(shí)監(jiān)控領(lǐng)域�。OpenTSDB應(yīng)用于很多互聯(lián)網(wǎng)公司的運(yùn)維系統(tǒng),例如Pinterest公司有超過100個(gè)節(jié)點(diǎn)的部署��,Yahoo��!公司也有超過50節(jié)點(diǎn)的部署��。它的設(shè)計(jì)思路是利用HBase的Key存儲(chǔ)一些tag信息��,將同一個(gè)小時(shí)數(shù)據(jù)放在一行存儲(chǔ)����,方便查詢的速度。
 2.InfluxDB
InfluxDB是最近非常流行的一個(gè)時(shí)序數(shù)據(jù)庫�����,由GoLang語言開發(fā)����,目前社區(qū)非?�;钴S���,它也是GoLang的一個(gè)非常成功的開源應(yīng)用���。其技術(shù)特點(diǎn)包括:支持任意數(shù)量的列��、支持方便強(qiáng)大的查詢語言��、集成了數(shù)據(jù)采集���、存儲(chǔ)和可視化功能。它支持高效存儲(chǔ)�����,使用高壓縮比的算法等�����。早期設(shè)計(jì)中����,存儲(chǔ)部分使用LevelDB為存儲(chǔ)�����,后來改成Time Series Merge Tree作為內(nèi)部存儲(chǔ)����,支持SQL類似的查詢語言�。
六、開源分布式計(jì)算平臺(tái)
1.Hadoop
Hadoop 是一個(gè)分布式系統(tǒng)基礎(chǔ)架構(gòu)�����,由Apache基金會(huì)開發(fā)�����。用戶可以在不了解分布式底層細(xì)節(jié)的情況下�����,開發(fā)分布式程序�����。充分利用集群的威力高速運(yùn)算和存儲(chǔ)。Hadoop實(shí)現(xiàn)了一個(gè)分布式文件系統(tǒng)(Hadoop Distributed File System)���,簡稱HDFS���。除了文件存儲(chǔ),Hadoop還有最完整的大數(shù)據(jù)生態(tài)���,包括機(jī)器管理、NoSQL KeyValue存儲(chǔ)(如HBase)�、協(xié)調(diào)服務(wù)(Zookeeper等)、SQL on Hadoop(Hive)等�����。
2.InfluxDB
InfluxDB是最近非常流行的一個(gè)時(shí)序數(shù)據(jù)庫�����,由GoLang語言開發(fā)����,目前社區(qū)非?�;钴S���,它也是GoLang的一個(gè)非常成功的開源應(yīng)用���。其技術(shù)特點(diǎn)包括:支持任意數(shù)量的列��、支持方便強(qiáng)大的查詢語言��、集成了數(shù)據(jù)采集���、存儲(chǔ)和可視化功能。它支持高效存儲(chǔ)�����,使用高壓縮比的算法等�����。早期設(shè)計(jì)中����,存儲(chǔ)部分使用LevelDB為存儲(chǔ)�����,后來改成Time Series Merge Tree作為內(nèi)部存儲(chǔ)����,支持SQL類似的查詢語言�。
六、開源分布式計(jì)算平臺(tái)
1.Hadoop
Hadoop 是一個(gè)分布式系統(tǒng)基礎(chǔ)架構(gòu)�����,由Apache基金會(huì)開發(fā)�����。用戶可以在不了解分布式底層細(xì)節(jié)的情況下�����,開發(fā)分布式程序�����。充分利用集群的威力高速運(yùn)算和存儲(chǔ)。Hadoop實(shí)現(xiàn)了一個(gè)分布式文件系統(tǒng)(Hadoop Distributed File System)���,簡稱HDFS���。除了文件存儲(chǔ),Hadoop還有最完整的大數(shù)據(jù)生態(tài)���,包括機(jī)器管理、NoSQL KeyValue存儲(chǔ)(如HBase)�、協(xié)調(diào)服務(wù)(Zookeeper等)、SQL on Hadoop(Hive)等�����。
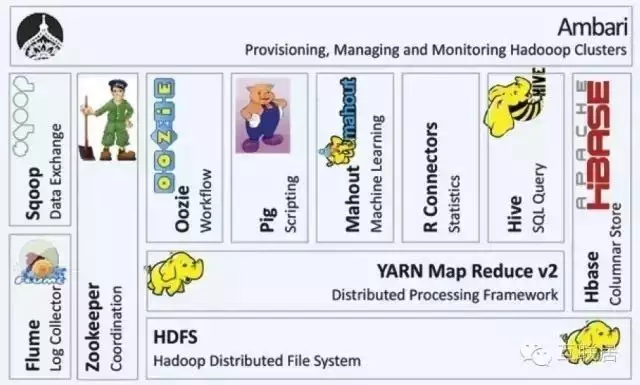 Hadoop基于可靠的分布式存儲(chǔ)��,通過MapReduce進(jìn)行迭代計(jì)算��,查詢批量的數(shù)據(jù)�。Hadoop是高吞吐的批處理系統(tǒng),適合大型任務(wù)的運(yùn)行��,但對(duì)任務(wù)響應(yīng)時(shí)間和實(shí)時(shí)性上有嚴(yán)格要求的需求方面Hadoop并不擅長����。
2.Spark
Spark是UC Berkeley AMP lab開源的類Hadoop MapReduce的通用的并行計(jì)算框架���,Spark同樣也是基于分布式計(jì)算,擁有Hadoop MapReduce的所有優(yōu)點(diǎn)���;不同的是Spark任務(wù)的中間計(jì)算結(jié)果可以緩存在內(nèi)存中�,這樣迭代計(jì)算時(shí)可從內(nèi)存直接獲取中間結(jié)果而不需要頻繁讀寫HDFS���,因此Spark運(yùn)行速度更快����,適用于對(duì)性能有要求的數(shù)據(jù)挖掘與數(shù)據(jù)分析的場(chǎng)景�����。
Hadoop基于可靠的分布式存儲(chǔ)��,通過MapReduce進(jìn)行迭代計(jì)算��,查詢批量的數(shù)據(jù)�。Hadoop是高吞吐的批處理系統(tǒng),適合大型任務(wù)的運(yùn)行��,但對(duì)任務(wù)響應(yīng)時(shí)間和實(shí)時(shí)性上有嚴(yán)格要求的需求方面Hadoop并不擅長����。
2.Spark
Spark是UC Berkeley AMP lab開源的類Hadoop MapReduce的通用的并行計(jì)算框架���,Spark同樣也是基于分布式計(jì)算,擁有Hadoop MapReduce的所有優(yōu)點(diǎn)���;不同的是Spark任務(wù)的中間計(jì)算結(jié)果可以緩存在內(nèi)存中�,這樣迭代計(jì)算時(shí)可從內(nèi)存直接獲取中間結(jié)果而不需要頻繁讀寫HDFS���,因此Spark運(yùn)行速度更快����,適用于對(duì)性能有要求的數(shù)據(jù)挖掘與數(shù)據(jù)分析的場(chǎng)景�����。
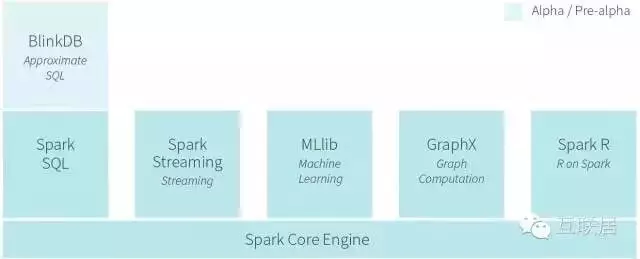 Spark是實(shí)現(xiàn)彈性的分布式數(shù)據(jù)集概念的計(jì)算集群系統(tǒng)���,可以看做商業(yè)分析平臺(tái)����。 RDDs能復(fù)用持久化到內(nèi)存中的數(shù)據(jù),從而為迭代算法提供更快的計(jì)算速度�����。這對(duì)一些工作流例如機(jī)器學(xué)習(xí)格外有用��,比如有些操作需要重復(fù)執(zhí)行很多次才能達(dá)到結(jié)果的最終收斂����。同時(shí),Spark也提供了大量的算法用來查詢和分析大量數(shù)據(jù)����,其開發(fā)語言采用scala,因此直接在上面做數(shù)據(jù)處理和分析�,開發(fā)成本會(huì)比較高�����,適合非結(jié)構(gòu)化的數(shù)據(jù)查詢處理���。
七�����、開源大數(shù)據(jù)實(shí)時(shí)分析數(shù)據(jù)庫
1.Druid
Druid是我非常喜歡的一個(gè)開源分析數(shù)據(jù)庫:簡單��,高效�����,穩(wěn)定����,支持大型數(shù)據(jù)集上進(jìn)行實(shí)時(shí)查詢的開源數(shù)據(jù)分析和存儲(chǔ)系統(tǒng)。它提供了低成本��,高性能�,高可靠性的解決方案,整個(gè)系統(tǒng)支持水平擴(kuò)展��,管理方便��。實(shí)際上�����,Druid的很多設(shè)計(jì)思想來源于Google的秘密分析武器PowerDrill����,從功能上�����,和Apache開源的Dremel也有幾分相似�����。
Druid被設(shè)計(jì)成支持PB級(jí)別數(shù)據(jù)量�����,現(xiàn)實(shí)中有數(shù)百TB級(jí)別的數(shù)據(jù)應(yīng)用實(shí)例����,每天處理數(shù)十億流式事件�。Druid廣泛應(yīng)用在互聯(lián)網(wǎng)公司中,例如阿里�,百度,騰訊�����,小米�����,愛奇藝��,優(yōu)酷等��,特別是用戶行為分析����,個(gè)性化推薦的數(shù)據(jù)分析,物聯(lián)網(wǎng)的實(shí)時(shí)數(shù)據(jù)分析����,互聯(lián)網(wǎng)廣告交易分析等領(lǐng)域。
從架構(gòu)上解釋����,Druid是一個(gè)典型的Lambda架構(gòu),分為實(shí)時(shí)數(shù)據(jù)流和批處理數(shù)據(jù)流���。全部節(jié)點(diǎn)使用MySQL管理MetaData�����,并且使用Zookeeper管理狀態(tài)等�����。
Spark是實(shí)現(xiàn)彈性的分布式數(shù)據(jù)集概念的計(jì)算集群系統(tǒng)���,可以看做商業(yè)分析平臺(tái)����。 RDDs能復(fù)用持久化到內(nèi)存中的數(shù)據(jù),從而為迭代算法提供更快的計(jì)算速度�����。這對(duì)一些工作流例如機(jī)器學(xué)習(xí)格外有用��,比如有些操作需要重復(fù)執(zhí)行很多次才能達(dá)到結(jié)果的最終收斂����。同時(shí),Spark也提供了大量的算法用來查詢和分析大量數(shù)據(jù)����,其開發(fā)語言采用scala,因此直接在上面做數(shù)據(jù)處理和分析�,開發(fā)成本會(huì)比較高�����,適合非結(jié)構(gòu)化的數(shù)據(jù)查詢處理���。
七�����、開源大數(shù)據(jù)實(shí)時(shí)分析數(shù)據(jù)庫
1.Druid
Druid是我非常喜歡的一個(gè)開源分析數(shù)據(jù)庫:簡單��,高效�����,穩(wěn)定����,支持大型數(shù)據(jù)集上進(jìn)行實(shí)時(shí)查詢的開源數(shù)據(jù)分析和存儲(chǔ)系統(tǒng)。它提供了低成本��,高性能�,高可靠性的解決方案,整個(gè)系統(tǒng)支持水平擴(kuò)展��,管理方便��。實(shí)際上�����,Druid的很多設(shè)計(jì)思想來源于Google的秘密分析武器PowerDrill����,從功能上�����,和Apache開源的Dremel也有幾分相似�����。
Druid被設(shè)計(jì)成支持PB級(jí)別數(shù)據(jù)量�����,現(xiàn)實(shí)中有數(shù)百TB級(jí)別的數(shù)據(jù)應(yīng)用實(shí)例����,每天處理數(shù)十億流式事件�。Druid廣泛應(yīng)用在互聯(lián)網(wǎng)公司中,例如阿里�,百度,騰訊�����,小米�����,愛奇藝��,優(yōu)酷等��,特別是用戶行為分析����,個(gè)性化推薦的數(shù)據(jù)分析,物聯(lián)網(wǎng)的實(shí)時(shí)數(shù)據(jù)分析����,互聯(lián)網(wǎng)廣告交易分析等領(lǐng)域。
從架構(gòu)上解釋����,Druid是一個(gè)典型的Lambda架構(gòu),分為實(shí)時(shí)數(shù)據(jù)流和批處理數(shù)據(jù)流���。全部節(jié)點(diǎn)使用MySQL管理MetaData�����,并且使用Zookeeper管理狀態(tài)等�����。
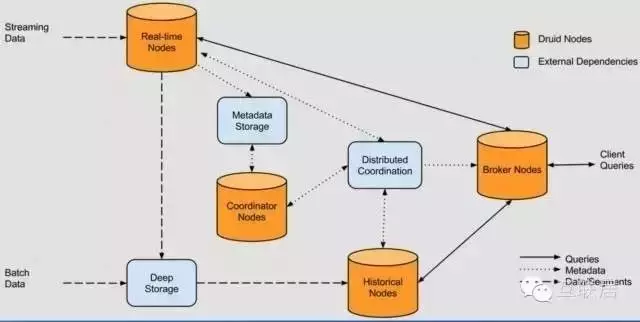 Druid的架構(gòu)圖顯示Druid自身包含以下四類節(jié)點(diǎn):
· 實(shí)時(shí)節(jié)點(diǎn)(Realtime Node):及時(shí)攝入實(shí)時(shí)數(shù)據(jù)�����,以及生成Segment數(shù)據(jù)文件�。
· 歷史節(jié)點(diǎn)(Historical Node):加載已生成好的數(shù)據(jù)文件以供數(shù)據(jù)查詢。
· 查詢節(jié)點(diǎn)(Broker Node):對(duì)外提供數(shù)據(jù)查詢服務(wù)��,并同時(shí)從實(shí)時(shí)節(jié)點(diǎn)與歷史節(jié)點(diǎn)查詢數(shù)據(jù)�、合并后返回給調(diào)用方。
· 協(xié)調(diào)節(jié)點(diǎn)(Coordinator Node):負(fù)責(zé)歷史節(jié)點(diǎn)的數(shù)據(jù)負(fù)載均衡��,以及通過Rules管理數(shù)據(jù)的生命周期�����。
同時(shí)��,集群還包含以下三類外部依賴:
· 元數(shù)據(jù)庫(Metastore):存儲(chǔ)Druid集群的原數(shù)據(jù)信息��,比如segment的相關(guān)信息��,一般用MySQL或PostgreSQL��。
· 分布式協(xié)調(diào)服務(wù)(Coordination):為Druid集群提供一致性協(xié)調(diào)服務(wù)的組件�,通常為Zookeeper。
· 數(shù)據(jù)文件存儲(chǔ)庫(DeepStorage):存放生成的Segment數(shù)據(jù)文件���,并供歷史節(jié)點(diǎn)下載���。
對(duì)于單節(jié)點(diǎn)集群來說可以是本地磁盤,而對(duì)于分布式集群一般來說是HDFS或NFS��。
從數(shù)據(jù)流轉(zhuǎn)的角度來看��,數(shù)據(jù)從架構(gòu)圖的左側(cè)進(jìn)入系統(tǒng)����,分為實(shí)時(shí)流數(shù)據(jù)與批量數(shù)據(jù)。實(shí)時(shí)流數(shù)據(jù)會(huì)被實(shí)時(shí)節(jié)點(diǎn)消費(fèi)�,然后實(shí)時(shí)節(jié)點(diǎn)將生成的Segment數(shù)據(jù)文件上傳到數(shù)據(jù)文件存儲(chǔ)庫;而批量數(shù)據(jù)經(jīng)過Druid集群消費(fèi)后(具體方法后面的章節(jié)會(huì)做介紹)會(huì)被直接上傳到數(shù)據(jù)文件存儲(chǔ)庫��。同時(shí)�,查詢節(jié)點(diǎn)會(huì)響應(yīng)外部的查詢請(qǐng)求,并將分別從實(shí)時(shí)節(jié)點(diǎn)與歷史節(jié)點(diǎn)查詢到的結(jié)果合并后返回���。
2.Pinot
如果要找一個(gè)與Druid最接近的系統(tǒng)�����,那么非LinkedIn Pinot莫屬�����。Pinot是Linkedin公司于2015年底開源的一個(gè)分布式列式數(shù)據(jù)存儲(chǔ)系統(tǒng)���。Linkedin在開源界頗有盛名��,大名鼎鼎的Kafka就是來源于LinkedIn��,因此Pinot在推出后就備受關(guān)注和追捧��。
Pinot的技術(shù)特點(diǎn)如下:
· 一個(gè)面向列式存儲(chǔ)的數(shù)據(jù)庫��,支持多種壓縮技術(shù)+ 可插入的索引技術(shù) – SortedIndex����、Bitmap Index�、Inverted Index
· 可以根據(jù)Query和Segment元數(shù)據(jù)進(jìn)行查詢和執(zhí)行計(jì)劃的優(yōu)化
· 從kafka的準(zhǔn)實(shí)時(shí)數(shù)據(jù)灌入和從hadoop的批量數(shù)據(jù)灌入
· 類似于SQL的查詢語言和各種常用聚合
· 支持多值字段
· 水平擴(kuò)展和容錯(cuò)
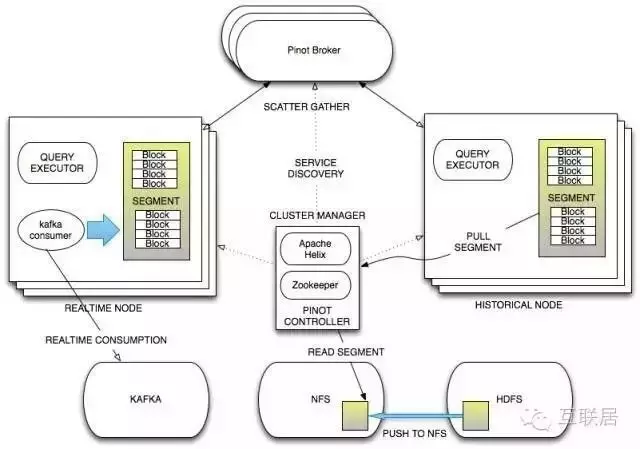
在架構(gòu)上,Pinot也采用了Lambda的架構(gòu)�����,將實(shí)時(shí)數(shù)據(jù)流和批處理數(shù)據(jù)分開處理。其中Realtime Node 處理實(shí)時(shí)數(shù)據(jù)查詢����,Historical Nodes處理歷史數(shù)據(jù)���。
Druid的架構(gòu)圖顯示Druid自身包含以下四類節(jié)點(diǎn):
· 實(shí)時(shí)節(jié)點(diǎn)(Realtime Node):及時(shí)攝入實(shí)時(shí)數(shù)據(jù)�����,以及生成Segment數(shù)據(jù)文件�。
· 歷史節(jié)點(diǎn)(Historical Node):加載已生成好的數(shù)據(jù)文件以供數(shù)據(jù)查詢。
· 查詢節(jié)點(diǎn)(Broker Node):對(duì)外提供數(shù)據(jù)查詢服務(wù)��,并同時(shí)從實(shí)時(shí)節(jié)點(diǎn)與歷史節(jié)點(diǎn)查詢數(shù)據(jù)�、合并后返回給調(diào)用方。
· 協(xié)調(diào)節(jié)點(diǎn)(Coordinator Node):負(fù)責(zé)歷史節(jié)點(diǎn)的數(shù)據(jù)負(fù)載均衡��,以及通過Rules管理數(shù)據(jù)的生命周期�����。
同時(shí)��,集群還包含以下三類外部依賴:
· 元數(shù)據(jù)庫(Metastore):存儲(chǔ)Druid集群的原數(shù)據(jù)信息��,比如segment的相關(guān)信息��,一般用MySQL或PostgreSQL��。
· 分布式協(xié)調(diào)服務(wù)(Coordination):為Druid集群提供一致性協(xié)調(diào)服務(wù)的組件�,通常為Zookeeper。
· 數(shù)據(jù)文件存儲(chǔ)庫(DeepStorage):存放生成的Segment數(shù)據(jù)文件���,并供歷史節(jié)點(diǎn)下載���。
對(duì)于單節(jié)點(diǎn)集群來說可以是本地磁盤,而對(duì)于分布式集群一般來說是HDFS或NFS��。
從數(shù)據(jù)流轉(zhuǎn)的角度來看��,數(shù)據(jù)從架構(gòu)圖的左側(cè)進(jìn)入系統(tǒng)����,分為實(shí)時(shí)流數(shù)據(jù)與批量數(shù)據(jù)。實(shí)時(shí)流數(shù)據(jù)會(huì)被實(shí)時(shí)節(jié)點(diǎn)消費(fèi)�,然后實(shí)時(shí)節(jié)點(diǎn)將生成的Segment數(shù)據(jù)文件上傳到數(shù)據(jù)文件存儲(chǔ)庫;而批量數(shù)據(jù)經(jīng)過Druid集群消費(fèi)后(具體方法后面的章節(jié)會(huì)做介紹)會(huì)被直接上傳到數(shù)據(jù)文件存儲(chǔ)庫��。同時(shí)�,查詢節(jié)點(diǎn)會(huì)響應(yīng)外部的查詢請(qǐng)求,并將分別從實(shí)時(shí)節(jié)點(diǎn)與歷史節(jié)點(diǎn)查詢到的結(jié)果合并后返回���。
2.Pinot
如果要找一個(gè)與Druid最接近的系統(tǒng)�����,那么非LinkedIn Pinot莫屬�����。Pinot是Linkedin公司于2015年底開源的一個(gè)分布式列式數(shù)據(jù)存儲(chǔ)系統(tǒng)���。Linkedin在開源界頗有盛名��,大名鼎鼎的Kafka就是來源于LinkedIn��,因此Pinot在推出后就備受關(guān)注和追捧��。
Pinot的技術(shù)特點(diǎn)如下:
· 一個(gè)面向列式存儲(chǔ)的數(shù)據(jù)庫��,支持多種壓縮技術(shù)+ 可插入的索引技術(shù) – SortedIndex����、Bitmap Index�、Inverted Index
· 可以根據(jù)Query和Segment元數(shù)據(jù)進(jìn)行查詢和執(zhí)行計(jì)劃的優(yōu)化
· 從kafka的準(zhǔn)實(shí)時(shí)數(shù)據(jù)灌入和從hadoop的批量數(shù)據(jù)灌入
· 類似于SQL的查詢語言和各種常用聚合
· 支持多值字段
· 水平擴(kuò)展和容錯(cuò)
在架構(gòu)上,Pinot也采用了Lambda的架構(gòu)�����,將實(shí)時(shí)數(shù)據(jù)流和批處理數(shù)據(jù)分開處理。其中Realtime Node 處理實(shí)時(shí)數(shù)據(jù)查詢����,Historical Nodes處理歷史數(shù)據(jù)���。
 3.Kylin
Kylin是一個(gè)Apache開源的分布式分析引擎���,提供了Hadoop之上的SQL查詢接口及多維分析(OLAP)能力,可以支持超大規(guī)模數(shù)據(jù)�����。最初由eBay公司開發(fā)并于2015年貢獻(xiàn)至開源社區(qū)�。它能在亞秒內(nèi)查詢巨大的Hive表。
Kylin的優(yōu)勢(shì)很明顯�,它支持標(biāo)準(zhǔn)的ANSI SQL接口,可以復(fù)用很多傳統(tǒng)的數(shù)據(jù)集成系統(tǒng)����,支持標(biāo)準(zhǔn)的OLAP Cube,數(shù)據(jù)查詢更加方便����,與大量BI工具無縫整合。另外它提供很多管理功能,例如Web管理����,訪問控制,支持LDAP�,支持HyperLoglog的近似算法。
從技術(shù)上理解�,Kylin在Hadoop Hive表上做了一層緩存,通過預(yù)計(jì)算和定期任務(wù)����,把很多數(shù)據(jù)事先存儲(chǔ)在HBase為基礎(chǔ)的OLAP Cube中,大部分查詢可以直接訪問HBase拿到結(jié)果��,而不需訪問Hive原始數(shù)據(jù)�。雖然數(shù)據(jù)緩存、預(yù)計(jì)算可以提高查詢效率�,另外一個(gè)方面,這種方式的缺點(diǎn)也很明顯��,查詢?nèi)狈`活性���,需要預(yù)先定義好查詢的一些模式�����,一些表結(jié)構(gòu)���。目前�����,Kylin缺少實(shí)時(shí)數(shù)據(jù)注入的能力。Druid使用Bitmap Index作為統(tǒng)一的內(nèi)部數(shù)據(jù)結(jié)構(gòu)���;Kylin使用Bitmap Index作為實(shí)時(shí)處理部分的數(shù)據(jù)結(jié)構(gòu)��,而使用MOLAP Cube為歷史數(shù)據(jù)的數(shù)據(jù)結(jié)構(gòu)�����。
3.Kylin
Kylin是一個(gè)Apache開源的分布式分析引擎���,提供了Hadoop之上的SQL查詢接口及多維分析(OLAP)能力,可以支持超大規(guī)模數(shù)據(jù)�����。最初由eBay公司開發(fā)并于2015年貢獻(xiàn)至開源社區(qū)�。它能在亞秒內(nèi)查詢巨大的Hive表。
Kylin的優(yōu)勢(shì)很明顯�,它支持標(biāo)準(zhǔn)的ANSI SQL接口,可以復(fù)用很多傳統(tǒng)的數(shù)據(jù)集成系統(tǒng)����,支持標(biāo)準(zhǔn)的OLAP Cube,數(shù)據(jù)查詢更加方便����,與大量BI工具無縫整合。另外它提供很多管理功能,例如Web管理����,訪問控制,支持LDAP�,支持HyperLoglog的近似算法。
從技術(shù)上理解�,Kylin在Hadoop Hive表上做了一層緩存,通過預(yù)計(jì)算和定期任務(wù)����,把很多數(shù)據(jù)事先存儲(chǔ)在HBase為基礎(chǔ)的OLAP Cube中,大部分查詢可以直接訪問HBase拿到結(jié)果��,而不需訪問Hive原始數(shù)據(jù)�。雖然數(shù)據(jù)緩存、預(yù)計(jì)算可以提高查詢效率�,另外一個(gè)方面,這種方式的缺點(diǎn)也很明顯��,查詢?nèi)狈`活性���,需要預(yù)先定義好查詢的一些模式�����,一些表結(jié)構(gòu)���。目前�����,Kylin缺少實(shí)時(shí)數(shù)據(jù)注入的能力。Druid使用Bitmap Index作為統(tǒng)一的內(nèi)部數(shù)據(jù)結(jié)構(gòu)���;Kylin使用Bitmap Index作為實(shí)時(shí)處理部分的數(shù)據(jù)結(jié)構(gòu)��,而使用MOLAP Cube為歷史數(shù)據(jù)的數(shù)據(jù)結(jié)構(gòu)�����。
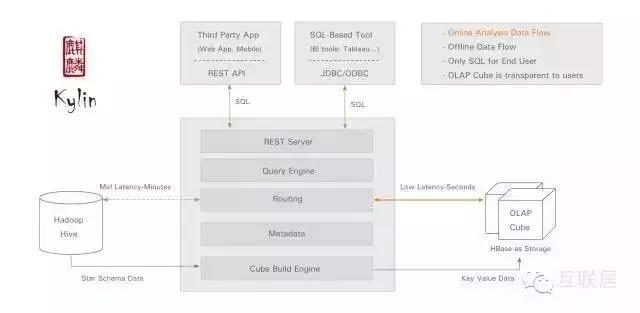 另外����,Kylin開發(fā)成員中很多開發(fā)人員來自中國����,因此PMC成員中,中國人占了大部分�,所以使用Kylin很容易得到很好的中文支持。Kylin的愿景就是創(chuàng)建一個(gè)分布式的高可擴(kuò)展的OLAP引擎。
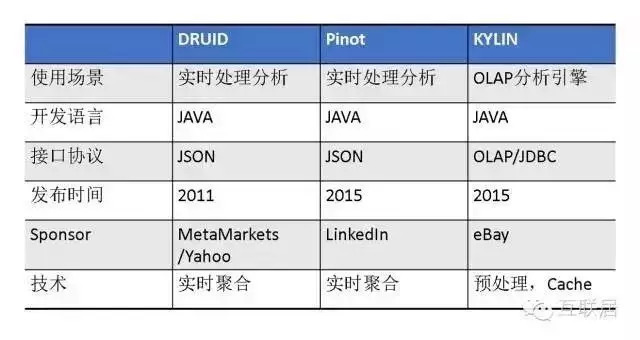
4.Druid����、Pinot和Kylin比較
Druid,Pinot和Kylin是數(shù)據(jù)分析軟件選型經(jīng)常碰到的問題���。Druid和Pinot解決的業(yè)務(wù)問題非常類似�����。Pinot架構(gòu)設(shè)計(jì)比較規(guī)范��,系統(tǒng)也比較復(fù)雜一些�����,由于開源時(shí)間短��,社區(qū)的支持力度弱于Druid����。Druid的設(shè)計(jì)輕巧����,代碼庫也比較容易懂���,支持比較靈活的功能增強(qiáng)。Kylin的最大優(yōu)勢(shì)是支持SQL訪問��,可以兼容傳統(tǒng)的BI工具和報(bào)表系統(tǒng)����,性能上沒有太大優(yōu)勢(shì)。
下面是這幾個(gè)軟件的簡單比較:
另外����,Kylin開發(fā)成員中很多開發(fā)人員來自中國����,因此PMC成員中,中國人占了大部分�,所以使用Kylin很容易得到很好的中文支持。Kylin的愿景就是創(chuàng)建一個(gè)分布式的高可擴(kuò)展的OLAP引擎。
4.Druid����、Pinot和Kylin比較
Druid,Pinot和Kylin是數(shù)據(jù)分析軟件選型經(jīng)常碰到的問題���。Druid和Pinot解決的業(yè)務(wù)問題非常類似�����。Pinot架構(gòu)設(shè)計(jì)比較規(guī)范��,系統(tǒng)也比較復(fù)雜一些�����,由于開源時(shí)間短��,社區(qū)的支持力度弱于Druid����。Druid的設(shè)計(jì)輕巧����,代碼庫也比較容易懂���,支持比較靈活的功能增強(qiáng)。Kylin的最大優(yōu)勢(shì)是支持SQL訪問��,可以兼容傳統(tǒng)的BI工具和報(bào)表系統(tǒng)����,性能上沒有太大優(yōu)勢(shì)。
下面是這幾個(gè)軟件的簡單比較:
 5.神秘的Google Dremel
Dremel 是Google 的“交互式”數(shù)據(jù)分析系統(tǒng)���?����?梢越M建成規(guī)模上千的集群,處理PB級(jí)別的數(shù)據(jù)��。由于Map Reduce的實(shí)時(shí)性缺陷�����,Google開發(fā)了Dremel將處理時(shí)間縮短到秒級(jí)��,作為Map Reduce的有力補(bǔ)充�。Dremel作為Google BigQuery的Report引擎��,獲得了很大的成功�。
Dremel 支持上千臺(tái)機(jī)器的集群部署����,處理PB級(jí)別的數(shù)據(jù),可以對(duì)于網(wǎng)狀數(shù)據(jù)的只讀數(shù)據(jù)����,進(jìn)行隨機(jī)查詢?cè)L問,幫助數(shù)據(jù)分析師提供Ad Hoc查詢功能����,進(jìn)行深度的數(shù)據(jù)探索(Exploration)。Google開發(fā)了Dremel將處理時(shí)間縮短到秒級(jí)�����,它也成為Map Reduce的一個(gè)有利補(bǔ)充�����。Dremel也應(yīng)用在Google Big Query的Report引擎����,也非常成功����。Dremel的應(yīng)用如下��。
· 抓取的網(wǎng)頁文檔的分析��,主要是一些元數(shù)據(jù)+ 追蹤Android市場(chǎng)的所有安裝數(shù)據(jù)
· 谷歌產(chǎn)品的Crash報(bào)告
· 作弊(Spam)分析
· 谷歌分布式構(gòu)建(Build)系統(tǒng)中的測(cè)試結(jié)果
· 上千萬的磁盤 I/O 分析
· 谷歌數(shù)據(jù)中心中任務(wù)的資源分析
· 谷歌代碼庫中的Symbols和依賴分析
· 其他
Google公開的論文《Dremel: Interactive Analysis of WebScaleDatasets》���,總體介紹了一下Dremel的設(shè)計(jì)原理��。論文寫于2006年���,公開于2010年,Dremel為了支持Nested Data��,做了很多設(shè)計(jì)的優(yōu)化和權(quán)衡�����。
Dremel系統(tǒng)有以下幾個(gè)主要技術(shù)特點(diǎn):
· Dremel是一個(gè)大規(guī)模高并發(fā)系統(tǒng)����。舉例來說��,磁盤的順序讀速度在100MB/s上下,那么在1s內(nèi)處理1TB數(shù)據(jù)�,意味著至少需要有1萬個(gè)磁盤的并發(fā)讀,在如此大量的讀寫���,需要復(fù)雜的容錯(cuò)設(shè)計(jì)���,少量節(jié)點(diǎn)的讀失敗(或慢操作)不能影響整體操作�����。
· Dremel支持嵌套的數(shù)據(jù)結(jié)構(gòu)���。互聯(lián)網(wǎng)數(shù)據(jù)常常是非關(guān)系型的����。Dremel還支持靈活的數(shù)據(jù)模型�����,一種嵌套(Nested)的數(shù)據(jù)模型����,類似于Protocol Buffer定義的數(shù)據(jù)結(jié)構(gòu)����。Dremel采用列式方法存儲(chǔ)這些數(shù)據(jù)���,由于嵌套數(shù)據(jù)結(jié)構(gòu)����,Dremel引入了一種樹狀的列式存儲(chǔ)結(jié)構(gòu)���,方便嵌套數(shù)據(jù)的查詢����。論文詳細(xì)解釋了嵌套數(shù)據(jù)類型的列存儲(chǔ)�����,這個(gè)特性是Druid缺少的�,實(shí)現(xiàn)也是非常復(fù)雜的���。
· Dremel采用層級(jí)的執(zhí)行引擎�����。Dremel在執(zhí)行過程中��,SQL查詢輸入會(huì)轉(zhuǎn)化成執(zhí)行計(jì)劃�����,并發(fā)處理數(shù)據(jù)�。和MapReduce一樣,Dremel也需要和數(shù)據(jù)運(yùn)行在一起�,將計(jì)算移動(dòng)到數(shù)據(jù)上面。所以它需要GFS這樣的文件系統(tǒng)作為存儲(chǔ)層�����。在設(shè)計(jì)之初�����,Dremel并非是MapReduce的替代品��,它只是可以執(zhí)行非?���?斓姆治觯谑褂玫臅r(shí)候,常常用它來處理MapReduce的結(jié)果集或者用來建立分析原型�。
在使用Dremel時(shí),工程師需要通過Map Reduce將數(shù)據(jù)導(dǎo)入到Dremel��,可以通過定期的MapReduce的定時(shí)任務(wù)完成導(dǎo)入�����。在數(shù)據(jù)的實(shí)時(shí)性方面��,論文并沒有討論太多�����。
6.Apache Drill
Apache Drill 通過開源方式實(shí)現(xiàn)了 Google’s Dremel���。Apache Drill的架構(gòu)����,整個(gè)思想還是通過優(yōu)化查詢引擎�����,進(jìn)行快速全表掃描�,以快速返回結(jié)果�����。
5.神秘的Google Dremel
Dremel 是Google 的“交互式”數(shù)據(jù)分析系統(tǒng)���?����?梢越M建成規(guī)模上千的集群,處理PB級(jí)別的數(shù)據(jù)��。由于Map Reduce的實(shí)時(shí)性缺陷�����,Google開發(fā)了Dremel將處理時(shí)間縮短到秒級(jí)��,作為Map Reduce的有力補(bǔ)充�。Dremel作為Google BigQuery的Report引擎��,獲得了很大的成功�。
Dremel 支持上千臺(tái)機(jī)器的集群部署����,處理PB級(jí)別的數(shù)據(jù),可以對(duì)于網(wǎng)狀數(shù)據(jù)的只讀數(shù)據(jù)����,進(jìn)行隨機(jī)查詢?cè)L問,幫助數(shù)據(jù)分析師提供Ad Hoc查詢功能����,進(jìn)行深度的數(shù)據(jù)探索(Exploration)。Google開發(fā)了Dremel將處理時(shí)間縮短到秒級(jí)�����,它也成為Map Reduce的一個(gè)有利補(bǔ)充�����。Dremel也應(yīng)用在Google Big Query的Report引擎����,也非常成功����。Dremel的應(yīng)用如下��。
· 抓取的網(wǎng)頁文檔的分析��,主要是一些元數(shù)據(jù)+ 追蹤Android市場(chǎng)的所有安裝數(shù)據(jù)
· 谷歌產(chǎn)品的Crash報(bào)告
· 作弊(Spam)分析
· 谷歌分布式構(gòu)建(Build)系統(tǒng)中的測(cè)試結(jié)果
· 上千萬的磁盤 I/O 分析
· 谷歌數(shù)據(jù)中心中任務(wù)的資源分析
· 谷歌代碼庫中的Symbols和依賴分析
· 其他
Google公開的論文《Dremel: Interactive Analysis of WebScaleDatasets》���,總體介紹了一下Dremel的設(shè)計(jì)原理��。論文寫于2006年���,公開于2010年,Dremel為了支持Nested Data��,做了很多設(shè)計(jì)的優(yōu)化和權(quán)衡�����。
Dremel系統(tǒng)有以下幾個(gè)主要技術(shù)特點(diǎn):
· Dremel是一個(gè)大規(guī)模高并發(fā)系統(tǒng)����。舉例來說��,磁盤的順序讀速度在100MB/s上下,那么在1s內(nèi)處理1TB數(shù)據(jù)�,意味著至少需要有1萬個(gè)磁盤的并發(fā)讀,在如此大量的讀寫���,需要復(fù)雜的容錯(cuò)設(shè)計(jì)���,少量節(jié)點(diǎn)的讀失敗(或慢操作)不能影響整體操作�����。
· Dremel支持嵌套的數(shù)據(jù)結(jié)構(gòu)���。互聯(lián)網(wǎng)數(shù)據(jù)常常是非關(guān)系型的����。Dremel還支持靈活的數(shù)據(jù)模型�����,一種嵌套(Nested)的數(shù)據(jù)模型����,類似于Protocol Buffer定義的數(shù)據(jù)結(jié)構(gòu)����。Dremel采用列式方法存儲(chǔ)這些數(shù)據(jù)���,由于嵌套數(shù)據(jù)結(jié)構(gòu)����,Dremel引入了一種樹狀的列式存儲(chǔ)結(jié)構(gòu)���,方便嵌套數(shù)據(jù)的查詢����。論文詳細(xì)解釋了嵌套數(shù)據(jù)類型的列存儲(chǔ)�����,這個(gè)特性是Druid缺少的�,實(shí)現(xiàn)也是非常復(fù)雜的���。
· Dremel采用層級(jí)的執(zhí)行引擎�����。Dremel在執(zhí)行過程中��,SQL查詢輸入會(huì)轉(zhuǎn)化成執(zhí)行計(jì)劃�����,并發(fā)處理數(shù)據(jù)�。和MapReduce一樣,Dremel也需要和數(shù)據(jù)運(yùn)行在一起�,將計(jì)算移動(dòng)到數(shù)據(jù)上面。所以它需要GFS這樣的文件系統(tǒng)作為存儲(chǔ)層�����。在設(shè)計(jì)之初�����,Dremel并非是MapReduce的替代品��,它只是可以執(zhí)行非?���?斓姆治觯谑褂玫臅r(shí)候,常常用它來處理MapReduce的結(jié)果集或者用來建立分析原型�。
在使用Dremel時(shí),工程師需要通過Map Reduce將數(shù)據(jù)導(dǎo)入到Dremel��,可以通過定期的MapReduce的定時(shí)任務(wù)完成導(dǎo)入�����。在數(shù)據(jù)的實(shí)時(shí)性方面��,論文并沒有討論太多�����。
6.Apache Drill
Apache Drill 通過開源方式實(shí)現(xiàn)了 Google’s Dremel���。Apache Drill的架構(gòu)����,整個(gè)思想還是通過優(yōu)化查詢引擎�����,進(jìn)行快速全表掃描�,以快速返回結(jié)果�����。
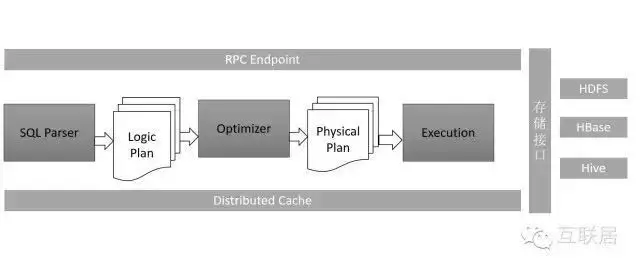 Apache Drill 在基于 SQL 的數(shù)據(jù)分析和商業(yè)智能(BI)上引入了 JSON 文件模型,這使得用戶能查詢固定架構(gòu)�����,支持各種格式和數(shù)據(jù)存儲(chǔ)中的模式無關(guān)(schema-free)數(shù)據(jù)�����。該體系架構(gòu)中關(guān)系查詢引擎和數(shù)據(jù)庫的構(gòu)建是有先決條件的��,即假設(shè)所有數(shù)據(jù)都有一個(gè)簡單的靜態(tài)架構(gòu)�。
Apache Drill 的架構(gòu)是獨(dú)一無二的。它是唯一一個(gè)支持復(fù)雜和無模式數(shù)據(jù)的柱狀執(zhí)行引擎(columnar execution engine)����,也是唯一一個(gè)能在查詢執(zhí)行期間進(jìn)行數(shù)據(jù)驅(qū)動(dòng)查詢(和重新編譯,也稱之為 schema discovery)的執(zhí)行引擎(execution engine)�����。這些獨(dú)一無二的性能使得 Apache Drill 在 JSON 文件模式下能實(shí)現(xiàn)記錄斷點(diǎn)性能(record-breaking performance)����。該項(xiàng)目將會(huì)創(chuàng)建出開源版本的谷歌Dremel Hadoop工具(谷歌使用該工具來為Hadoop數(shù)據(jù)分析工具的互聯(lián)網(wǎng)應(yīng)用提速)�����。而“Drill”將有助于Hadoop用戶實(shí)現(xiàn)更快查詢海量數(shù)據(jù)集的目的��。
目前�����,Drill已經(jīng)完成的需求和架構(gòu)設(shè)計(jì)��?�?偣卜譃橐韵滤膫€(gè)組件:
· Query language:類似Google BigQuery的查詢語言�����,支持嵌套模型�����,名為DrQL�。
· Low-lantency distribute execution engine:執(zhí)行引擎�����,可以支持大規(guī)模擴(kuò)展和容錯(cuò),并運(yùn)行在上萬臺(tái)機(jī)器上計(jì)算數(shù)以PB的數(shù)據(jù)���。
· Nested data format:嵌套數(shù)據(jù)模型,和Dremel類似����。也支持CSV,JSON��,YAML之類的模型���。這樣執(zhí)行引擎就可以支持更多的數(shù)據(jù)類型�����。
· Scalable data source: 支持多種數(shù)據(jù)源�����,現(xiàn)階段以Hadoop為數(shù)據(jù)源��。
7.ElasticSearch
Elasticsearch是Elastic公司推出的一個(gè)基于Lucene的分布式搜索服務(wù)系統(tǒng)�����,它是一個(gè)高可靠�、可擴(kuò)展、分布式的全文搜索引擎���,下面簡稱ES�����,提供了方便的RESTful web接口����。ES采用Java語言開發(fā)���,并作為Apache許可條款下的開放源碼發(fā)布�,它是流行的企業(yè)搜索引擎��。與之類似的軟件還有Solr���,兩個(gè)軟件有一定的相似性��。
ES在前幾年的定位一直是文本的倒排索引引擎��,用于文本搜索的場(chǎng)景���。最近幾年�����,Elastic公司將ES用于日志分析和數(shù)據(jù)的可視化�,慢慢轉(zhuǎn)成一個(gè)數(shù)據(jù)分析平臺(tái)��。它能夠提供類似于OLAP的一些簡單的Count ����,Group by 功能��。另外�,套件中內(nèi)置的Kibana可視化工具提供了出色的交互界面,可以對(duì)接常用的儀表盤(Dashboard)功能���。因此�����,在一些數(shù)據(jù)量不大��,需要文本搜索的場(chǎng)景下�����,直接使用Elaticsearch作為簡單的數(shù)據(jù)分析平臺(tái)也是快速的解決方案����。
Elastic主推ELK產(chǎn)品,它是一個(gè)提供數(shù)據(jù)分析功能的套裝�����,包括LogStash:數(shù)據(jù)收集���、ES:數(shù)據(jù)索引和 Kibana:可視化表現(xiàn)�����。
ES內(nèi)部使用了Lucence的倒排索引�����,每個(gè)Term后面都關(guān)聯(lián)了相關(guān)的文檔ID列表�����,這種結(jié)構(gòu)比較適合基數(shù)較大的列��,比如人名����,單詞等。Elasticsearch支持靈活的數(shù)據(jù)輸入�����,支持無固定格式(Schema Free)的數(shù)據(jù)輸入�����,隨時(shí)增加索引��。
相比Druid�����,Elaticsearch對(duì)于基數(shù)大的列能夠提供完美的索引方案�,例如文本����。Elasticsearch也提供了實(shí)時(shí)的數(shù)據(jù)注入功能�����,但是性能比Druid要慢很多����,應(yīng)為它的索引過程更加復(fù)雜�。另外一個(gè)顯著不同,ES是Schema Free的����,也就是說無需定義Schema,就可以直接插入Json數(shù)據(jù)����,進(jìn)行索引,而且數(shù)據(jù)結(jié)構(gòu)也支持?jǐn)?shù)組等靈活的數(shù)據(jù)類型�����。Druid需要定義清楚維度和指標(biāo)列�。另外一個(gè)很大區(qū)別,ES會(huì)保持元素的文檔數(shù)據(jù)��,而Druid在按照時(shí)間粒度數(shù)據(jù)聚合后,原始數(shù)據(jù)將會(huì)丟棄��,因此無法找回具體的某一數(shù)據(jù)行�����。
最近幾年�,ES一直在增加數(shù)據(jù)分析的能力,包括各種聚合查詢等����,性能提升也很快。如果數(shù)據(jù)規(guī)模不大的情況下�,ES也是非常不錯(cuò)的選擇。Druid更善于處理更大規(guī)模�,實(shí)時(shí)性更強(qiáng)的數(shù)據(jù)。
八���、SQL on Hadoop/Spark
Hadoop生態(tài)發(fā)展了多年,越來越多的公司將重要的日志數(shù)據(jù)存入Hadoop的HDFS系統(tǒng)中���,數(shù)據(jù)的持久化和可靠性得到了保證�,但是如何快速挖掘出其中的價(jià)值確實(shí)很多公司的痛點(diǎn)��。常用的分析過程有以下幾種:
數(shù)據(jù)從HDFS導(dǎo)入到RDBMS/NoSQL+ 基于HDFS,寫代碼通過Map Reduce進(jìn)行數(shù)據(jù)分析+ 基于HDFS�����,編寫SQL直接訪問+ SQL訪問內(nèi)部轉(zhuǎn)為Map Reduce任務(wù)
訪問引擎直接訪問HDFS文件系統(tǒng)
接下來��,我們來看看簡單的SQL查詢是如何訪問HDFS的���。
1.Hive
Hive是基于Hadoop的一個(gè)數(shù)據(jù)倉庫工具�����,可以將結(jié)構(gòu)化的數(shù)據(jù)文件映射為一張數(shù)據(jù)庫表�,并提供簡單的SQL查詢功能���,可以將sql語句轉(zhuǎn)換為Map Reduce任務(wù)進(jìn)行運(yùn)行����。 其優(yōu)點(diǎn)是學(xué)習(xí)成本低���,可以通過類SQL語句快速實(shí)現(xiàn)簡單的Map Reduce統(tǒng)計(jì)�����,不必開發(fā)專門的Map Reduce應(yīng)用��,十分適合數(shù)據(jù)倉庫的統(tǒng)計(jì)分析�����。 Hive 并不適合那些需要低延遲的應(yīng)用�����,例如��,聯(lián)機(jī)事務(wù)處理(OLTP)���。Hive 查詢操作過程嚴(yán)格遵守Hadoop Map Reduce 的作業(yè)執(zhí)行模型��,整個(gè)查詢過程也比較慢���,不適合實(shí)時(shí)的數(shù)據(jù)分析。
幾乎所有的Hadoop環(huán)境都會(huì)配置Hive的應(yīng)用�����,雖然Hive易用�����,但內(nèi)部的Map Reduce操作還是帶來非常慢的查詢體驗(yàn)����。所有嘗試Hive的公司,機(jī)會(huì)都會(huì)轉(zhuǎn)型到Impala的應(yīng)用����。
2.Impala
Impala是Cloudera在受到Google的Dremel啟發(fā)下開發(fā)的實(shí)時(shí)交互SQL大數(shù)據(jù)查詢工具,使用C++編寫���,通過使用與商用MPP類似的分布式查詢引擎(由Query Planner����、Query Coordinator和Query Exec Engine三部分組成)��,可以直接從HDFS或HBase中用SELECT�����、JOIN和統(tǒng)計(jì)函數(shù)查詢數(shù)據(jù)���,從而大大降低了延遲�����。 Impala使用的列存儲(chǔ)格式是Parquet�����。Parquet實(shí)現(xiàn)了Dremel中的列存儲(chǔ)����,未來還將支持 Hive并添加字典編碼、游程編碼等功能���。 在Cloudera的測(cè)試中��,Impala的查詢效率比Hive有數(shù)量級(jí)的提升����,因?yàn)镮mpala省去了Map Reduce的過程����,減少了終結(jié)結(jié)果落盤的問題。
Apache Drill 在基于 SQL 的數(shù)據(jù)分析和商業(yè)智能(BI)上引入了 JSON 文件模型,這使得用戶能查詢固定架構(gòu)�����,支持各種格式和數(shù)據(jù)存儲(chǔ)中的模式無關(guān)(schema-free)數(shù)據(jù)�����。該體系架構(gòu)中關(guān)系查詢引擎和數(shù)據(jù)庫的構(gòu)建是有先決條件的��,即假設(shè)所有數(shù)據(jù)都有一個(gè)簡單的靜態(tài)架構(gòu)�。
Apache Drill 的架構(gòu)是獨(dú)一無二的。它是唯一一個(gè)支持復(fù)雜和無模式數(shù)據(jù)的柱狀執(zhí)行引擎(columnar execution engine)����,也是唯一一個(gè)能在查詢執(zhí)行期間進(jìn)行數(shù)據(jù)驅(qū)動(dòng)查詢(和重新編譯,也稱之為 schema discovery)的執(zhí)行引擎(execution engine)�����。這些獨(dú)一無二的性能使得 Apache Drill 在 JSON 文件模式下能實(shí)現(xiàn)記錄斷點(diǎn)性能(record-breaking performance)����。該項(xiàng)目將會(huì)創(chuàng)建出開源版本的谷歌Dremel Hadoop工具(谷歌使用該工具來為Hadoop數(shù)據(jù)分析工具的互聯(lián)網(wǎng)應(yīng)用提速)�����。而“Drill”將有助于Hadoop用戶實(shí)現(xiàn)更快查詢海量數(shù)據(jù)集的目的��。
目前�����,Drill已經(jīng)完成的需求和架構(gòu)設(shè)計(jì)��?�?偣卜譃橐韵滤膫€(gè)組件:
· Query language:類似Google BigQuery的查詢語言�����,支持嵌套模型�����,名為DrQL�。
· Low-lantency distribute execution engine:執(zhí)行引擎�����,可以支持大規(guī)模擴(kuò)展和容錯(cuò),并運(yùn)行在上萬臺(tái)機(jī)器上計(jì)算數(shù)以PB的數(shù)據(jù)���。
· Nested data format:嵌套數(shù)據(jù)模型,和Dremel類似����。也支持CSV,JSON��,YAML之類的模型���。這樣執(zhí)行引擎就可以支持更多的數(shù)據(jù)類型�����。
· Scalable data source: 支持多種數(shù)據(jù)源�����,現(xiàn)階段以Hadoop為數(shù)據(jù)源��。
7.ElasticSearch
Elasticsearch是Elastic公司推出的一個(gè)基于Lucene的分布式搜索服務(wù)系統(tǒng)�����,它是一個(gè)高可靠�、可擴(kuò)展、分布式的全文搜索引擎���,下面簡稱ES�����,提供了方便的RESTful web接口����。ES采用Java語言開發(fā)���,并作為Apache許可條款下的開放源碼發(fā)布�,它是流行的企業(yè)搜索引擎��。與之類似的軟件還有Solr���,兩個(gè)軟件有一定的相似性��。
ES在前幾年的定位一直是文本的倒排索引引擎��,用于文本搜索的場(chǎng)景���。最近幾年�����,Elastic公司將ES用于日志分析和數(shù)據(jù)的可視化�,慢慢轉(zhuǎn)成一個(gè)數(shù)據(jù)分析平臺(tái)��。它能夠提供類似于OLAP的一些簡單的Count ����,Group by 功能��。另外�,套件中內(nèi)置的Kibana可視化工具提供了出色的交互界面,可以對(duì)接常用的儀表盤(Dashboard)功能���。因此�����,在一些數(shù)據(jù)量不大��,需要文本搜索的場(chǎng)景下�����,直接使用Elaticsearch作為簡單的數(shù)據(jù)分析平臺(tái)也是快速的解決方案����。
Elastic主推ELK產(chǎn)品,它是一個(gè)提供數(shù)據(jù)分析功能的套裝�����,包括LogStash:數(shù)據(jù)收集���、ES:數(shù)據(jù)索引和 Kibana:可視化表現(xiàn)�����。
ES內(nèi)部使用了Lucence的倒排索引�����,每個(gè)Term后面都關(guān)聯(lián)了相關(guān)的文檔ID列表�����,這種結(jié)構(gòu)比較適合基數(shù)較大的列��,比如人名����,單詞等。Elasticsearch支持靈活的數(shù)據(jù)輸入�����,支持無固定格式(Schema Free)的數(shù)據(jù)輸入�����,隨時(shí)增加索引��。
相比Druid�����,Elaticsearch對(duì)于基數(shù)大的列能夠提供完美的索引方案�,例如文本����。Elasticsearch也提供了實(shí)時(shí)的數(shù)據(jù)注入功能�����,但是性能比Druid要慢很多����,應(yīng)為它的索引過程更加復(fù)雜�。另外一個(gè)顯著不同,ES是Schema Free的����,也就是說無需定義Schema,就可以直接插入Json數(shù)據(jù)����,進(jìn)行索引,而且數(shù)據(jù)結(jié)構(gòu)也支持?jǐn)?shù)組等靈活的數(shù)據(jù)類型�����。Druid需要定義清楚維度和指標(biāo)列�。另外一個(gè)很大區(qū)別,ES會(huì)保持元素的文檔數(shù)據(jù)��,而Druid在按照時(shí)間粒度數(shù)據(jù)聚合后,原始數(shù)據(jù)將會(huì)丟棄��,因此無法找回具體的某一數(shù)據(jù)行�����。
最近幾年�,ES一直在增加數(shù)據(jù)分析的能力,包括各種聚合查詢等����,性能提升也很快。如果數(shù)據(jù)規(guī)模不大的情況下�,ES也是非常不錯(cuò)的選擇。Druid更善于處理更大規(guī)模�,實(shí)時(shí)性更強(qiáng)的數(shù)據(jù)。
八���、SQL on Hadoop/Spark
Hadoop生態(tài)發(fā)展了多年,越來越多的公司將重要的日志數(shù)據(jù)存入Hadoop的HDFS系統(tǒng)中���,數(shù)據(jù)的持久化和可靠性得到了保證�,但是如何快速挖掘出其中的價(jià)值確實(shí)很多公司的痛點(diǎn)��。常用的分析過程有以下幾種:
數(shù)據(jù)從HDFS導(dǎo)入到RDBMS/NoSQL+ 基于HDFS,寫代碼通過Map Reduce進(jìn)行數(shù)據(jù)分析+ 基于HDFS�����,編寫SQL直接訪問+ SQL訪問內(nèi)部轉(zhuǎn)為Map Reduce任務(wù)
訪問引擎直接訪問HDFS文件系統(tǒng)
接下來��,我們來看看簡單的SQL查詢是如何訪問HDFS的���。
1.Hive
Hive是基于Hadoop的一個(gè)數(shù)據(jù)倉庫工具�����,可以將結(jié)構(gòu)化的數(shù)據(jù)文件映射為一張數(shù)據(jù)庫表�,并提供簡單的SQL查詢功能���,可以將sql語句轉(zhuǎn)換為Map Reduce任務(wù)進(jìn)行運(yùn)行����。 其優(yōu)點(diǎn)是學(xué)習(xí)成本低���,可以通過類SQL語句快速實(shí)現(xiàn)簡單的Map Reduce統(tǒng)計(jì)�����,不必開發(fā)專門的Map Reduce應(yīng)用��,十分適合數(shù)據(jù)倉庫的統(tǒng)計(jì)分析�����。 Hive 并不適合那些需要低延遲的應(yīng)用�����,例如��,聯(lián)機(jī)事務(wù)處理(OLTP)���。Hive 查詢操作過程嚴(yán)格遵守Hadoop Map Reduce 的作業(yè)執(zhí)行模型��,整個(gè)查詢過程也比較慢���,不適合實(shí)時(shí)的數(shù)據(jù)分析。
幾乎所有的Hadoop環(huán)境都會(huì)配置Hive的應(yīng)用�����,雖然Hive易用�����,但內(nèi)部的Map Reduce操作還是帶來非常慢的查詢體驗(yàn)����。所有嘗試Hive的公司,機(jī)會(huì)都會(huì)轉(zhuǎn)型到Impala的應(yīng)用����。
2.Impala
Impala是Cloudera在受到Google的Dremel啟發(fā)下開發(fā)的實(shí)時(shí)交互SQL大數(shù)據(jù)查詢工具,使用C++編寫���,通過使用與商用MPP類似的分布式查詢引擎(由Query Planner����、Query Coordinator和Query Exec Engine三部分組成)��,可以直接從HDFS或HBase中用SELECT�����、JOIN和統(tǒng)計(jì)函數(shù)查詢數(shù)據(jù)���,從而大大降低了延遲�����。 Impala使用的列存儲(chǔ)格式是Parquet�����。Parquet實(shí)現(xiàn)了Dremel中的列存儲(chǔ)����,未來還將支持 Hive并添加字典編碼、游程編碼等功能���。 在Cloudera的測(cè)試中��,Impala的查詢效率比Hive有數(shù)量級(jí)的提升����,因?yàn)镮mpala省去了Map Reduce的過程����,減少了終結(jié)結(jié)果落盤的問題。
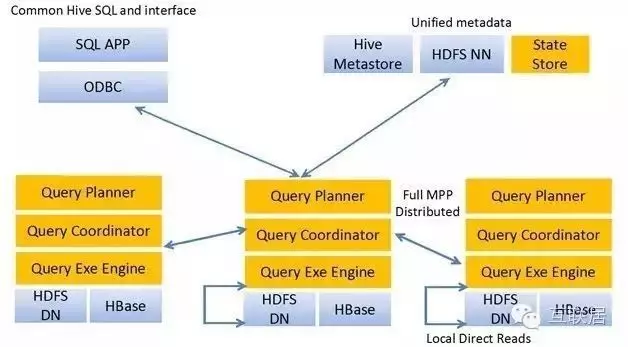 3.Facebook Presto
Presto出生名門���,來自于Facebook���,從出生起就收到關(guān)注。它是用于大數(shù)據(jù)的一個(gè)分布式SQL查詢引擎����,系統(tǒng)主要是Java編寫。Presto是一個(gè)分布式SQL查詢引擎��,它被設(shè)計(jì)用于專門進(jìn)行高速�、實(shí)時(shí)的數(shù)據(jù)分析。它支持標(biāo)準(zhǔn)的ANSI SQL����,包括復(fù)雜查詢、聚合(aggregation)�、連接(join)和窗口函數(shù)(window functions)。下圖展現(xiàn)了簡化的Presto系統(tǒng)架構(gòu)����。
3.Facebook Presto
Presto出生名門���,來自于Facebook���,從出生起就收到關(guān)注。它是用于大數(shù)據(jù)的一個(gè)分布式SQL查詢引擎����,系統(tǒng)主要是Java編寫。Presto是一個(gè)分布式SQL查詢引擎��,它被設(shè)計(jì)用于專門進(jìn)行高速�、實(shí)時(shí)的數(shù)據(jù)分析。它支持標(biāo)準(zhǔn)的ANSI SQL����,包括復(fù)雜查詢、聚合(aggregation)�、連接(join)和窗口函數(shù)(window functions)。下圖展現(xiàn)了簡化的Presto系統(tǒng)架構(gòu)����。
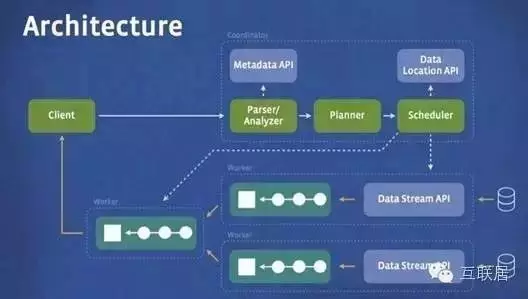
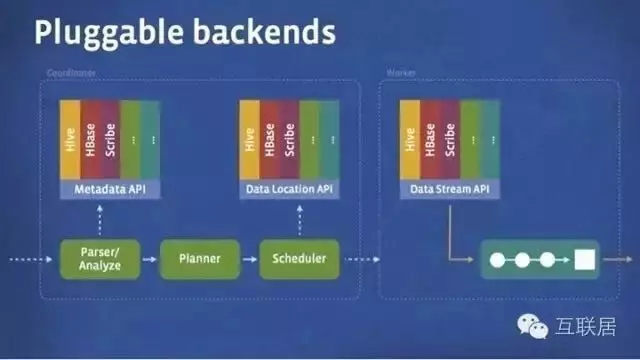
Presto的運(yùn)行模型和Hive或MapReduce有著本質(zhì)的區(qū)別。Hive將查詢翻譯成多階段的MapReduce任務(wù)�����, 一個(gè)接著一個(gè)地運(yùn)行���。每一個(gè)任務(wù)從磁盤上讀取輸入數(shù)據(jù)并且將中間結(jié)果輸出到磁盤上�。然而Presto引擎沒有使用Map Reduce。它使用了一個(gè)定制的查詢和執(zhí)行引擎和響應(yīng)的操作符來支持SQL的語法����。除了改進(jìn)的調(diào)度算法之外,所有的數(shù)據(jù)處理都是在內(nèi)存中進(jìn)行的���。通過軟件的優(yōu)化��,形成處理的流水線���,以避免不必要的磁盤讀寫和額外的延遲。這種流水線式的執(zhí)行模型會(huì)在同一時(shí)間運(yùn)行多個(gè)數(shù)據(jù)處理段����,一旦數(shù)據(jù)可用的時(shí)候就會(huì)將數(shù)據(jù)從一個(gè)處理段傳入到下一個(gè)處理段。這樣的方式會(huì)大大的減少各種查詢的端到端響應(yīng)時(shí)間��。
九��、數(shù)據(jù)分析云服務(wù)
1.Amazon RedShift
Amazon Redshift 是一種快速���、完全托管的 PB 級(jí)數(shù)據(jù)倉庫��,可方便你使用現(xiàn)有的商業(yè)智能工具以一種經(jīng)濟(jì)的方式輕松分析所有數(shù)據(jù)���。 Amazon Redshift 使用列存儲(chǔ)技術(shù)改善 I/O 效率并跨過多個(gè)節(jié)點(diǎn)平行放置查詢����,從而提供快速的查詢性能�����。Amazon Redshift 提供了定制的 JDBC 和 ODBC 驅(qū)動(dòng)程序�����,你可以從我們的控制臺(tái)的“連接客戶端”選項(xiàng)卡中進(jìn)行下載�,以使用各種各種大量熟悉的 SQL 客戶端�����。你也可以使用標(biāo)準(zhǔn)的 PostgreSQL JDBC 和 ODBC 驅(qū)動(dòng)程序�。數(shù)據(jù)加載速度與集群大小、與 Amazon S3�、Amazon DynamoDB、Amazon Elastic MapReduce、Amazon Kinesis 或任何啟用 SSH 的主機(jī)的集成呈線性擴(kuò)展關(guān)系�����。
2.阿里云數(shù)據(jù)倉庫服務(wù)
分析型數(shù)據(jù)庫(Analytic DB)���,是阿里巴巴自主研發(fā)的海量數(shù)據(jù)實(shí)時(shí)高并發(fā)在線分析(Realtime OLAP)云計(jì)算服務(wù)�����,使得您可以在毫秒級(jí)針對(duì)千億級(jí)數(shù)據(jù)進(jìn)行即時(shí)的多維分析透視和業(yè)務(wù)探索���。分析型數(shù)據(jù)庫對(duì)海量數(shù)據(jù)的自由計(jì)算和極速響應(yīng)能力,能讓用戶在瞬息之間進(jìn)行靈活的數(shù)據(jù)探索����,快速發(fā)現(xiàn)數(shù)據(jù)價(jià)值,并可直接嵌入業(yè)務(wù)系統(tǒng)為終端客戶提供分析服務(wù)�。
小結(jié)
數(shù)據(jù)分析的世界繁花似錦,雖然我們可以通過開源/商業(yè)��,SaaS/私有部署等方式來分類���,但是每種數(shù)據(jù)分析軟件都有自己獨(dú)特的定位�。大部分組織,在不同的階段會(huì)使用不同的軟件解決業(yè)務(wù)的問題����,但是業(yè)務(wù)對(duì)于數(shù)據(jù)分析的根本需求沒有變化:更多的數(shù)據(jù),更快的數(shù)據(jù)����,更多樣的數(shù)據(jù)源,更有價(jià)值的分析結(jié)果����,這也是大數(shù)據(jù)的4V本質(zhì)�。

對(duì)CDA數(shù)據(jù)分析師系列課程感興趣的同學(xué),歡迎參加:
http://www.3lll3.cn/kecheng.html
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330